 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Causal/Non-Causal Self-Attention for Streaming End-to-End Speech Recognition
Jul 02, 2021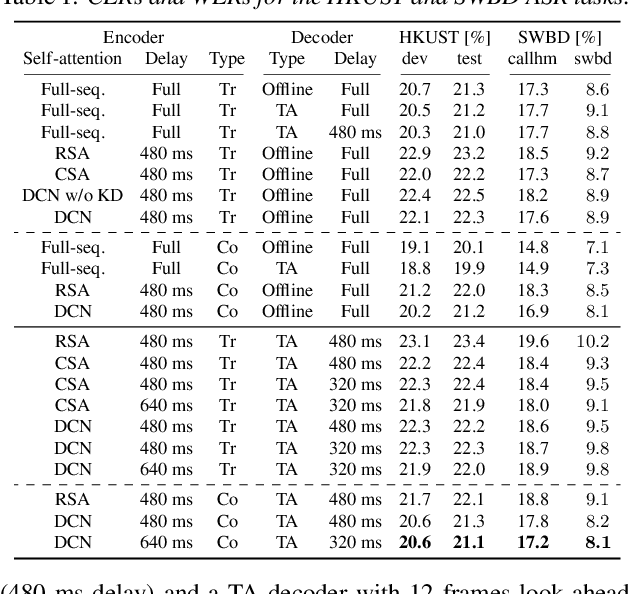
Attention-based end-to-end automatic speech recognition (ASR) systems have recently demonstrated state-of-the-art results for numerous tasks. However, the application of self-attention and attention-based encoder-decoder models remains challenging for streaming ASR, where each word must be recognized shortly after it was spoken. In this work, we present the dual causal/non-causal self-attention (DCN) architecture, which in contrast to restricted self-attention prevents the overall context to grow beyond the look-ahead of a single layer when used in a deep architecture. DCN is compared to chunk-based and restricted self-attention using streaming transformer and conformer architectures, showing improved ASR performance over restricted self-attention and competitive ASR results compared to chunk-based self-attention, while providing the advantage of frame-synchronous processing. Combined with triggered attention, the proposed streaming end-to-end ASR systems obtained state-of-the-art results on the LibriSpeech, HKUST, and Switchboard ASR tasks.
Momentum Pseudo-Labeling for Semi-Supervised Speech Recognition
Jun 16, 2021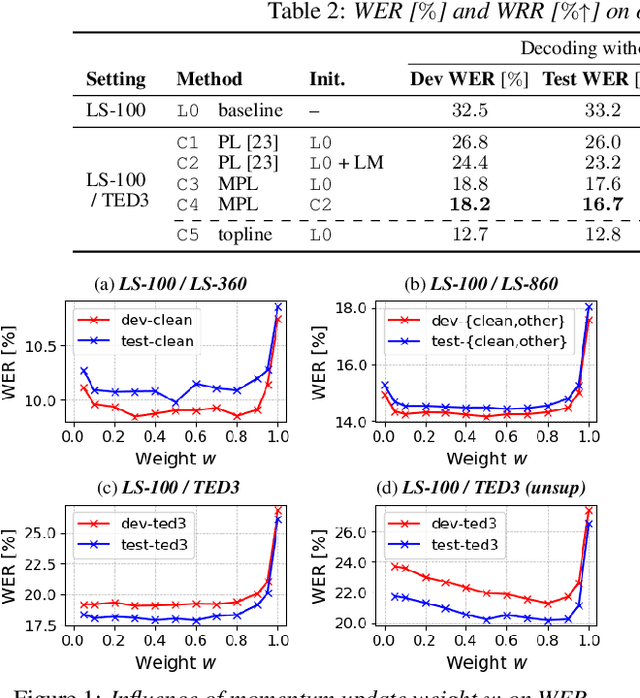
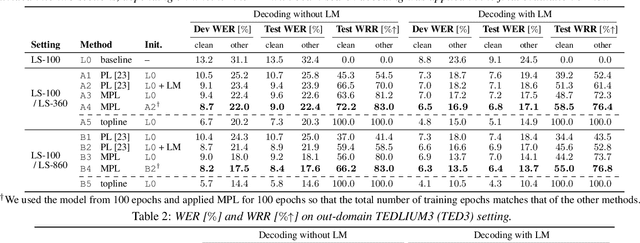
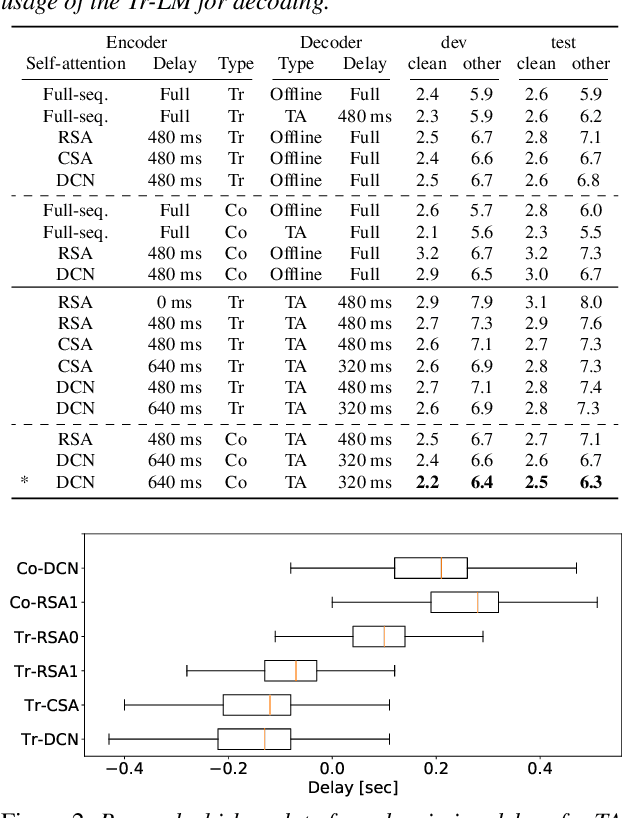
