 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Scene Graphs
Mar 26, 2019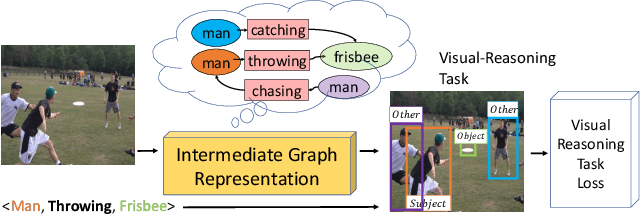
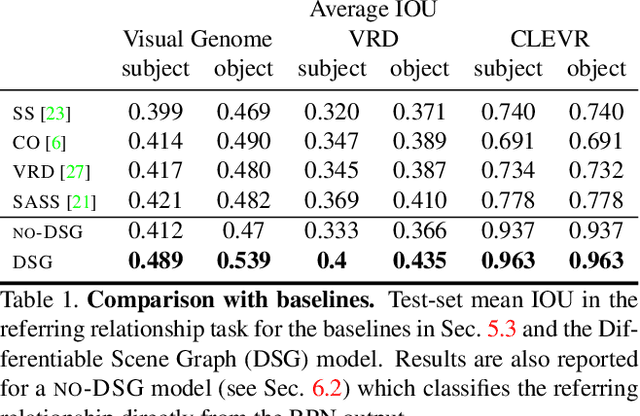
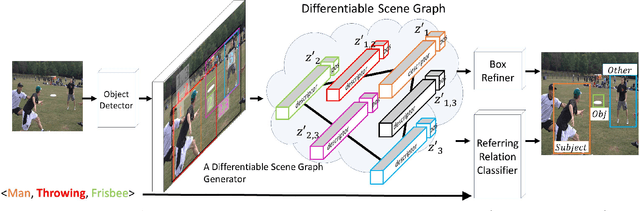
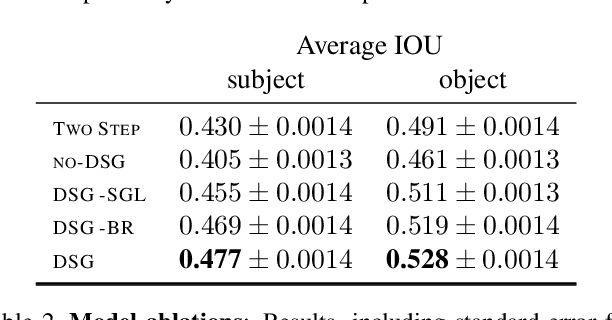
Understanding the semantics of complex visual scenes involves perception of entities and reasoning about their relations. Scene graphs provide a natural representation for these tasks, by assigning labels to both entities (nodes) and relations (edges). However, scene graphs are not commonly used as intermediate components in visual reasoning systems, for two complementary reasons. First, training models to map images to scene graphs requires prohibitive manual annotation, and results in graphs that often do not match the needs of a downstream visual reasoning application. Second, using these discrete graphs as an intermediate latent representation results in a non-differentiable function that is difficult to optimize. Here we propose Differentiable Scene Graphs (DSGs), an image representation that is amenable to differentiable end-to-end optimization, and requires supervision only from the downstream tasks. DSGs provide a dense representation for all regions and pairs of regions, investing model capacity on the important aspects of the image. We describe a multi-task objective function that allows us to learn this representation from indirect supervision only, provided by the downstream task. We evaluate our model on the challenging task of identifying referring relationships, and show that training DSGs using our multi-task objective leads to new state-of-the-art performance.
