 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInto the Wild with AudioScope: Unsupervised Audio-Visual Separation of On-Screen Sounds
Nov 02, 2020
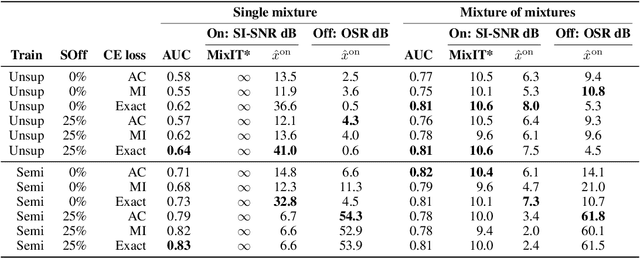
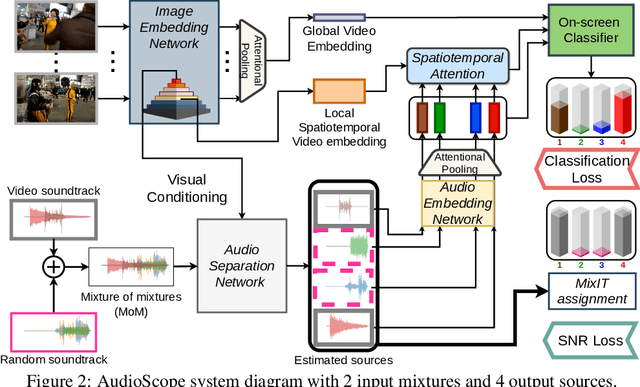
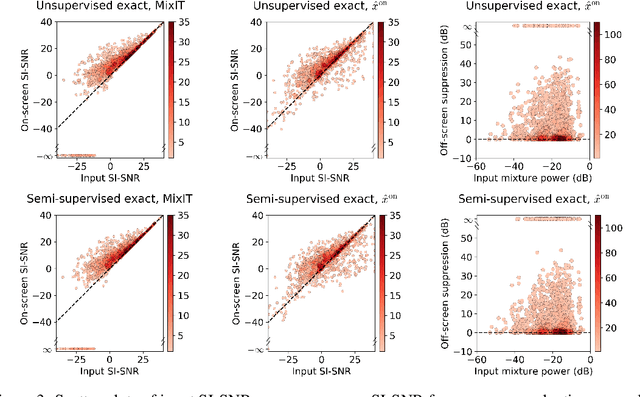
Recent progress in deep learning has enabled many advances in sound separation and visual scene understanding. However, extracting sound sources which are apparent in natural videos remains an open problem. In this work, we present AudioScope, a novel audio-visual sound separation framework that can be trained without supervision to isolate on-screen sound sources from real in-the-wild videos. Prior audio-visual separation work assumed artificial limitations on the domain of sound classes (e.g., to speech or music), constrained the number of sources, and required strong sound separation or visual segmentation labels. AudioScope overcomes these limitations, operating on an open domain of sounds, with variable numbers of sources, and without labels or prior visual segmentation. The training procedure for AudioScope uses mixture invariant training (MixIT) to separate synthetic mixtures of mixtures (MoMs) into individual sources, where noisy labels for mixtures are provided by an unsupervised audio-visual coincidence model. Using the noisy labels, along with attention between video and audio features, AudioScope learns to identify audio-visual similarity and to suppress off-screen sounds. We demonstrate the effectiveness of our approach using a dataset of video clips extracted from open-domain YFCC100m video data. This dataset contains a wide diversity of sound classes recorded in unconstrained conditions, making the application of previous methods unsuitable. For evaluation and semi-supervised experiments, we collected human labels for presence of on-screen and off-screen sounds on a small subset of clips.
