 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudioScopeV2: Audio-Visual Attention Architectures for Calibrated Open-Domain On-Screen Sound Separation
Jul 20, 2022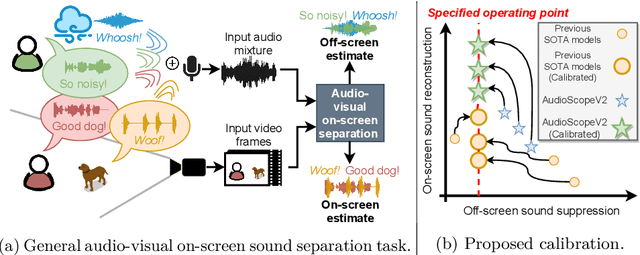
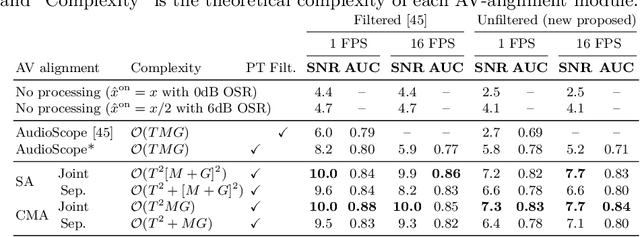
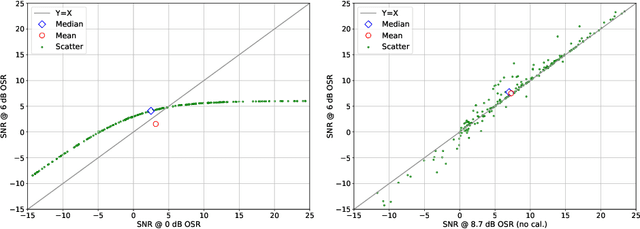
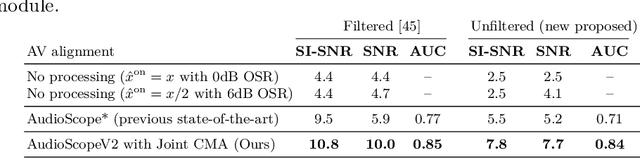
We introduce AudioScopeV2, a state-of-the-art universal audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify several limitations of previous work on audio-visual on-screen sound separation, including the coarse resolution of spatio-temporal attention, poor convergence of the audio separation model, limited variety in training and evaluation data, and failure to account for the trade off between preservation of on-screen sounds and suppression of off-screen sounds. We provide solutions to all of these issues. Our proposed cross-modal and self-attention network architectures capture audio-visual dependencies at a finer resolution over time, and we also propose efficient separable variants that are capable of scaling to longer videos without sacrificing much performance. We also find that pre-training the separation model only on audio greatly improves results. For training and evaluation, we collected new human annotations of onscreen sounds from a large database of in-the-wild videos (YFCC100M). This new dataset is more diverse and challenging. Finally, we propose a calibration procedure that allows exact tuning of on-screen reconstruction versus off-screen suppression, which greatly simplifies comparing performance between models with different operating points. Overall, our experimental results show marked improvements in on-screen separation performance under much more general conditions than previous methods with minimal additional computational complexity.