DiscoFuse: A Large-Scale Dataset for Discourse-Based Sentence Fusion
Mar 18, 2019
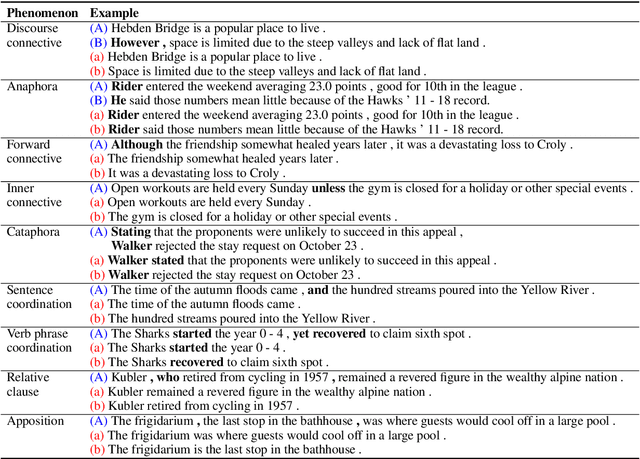
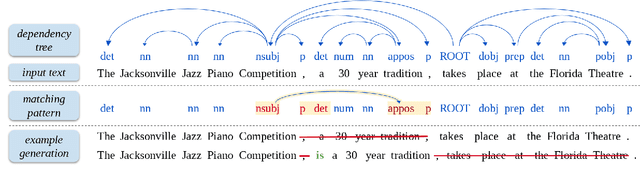

Sentence fusion is the task of joining several independent sentences into a single coherent text. Current datasets for sentence fusion are small and insufficient for training modern neural models. In this paper, we propose a method for automatically-generating fusion examples from raw text and present DiscoFuse, a large scale dataset for discourse-based sentence fusion. We author a set of rules for identifying a diverse set of discourse phenomena in raw text, and decomposing the text into two independent sentences. We apply our approach on two document collections: Wikipedia and Sports articles, yielding 60 million fusion examples annotated with discourse information required to reconstruct the fused text. We develop a sequence-to-sequence model on DiscoFuse and thoroughly analyze its strengths and weaknesses with respect to the various discourse phenomena, using both automatic as well as human evaluation. Finally, we conduct transfer learning experiments with WebSplit, a recent dataset for text simplification. We show that pretraining on DiscoFuse substantially improves performance on WebSplit when viewed as a sentence fusion task.
Neural network gradient-based learning of black-box function interfaces
Jan 13, 2019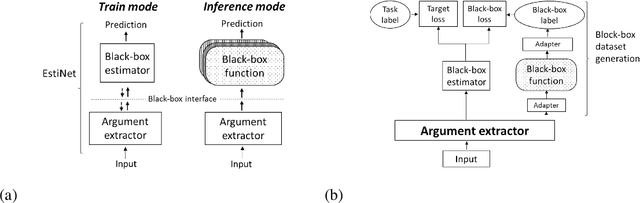
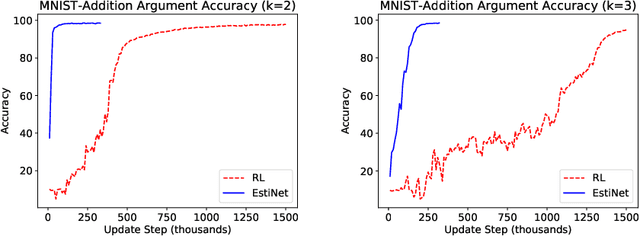

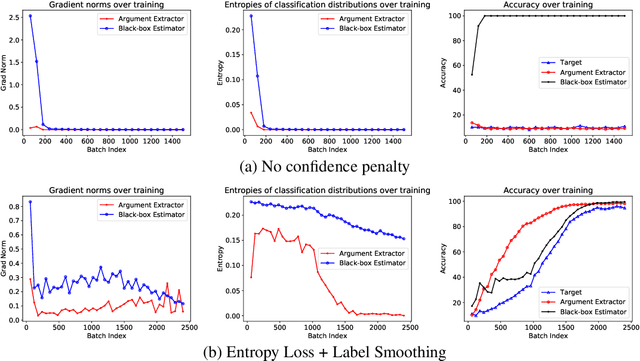
Deep neural networks work well at approximating complicated functions when provided with data and trained by gradient descent methods. At the same time, there is a vast amount of existing functions that programmatically solve different tasks in a precise manner eliminating the need for training. In many cases, it is possible to decompose a task to a series of functions, of which for some we may prefer to use a neural network to learn the functionality, while for others the preferred method would be to use existing black-box functions. We propose a method for end-to-end training of a base neural network that integrates calls to existing black-box functions. We do so by approximating the black-box functionality with a differentiable neural network in a way that drives the base network to comply with the black-box function interface during the end-to-end optimization process. At inference time, we replace the differentiable estimator with its external black-box non-differentiable counterpart such that the base network output matches the input arguments of the black-box function. Using this "Estimate and Replace" paradigm, we train a neural network, end to end, to compute the input to black-box functionality while eliminating the need for intermediate labels. We show that by leveraging the existing precise black-box function during inference, the integrated model generalizes better than a fully differentiable model, and learns more efficiently compared to RL-based methods.