Unsupervised Sound Separation Using Mixtures of Mixtures
Jun 23, 2020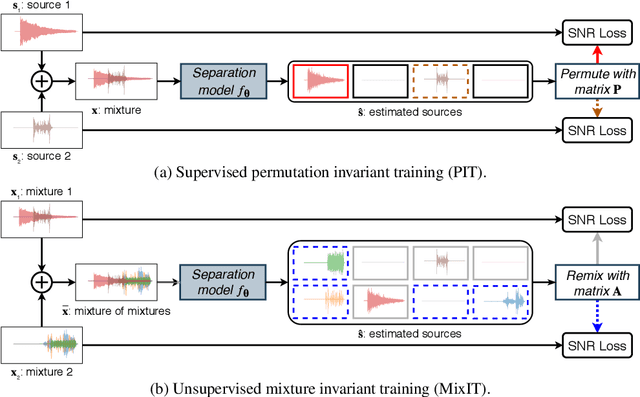
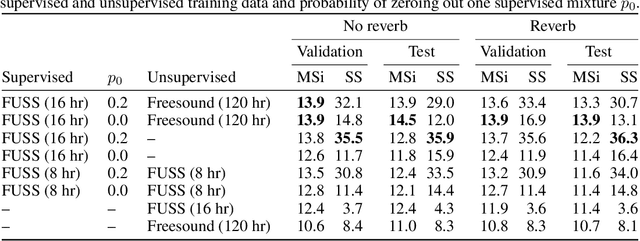
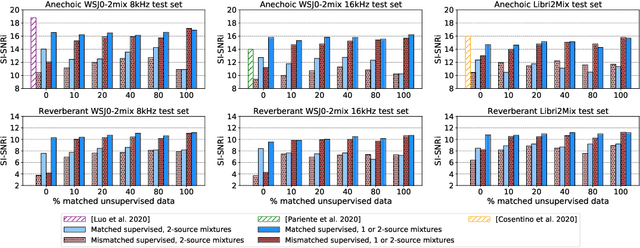
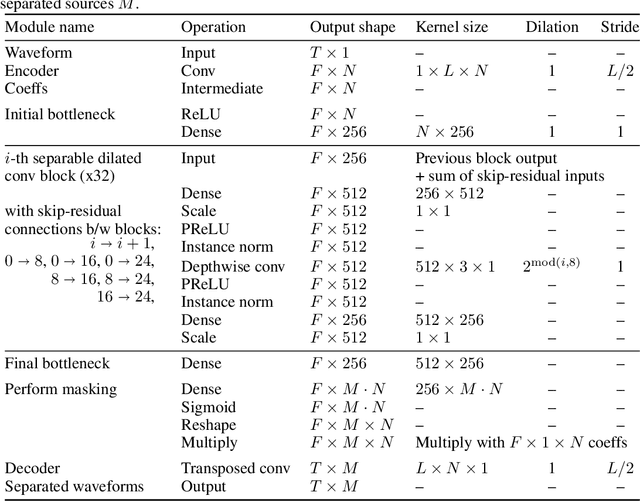
In recent years, rapid progress has been made on the problem of single-channel sound separation using supervised training of deep neural networks. In such supervised approaches, the model is trained to predict the component sources from synthetic mixtures created by adding up isolated ground-truth sources. The reliance on this synthetic training data is problematic because good performance depends upon the degree of match between the training data and real-world audio, especially in terms of the acoustic conditions and distribution of sources. The acoustic properties can be challenging to accurately simulate, and the distribution of sound types may be hard to replicate. In this paper, we propose a completely unsupervised method, mixture invariant training (MixIT), that requires only single-channel acoustic mixtures. In MixIT, training examples are constructed by mixing together existing mixtures, and the model separates them into a variable number of latent sources, such that the separated sources can be remixed to approximate the original mixtures. We show that MixIT can achieve competitive performance compared to supervised methods on speech separation. Using MixIT in a semi-supervised learning setting enables unsupervised domain adaptation and learning from large amounts of real-world data without ground-truth source waveforms. In particular, we significantly improve reverberant speech separation performance by incorporating reverberant mixtures, train a speech enhancement system from noisy mixtures, and improve universal sound separation by incorporating a large amount of in-the-wild data.
