 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelay-aware Robust Control for Safe Autonomous Driving and Racing
Aug 29, 2022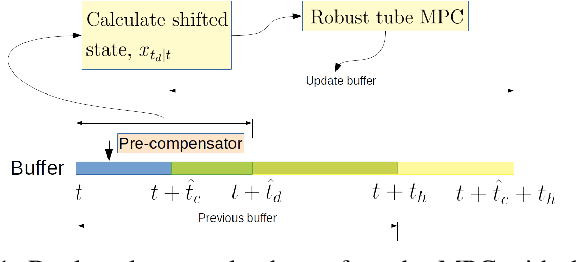
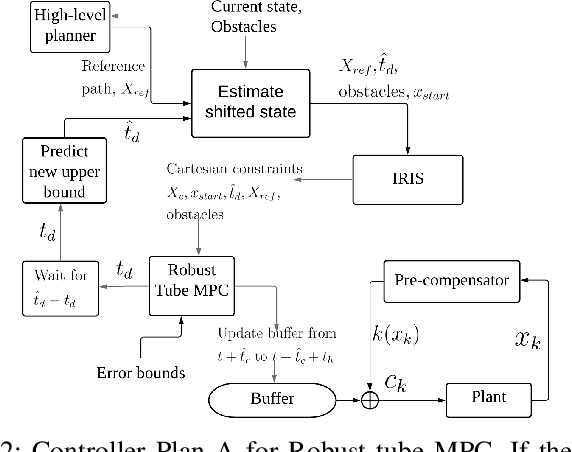
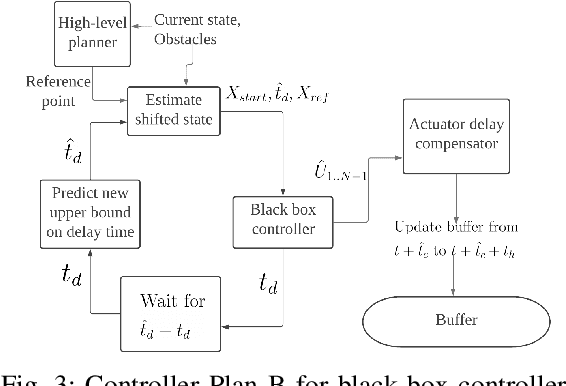
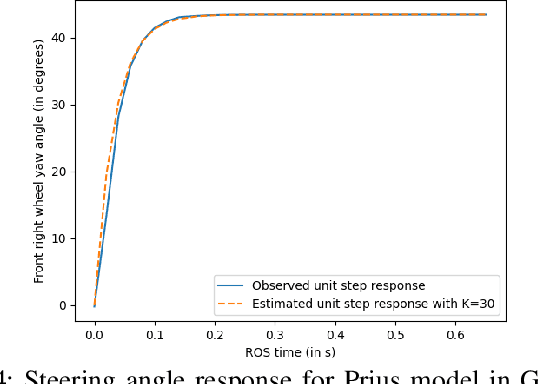
Delays endanger safety of autonomous systems operating in a rapidly changing environment, such as nondeterministic surrounding traffic participants in autonomous driving and high-speed racing. Unfortunately, delays are typically not considered during the conventional controller design or learning-enabled controller training phases prior to deployment in the physical world. In this paper, the computation delay from nonlinear optimization for motion planning and control, as well as other unavoidable delays caused by actuators, are addressed systematically and unifiedly. To deal with all these delays, in our framework: 1) we propose a new filtering approach with no prior knowledge of dynamics and disturbance distribution to adaptively and safely estimate the time-variant computation delay; 2) we model actuation dynamics for steering delay; 3) all the constrained optimization is realized in a robust tube model predictive controller. For the application merits, we demonstrate that our approach is suitable for both autonomous driving and autonomous racing. Our approach is a novel design for a standalone delay compensation controller. In addition, in the case that a learning-enabled controller assuming no delay works as a primary controller, our approach serves as the primary controller's safety guard.
