 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Mapping of Natural Language to SQL through Question Decomposition
Dec 12, 2021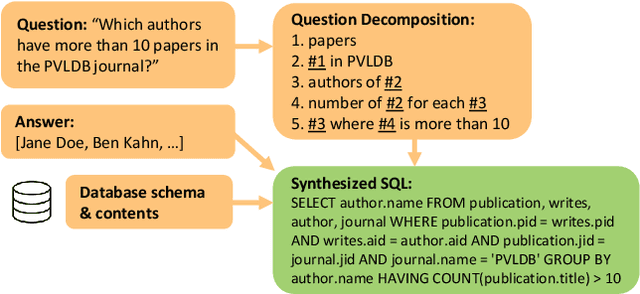
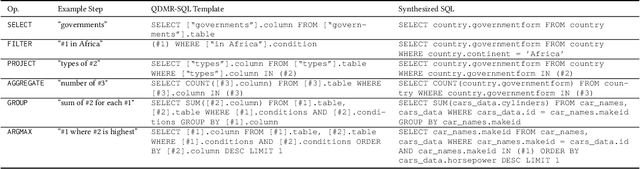
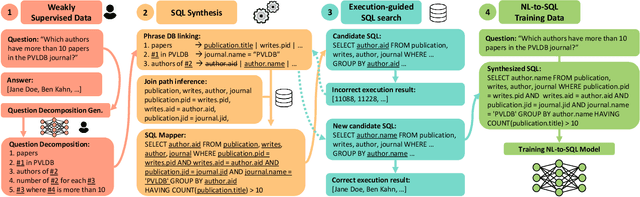

Natural Language Interfaces to Databases (NLIDBs), where users pose queries in Natural Language (NL), are crucial for enabling non-experts to gain insights from data. Developing such interfaces, by contrast, is dependent on experts who often code heuristics for mapping NL to SQL. Alternatively, NLIDBs based on machine learning models rely on supervised examples of NL to SQL mappings (NL-SQL pairs) used as training data. Such examples are again procured using experts, which typically involves more than a one-off interaction. Namely, each data domain in which the NLIDB is deployed may have different characteristics and therefore require either dedicated heuristics or domain-specific training examples. To this end, we propose an alternative approach for training machine learning-based NLIDBs, using weak supervision. We use the recently proposed question decomposition representation called QDMR, an intermediate between NL and formal query languages. Recent work has shown that non-experts are generally successful in translating NL to QDMR. We consequently use NL-QDMR pairs, along with the question answers, as supervision for automatically synthesizing SQL queries. The NL questions and synthesized SQL are then used to train NL-to-SQL models, which we test on five benchmark datasets. Extensive experiments show that our solution, requiring zero expert annotations, performs competitively with models trained on expert annotated data.
COVR: A test-bed for Visually Grounded Compositional Generalization with real images
Sep 22, 2021
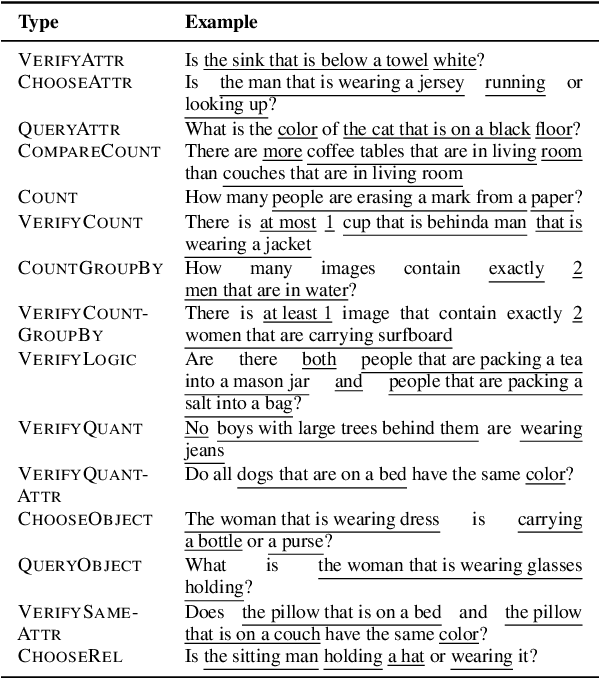
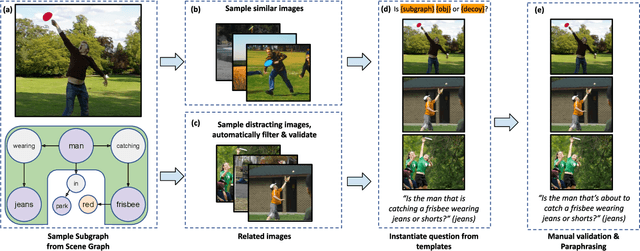
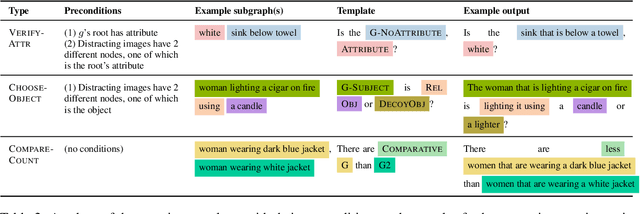