Alternating Between Spectral and Spatial Estimation for Speech Separation and Enhancement
Nov 18, 2019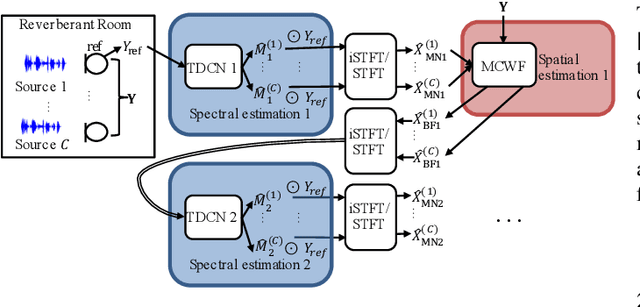
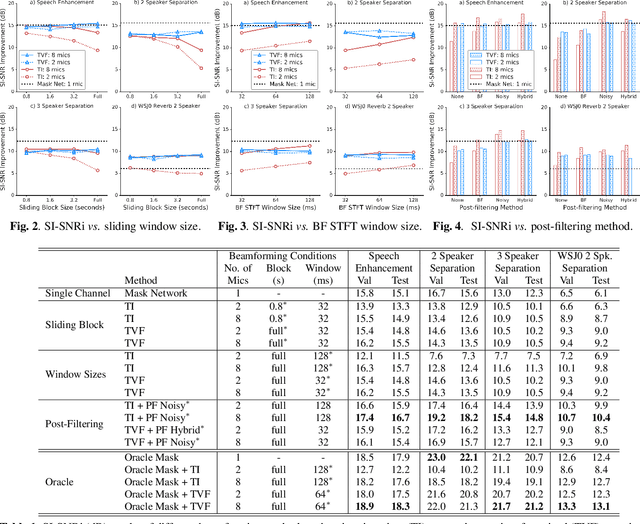
This work investigates alternation between spectral separation using masking-based networks and spatial separation using multichannel beamforming. In this framework, the spectral separation is performed using a mask-based deep network. The result of mask-based separation is used, in turn, to estimate a spatial beamformer. The output of the beamformer is fed back into another mask-based separation network. We explore multiple ways of computing time-varying covariance matrices to improve beamforming, including factorizing the spatial covariance into a time-varying amplitude component and time-invariant spatial component. For the subsequent mask-based filtering, we consider different modes, including masking the noisy input, masking the beamformer output, and a hybrid approach combining both. Our best method first uses spectral separation, then spatial beamforming, and finally a spectral post-filter, and demonstrates an average improvement of 2.8 dB over baseline mask-based separation, across four different reverberant speech enhancement and separation tasks.
Improving Universal Sound Separation Using Sound Classification
Nov 18, 2019
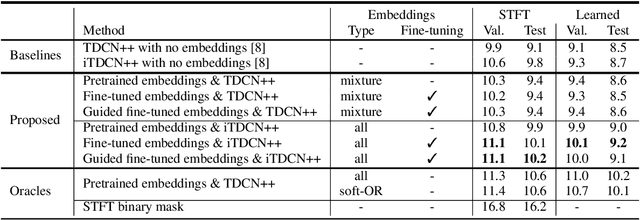
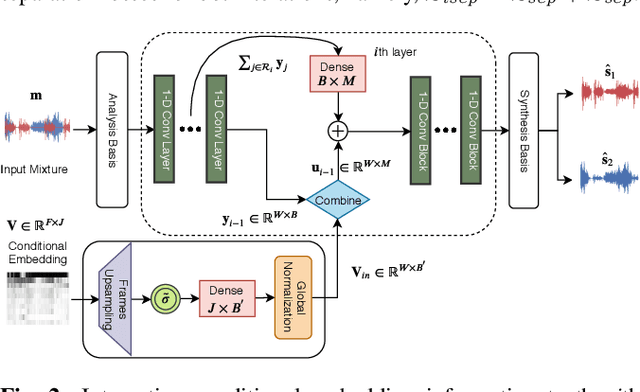
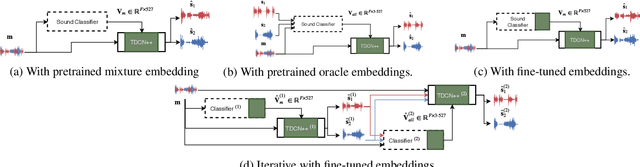
Deep learning approaches have recently achieved impressive performance on both audio source separation and sound classification. Most audio source separation approaches focus only on separating sources belonging to a restricted domain of source classes, such as speech and music. However, recent work has demonstrated the possibility of "universal sound separation", which aims to separate acoustic sources from an open domain, regardless of their class. In this paper, we utilize the semantic information learned by sound classifier networks trained on a vast amount of diverse sounds to improve universal sound separation. In particular, we show that semantic embeddings extracted from a sound classifier can be used to condition a separation network, providing it with useful additional information. This approach is especially useful in an iterative setup, where source estimates from an initial separation stage and their corresponding classifier-derived embeddings are fed to a second separation network. By performing a thorough hyperparameter search consisting of over a thousand experiments, we find that classifier embeddings from clean sources provide nearly one dB of SNR gain, and our best iterative models achieve a significant fraction of this oracle performance, establishing a new state-of-the-art for universal sound separation.