Value-based Search in Execution Space for Mapping Instructions to Programs
Nov 02, 2018

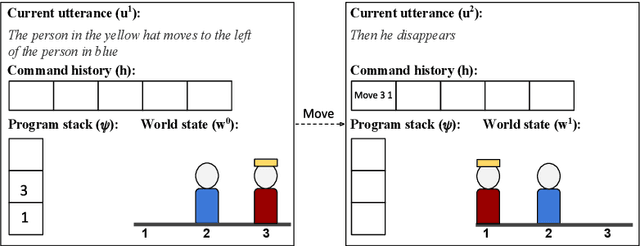

Training models to map natural language instructions to programs given target world supervision only requires searching for good programs at training time. Search is commonly done using beam search in the space of partial programs or program trees, but as the length of the instructions grows finding a good program becomes difficult. In this work, we propose a search algorithm that uses the target world state, known at training time, to train a critic network that predicts the expected reward of every search state. We then score search states on the beam by interpolating their expected reward with the likelihood of programs represented by the search state. Moreover, we search not in the space of programs but in a more compressed state of program executions, augmented with recent entities and actions. On the SCONE dataset, we show that our algorithm dramatically improves performance on all three domains compared to standard beam search and other baselines.
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Nov 02, 2018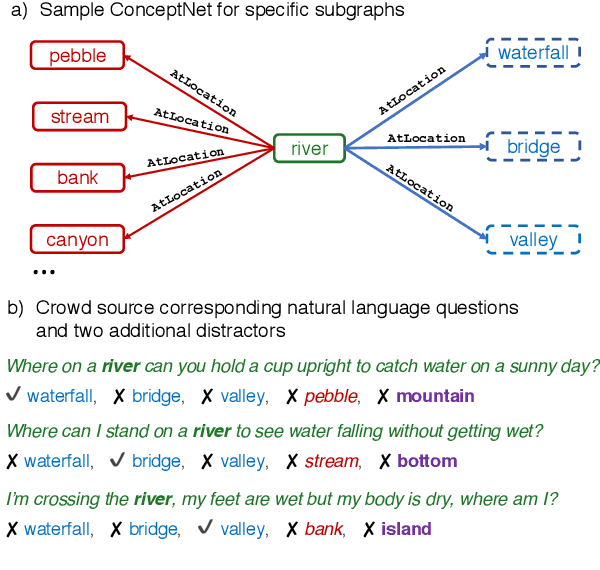

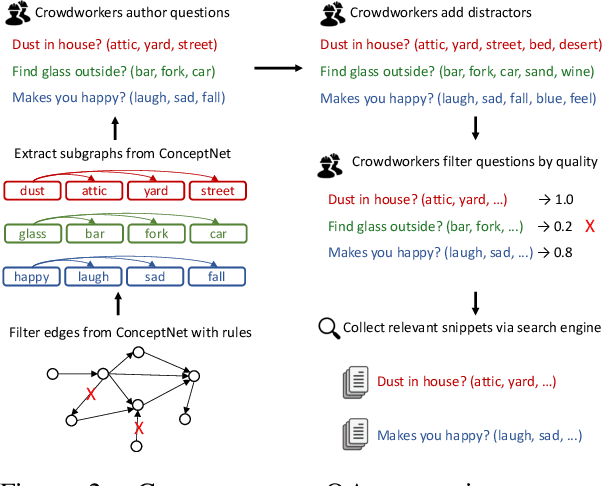

When answering a question, people often draw upon their rich world knowledge in addition to some task-specific context. Recent work has focused primarily on answering questions based on some relevant document or content, and required very little general background. To investigate question answering with prior knowledge, we present CommonsenseQA: a difficult new dataset for commonsense question answering. To capture common sense beyond associations, each question discriminates between three target concepts that all share the same relationship to a single source drawn from ConceptNet (Speer et al., 2017). This constraint encourages crowd workers to author multiple-choice questions with complex semantics, in which all candidates relate to the subject in a similar way. We create 9,500 questions through this procedure and demonstrate the dataset's difficulty with a large number of strong baselines. Our best baseline, the OpenAI GPT (Radford et al., 2018), obtains 54.8% accuracy, well below human performance, which is 95.3%.