While interest in models that generalize at test time to new compositions has risen in recent years, benchmarks in the visually-grounded domain have thus far been restricted to synthetic images. In this work, we propose COVR, a new test-bed for visually-grounded compositional generalization with real images. To create COVR, we use real images annotated with scene graphs, and propose an almost fully automatic procedure for generating question-answer pairs along with a set of context images. COVR focuses on questions that require complex reasoning, including higher-order operations such as quantification and aggregation. Due to the automatic generation process, COVR facilitates the creation of compositional splits, where models at test time need to generalize to new concepts and compositions in a zero- or few-shot setting. We construct compositional splits using COVR and demonstrate a myriad of cases where state-of-the-art pre-trained language-and-vision models struggle to compositionally generalize.
Finding needles in a haystack: Sampling Structurally-diverse Training Sets from Synthetic Data for Compositional Generalization
Sep 06, 2021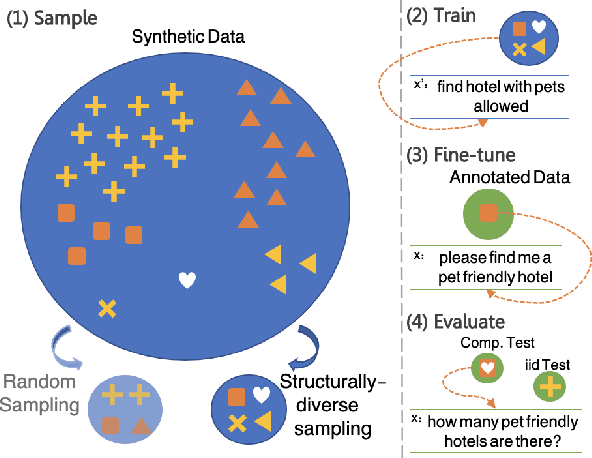



Modern semantic parsers suffer from two principal limitations. First, training requires expensive collection of utterance-program pairs. Second, semantic parsers fail to generalize at test time to new compositions/structures that have not been observed during training. Recent research has shown that automatic generation of synthetic utterance-program pairs can alleviate the first problem, but its potential for the second has thus far been under-explored. In this work, we investigate automatic generation of synthetic utterance-program pairs for improving compositional generalization in semantic parsing. Given a small training set of annotated examples and an "infinite" pool of synthetic examples, we select a subset of synthetic examples that are structurally-diverse and use them to improve compositional generalization. We evaluate our approach on a new split of the schema2QA dataset, and show that it leads to dramatic improvements in compositional generalization as well as moderate improvements in the traditional i.i.d setup. Moreover, structurally-diverse sampling achieves these improvements with as few as 5K examples, compared to 1M examples when sampling uniformly at random -- a 200x improvement in data efficiency.