Universal Sound Separation
May 08, 2019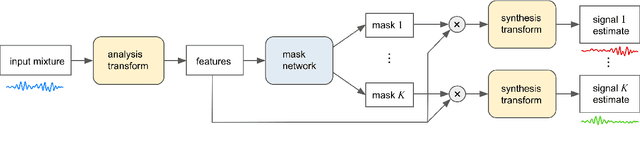
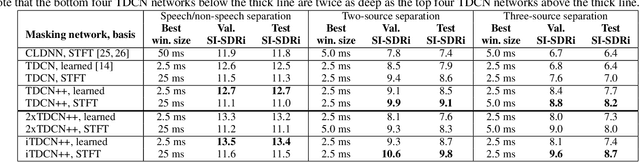
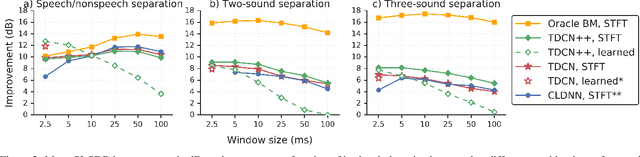
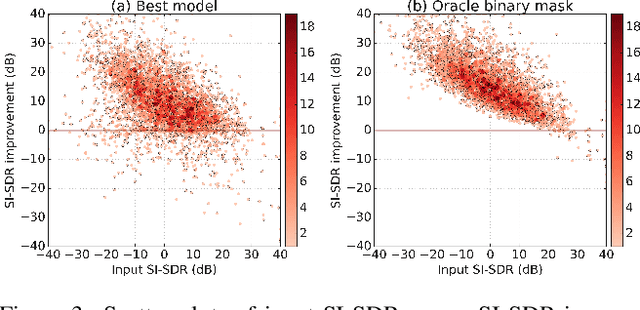
Recent deep learning approaches have achieved impressive performance on speech enhancement and separation tasks. However, these approaches have not been investigated for separating mixtures of arbitrary sounds of different types, a task we refer to as universal sound separation, and it is unknown whether performance on speech tasks carries over to non-speech tasks. To study this question, we develop a universal dataset of mixtures containing arbitrary sounds, and use it to investigate the space of mask-based separation architectures, varying both the overall network architecture and the framewise analysis-synthesis basis for signal transformations. These network architectures include convolutional long short-term memory networks and time-dilated convolution stacks inspired by the recent success of time-domain enhancement networks like ConvTasNet. For the latter architecture, we also propose novel modifications that further improve separation performance. In terms of the framewise analysis-synthesis basis, we explore using either a short-time Fourier transform (STFT) or a learnable basis, as used in ConvTasNet, and for both of these bases, we examine the effect of window size. In particular, for STFTs, we find that longer windows (25-50 ms) work best for speech/non-speech separation, while shorter windows (2.5 ms) work best for arbitrary sounds. For learnable bases, shorter windows (2.5 ms) work best on all tasks. Surprisingly, for universal sound separation, STFTs outperform learnable bases. Our best methods produce an improvement in scale-invariant signal-to-distortion ratio of over 13 dB for speech/non-speech separation and close to 10 dB for universal sound separation.
Phasebook and Friends: Leveraging Discrete Representations for Source Separation
Oct 02, 2018

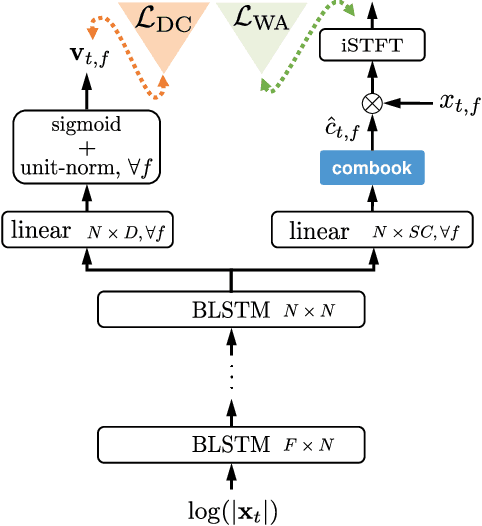
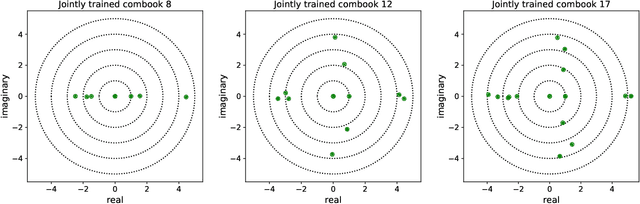
Deep learning based speech enhancement and source separation systems have recently reached unprecedented levels of quality, to the point that performance is reaching a new ceiling. Most systems rely on estimating the magnitude of a target source by estimating a real-valued mask to be applied to a time-frequency representation of the mixture signal. A limiting factor in such approaches is a lack of phase estimation: the phase of the mixture is most often used when reconstructing the estimated time-domain signal. Here, we propose `MagBook', `phasebook', and `Combook', three new types of layers based on discrete representations that can be used to estimate complex time-frequency masks. MagBook layers extend classical sigmoidal units and a recently introduced convex softmax activation for mask-based magnitude estimation. Phasebook layers use a similar structure to give an estimate of the phase mask without suffering from phase wrapping issues. Combook layers are an alternative to the MagBook-Phasebook combination that directly estimate complex masks. We present various training and inference regimes involving these representations, and explain in particular how to include them in an end-to-end learning framework. We also present an oracle study to assess upper bounds on performance for various types of masks using discrete phase representations. We evaluate the proposed methods on the wsj0-2mix dataset, a well-studied corpus for single-channel speaker-independent speaker separation, matching the performance of state-of-the-art mask-based approaches without requiring additional phase reconstruction steps.