Distance-Based Sound Separation
Jul 01, 2022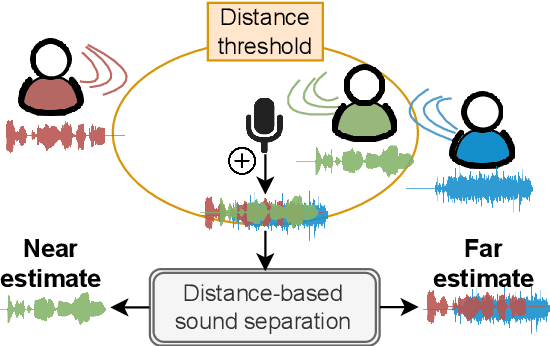
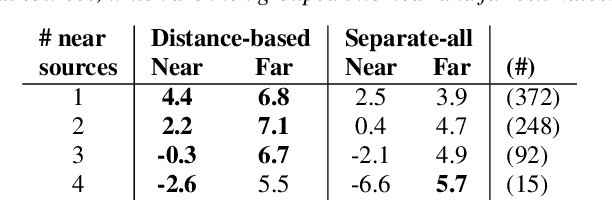
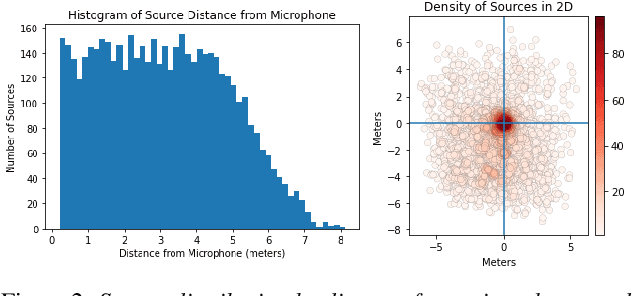

We propose the novel task of distance-based sound separation, where sounds are separated based only on their distance from a single microphone. In the context of assisted listening devices, proximity provides a simple criterion for sound selection in noisy environments that would allow the user to focus on sounds relevant to a local conversation. We demonstrate the feasibility of this approach by training a neural network to separate near sounds from far sounds in single channel synthetic reverberant mixtures, relative to a threshold distance defining the boundary between near and far. With a single nearby speaker and four distant speakers, the model improves scale-invariant signal to noise ratio by 4.4 dB for near sounds and 6.8 dB for far sounds.
CycleGAN-Based Unpaired Speech Dereverberation
Mar 29, 2022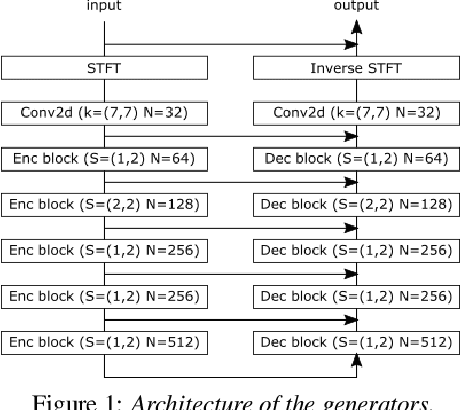

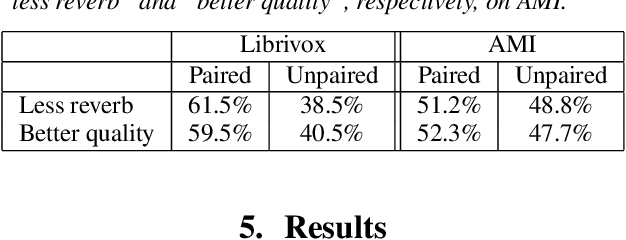
Typically, neural network-based speech dereverberation models are trained on paired data, composed of a dry utterance and its corresponding reverberant utterance. The main limitation of this approach is that such models can only be trained on large amounts of data and a variety of room impulse responses when the data is synthetically reverberated, since acquiring real paired data is costly. In this paper we propose a CycleGAN-based approach that enables dereverberation models to be trained on unpaired data. We quantify the impact of using unpaired data by comparing the proposed unpaired model to a paired model with the same architecture and trained on the paired version of the same dataset. We show that the performance of the unpaired model is comparable to the performance of the paired model on two different datasets, according to objective evaluation metrics. Furthermore, we run two subjective evaluations and show that both models achieve comparable subjective quality on the AMI dataset, which was not seen during training.