Pseudo-labeling (PL) has been shown to be effective in semi-supervised automatic speech recognition (ASR), where a base model is self-trained with pseudo-labels generated from unlabeled data. While PL can be further improved by iteratively updating pseudo-labels as the model evolves, most of the previous approaches involve inefficient retraining of the model or intricate control of the label update. We present momentum pseudo-labeling (MPL), a simple yet effective strategy for semi-supervised ASR. MPL consists of a pair of online and offline models that interact and learn from each other, inspired by the mean teacher method. The online model is trained to predict pseudo-labels generated on the fly by the offline model. The offline model maintains a momentum-based moving average of the online model. MPL is performed in a single training process and the interaction between the two models effectively helps them reinforce each other to improve the ASR performance. We apply MPL to an end-to-end ASR model based on the connectionist temporal classification. The experimental results demonstrate that MPL effectively improves over the base model and is scalable to different semi-supervised scenarios with varying amounts of data or domain mismatch.
Advanced Long-context End-to-end Speech Recognition Using Context-expanded Transformers
Apr 19, 2021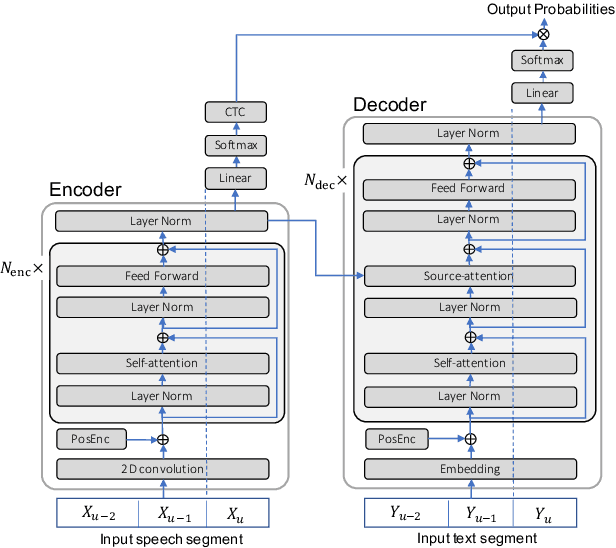
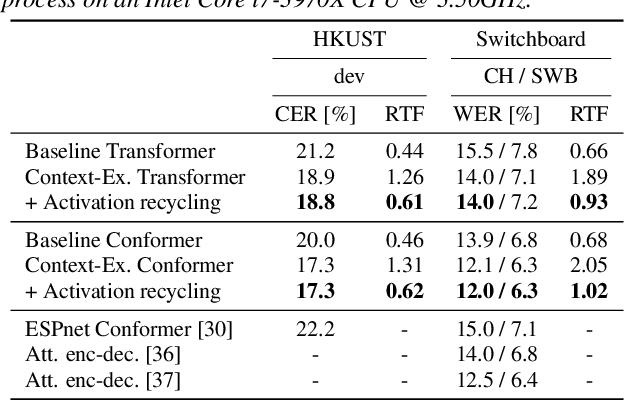
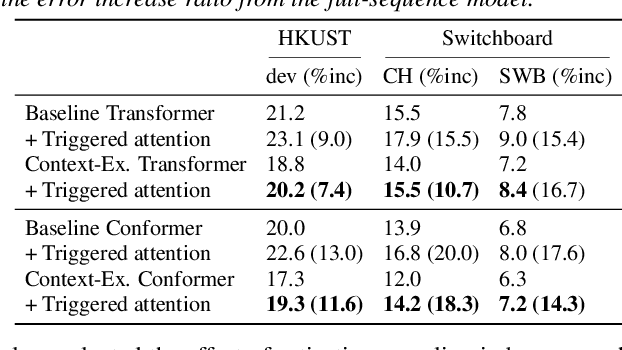
This paper addresses end-to-end automatic speech recognition (ASR) for long audio recordings such as lecture and conversational speeches. Most end-to-end ASR models are designed to recognize independent utterances, but contextual information (e.g., speaker or topic) over multiple utterances is known to be useful for ASR. In our prior work, we proposed a context-expanded Transformer that accepts multiple consecutive utterances at the same time and predicts an output