A Purely End-to-end System for Multi-speaker Speech Recognition
May 15, 2018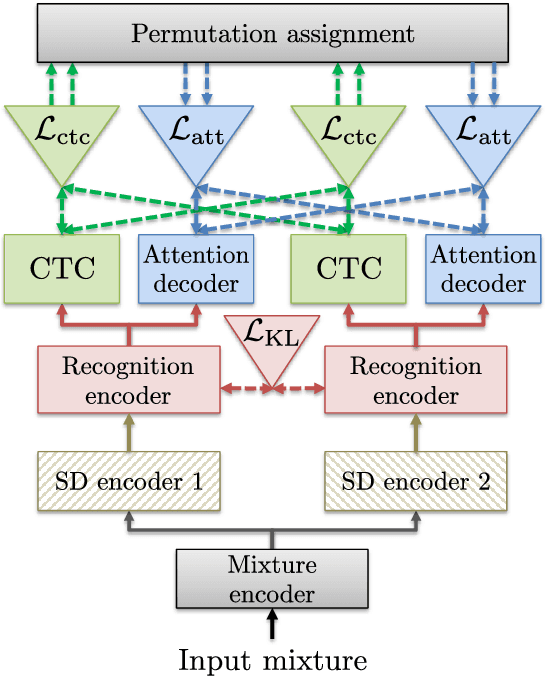

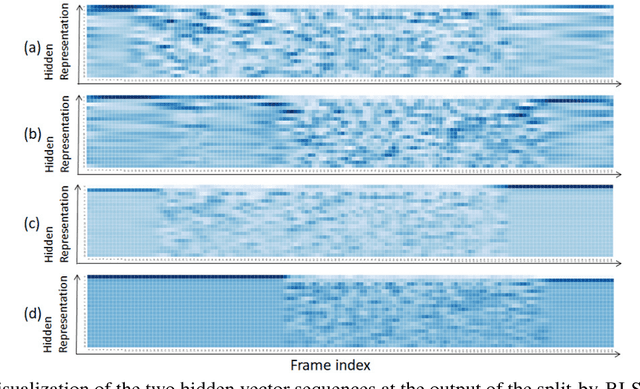
Recently, there has been growing interest in multi-speaker speech recognition, where the utterances of multiple speakers are recognized from their mixture. Promising techniques have been proposed for this task, but earlier works have required additional training data such as isolated source signals or senone alignments for effective learning. In this paper, we propose a new sequence-to-sequence framework to directly decode multiple label sequences from a single speech sequence by unifying source separation and speech recognition functions in an end-to-end manner. We further propose a new objective function to improve the contrast between the hidden vectors to avoid generating similar hypotheses. Experimental results show that the model is directly able to learn a mapping from a speech mixture to multiple label sequences, achieving 83.1 % relative improvement compared to a model trained without the proposed objective. Interestingly, the results are comparable to those produced by previous end-to-end works featuring explicit separation and recognition modules.