State Dropout-Based Curriculum Reinforcement Learning for Self-Driving at Unsignalized Intersections
Jul 10, 2022
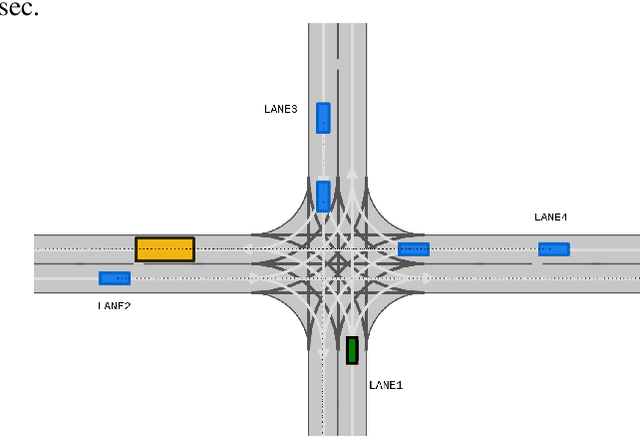
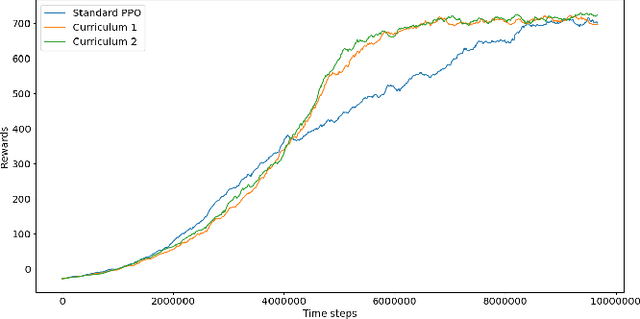
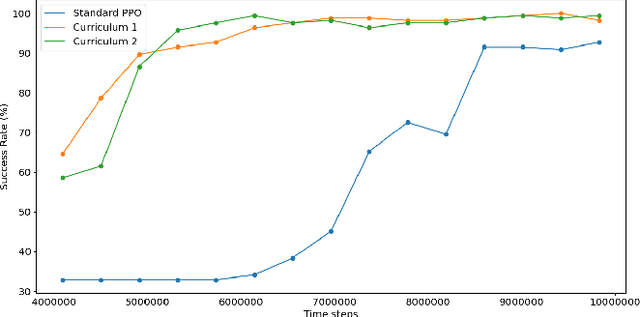
Traversing intersections is a challenging problem for autonomous vehicles, especially when the intersections do not have traffic control. Recently deep reinforcement learning has received massive attention due to its success in dealing with autonomous driving tasks. In this work, we address the problem of traversing unsignalized intersections using a novel curriculum for deep reinforcement learning. The proposed curriculum leads to: 1) A faster training process for the reinforcement learning agent, and 2) Better performance compared to an agent trained without curriculum. Our main contribution is two-fold: 1) Presenting a unique curriculum for training deep reinforcement learning agents, and 2) showing the application of the proposed curriculum for the unsignalized intersection traversal task. The framework expects processed observations of the surroundings from the perception system of the autonomous vehicle. We test our method in the CommonRoad motion planning simulator on T-intersections and four-way intersections.
Responsibility-associated Multi-agent Collision Avoidance with Social Preferences
Jun 17, 2022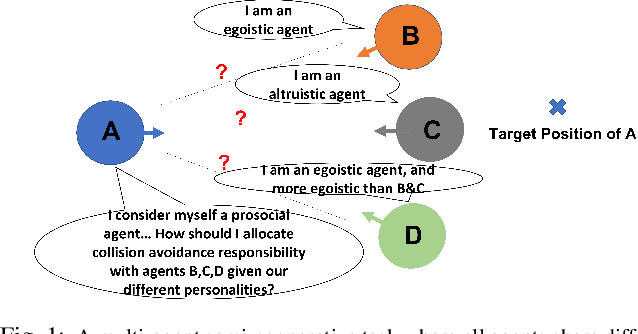
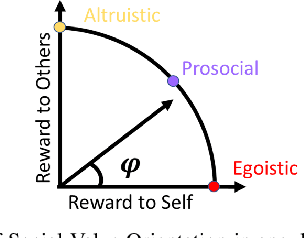

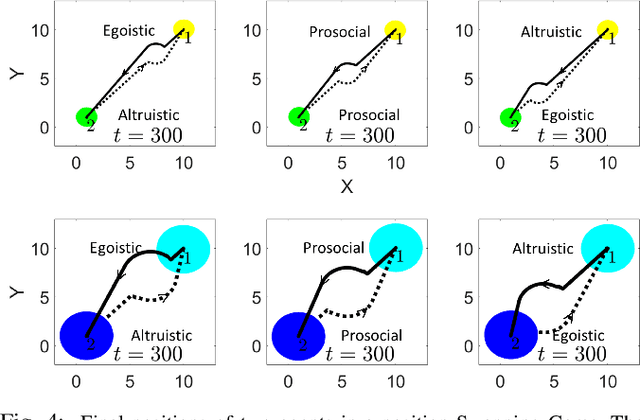
This paper introduces a novel social preference-aware decentralized safe control framework to address the responsibility allocation problem in multi-agent collision avoidance. Considering that agents do not necessarily cooperate in symmetric ways, this paper focuses on semi-cooperative behavior among heterogeneous agents with varying cooperation levels. Drawing upon the idea of Social Value Orientation (SVO) for quantifying the individual selfishness, we propose a novel concept of Responsibility-associated Social Value Orientation (R-SVO) to express the intended relative social implications between pairwise agents. This is used to redefine each agent's social preferences or personalities in terms of corresponding responsibility shares in contributing to the