Break, Perturb, Build: Automatic Perturbation of Reasoning Paths through Question Decomposition
Jul 29, 2021
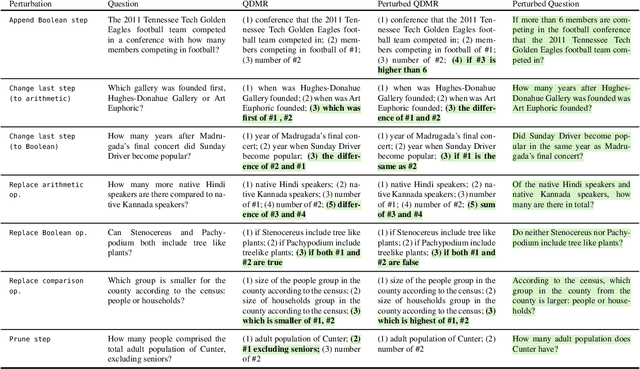


Recent efforts to create challenge benchmarks that test the abilities of natural language understanding models have largely depended on human annotations. In this work, we introduce the "Break, Perturb, Build" (BPB) framework for automatic reasoning-oriented perturbation of question-answer pairs. BPB represents a question by decomposing it into the reasoning steps that are required to answer it, symbolically perturbs the decomposition, and then generates new question-answer pairs. We demonstrate the effectiveness of BPB by creating evaluation sets for three reading comprehension (RC) benchmarks, generating thousands of high-quality examples without human intervention. We evaluate a range of RC models on our evaluation sets, which reveals large performance gaps on generated examples compared to the original data. Moreover, symbolic perturbations enable fine-grained analysis of the strengths and limitations of models. Last, augmenting the training data with examples generated by BPB helps close performance gaps, without any drop on the original data distribution.
Turning Tables: Generating Examples from Semi-structured Tables for Endowing Language Models with Reasoning Skills
Jul 15, 2021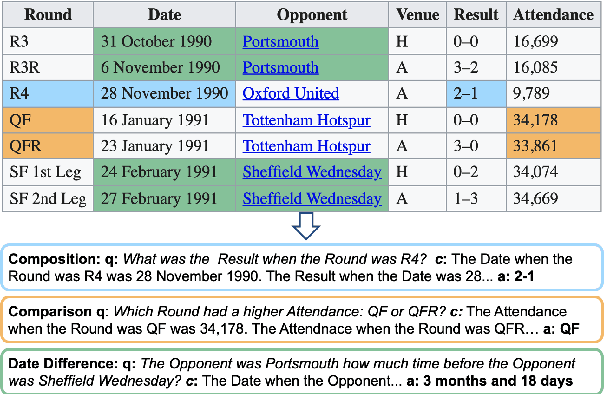
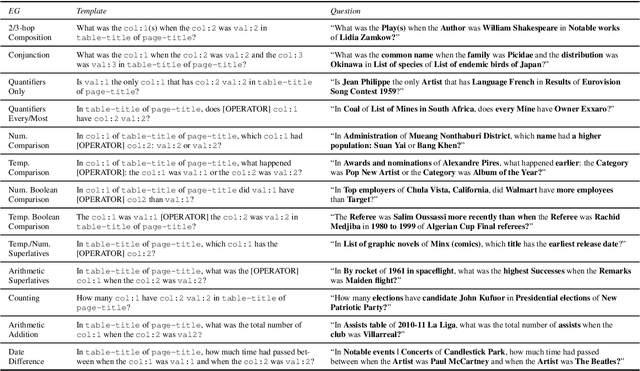
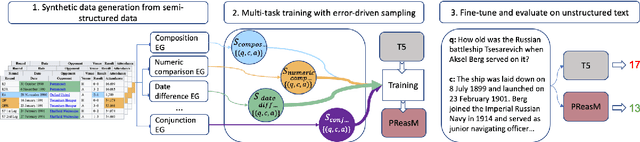
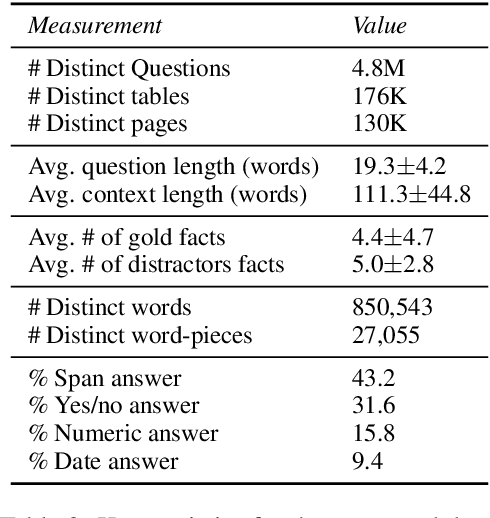
Models pre-trained with a language modeling objective possess ample world knowledge and language skills, but are known to struggle in tasks that require reasoning. In this work, we propose to leverage semi-structured tables, and automatically generate at scale question-paragraph pairs, where answering the question requires reasoning over multiple facts in the paragraph. We add a pre-training step over this synthetic data, which includes examples that require 16 different reasoning skills such as number comparison, conjunction, and fact