End-to-End Speech Separation with Unfolded Iterative Phase Reconstruction
Apr 26, 2018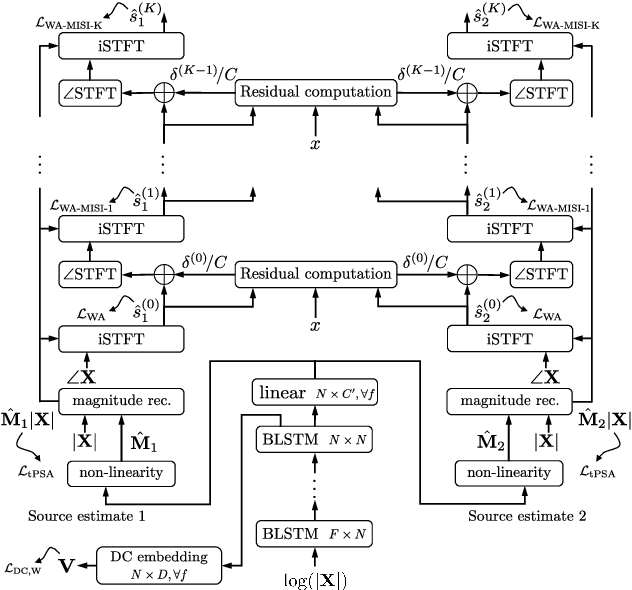
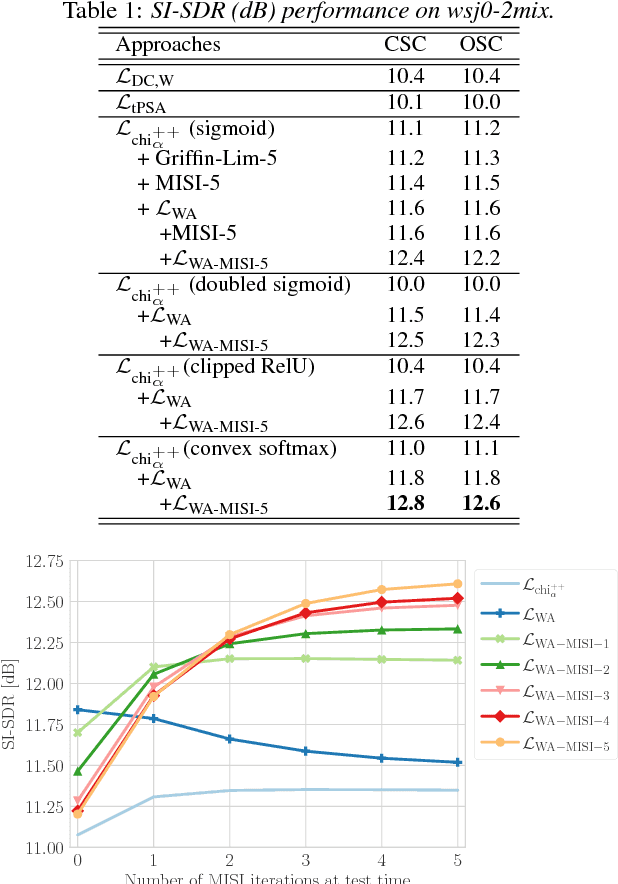
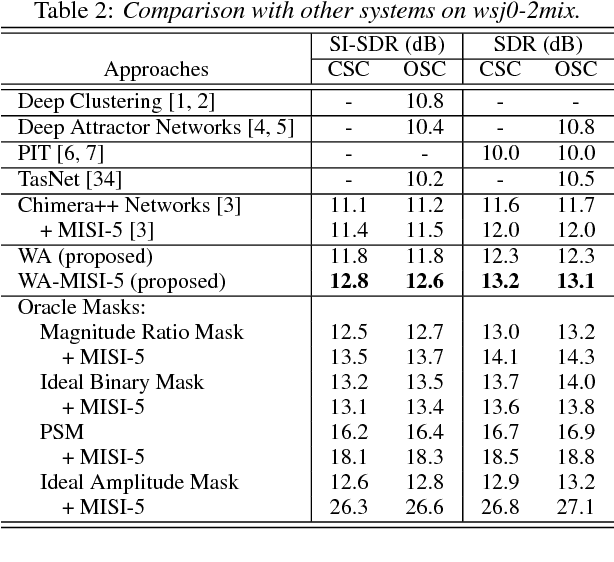
This paper proposes an end-to-end approach for single-channel speaker-independent multi-speaker speech separation, where time-frequency (T-F) masking, the short-time Fourier transform (STFT), and its inverse are represented as layers within a deep network. Previous approaches, rather than computing a loss on the reconstructed signal, used a surrogate loss based on the target STFT magnitudes. This ignores reconstruction error introduced by phase inconsistency. In our approach, the loss function is directly defined on the reconstructed signals, which are optimized for best separation. In addition, we train through unfolded iterations of a phase reconstruction algorithm, represented as a series of STFT and inverse STFT layers. While mask values are typically limited to lie between zero and one for approaches using the mixture phase for reconstruction, this limitation is less relevant if the estimated magnitudes are to be used together with phase reconstruction. We thus propose several novel activation functions for the output layer of the T-F masking, to allow mask values beyond one. On the publicly-available wsj0-2mix dataset, our approach achieves state-of-the-art 12.6 dB scale-invariant signal-to-distortion ratio (SI-SDR) and 13.1 dB SDR, revealing new possibilities for deep learning based phase reconstruction and representing a fundamental progress towards solving the notoriously-hard cocktail party problem.
