 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Diffusion Models
Jul 12, 2021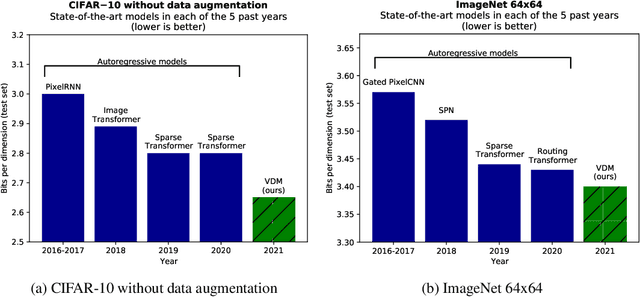
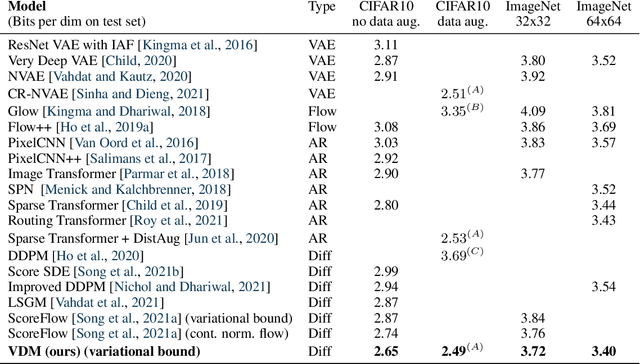