sequence for the last utterance, achieving 5-15% relative error reduction from utterance-based baselines in lecture and conversational ASR benchmarks. Although the results have shown remarkable performance gain, there is still potential to further improve the model architecture and the decoding process. In this paper, we extend our prior work by (1) introducing the Conformer architecture to further improve the accuracy, (2) accelerating the decoding process with a novel activation recycling technique, and (3) enabling streaming decoding with triggered attention. We demonstrate that the extended Transformer provides state-of-the-art end-to-end ASR performance, obtaining a 17.3% character error rate for the HKUST dataset and 12.0%/6.3% word error rates for the Switchboard-300 Eval2000 CallHome/Switchboard test sets. The new decoding method reduces decoding time by more than 50% and further enables streaming ASR with limited accuracy degradation.
Capturing Multi-Resolution Context by Dilated Self-Attention
Apr 07, 2021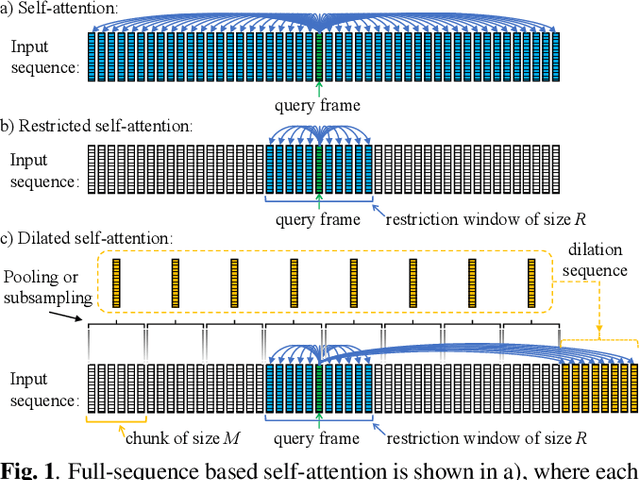
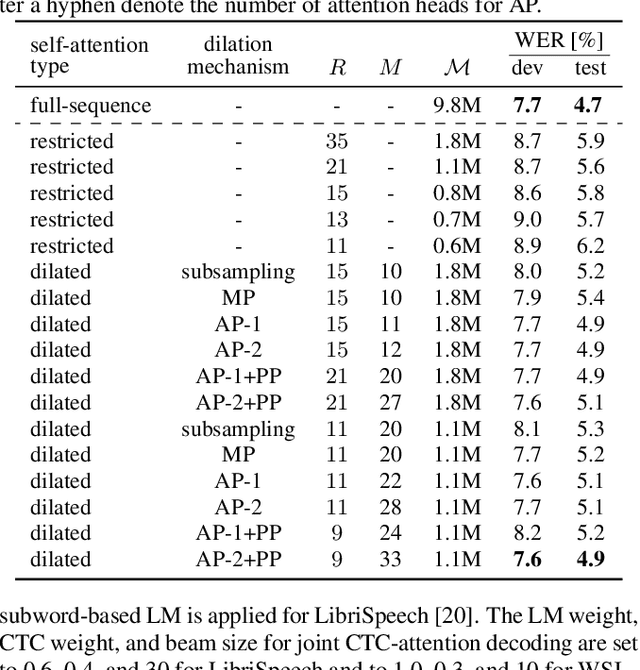
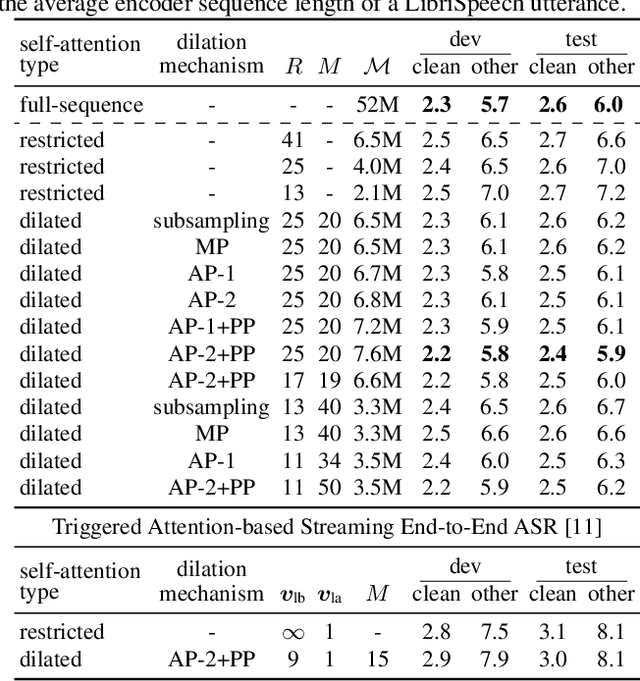
Self-attention has become an important and widely used neural network component that helped to establish new state-of-the-art results for various applications, such as machine translation and automatic speech recognition (ASR). However, the computational complexity of self-attention grows quadratically with the input sequence length. This can be particularly problematic for applications such as ASR, where an input sequence generated from an utterance can be relatively long. In this work, we propose a combination of restricted self-attention