Adapting Speech Separation to Real-World Meetings Using Mixture Invariant Training
Oct 20, 2021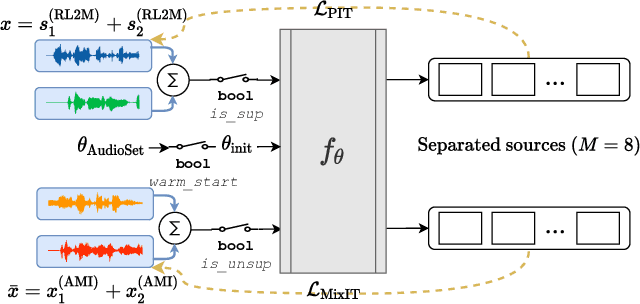
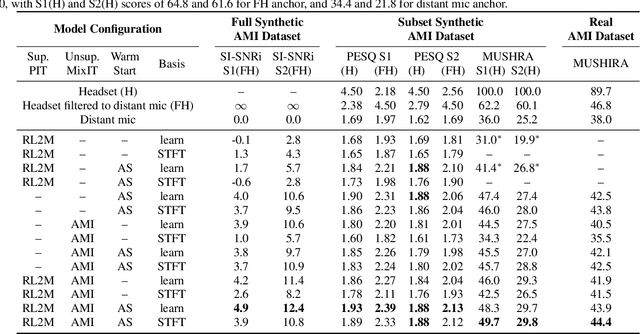
The recently-proposed mixture invariant training (MixIT) is an unsupervised method for training single-channel sound separation models in the sense that it does not require ground-truth isolated reference sources. In this paper, we investigate using MixIT to adapt a separation model on real far-field overlapping reverberant and noisy speech data from the AMI Corpus. The models are tested on real AMI recordings containing overlapping speech, and are evaluated subjectively by human listeners. To objectively evaluate our models, we also devise a synthetic AMI test set. For human evaluations on real recordings, we also propose a modification of the standard MUSHRA protocol to handle imperfect reference signals, which we call MUSHIRA. Holding network architectures constant, we find that a fine-tuned semi-supervised model yields the largest SI-SNR improvement, PESQ scores, and human listening ratings across synthetic and real datasets, outperforming unadapted generalist models trained on orders of magnitude more data. Our results show that unsupervised learning through MixIT enables model adaptation on real-world unlabeled spontaneous speech recordings.
Improving Bird Classification with Unsupervised Sound Separation
Oct 07, 2021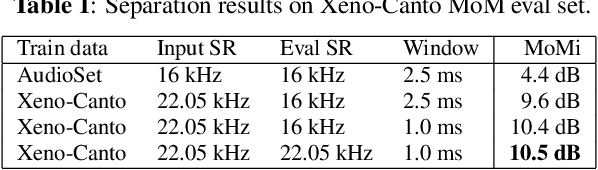

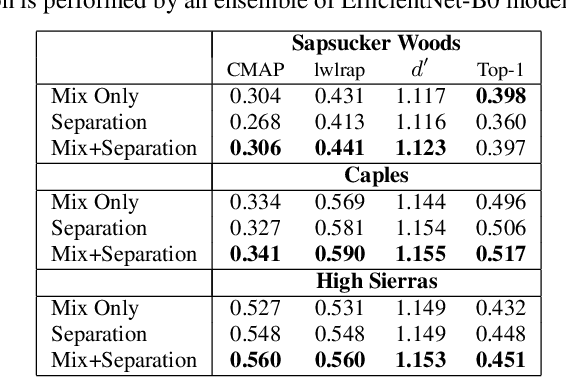
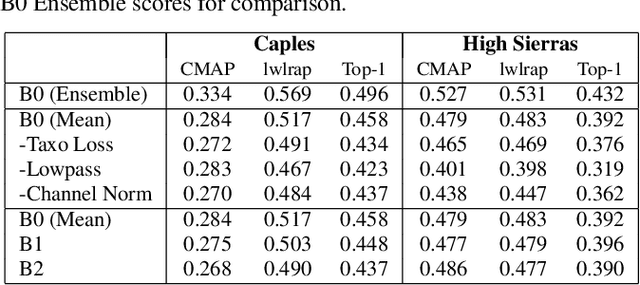
This paper addresses the problem of species classification in bird song recordings. The massive amount of available field recordings of birds presents an opportunity to use machine learning to automatically track bird populations. However, it also poses a problem: such field recordings typically contain significant environmental noise and overlapping vocalizations that interfere with classification. The widely available training datasets for species identification also typically leave background species unlabeled. This leads classifiers to ignore vocalizations with a low signal-to-noise ratio. However, recent advances in unsupervised sound separation, such as \emph{mixture invariant training} (MixIT), enable high quality separation of bird songs to be learned from such noisy recordings. In this paper, we demonstrate improved separation quality when training a MixIT model specifically for birdsong data, outperforming a general audio separation model by over 5 dB in SI-SNR improvement of reconstructed mixtures. We also demonstrate precision improvements with a downstream multi-species bird classifier across three independent datasets. The best classifier performance is achieved by taking the maximum model activations over the separated channels and original audio. Finally, we document additional classifier improvements, including taxonomic classification, augmentation by random low-pass filters, and additional channel normalization.