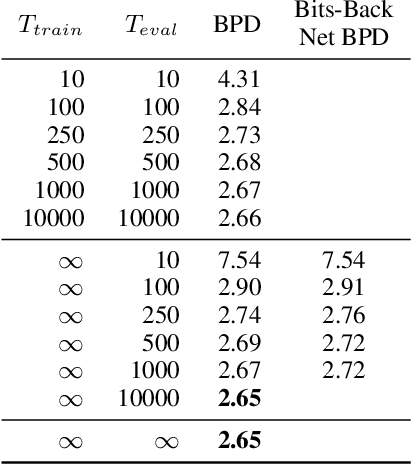
Diffusion-based generative models have demonstrated a capacity for perceptually impressive synthesis, but can they also be great likelihood-based models? We answer this in the affirmative, and introduce a family of diffusion-based generative models that obtain state-of-the-art likelihoods on standard image density estimation benchmarks. Unlike other diffusion-based models, our method allows for efficient optimization of the noise schedule jointly with the rest of the model. We show that the variational lower bound (VLB) simplifies to a remarkably short expression in terms of the signal-to-noise ratio of the diffused data, thereby improving our theoretical understanding of this model class. Using this insight, we prove an equivalence between several models proposed in the literature. In addition, we show that the continuous-time VLB is invariant to the noise schedule, except for the signal-to-noise ratio at its endpoints. This enables us to learn a noise schedule that minimizes the variance of the resulting VLB estimator, leading to faster optimization. Combining these advances with architectural improvements, we obtain state-of-the-art likelihoods on image density estimation benchmarks, outperforming autoregressive models that have dominated these benchmarks for many years, with often significantly faster optimization. In addition, we show how to turn the model into a bits-back compression scheme, and demonstrate lossless compression rates close to the theoretical optimum.
Learning to Efficiently Sample from Diffusion Probabilistic Models
Jun 07, 2021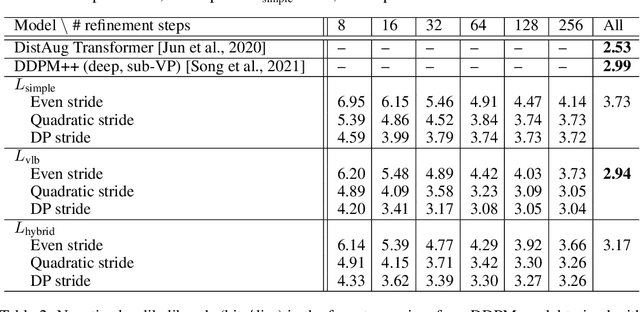
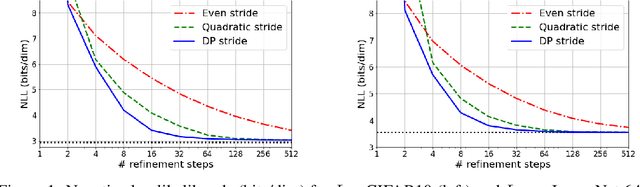
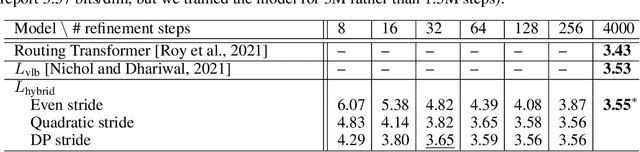
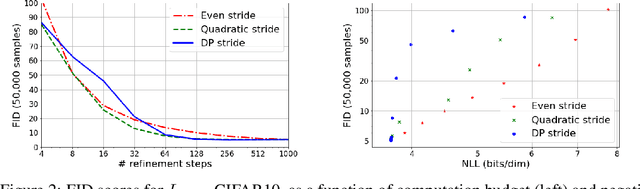
Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a powerful family of generative models that can yield high-fidelity samples and competitive log-likelihoods across a range of domains, including image and speech synthesis. Key advantages of DDPMs include ease of training, in contrast to generative adversarial networks, and speed of generation, in contrast to autoregressive models. However, DDPMs typically require hundreds-to-thousands of steps to generate a high fidelity sample, making them prohibitively expensive for high dimensional problems. Fortunately, DDPMs allow trading generation speed for sample quality through adjusting the number of refinement steps as a post process. Prior work has been successful in improving generation speed through handcrafting the time schedule by trial and error. We instead view the selection of the inference time schedules as an optimization problem, and introduce an exact dynamic programming algorithm that finds the optimal discrete time schedules for any pre-trained DDPM. Our method exploits the fact that ELBO can be decomposed into separate KL terms, and given any computation budget, discovers the time schedule that maximizes the training ELBO exactly. Our method is efficient, has no hyper-parameters of its own, and can be applied to any pre-trained DDPM with no retraining. We discover inference time schedules requiring as few as 32 refinement steps, while sacrificing less than 0.1 bits per dimension compared to the default 4,000 steps used on ImageNet 64x64 [Ho et al., 2020; Nichol and Dhariwal, 2021].
Image Super-Resolution via Iterative Refinement
Apr 15, 2021
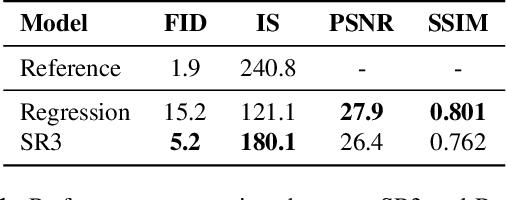
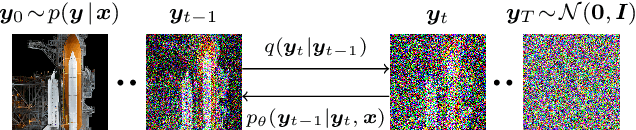

We present SR3, an approach to image Super-Resolution via Repeated Refinement. SR3 adapts denoising diffusion probabilistic models to conditional image generation and performs super-resolution through a stochastic denoising process. Inference starts with pure Gaussian noise and iteratively refines the noisy output using a U-Net model trained on denoising at various noise levels. SR3 exhibits strong performance on super-resolution tasks at different magnification factors, on faces and natural images. We conduct human evaluation on a standard 8X face super-resolution task on CelebA-HQ, comparing with SOTA GAN methods. SR3 achieves a fool rate close to 50%, suggesting photo-realistic outputs, while GANs do not exceed a fool rate of 34%. We further show the effectiveness of SR3 in cascaded image generation, where generative models are chained with super-resolution models, yielding a competitive FID score of 11.3 on ImageNet.
Denoising Diffusion Probabilistic Models
Jun 19, 2020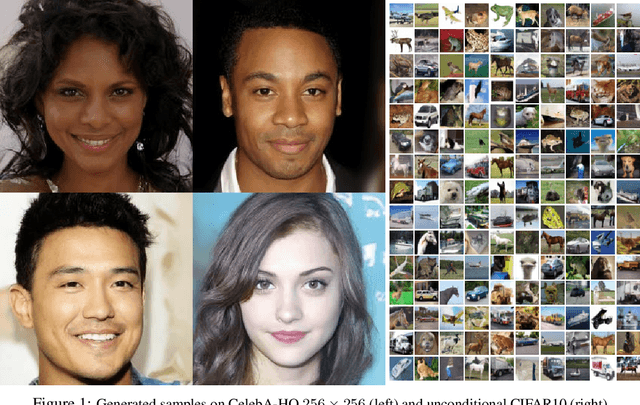
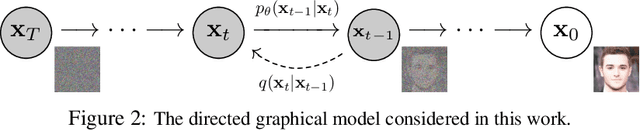
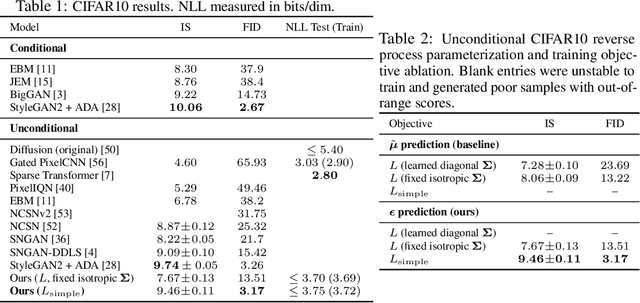