and a dilation mechanism, which we refer to as dilated self-attention. The restricted self-attention allows attention to neighboring frames of the query at a high resolution, and the dilation mechanism summarizes distant information to allow attending to it with a lower resolution. Different methods for summarizing distant frames are studied, such as subsampling, mean-pooling, and attention-based pooling. ASR results demonstrate substantial improvements compared to restricted self-attention alone, achieving similar results compared to full-sequence based self-attention with a fraction of the computational costs.
Unsupervised Domain Adaptation for Speech Recognition via Uncertainty Driven Self-Training
Nov 26, 2020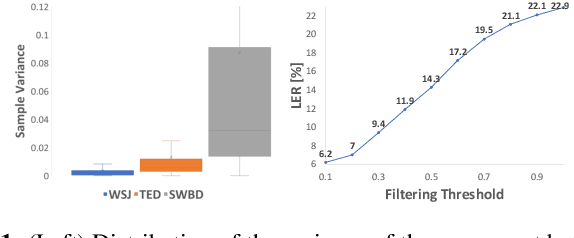
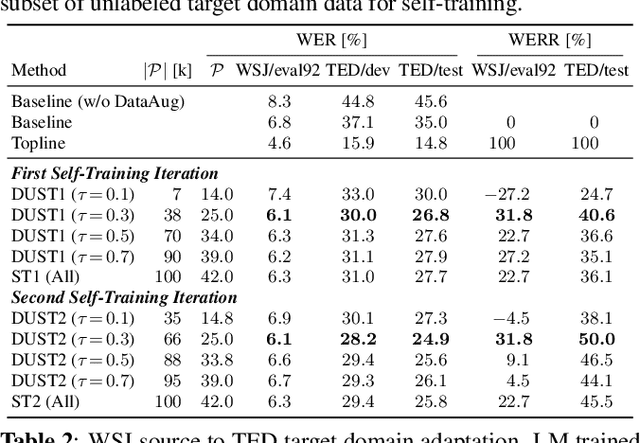
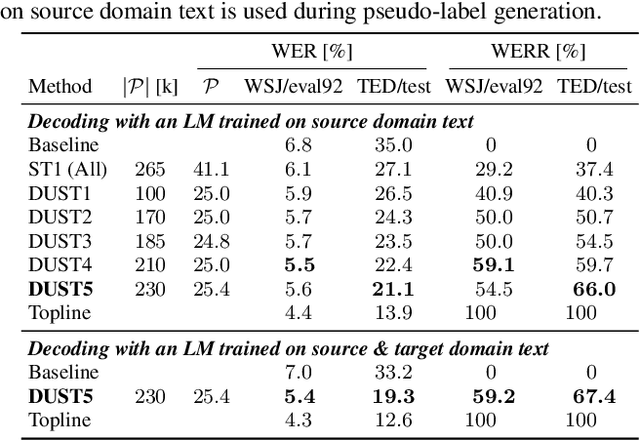
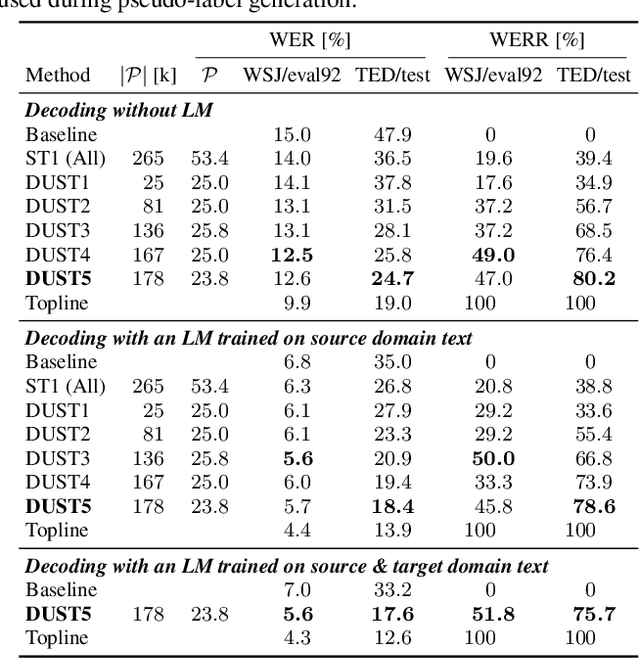
The performance of automatic speech recognition (ASR) systems typically degrades significantly when the training and test data domains are mismatched. In this paper, we show that self-training (ST) combined with an uncertainty-based pseudo-label filtering approach can be effectively used for domain adaptation. We propose DUST, a dropout-based uncertainty-driven self-training technique which uses agreement between multiple predictions of an ASR system obtained for different dropout settings to measure the model's uncertainty about its prediction. DUST excludes pseudo-labeled data with high uncertainties from the training, which leads to substantially improved ASR results compared to ST without filtering, and accelerates the training time due to a reduced training data set. Domain adaptation experiments using WSJ as a source domain and TED-LIUM 3 as well as SWITCHBOARD as the target domains show that up to 80% of the performance of a system trained on ground-truth data can be recovered.