coordination scenario, such as semi-cooperative collision avoidance where all agents interact in an asymmetric way. By incorporating such relative social implications through proposed Local Pairwise Responsibility Weights, we develop a Responsibility-associated Control Barrier Function-based safe control framework for individual agents, and multi-agent collision avoidance is achieved with formally provable safety guarantees. Simulations are provided to demonstrate the effectiveness and efficiency of the proposed framework in several multi-agent navigation tasks, such as a position-swapping game, a self-driving car highway ramp merging scenario, and a circular position swapping game.
BATS: Best Action Trajectory Stitching
Apr 26, 2022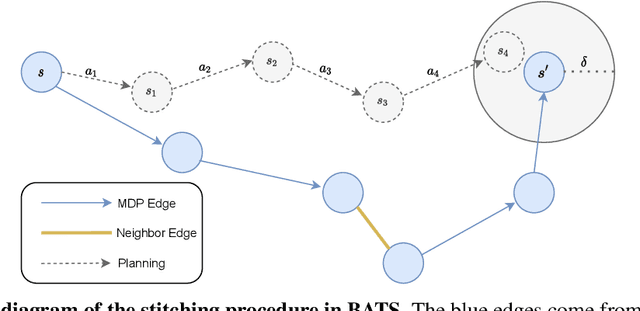

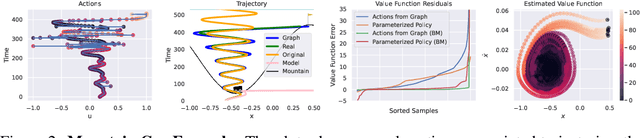
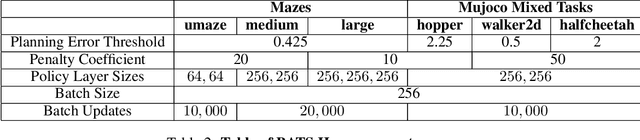
The problem of offline reinforcement learning focuses on learning a good policy from a log of environment interactions. Past efforts for developing algorithms in this area have revolved around introducing constraints to online reinforcement learning algorithms to ensure the actions of the learned policy are constrained to the logged data. In this work, we explore an alternative approach by planning on the fixed dataset directly. Specifically, we introduce an algorithm which forms a tabular Markov Decision Process (MDP) over the logged data by adding new transitions to the dataset. We do this by using learned dynamics models to plan short trajectories between states. Since exact value iteration can be performed on this constructed MDP, it becomes easy to identify which trajectories are advantageous to add to the MDP. Crucially, since most transitions in this MDP come from the logged data, trajectories from the MDP can be rolled out for long periods with confidence. We prove that this property allows one to make upper and lower bounds on the value function up to appropriate distance metrics. Finally, we demonstrate empirically how algorithms that uniformly constrain the learned policy to the entire dataset can result in unwanted behavior, and we show an example in which simply behavior cloning the optimal policy of the MDP created by our algorithm avoids this problem.