DF-Conformer: Integrated architecture of Conv-TasNet and Conformer using linear complexity self-attention for speech enhancement
Jun 30, 2021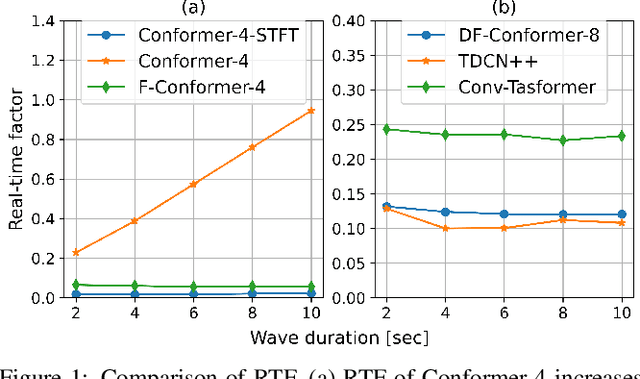
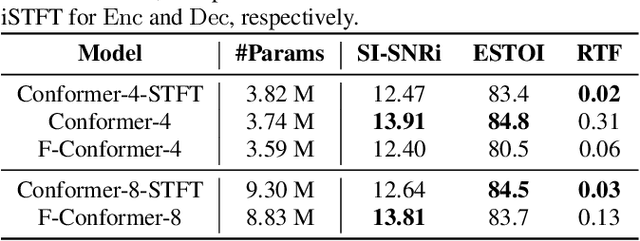
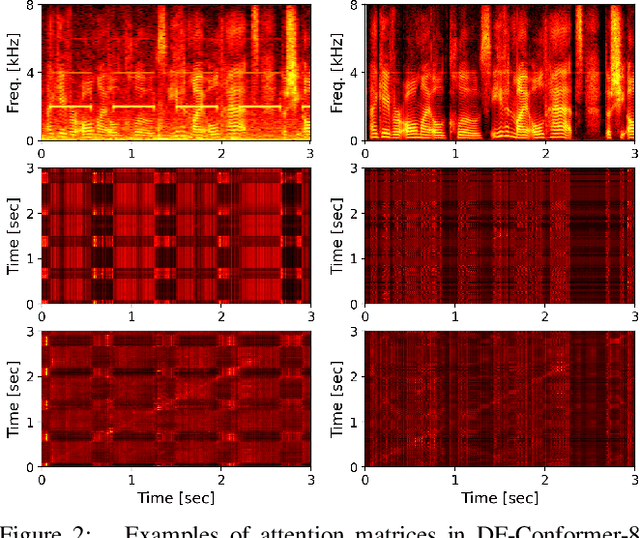
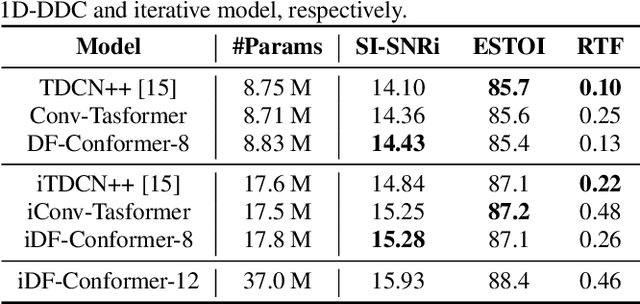
Single-channel speech enhancement (SE) is an important task in speech processing. A widely used framework combines an analysis/synthesis filterbank with a mask prediction network, such as the Conv-TasNet architecture. In such systems, the denoising performance and computational efficiency are mainly affected by the structure of the mask prediction network. In this study, we aim to improve the sequential modeling ability of Conv-TasNet architectures by integrating Conformer layers into a new mask prediction network. To make the model computationally feasible, we extend the Conformer using linear complexity attention and stacked 1-D dilated depthwise convolution layers. We trained the model on 3,396 hours of noisy speech data, and show that (i) the use of linear complexity attention avoids high computational complexity, and (ii) our model achieves higher scale-invariant signal-to-noise ratio than the improved time-dilated convolution network (TDCN++), an extended version of Conv-TasNet.