Semi-Supervised Speech Recognition via Graph-based Temporal Classification
Oct 29, 2020

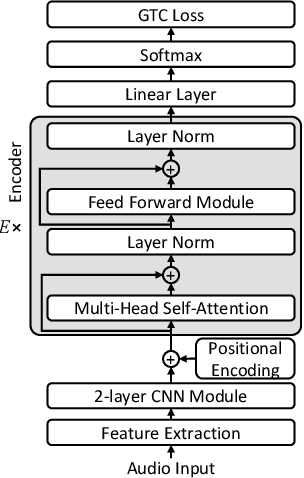
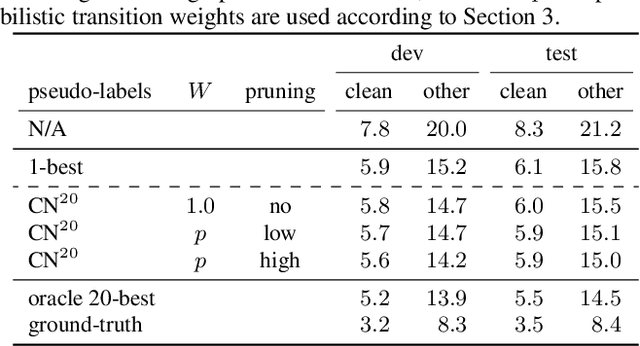
Semi-supervised learning has demonstrated promising results in automatic speech recognition (ASR) by self-training using a seed ASR model with pseudo-labels generated for unlabeled data. The effectiveness of this approach largely relies on the pseudo-label accuracy, for which typically only the 1-best ASR hypothesis is used. However, alternative ASR hypotheses of an N-best list can provide more accurate labels for an unlabeled speech utterance and also reflect uncertainties of the seed ASR model. In this paper, we propose a generalized form of the connectionist temporal classification (CTC) objective that accepts a graph representation of the training targets. The newly proposed graph-based temporal classification (GTC) objective is applied for self-training with WFST-based supervision, which is generated from an N-best list of pseudo-labels. In this setup, GTC is used to learn not only a temporal alignment, similarly to CTC, but also a label alignment to obtain the optimal pseudo-label sequence from the weighted graph. Results show that this approach can effectively exploit an N-best list of pseudo-labels with associated scores, outperforming standard pseudo-labeling by a large margin, with ASR results close to an oracle experiment in which the best hypotheses of the N-best lists are selected manually.