Mapping Images to Scene Graphs with Permutation-Invariant Structured Prediction
Nov 01, 2018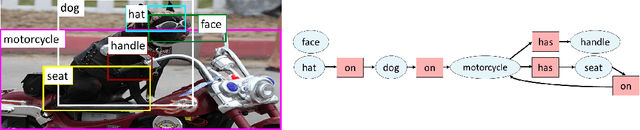
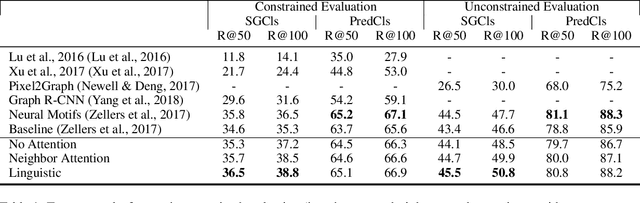
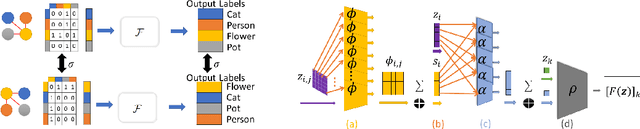
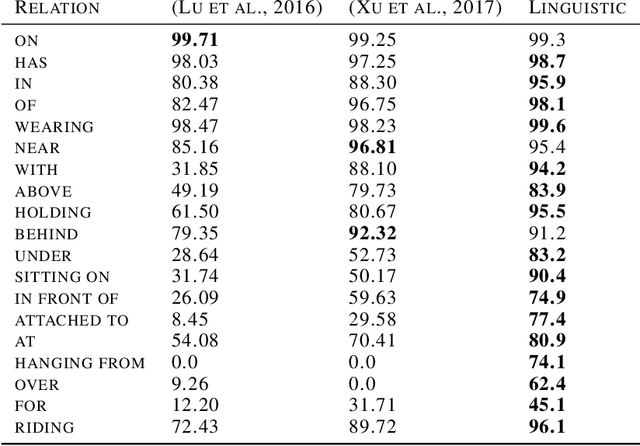
Machine understanding of complex images is a key goal of artificial intelligence. One challenge underlying this task is that visual scenes contain multiple inter-related objects, and that global context plays an important role in interpreting the scene. A natural modeling framework for capturing such effects is structured prediction, which optimizes over complex labels, while modeling within-label interactions. However, it is unclear what principles should guide the design of a structured prediction model that utilizes the power of deep learning components. Here we propose a design principle for such architectures that follows from a natural requirement of permutation invariance. We prove a necessary and sufficient characterization for architectures that follow this invariance, and discuss its implication on model design. Finally, we show that the resulting model achieves new state of the art results on the Visual Genome scene graph labeling benchmark, outperforming all recent approaches.