We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound designed according to a novel connection between diffusion probabilistic models and denoising score matching with Langevin dynamics, and our models naturally admit a progressive lossy decompression scheme that can be interpreted as a generalization of autoregressive decoding. On the unconditional CIFAR10 dataset, we obtain an Inception score of 9.46 and a state-of-the-art FID score of 3.17. On 256x256 LSUN, we obtain sample quality similar to ProgressiveGAN. Our implementation is available at https://github.com/hojonathanho/diffusion
Axial Attention in Multidimensional Transformers
Dec 20, 2019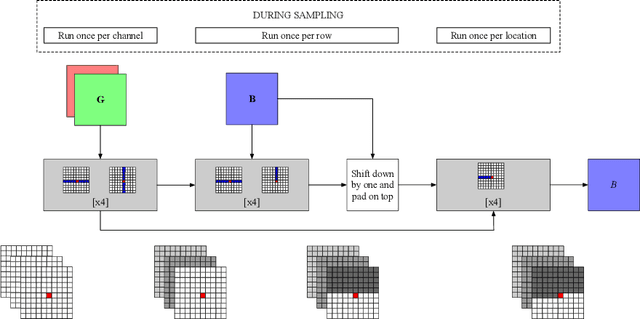

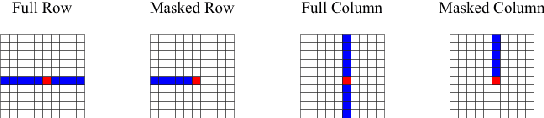
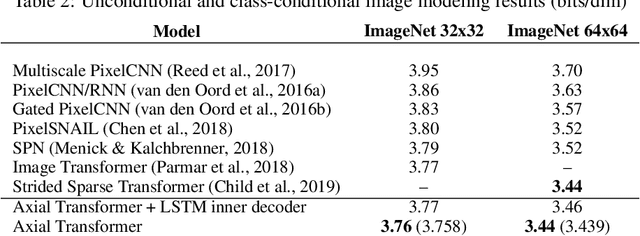
We propose Axial Transformers, a self-attention-based autoregressive model for images and other data organized as high dimensional tensors. Existing autoregressive models either suffer from excessively large computational resource requirements for high dimensional data, or make compromises in terms of distribution expressiveness or ease of implementation in order to decrease resource requirements. Our architecture, by contrast, maintains both full expressiveness over joint distributions over data and ease of implementation with standard deep learning frameworks, while requiring reasonable memory and computation and achieving state-of-the-art results on standard generative modeling benchmarks. Our models are based on axial attention, a simple generalization of self-attention that naturally aligns with the multiple dimensions of the tensors in both the encoding and the decoding settings. Notably the proposed structure of the layers allows for the vast majority of the context to be computed in parallel during decoding without introducing any independence assumptions. This semi-parallel structure goes a long way to making decoding from even a very large Axial Transformer broadly applicable. We demonstrate state-of-the-art results for the Axial Transformer on the ImageNet-32 and ImageNet-64 image benchmarks as well as on the BAIR Robotic Pushing video benchmark. We open source the implementation of Axial Transformers.
Natural Image Manipulation for Autoregressive Models Using Fisher Scores
Nov 25, 2019