Transcription Is All You Need: Learning to Separate Musical Mixtures with Score as Supervision
Oct 22, 2020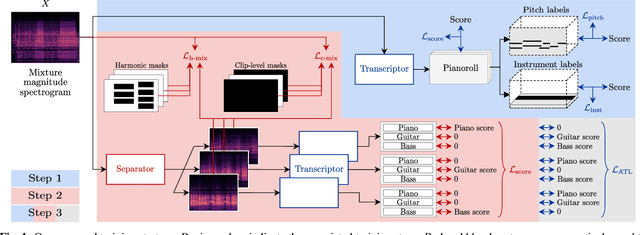
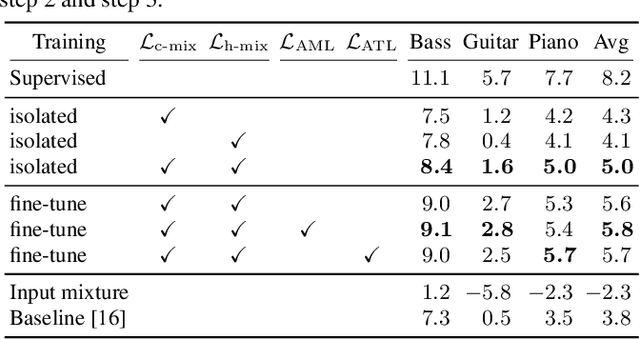
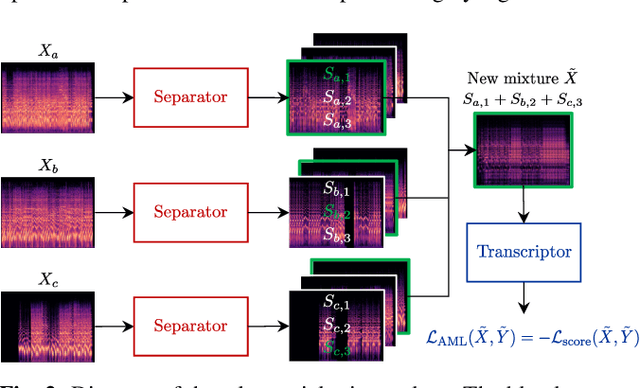
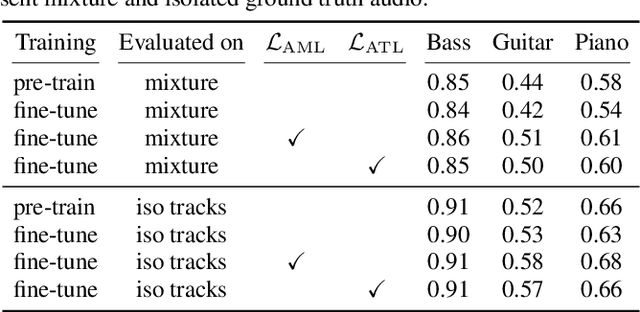
Most music source separation systems require large collections of isolated sources for training, which can be difficult to obtain. In this work, we use musical scores, which are comparatively easy to obtain, as a weak label for training a source separation system. In contrast with previous score-informed separation approaches, our system does not require isolated sources, and score is used only as a training target, not required for inference. Our model consists of a separator that outputs a time-frequency mask for each instrument, and a transcriptor that acts as a critic, providing both temporal and frequency supervision to guide the learning of the separator. A harmonic mask constraint is introduced as another way of leveraging score information during training, and we propose two novel adversarial losses for additional fine-tuning of both the transcriptor and the separator. Results demonstrate that using score information outperforms temporal weak-labels, and adversarial structures lead to further improvements in both separation and transcription performance.
