 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiSCo: Diffusion Sequence Copilots for Shared Autonomy
Mar 24, 2026Shared autonomy combines human user and AI copilot actions to control complex systems such as robotic arms. When a task is challenging, requires high dimensional control, or is subject to corruption, shared autonomy can significantly increase task performance by using a trained copilot to effectively correct user actions in a manner consistent with the user's goals. To significantly improve the performance of shared autonomy, we introduce Diffusion Sequence Copilots (DiSCo): a method of shared autonomy with diffusion policy that plans action sequences consistent with past user actions. DiSCo seeds and inpaints the diffusion process with user-provided actions with hyperparameters to balance conformity to expert actions, alignment with user intent, and perceived responsiveness. We demonstrate that DiSCo substantially improves task performance in simulated driving and robotic arm tasks. Project website: https://sites.google.com/view/disco-shared-autonomy/
Flattening Hierarchies with Policy Bootstrapping
May 20, 2025



Offline goal-conditioned reinforcement learning (GCRL) is a promising approach for pretraining generalist policies on large datasets of reward-free trajectories, akin to the self-supervised objectives used to train foundation models for computer vision and natural language processing. However, scaling GCRL to longer horizons remains challenging due to the combination of sparse rewards and discounting, which obscures the comparative advantages of primitive actions with respect to distant goals. Hierarchical RL methods achieve strong empirical results on long-horizon goal-reaching tasks, but their reliance on modular, timescale-specific policies and subgoal generation introduces significant additional complexity and hinders scaling to high-dimensional goal spaces. In this work, we introduce an algorithm to train a flat (non-hierarchical) goal-conditioned policy by bootstrapping on subgoal-conditioned policies with advantage-weighted importance sampling. Our approach eliminates the need for a generative model over the (sub)goal space, which we find is key for scaling to high-dimensional control in large state spaces. We further show that existing hierarchical and bootstrapping-based approaches correspond to specific design choices within our derivation. Across a comprehensive suite of state- and pixel-based locomotion and manipulation benchmarks, our method matches or surpasses state-of-the-art offline GCRL algorithms and scales to complex, long-horizon tasks where prior approaches fail.
Reciprocal Reward Influence Encourages Cooperation From Self-Interested Agents
Jun 03, 2024



Emergent cooperation among self-interested individuals is a widespread phenomenon in the natural world, but remains elusive in interactions between artificially intelligent agents. Instead, na\"ive reinforcement learning algorithms typically converge to Pareto-dominated outcomes in even the simplest of social dilemmas. An emerging class of opponent-shaping methods have demonstrated the ability to reach prosocial outcomes by influencing the learning of other agents. However, they rely on higher-order derivatives through the predicted learning step of other agents or learning meta-game dynamics, which in turn rely on stringent assumptions over opponent learning rules or exponential sample complexity, respectively. To provide a learning rule-agnostic and sample-efficient alternative, we introduce Reciprocators, reinforcement learning agents which are intrinsically motivated to reciprocate the influence of an opponent's actions on their returns. This approach effectively seeks to modify other agents' $Q$-values by increasing their return following beneficial actions (with respect to the Reciprocator) and decreasing it after detrimental actions, guiding them towards mutually beneficial actions without attempting to directly shape policy updates. We show that Reciprocators can be used to promote cooperation in a variety of temporally extended social dilemmas during simultaneous learning.
What Are Large Language Models Mapping to in the Brain? A Case Against Over-Reliance on Brain Scores
Jun 03, 2024



Given the remarkable capabilities of large language models (LLMs), there has been a growing interest in evaluating their similarity to the human brain. One approach towards quantifying this similarity is by measuring how well a model predicts neural signals, also called "brain score". Internal representations from LLMs achieve state-of-the-art brain scores, leading to speculation that they share computational principles with human language processing. This inference is only valid if the subset of neural activity predicted by LLMs reflects core elements of language processing. Here, we question this assumption by analyzing three neural datasets used in an impactful study on LLM-to-brain mappings, with a particular focus on an fMRI dataset where participants read short passages. We first find that when using shuffled train-test splits, as done in previous studies with these datasets, a trivial feature that encodes temporal autocorrelation not only outperforms LLMs but also accounts for the majority of neural variance that LLMs explain. We therefore use contiguous splits moving forward. Second, we explain the surprisingly high brain scores of untrained LLMs by showing they do not account for additional neural variance beyond two simple features: sentence length and sentence position. This undermines evidence used to claim that the transformer architecture biases computations to be more brain-like. Third, we find that brain scores of trained LLMs on this dataset can largely be explained by sentence length, position, and pronoun-dereferenced static word embeddings; a small, additional amount is explained by sense-specific embeddings and contextual representations of sentence structure. We conclude that over-reliance on brain scores can lead to over-interpretations of similarity between LLMs and brains, and emphasize the importance of deconstructing what LLMs are mapping to in neural signals.
