 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$μ_0$: A Scalable 3D Interaction-Trace World Model
Jun 11, 2026World models that capture how actions induce physical change enable scalable robot learning without reliance on embodiment-specific action labels. Pixel-space video models provide broad visual priors but expend model capacity on dense appearance reconstruction, while direct action models require embodiment-specific labels that hinder scalability. We present $μ_0$, a scalable world model based on 3D traces. Rather than predicting dense pixels or directly modeling actions, $μ_0$ forecasts smooth 3D trajectories for salient interaction points such as objects, tools, hands, and contact regions, yielding a compact, embodiment-agnostic motion interface. To enable training from diverse video sources, our TraceExtract system automatically extracts 3D supervision by selecting keypoints, constructing globally aligned traces, and associating motion segments with hierarchical language captions. This TraceExtract supervision pretrains $μ_0$ by combining a pretrained vision-language backbone with a modular trace expert, which represents each query via B-spline control points and predicts future traces. Experiments show that $μ_0$ outperforms baselines in both 2D and 3D trace prediction, including trace prediction models and tokenized VLM methods. Because $μ_0$ is frozen and reusable, it can be paired with action experts for downstream robot embodiments. Despite action-free pretraining, the resulting trace-conditioned policies achieve performance competitive with VLA models pretrained with action supervision, such as $π_0$. These results establish 3D traces as a scalable and transferable representation for cross-embodiment manipulation.
DynaFLIP: Rethinking Robotics Perception via Tri-Modal-Dynamics Guided Representation
May 28, 2026Robot manipulation critically depends on perception that preserves the action-relevant aspects of a scene. Yet most robot learning pipelines are built upon visual encoders pre-trained for static recognition or vision-language alignment, leaving motion understanding to downstream policies. We introduce DynaFLIP, a dynamics-aware multimodal pre-training framework that pushes motion understanding upstream into perception. We construct image-language-3D flow triplets from heterogeneous human and robot videos, and use these triplets as training-time supervision to shape an image-only encoder. Our key idea is to encourage the three modalities to span a small simplex volume in the shared hyperspherical space -- a smaller simplex volume indicating stronger alignment. To avoid the geometric ambiguity and trivial collapse of naive volume minimization, we combine simplex-volume minimization with a cosine regularizer and a contrastive objective. Our analyses show that DynaFLIP focuses on control-relevant regions critical for manipulation. The resulting dynamics-aware representations serve as reusable visual backbones and consistently outperform baselines across diverse downstream policies, including VLAs. We validate this across diverse simulation and real-world setups, with gains reaching +22.5% under out-of-distribution scenarios. Our results suggest that robot generalization improves when visual representations are trained to encode not just what is present, but how the world changes under action.
Choose Your Own Question: Encouraging Self-Personalization in Learning Path Construction
May 08, 2020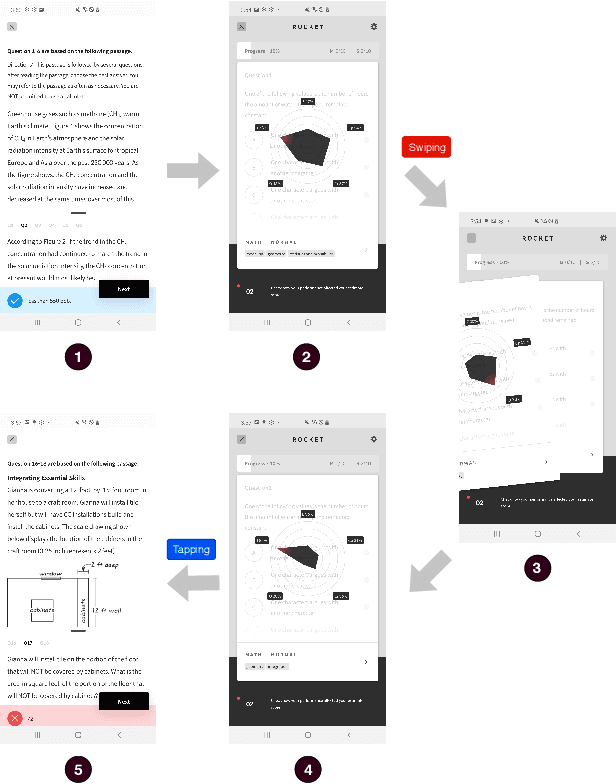
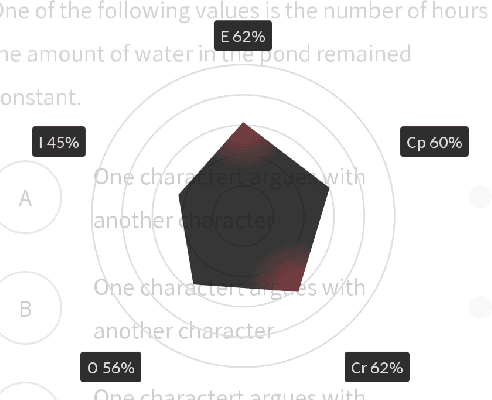
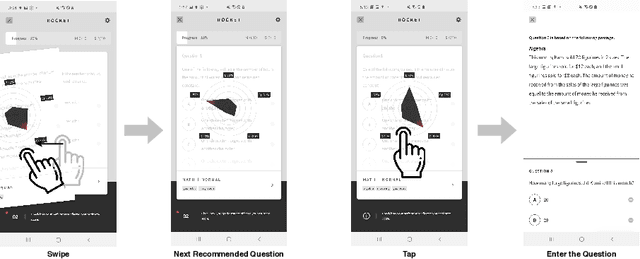
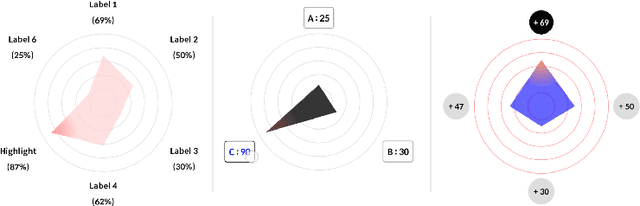
Learning Path Recommendation is the heart of adaptive learning, the educational paradigm of an Interactive Educational System (IES) providing a personalized learning experience based on the student's history of learning activities. In typical existing IESs, the student must fully consume a recommended learning item to be provided a new recommendation. This workflow comes with several limitations. For example, there is no opportunity for the student to give feedback on the choice of learning items made by the IES. Furthermore, the mechanism by which the choice is made is opaque to the student, limiting the student's ability to track their learning. To this end, we introduce Rocket, a Tinder-like User Interface for a general class of IESs. Rocket provides a visual representation of Artificial Intelligence (AI)-extracted features of learning materials, allowing the student to quickly decide whether the material meets their needs. The student can choose between engaging with the material and receiving a new recommendation by swiping or tapping. Rocket offers the following potential improvements for IES User Interfaces: First, Rocket enhances the explainability of IES recommendations by showing students a visual summary of the meaningful AI-extracted features used in the decision-making process. Second, Rocket enables self-personalization of the learning experience by leveraging the students' knowledge of their own abilities and needs. Finally, Rocket provides students with fine-grained information on their learning path, giving them an avenue to assess their own skills and track their learning progress. We present the source code of Rocket, in which we emphasize the independence and extensibility of each component, and make it publicly available for all purposes.