Adaptive Safe Merging Control for Heterogeneous Autonomous Vehicles using Parametric Control Barrier Functions
Feb 20, 2022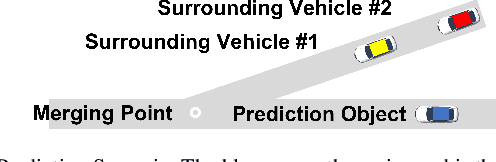
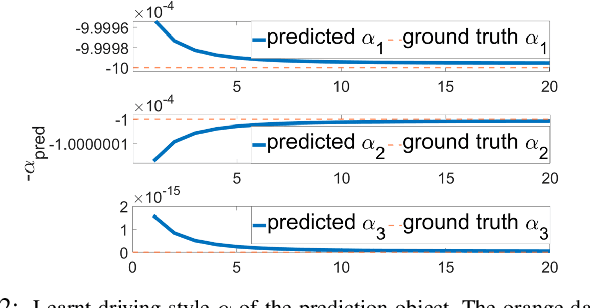
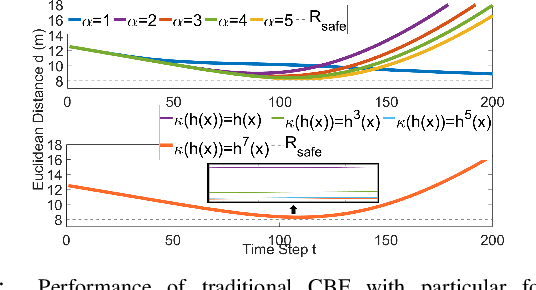
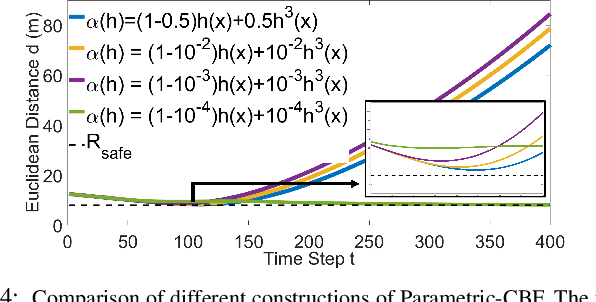
With the increasing emphasis on the safe autonomy for robots, model-based safe control approaches such as Control Barrier Functions have been extensively studied to ensure guaranteed safety during inter-robot interactions. In this paper, we introduce the Parametric Control Barrier Function (Parametric-CBF), a novel variant of the traditional Control Barrier Function to extend its expressivity in describing different safe behaviors among heterogeneous robots. Instead of assuming cooperative and homogeneous robots using the same safe controllers, the ego robot is able to model the neighboring robots' underlying safe controllers through different Parametric-CBFs with observed data. Given learned parametric-CBF and proved forward invariance, it provides greater flexibility for the ego robot to better coordinate with other heterogeneous robots with improved efficiency while enjoying formally provable safety guarantees. We demonstrate the usage of Parametric-CBF in behavior prediction and adaptive safe control in the ramp merging scenario from the applications of autonomous driving. Compared to traditional CBF, Parametric-CBF has the advantage of capturing varying drivers' characteristics given richer description of robot behavior in the context of safe control. Numerical simulations are given to validate the effectiveness of the proposed method.
Delay-aware Robust Control for Safe Autonomous Driving
Sep 15, 2021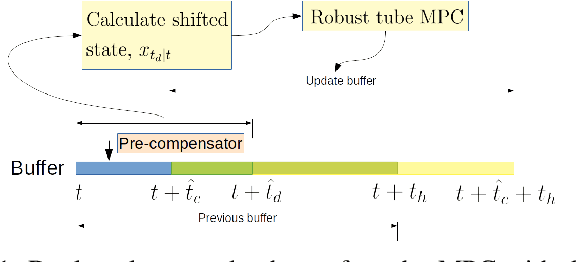
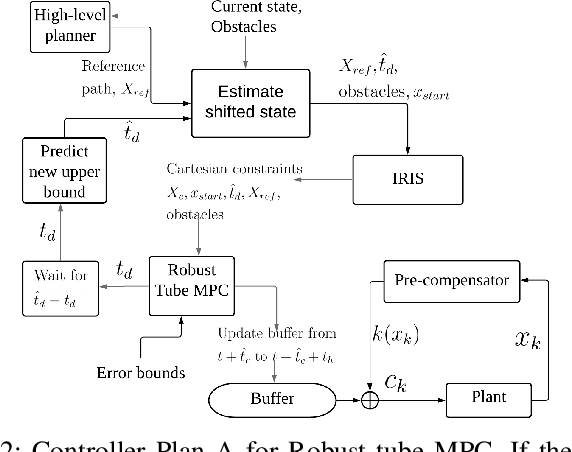
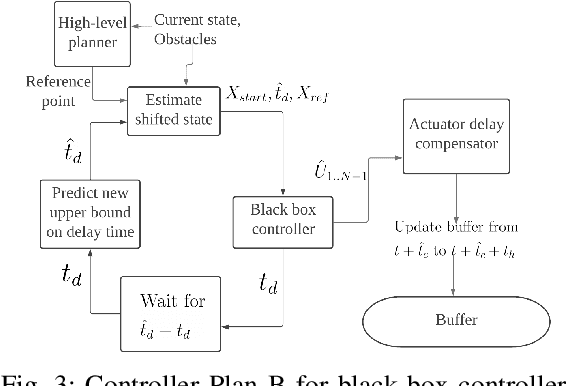
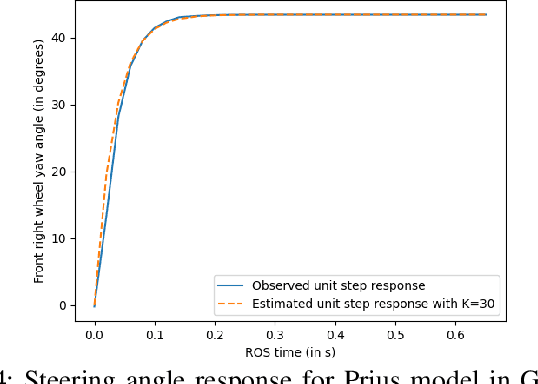
With the advancement of affordable self-driving vehicles using complicated nonlinear optimization but limited computation resources, computation time becomes a matter of concern. Other factors such as actuator dynamics and actuator command processing cost also unavoidably cause delays. In high-speed scenarios, these delays are critical to the safety of a vehicle. Recent works consider these delays individually, but none unifies them all in the context of autonomous driving. Moreover, recent