Memory Augmented Policy Optimization for Program Synthesis and Semantic Parsing
Oct 31, 2018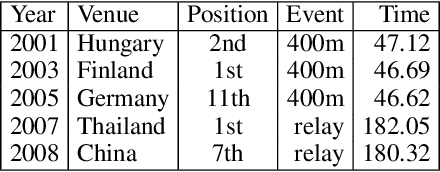
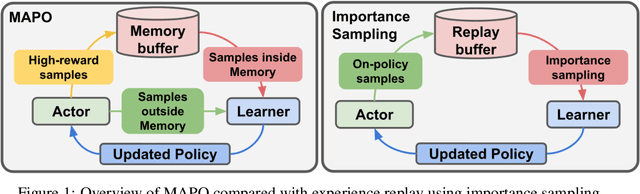
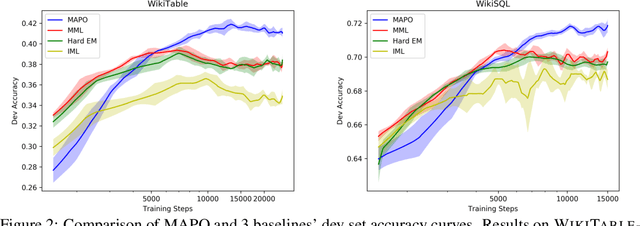

We present Memory Augmented Policy Optimization (MAPO), a simple and novel way to leverage a memory buffer of promising trajectories to reduce the variance of policy gradient estimate. MAPO is applicable to deterministic environments with discrete actions, such as structured prediction and combinatorial optimization tasks. We express the expected return objective as a weighted sum of two terms: an expectation over the high-reward trajectories inside the memory buffer, and a separate expectation over trajectories outside the buffer. To make an efficient algorithm of MAPO, we propose: (1) memory weight clipping to accelerate and stabilize training; (2) systematic exploration to discover high-reward trajectories; (3) distributed sampling from inside and outside of the memory buffer to scale up training. MAPO improves the sample efficiency and robustness of policy gradient, especially on tasks with sparse rewards. We evaluate MAPO on weakly supervised program synthesis from natural language (semantic parsing). On the WikiTableQuestions benchmark, we improve the state-of-the-art by 2.6%, achieving an accuracy of 46.3%. On the WikiSQL benchmark, MAPO achieves an accuracy of 74.9% with only weak supervision, outperforming several strong baselines with full supervision. Our source code is available at https://github.com/crazydonkey200/neural-symbolic-machines
Evaluating Text GANs as Language Models
Oct 30, 2018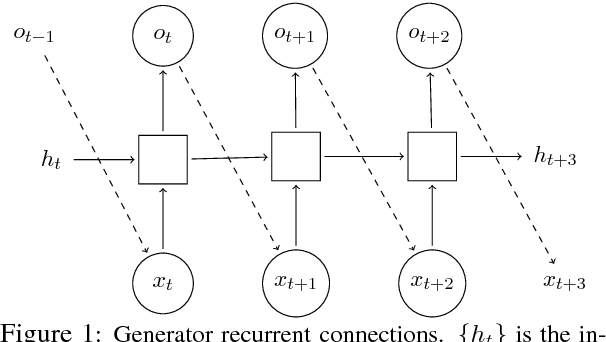

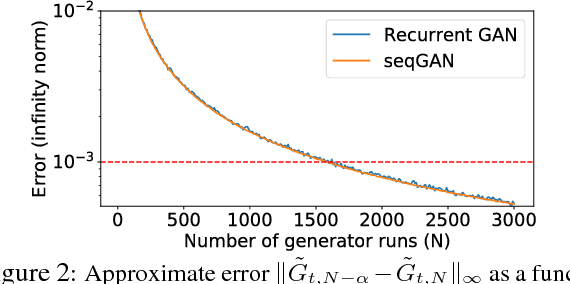
Generative Adversarial Networks (GANs) are a promising approach for text generation that, unlike traditional language models (LM), does not suffer from the problem of "exposure bias". However, A major hurdle for understanding the potential of GANs for text generation is the lack of a clear evaluation metric. In this work, we propose to approximate the distribution of text generated by a GAN, which permits evaluating them with traditional probability-based LM metrics. We apply our approximation procedure on several GAN-based models and show that they currently perform substantially worse than state-of-the-art LMs. Our evaluation procedure promotes better understanding of the relation between GANs and LMs, and can accelerate progress in GAN-based text generation.