Multi-Pass Transformer for Machine Translation
Sep 23, 2020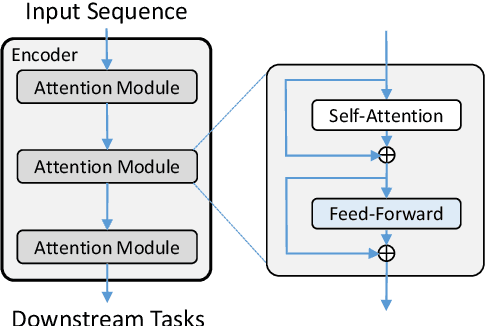
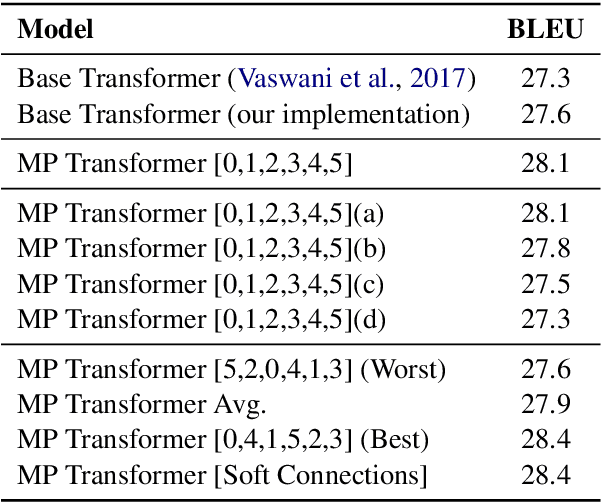
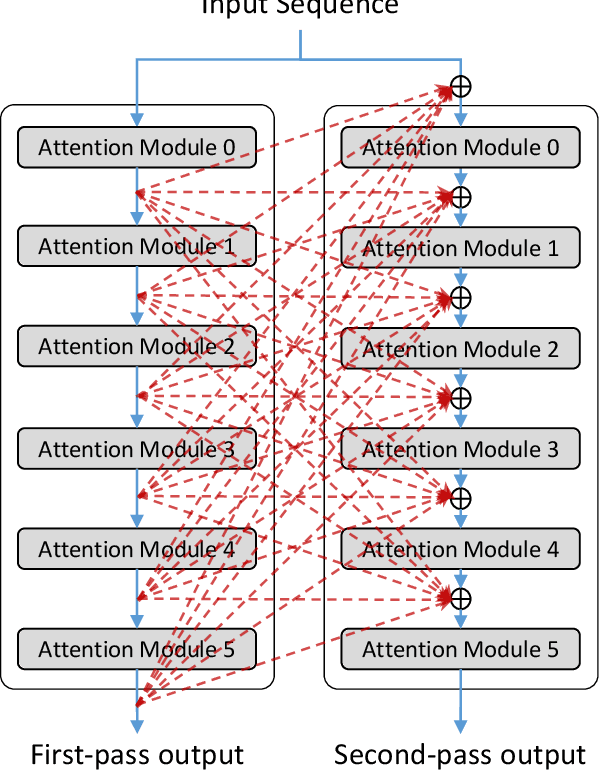
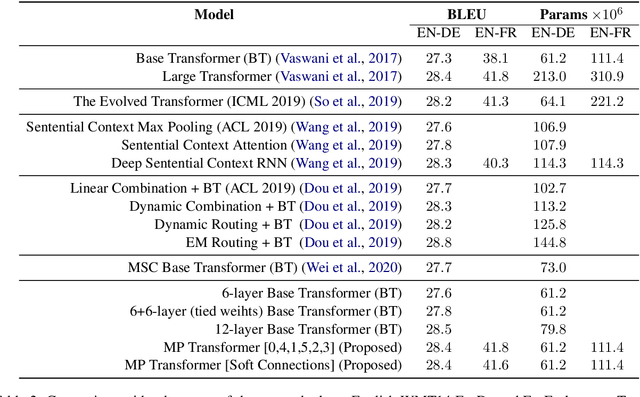
In contrast with previous approaches where information flows only towards deeper layers of a stack, we consider a multi-pass transformer (MPT) architecture in which earlier layers are allowed to process information in light of the output of later layers. To maintain a directed acyclic graph structure, the encoder stack of a transformer is repeated along a new multi-pass dimension, keeping the parameters tied, and information is allowed to proceed unidirectionally both towards deeper layers within an encoder stack and towards any layer of subsequent stacks. We consider both soft (i.e., continuous) and hard (i.e., discrete) connections between parallel encoder stacks, relying on a neural architecture search to find the best connection pattern in the hard case. We perform an extensive ablation study of the proposed MPT architecture and compare it with other state-of-the-art transformer architectures. Surprisingly, Base Transformer equipped with MPT can surpass the performance of Large Transformer on the challenging machine translation En-De and En-Fr datasets. In the hard connection case, the optimal connection pattern found for En-De also leads to improved performance for En-Fr.