Deep autoregressive models are one of the most powerful models that exist today which achieve state-of-the-art bits per dim. However, they lie at a strict disadvantage when it comes to controlled sample generation compared to latent variable models. Latent variable models such as VAEs and normalizing flows allow meaningful semantic manipulations in latent space, which autoregressive models do not have. In this paper, we propose using Fisher scores as a method to extract embeddings from an autoregressive model to use for interpolation and show that our method provides more meaningful sample manipulation compared to alternate embeddings such as network activations.
Bit-Swap: Recursive Bits-Back Coding for Lossless Compression with Hierarchical Latent Variables
Jun 05, 2019

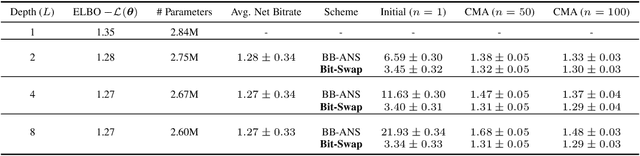
The bits-back argument suggests that latent variable models can be turned into lossless compression schemes. Translating the bits-back argument into efficient and practical lossless compression schemes for general latent variable models, however, is still an open problem. Bits-Back with Asymmetric Numeral Systems (BB-ANS), recently proposed by Townsend et al. (2019), makes bits-back coding practically feasible for latent variable models with one latent layer, but it is inefficient for hierarchical latent variable models. In this paper we propose Bit-Swap, a new compression scheme that generalizes BB-ANS and achieves strictly better compression rates for hierarchical latent variable models with Markov chain structure. Through experiments we verify that Bit-Swap results in lossless compression rates that are empirically superior to existing techniques. Our implementation is available at https://github.com/fhkingma/bitswap.
Compression with Flows via Local Bits-Back Coding
May 22, 2019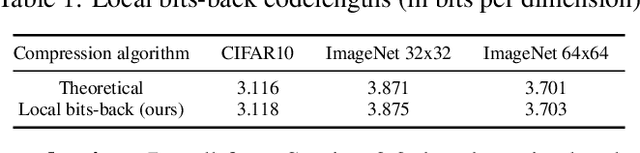
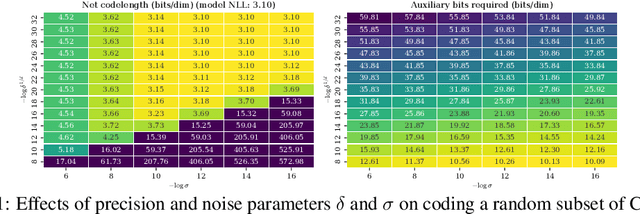
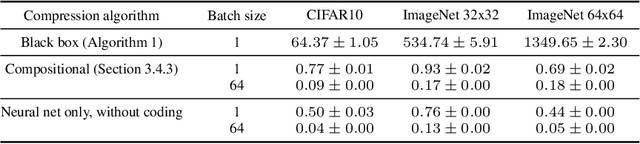
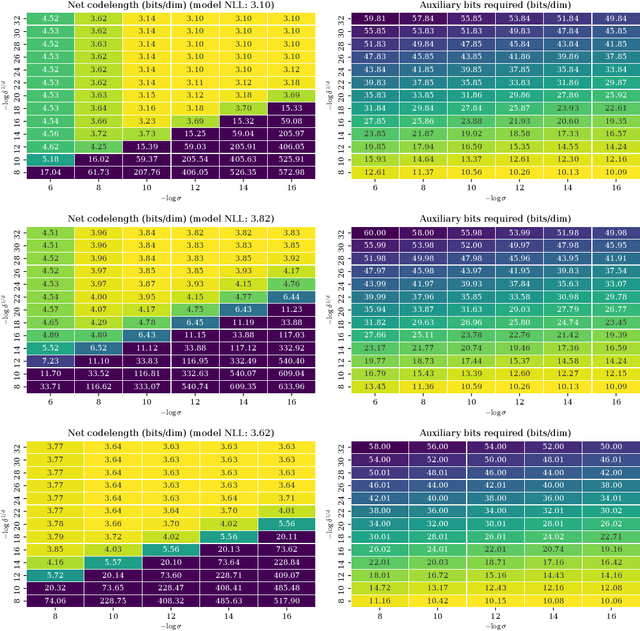
Likelihood-based generative models are the backbones of lossless compression, due to the guaranteed existence of codes with lengths close to negative log likelihood. However, there is no guaranteed existence of computationally efficient codes that achieve these lengths, and coding algorithms must be hand-tailored to specific types of generative models to ensure computational efficiency. Such coding algorithms are known for autoregressive models and variational autoencoders, but not for general types of flow models. To fill in this gap, we introduce local bits-back coding, a new compression technique compatible with flow models. We present efficient algorithms that instantiate our technique for many popular types of flows, and we demonstrate that our algorithms closely achieve theoretical codelengths for state-of-the-art flow models on high-dimensional data.
Flow++: Improving Flow-Based Generative Models with Variational Dequantization and Architecture Design
Feb 01, 2019