works inappropriately consider computation time as a constant or a large upper bound, which makes the control either less responsive or over-conservative. To deal with all these delays, we present a unified framework by 1) modeling actuation dynamics, 2) using robust tube model predictive control, 3) using a novel adaptive Kalman filter without assuminga known process model and noise covariance, which makes the controller safe while minimizing conservativeness. On onehand, our approach can serve as a standalone controller; on theother hand, our approach provides a safety guard for a high-level controller, which assumes no delay. This can be used for compensating the sim-to-real gap when deploying a black-box learning-enabled controller trained in a simplistic environment without considering delays for practical vehicle systems.
Probabilistic Safety-Assured Adaptive Merging Control for Autonomous Vehicles
Apr 29, 2021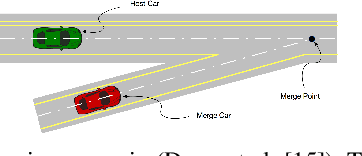
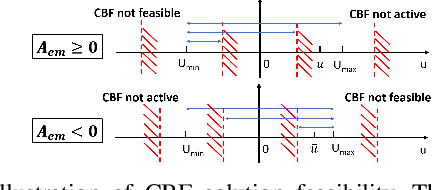
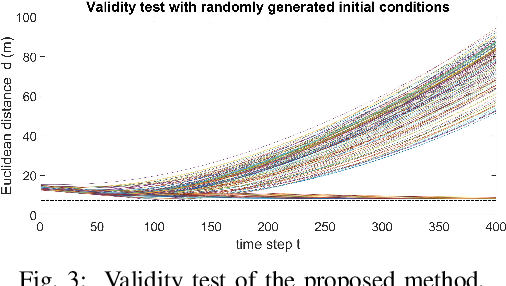
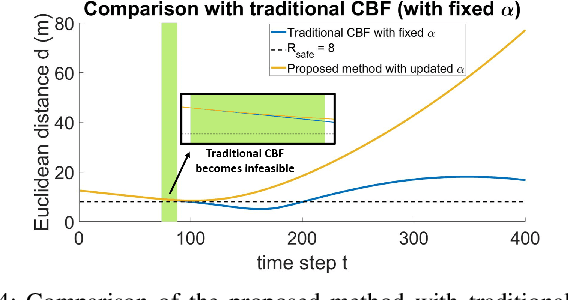
Autonomous vehicles face tremendous challenges while interacting with human drivers in different kinds of scenarios. Developing control methods with safety guarantees while performing interactions with uncertainty is an ongoing research goal. In this paper, we present a real-time safe control framework using bi-level optimization with Control Barrier Function (CBF) that enables an autonomous ego vehicle to interact with human-driven cars in ramp merging scenarios with a consistent safety guarantee. In order to explicitly address motion uncertainty, we propose a novel extension of control barrier functions to a probabilistic setting with provable chance-constrained safety and analyze the feasibility of our control design. The formulated bi-level optimization framework entails first choosing the ego vehicle's optimal driving style in terms of safety and primary objective, and then minimally modifying a nominal controller in the context of quadratic programming subject to the probabilistic safety constraints. This allows for adaptation to different driving strategies with a formally provable feasibility guarantee for the ego vehicle's safe controller. Experimental results are provided to demonstrate the effectiveness of our proposed approach.