Decoupling Structure and Lexicon for Zero-Shot Semantic Parsing
Sep 22, 2018
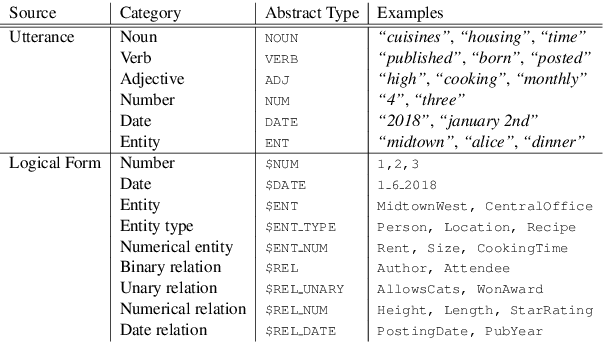
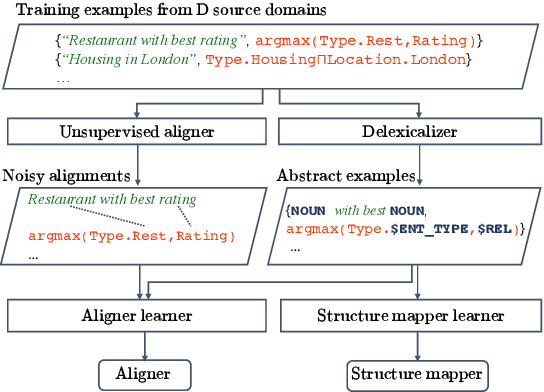

Building a semantic parser quickly in a new domain is a fundamental challenge for conversational interfaces, as current semantic parsers require expensive supervision and lack the ability to generalize to new domains. In this paper, we introduce a zero-shot approach to semantic parsing that can parse utterances in unseen domains while only being trained on examples in other source domains. First, we map an utterance to an abstract, domain-independent, logical form that represents the structure of the logical form, but contains slots instead of KB constants. Then, we replace slots with KB constants via lexical alignment scores and global inference. Our model reaches an average accuracy of 53.4% on 7 domains in the Overnight dataset, substantially better than other zero-shot baselines, and performs as good as a parser trained on over 30% of the target domain examples.
Learning to Search in Long Documents Using Document Structure
Sep 10, 2018
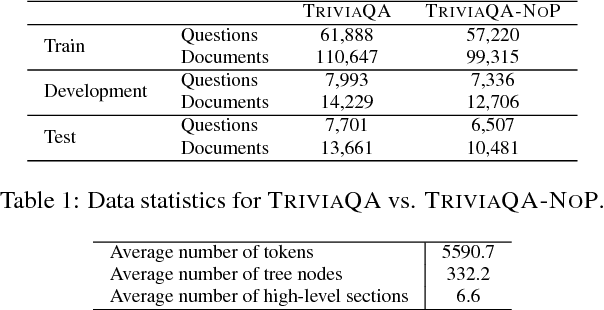
Reading comprehension models are based on recurrent neural networks that sequentially process the document tokens. As interest turns to answering more complex questions over longer documents, sequential reading of large portions of text becomes a substantial bottleneck. Inspired by how humans use document structure, we propose a novel framework for reading comprehension. We represent documents as trees, and model an agent that learns to interleave quick navigation through the document tree with more expensive answer extraction. To encourage exploration of the document tree, we propose a new algorithm, based on Deep Q-Network (DQN), which strategically samples tree nodes at training time. Empirically we find our algorithm improves question answering performance compared to DQN and a strong information-retrieval (IR) baseline, and that ensembling our model with the IR baseline results in further gains in performance.