composition. To improve data efficiency, we propose sampling strategies that focus training on reasoning skills the model is currently lacking. We evaluate our approach on three reading comprehension datasets that are focused on reasoning, and show that our model, PReasM, substantially outperforms T5, a popular pre-trained encoder-decoder model. Moreover, sampling examples based on current model errors leads to faster training and higher overall performance.
Memory-efficient Transformers via Top-$k$ Attention
Jun 13, 2021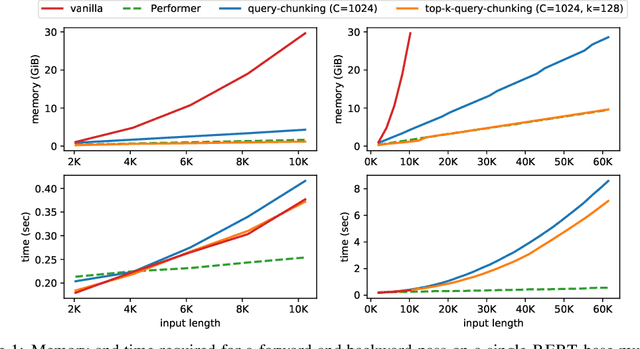
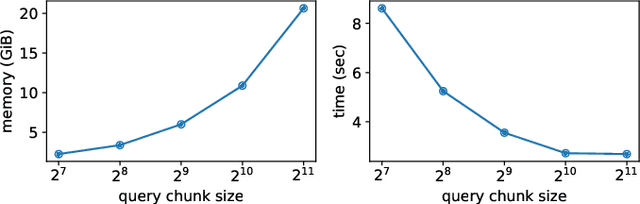
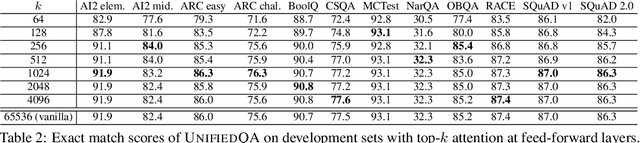
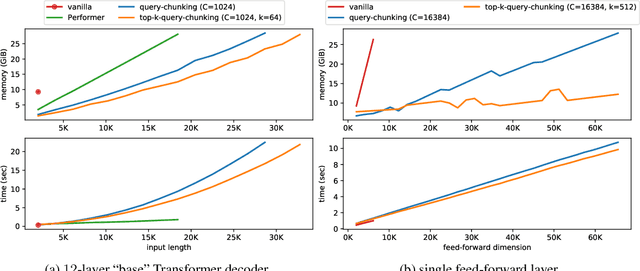
Following the success of dot-product attention in Transformers, numerous approximations have been recently proposed to address its quadratic complexity with respect to the input length. While these variants are memory and compute efficient, it is not possible to directly use them with popular pre-trained language models trained using vanilla attention, without an expensive corrective pre-training stage. In this work, we propose a simple yet highly accurate approximation for vanilla attention. We process the queries in chunks, and for each query, compute the top-$k$ scores with respect to the keys. Our approach offers several advantages: (a) its memory usage is linear in the input size, similar to linear attention variants, such as Performer and RFA (b) it is a drop-in replacement for vanilla attention that does not require any corrective pre-training, and (c) it can also lead to significant memory savings in the feed-forward layers after casting them into the familiar query-key-value framework. We evaluate the quality of top-$k$ approximation for multi-head attention layers on the Long Range Arena Benchmark, and for feed-forward layers of T5 and UnifiedQA on multiple QA datasets. We show our approach leads to accuracy that is nearly-identical to vanilla attention in multiple setups including training from scratch, fine-tuning, and zero-shot inference.