Usable Information and Evolution of Optimal Representations During Training
Oct 06, 2020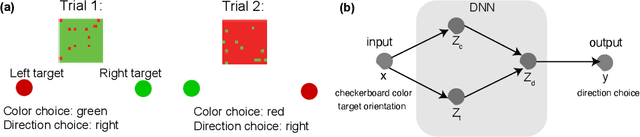
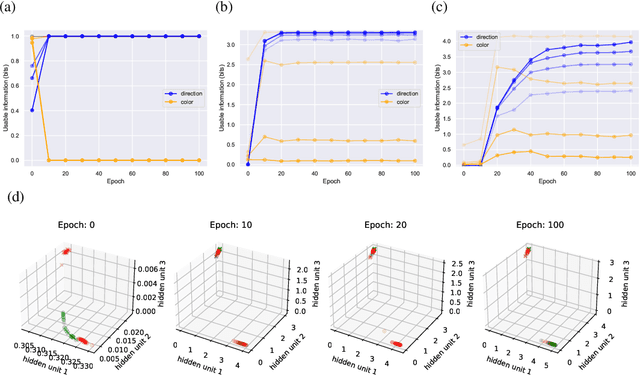
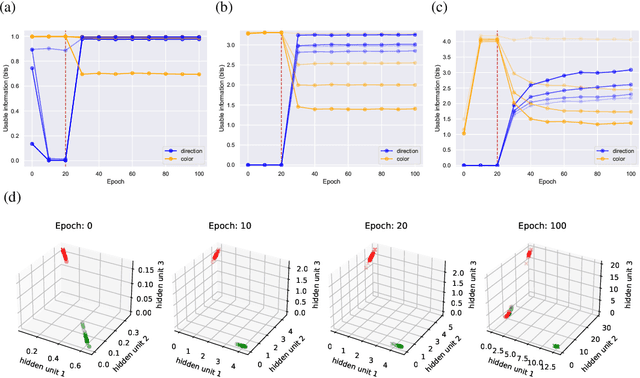
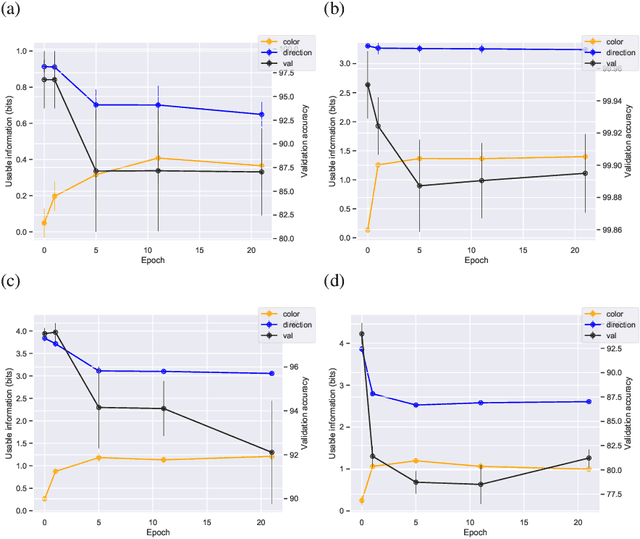
We introduce a notion of usable information contained in the representation learned by a deep network, and use it to study how optimal representations for the task emerge during training, and how they adapt to different tasks. We use this to characterize the transient dynamics of deep neural networks on perceptual decision-making tasks inspired by neuroscience literature. In particular, we show that both the random initialization and the implicit regularization from Stochastic Gradient Descent play an important role in learning minimal sufficient representations for the task. If the network is not randomly initialized, we show that the training may not recover an optimal representation, increasing the chance of overfitting.