Deep Long Short-Term Memory Adaptive Beamforming Networks For Multichannel Robust Speech Recognition
Nov 21, 2017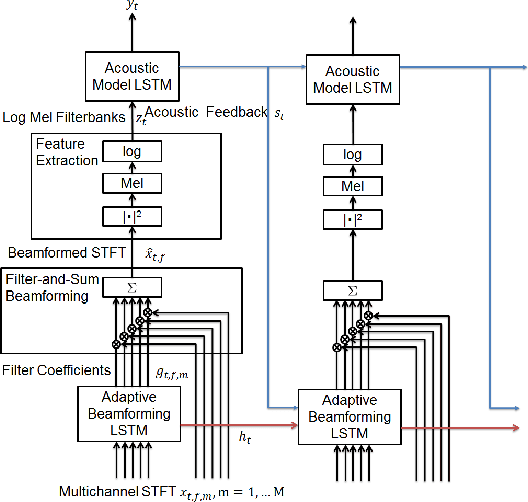
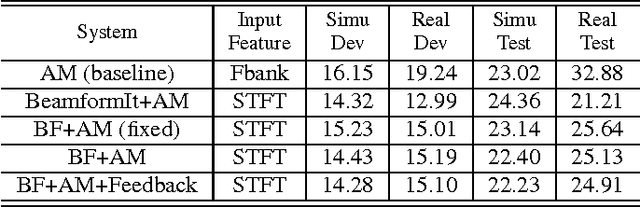
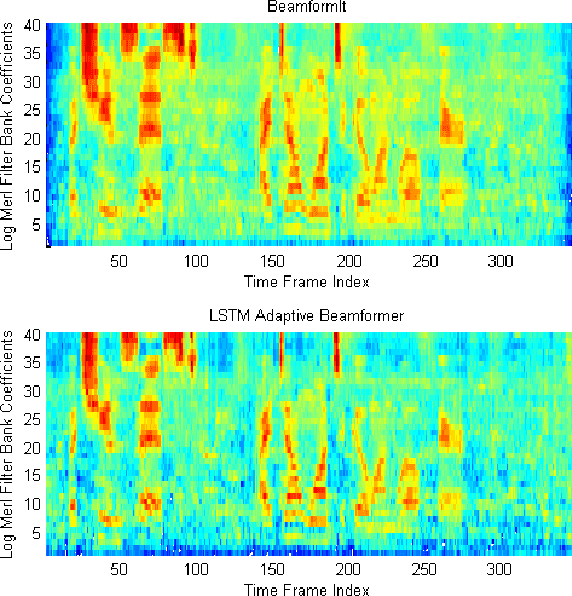
Far-field speech recognition in noisy and reverberant conditions remains a challenging problem despite recent deep learning breakthroughs. This problem is commonly addressed by acquiring a speech signal from multiple microphones and performing beamforming over them. In this paper, we propose to use a recurrent neural network with long short-term memory (LSTM) architecture to adaptively estimate real-time beamforming filter coefficients to cope with non-stationary environmental noise and dynamic nature of source and microphones positions which results in a set of timevarying room impulse responses. The LSTM adaptive beamformer is jointly trained with a deep LSTM acoustic model to predict senone labels. Further, we use hidden units in the deep LSTM acoustic model to assist in predicting the beamforming filter coefficients. The proposed system achieves 7.97% absolute gain over baseline systems with no beamforming on CHiME-3 real evaluation set.