Question Decomposition with Dependency Graphs
Apr 17, 2021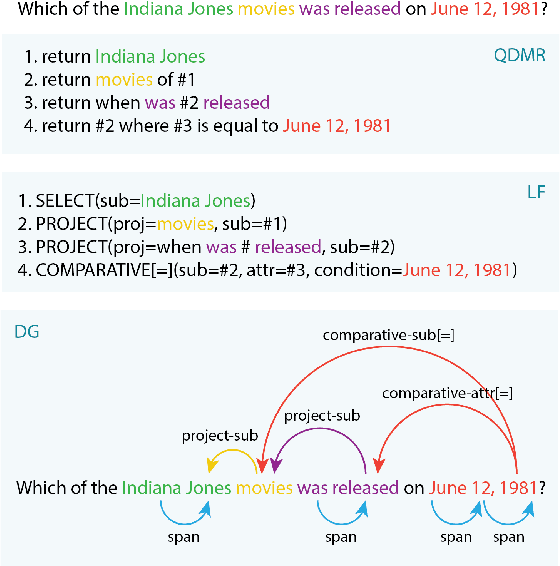

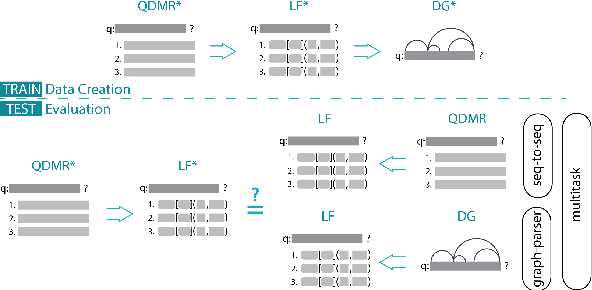
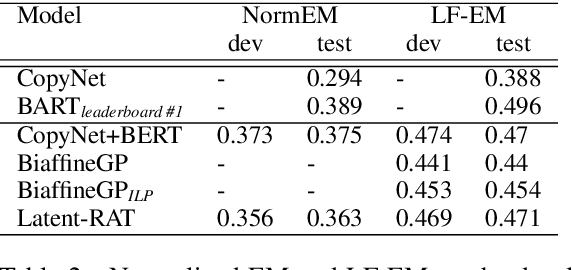
QDMR is a meaning representation for complex questions, which decomposes questions into a sequence of atomic steps. While state-of-the-art QDMR parsers use the common sequence-to-sequence (seq2seq) approach, a QDMR structure fundamentally describes labeled relations between spans in the input question, and thus dependency-based approaches seem appropriate for this task. In this work, we present a QDMR parser that is based on dependency graphs (DGs), where nodes in the graph are words and edges describe logical relations that correspond to the different computation steps. We propose (a) a non-autoregressive graph parser, where all graph edges are computed simultaneously, and (b) a seq2seq parser that uses gold graph as auxiliary supervision. We find that a graph parser leads to a moderate reduction in performance (0.47 to 0.44), but to a 16x speed-up in inference time due to the non-autoregressive nature of the parser, and to improved sample complexity compared to a seq2seq model. Second, a seq2seq model trained with auxiliary graph supervision has better generalization to new domains compared to a seq2seq model, and also performs better on questions with long sequences of computation steps.