Improving On-Screen Sound Separation for Open Domain Videos with Audio-Visual Self-attention
Jun 17, 2021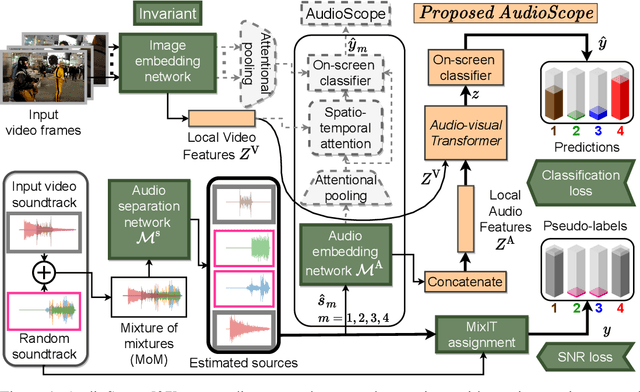
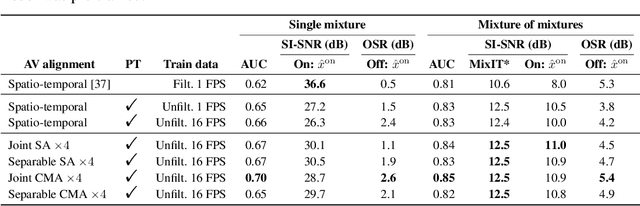
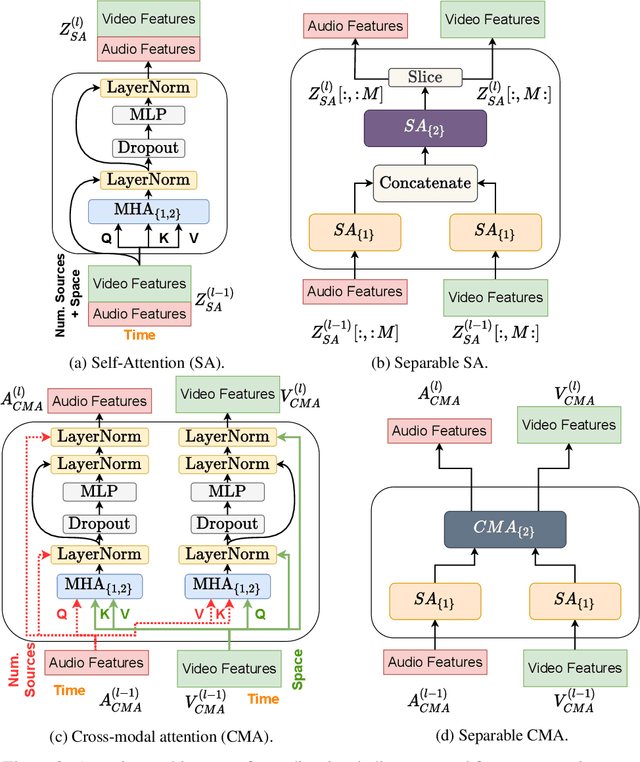
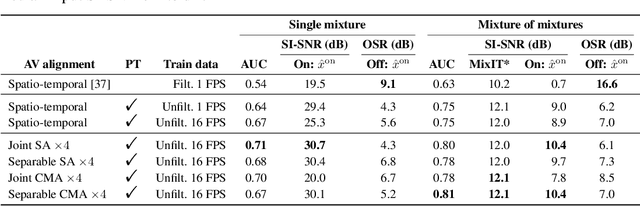
We introduce a state-of-the-art audio-visual on-screen sound separation system which is capable of learning to separate sounds and associate them with on-screen objects by looking at in-the-wild videos. We identify limitations of previous work on audiovisual on-screen sound separation, including the simplicity and coarse resolution of spatio-temporal attention, and poor convergence of the audio separation model. Our proposed model addresses these issues using cross-modal and self-attention modules that capture audio-visual dependencies at a finer resolution over time, and by unsupervised pre-training of audio separation model. These improvements allow the model to generalize to a much wider set of unseen videos. For evaluation and semi-supervised training, we collected human annotations of on-screen audio from a large database of in-the-wild videos (YFCC100M). Our results show marked improvements in on-screen separation performance, in more general conditions than previous methods.