AutoClip: Adaptive Gradient Clipping for Source Separation Networks
Jul 25, 2020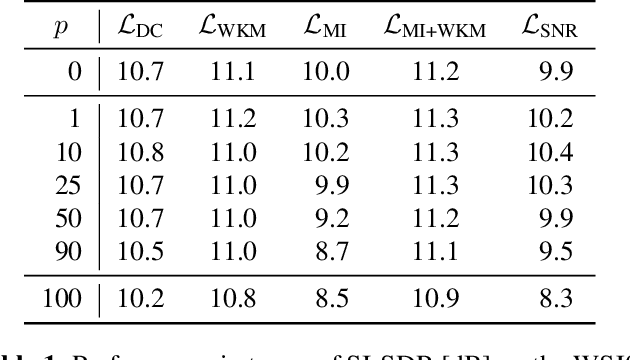
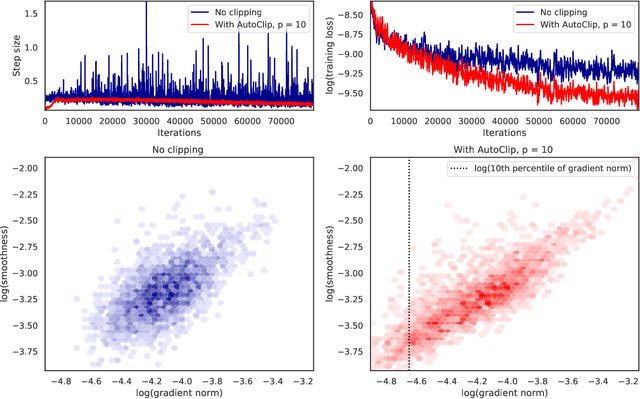
Clipping the gradient is a known approach to improving gradient descent, but requires hand selection of a clipping threshold hyperparameter. We present AutoClip, a simple method for automatically and adaptively choosing a gradient clipping threshold, based on the history of gradient norms observed during training. Experimental results show that applying AutoClip results in improved generalization performance for audio source separation networks. Observation of the training dynamics of a separation network trained with and without AutoClip show that AutoClip guides optimization into smoother parts of the loss landscape. AutoClip is very simple to implement and can be integrated readily into a variety of applications across multiple domains.
Spatio-Temporal Scene Graphs for Video Dialog
Jul 08, 2020
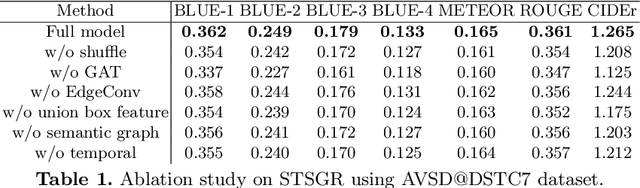
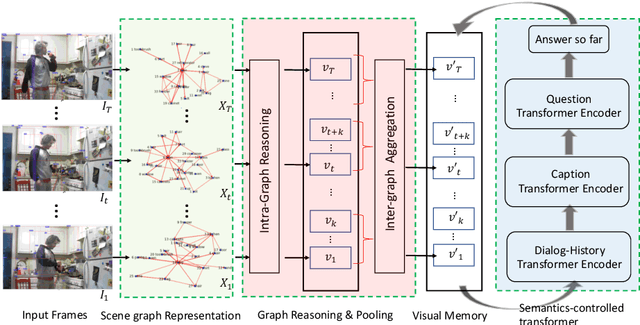
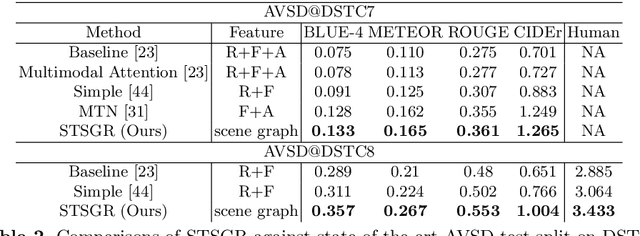
The Audio-Visual Scene-aware Dialog (AVSD) task requires an agent to indulge in a natural conversation with a human about a given video. Specifically, apart from the video frames, the agent receives the audio, brief captions, and a dialog history, and the task is to produce the correct answer to a question about the video. Due to the diversity in the type of inputs, this task poses a very challenging multimodal reasoning problem. Current approaches to AVSD either use global video-level features or those from a few sampled frames, and thus lack the ability to explicitly capture relevant visual regions or their interactions for answer generation. To this end, we propose a novel spatio-temporal scene graph representation (STSGR) modeling fine-grained information flows within videos. Specifically, on an input video sequence, STSGR (i) creates a two-stream visual and semantic scene graph on every frame, (ii) conducts intra-graph reasoning using node and edge convolutions generating visual memories, and (iii) applies inter-graph aggregation to capture their temporal evolutions. These visual memories are then combined with other modalities and the question embeddings using a novel semantics-controlled multi-head shuffled transformer, which then produces the answer recursively. Our entire pipeline is trained end-to-end. We present experiments on the AVSD dataset and demonstrate state-of-the-art results. A human evaluation on the quality of our generated answers shows 12% relative improvement against prior methods.