What's in your Head? Emergent Behaviour in Multi-Task Transformer Models
Apr 13, 2021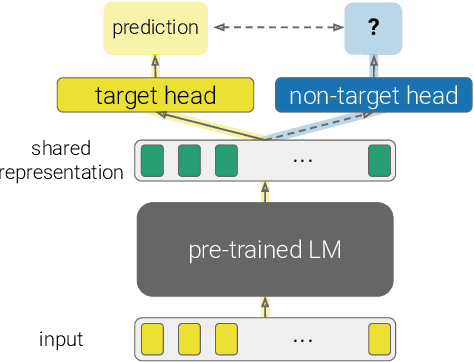

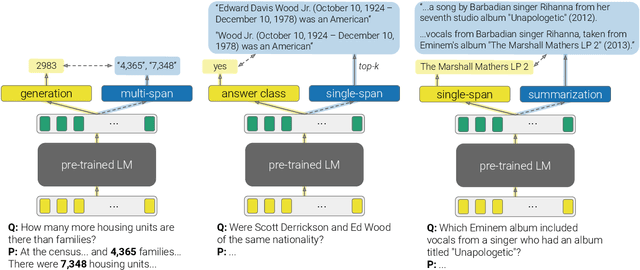

The primary paradigm for multi-task training in natural language processing is to represent the input with a shared pre-trained language model, and add a small, thin network (head) per task. Given an input, a target head is the head that is selected for outputting the final prediction. In this work, we examine the behaviour of non-target heads, that is, the output of heads when given input that belongs to a different task than the one they were trained for. We find that non-target heads exhibit emergent behaviour, which may either explain the target task, or generalize beyond their original task. For example, in a numerical reasoning task, a span extraction head extracts from the input the arguments to a computation that results in a number generated by a target generative head. In addition, a summarization head that is trained with a target question answering head, outputs query-based summaries when given a question and a context from which the answer is to be extracted. This emergent behaviour suggests that multi-task training leads to non-trivial extrapolation of skills, which can be harnessed for interpretability and generalization.
MultiModalQA: Complex Question Answering over Text, Tables and Images
Apr 13, 2021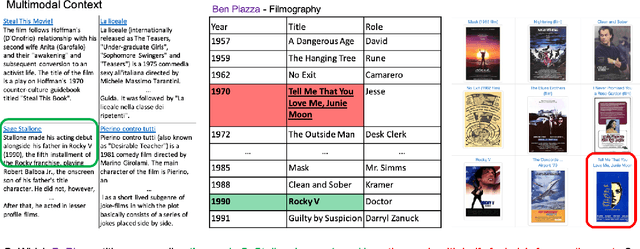
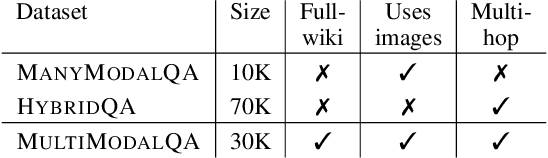

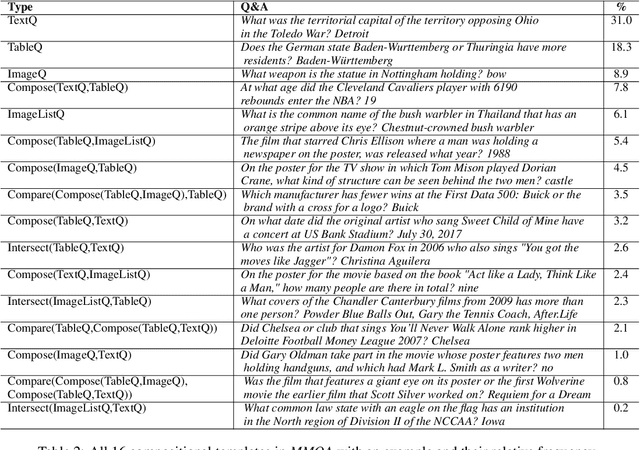
When answering complex questions, people can seamlessly combine information from visual, textual and tabular sources. While interest in models that reason over multiple pieces of evidence has surged in recent years, there has been relatively little work on question answering models that reason across multiple modalities. In this paper, we present MultiModalQA(MMQA): a challenging question answering dataset that requires joint reasoning over text, tables and images. We create MMQA using a new framework for generating complex multi-modal questions at scale, harvesting tables from Wikipedia, and attaching images and text paragraphs using entities that appear in each table. We then define a formal