Flow-based generative models are powerful exact likelihood models with efficient sampling and inference. Despite their computational efficiency, flow-based models generally have much worse density modeling performance compared to state-of-the-art autoregressive models. In this paper, we investigate and improve upon three limiting design choices employed by flow-based models in prior work: the use of uniform noise for dequantization, the use of inexpressive affine flows, and the use of purely convolutional conditioning networks in coupling layers. Based on our findings, we propose Flow++, a new flow-based model that is now the state-of-the-art non-autoregressive model for unconditional density estimation on standard image benchmarks. Our work has begun to close the significant performance gap that has so far existed between autoregressive models and flow-based models. Our implementation is available at https://github.com/aravind0706/flowpp.
Evolved Policy Gradients
Apr 29, 2018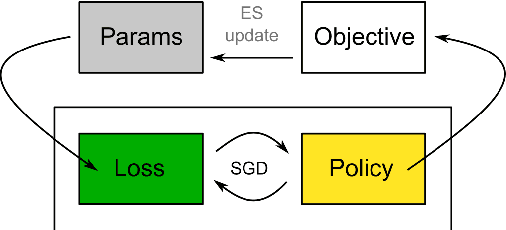

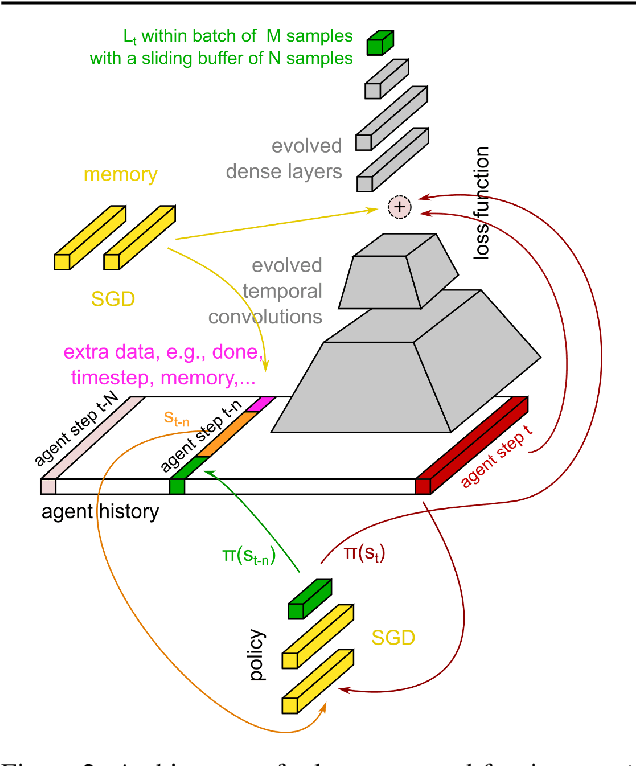

We propose a metalearning approach for learning gradient-based reinforcement learning (RL) algorithms. The idea is to evolve a differentiable loss function, such that an agent, which optimizes its policy to minimize this loss, will achieve high rewards. The loss is parametrized via temporal convolutions over the agent's experience. Because this loss is highly flexible in its ability to take into account the agent's history, it enables fast task learning. Empirical results show that our evolved policy gradient algorithm (EPG) achieves faster learning on several randomized environments compared to an off-the-shelf policy gradient method. We also demonstrate that EPG's learned loss can generalize to out-of-distribution test time tasks, and exhibits qualitatively different behavior from other popular metalearning algorithms.