Sparse, Efficient, and Semantic Mixture Invariant Training: Taming In-the-Wild Unsupervised Sound Separation
Jun 01, 2021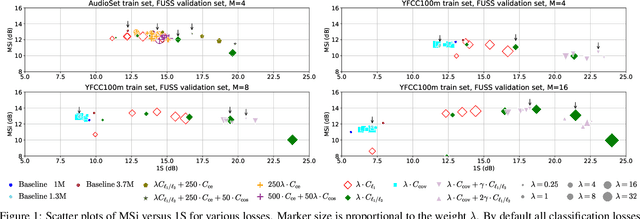
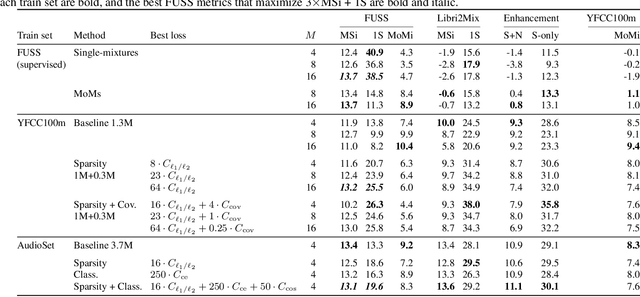
Supervised neural network training has led to significant progress on single-channel sound separation. This approach relies on ground truth isolated sources, which precludes scaling to widely available mixture data and limits progress on open-domain tasks. The recent mixture invariant training (MixIT) method enables training on in-the wild data; however, it suffers from two outstanding problems. First, it produces models which tend to over-separate, producing more output sources than are present in the input. Second, the exponential computational complexity of the MixIT loss limits the number of feasible output sources. These problems interact: increasing the number of output sources exacerbates over-separation. In this paper we address both issues. To combat over-separation we introduce new losses: sparsity losses that favor fewer output sources and a covariance loss that discourages correlated outputs. We also experiment with a semantic classification loss by predicting weak class labels for each mixture. To extend MixIT to larger numbers of sources, we introduce an efficient approximation using a fast least-squares solution, projected onto the MixIT constraint set. Our experiments show that the proposed losses curtail over-separation and improve overall performance. The best performance is achieved using larger numbers of output sources, enabled by our efficient MixIT loss, combined with sparsity losses to prevent over-separation. On the FUSS test set, we achieve over 13 dB in multi-source SI-SNR improvement, while boosting single-source reconstruction SI-SNR by over 17 dB.