* in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Deep Clustering and Conventional Networks for Music Separation: Stronger Together
Jun 15, 2017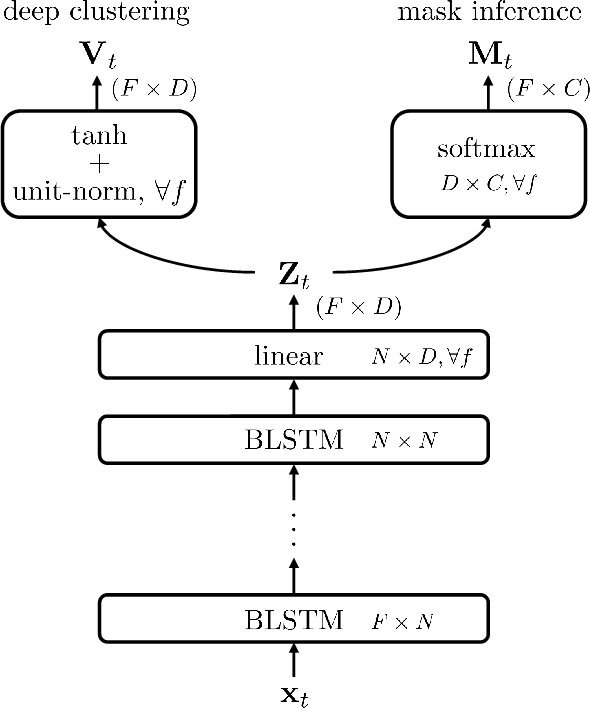
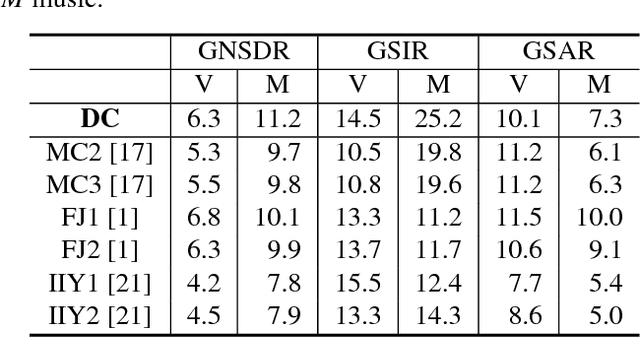
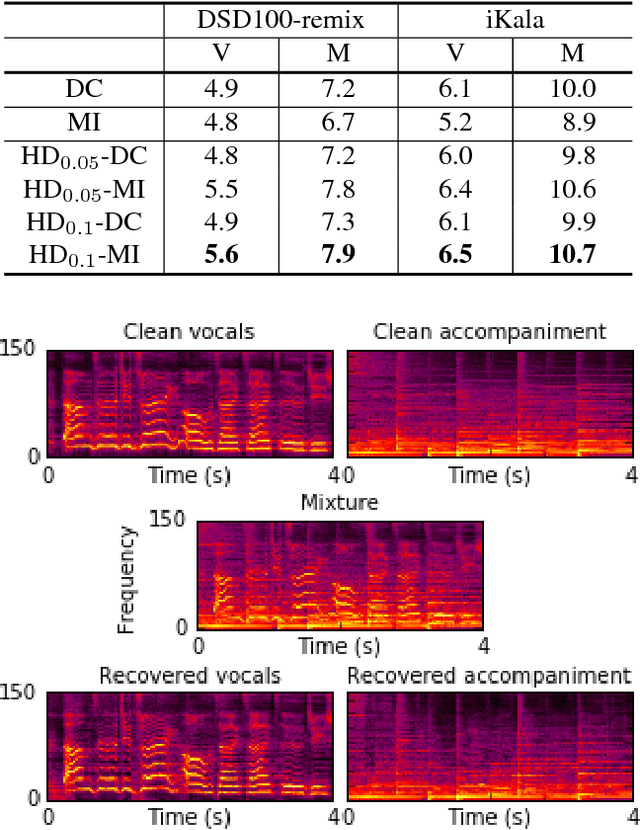
Deep clustering is the first method to handle general audio separation scenarios with multiple sources of the same type and an arbitrary number of sources, performing impressively in speaker-independent speech separation tasks. However, little is known about its effectiveness in other challenging situations such as music source separation. Contrary to conventional networks that directly estimate the source signals, deep clustering generates an embedding for each time-frequency bin, and separates sources by clustering the bins in the embedding space. We show that deep clustering outperforms conventional networks on a singing voice separation task, in both matched and mismatched conditions, even though conventional networks have the advantage of end-to-end training for best signal approximation, presumably because its more flexible objective engenders better regularization. Since the strengths of deep clustering and conventional network architectures appear complementary, we explore combining them in a single hybrid network trained via an approach akin to multi-task learning. Remarkably, the combination significantly outperforms either of its components.