language that allows us to take questions that can be answered from a single modality, and combine them to generate cross-modal questions. Last, crowdsourcing workers take these automatically-generated questions and rephrase them into more fluent language. We create 29,918 questions through this procedure, and empirically demonstrate the necessity of a multi-modal multi-hop approach to solve our task: our multi-hop model, ImplicitDecomp, achieves an average F1of 51.7 over cross-modal questions, substantially outperforming a strong baseline that achieves 38.2 F1, but still lags significantly behind human performance, which is at 90.1 F1
Achieving Model Robustness through Discrete Adversarial Training
Apr 11, 2021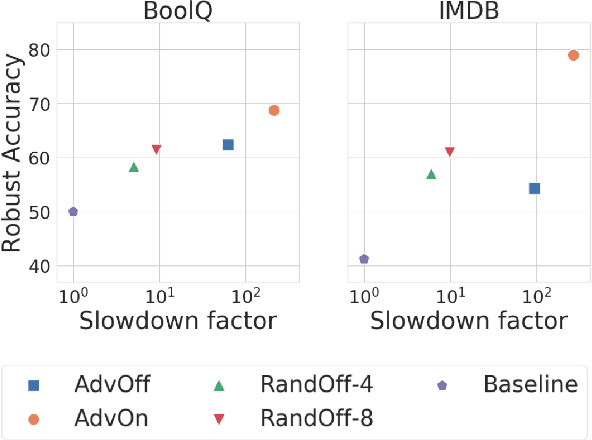
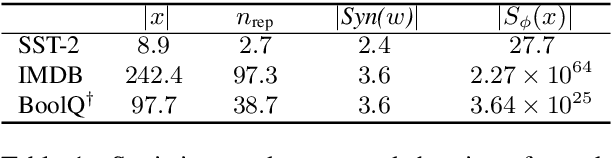

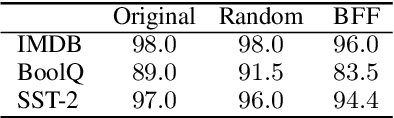
Discrete adversarial attacks are symbolic perturbations to a language input that preserve the output label but lead to a prediction error. While such attacks have been extensively explored for the purpose of evaluating model robustness, their utility for improving robustness has been limited to offline augmentation only, i.e., given a trained model, attacks are used to generate perturbed (adversarial) examples, and the model is re-trained exactly once. In this work, we address this gap and leverage discrete attacks for online augmentation, where adversarial examples are generated at every step, adapting to the changing nature of the model. We also consider efficient attacks based on random sampling, that unlike prior work are not based on expensive search-based procedures. As a second contribution, we provide a general formulation for multiple search-based attacks from past work, and propose a new attack based on best-first search. Surprisingly, we find that random sampling leads to impressive gains in robustness, outperforming the commonly-used offline augmentation, while leading to a speedup at training time of ~10x. Furthermore, online augmentation with search-based attacks justifies the higher training cost, significantly improving robustness on three datasets. Last, we show that our proposed algorithm substantially improves robustness compared to prior methods.