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021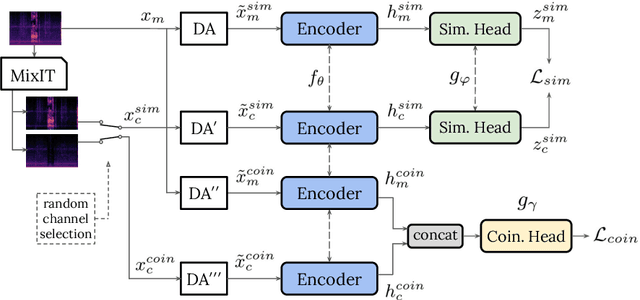
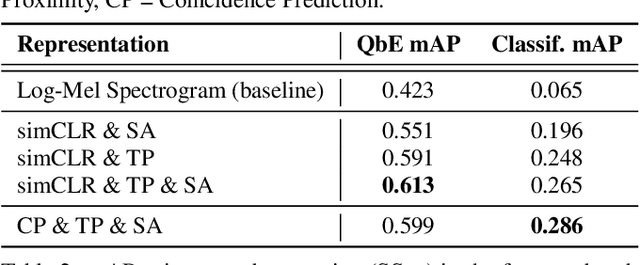

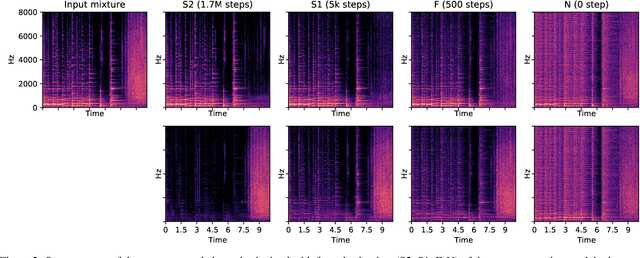
Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
End-to-End Diarization for Variable Number of Speakers with Local-Global Networks and Discriminative Speaker Embeddings
May 05, 2021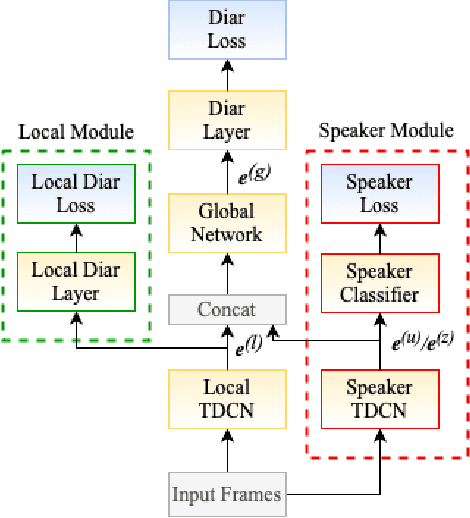
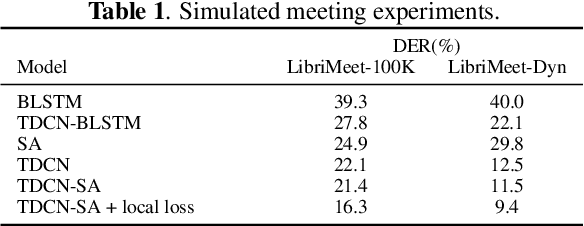
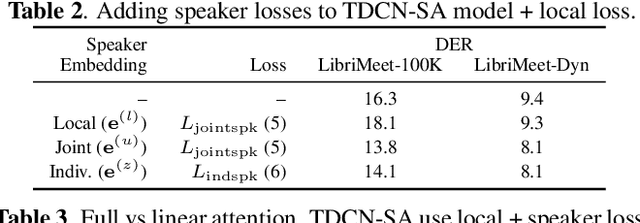
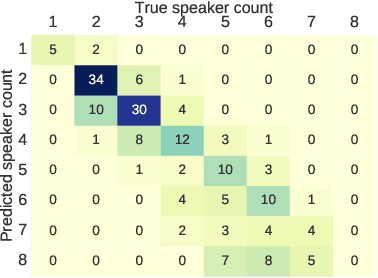
We present an end-to-end deep network model that performs meeting diarization from single-channel audio recordings. End-to-end diarization models have the advantage of handling speaker overlap and enabling straightforward handling of discriminative training, unlike traditional clustering-based diarization methods. The proposed system is designed to handle meetings with unknown numbers of speakers, using variable-number permutation-invariant cross-entropy based loss functions. We introduce several components that appear to help with diarization performance, including a local convolutional network followed by a global self-attention module, multi-task transfer learning using a speaker identification component, and a sequential approach where the model is refined with a second stage. These are trained and validated on simulated meeting data based on LibriSpeech and LibriTTS datasets; final evaluations are done using LibriCSS, which consists of simulated meetings recorded using real acoustics via loudspeaker playback. The proposed model performs better than previously proposed end-to-end diarization models on these data.
* 5 pages, 2 figures, ICASSP 2021