Making brain-machine interfaces robust to future neural variability
Oct 19, 2016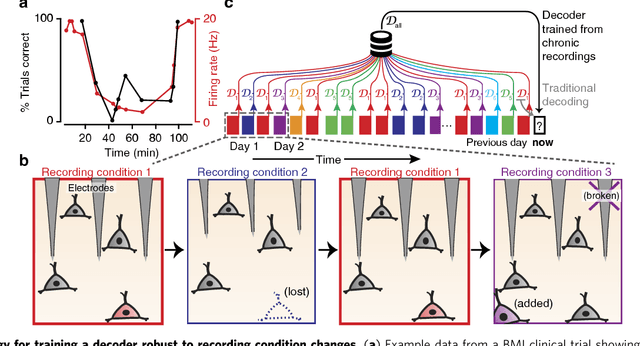
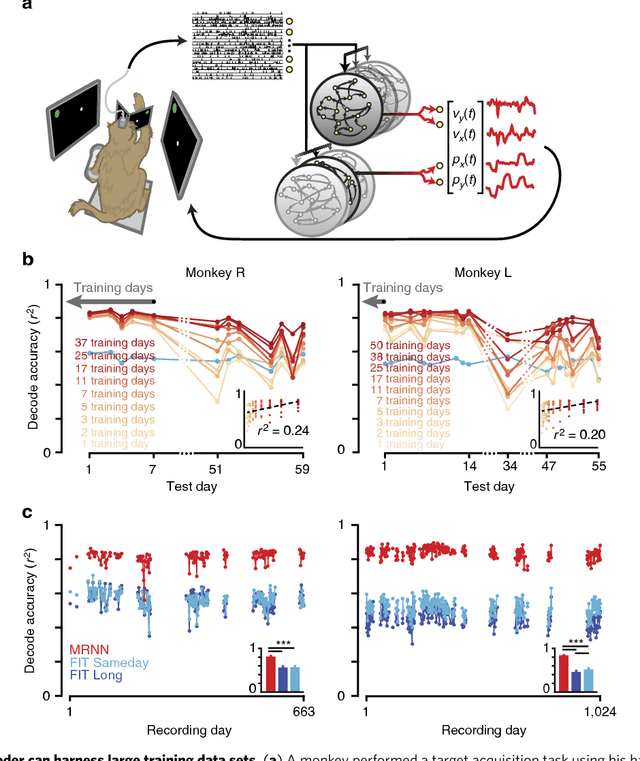
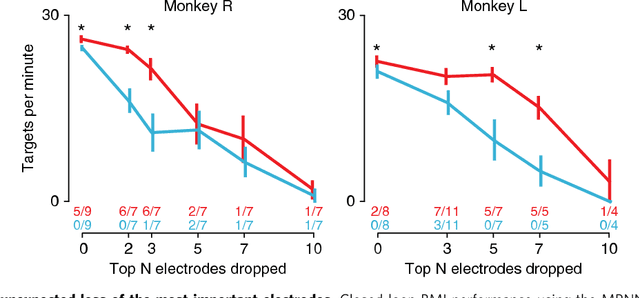
A major hurdle to clinical translation of brain-machine interfaces (BMIs) is that current decoders, which are trained from a small quantity of recent data, become ineffective when neural recording conditions subsequently change. We tested whether a decoder could be made more robust to future neural variability by training it to handle a variety of recording conditions sampled from months of previously collected data as well as synthetic training data perturbations. We developed a new multiplicative recurrent neural network BMI decoder that successfully learned a large variety of neural-to- kinematic mappings and became more robust with larger training datasets. When tested with a non-human primate preclinical BMI model, this decoder was robust under conditions that disabled a state-of-the-art Kalman filter based decoder. These results validate a new BMI strategy in which accumulated data history is effectively harnessed, and may facilitate reliable daily BMI use by reducing decoder retraining downtime.
* D.S., S.D.S., and J.C.K. contributed equally to this work