Learning to Robustly Negotiate Bi-Directional Lane Usage in High-Conflict Driving Scenarios
Mar 22, 2021
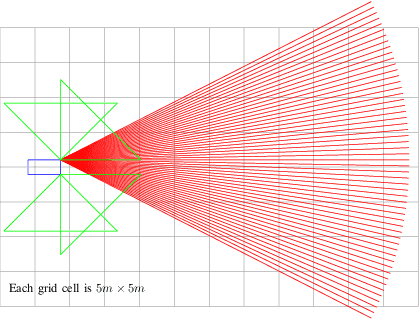
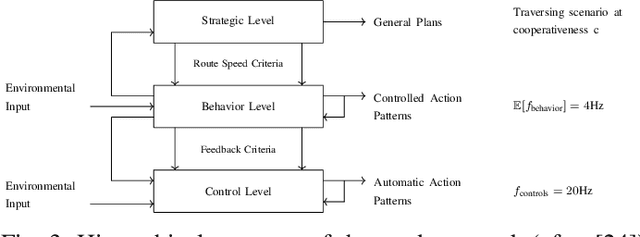
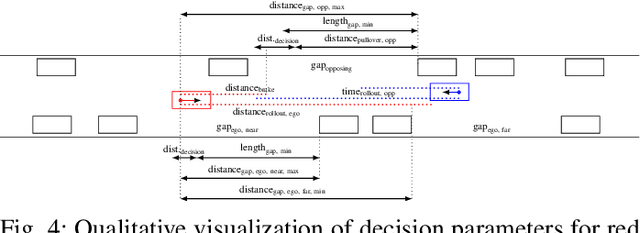
Recently, autonomous driving has made substantial progress in addressing the most common traffic scenarios like intersection navigation and lane changing. However, most of these successes have been limited to scenarios with well-defined traffic rules and require minimal negotiation with other vehicles. In this paper, we introduce a previously unconsidered, yet everyday, high-conflict driving scenario requiring negotiations between agents of equal rights and priorities. There exists no centralized control structure and we do not allow communications. Therefore, it is unknown if other drivers are willing to cooperate, and if so to what extent. We train policies to robustly negotiate with opposing vehicles of an unobservable degree of cooperativeness using multi-agent reinforcement learning (MARL). We propose Discrete Asymmetric Soft Actor-Critic (DASAC), a maximum-entropy off-policy MARL algorithm allowing for centralized training with decentralized execution. We show that using DASAC we are able to successfully negotiate and traverse the scenario considered over 99% of the time. Our agents are robust to an unknown timing of opponent decisions, an unobservable degree of cooperativeness of the opposing vehicle, and previously unencountered policies. Furthermore, they learn to exhibit human-like behaviors such as defensive driving, anticipating solution options and interpreting the behavior of other agents.
Trajectory Planning for Autonomous Vehicles Using Hierarchical Reinforcement Learning
Nov 09, 2020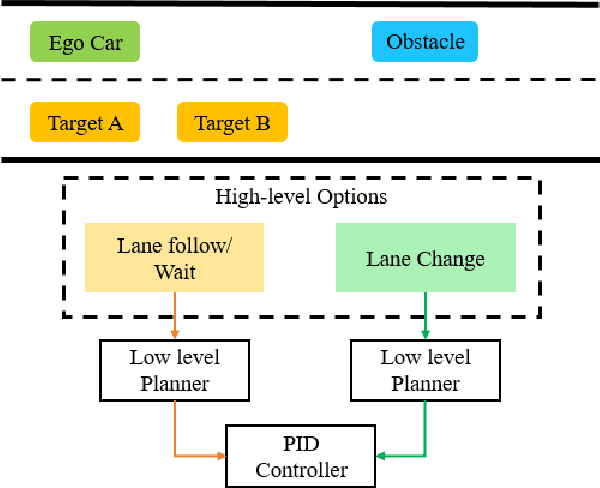
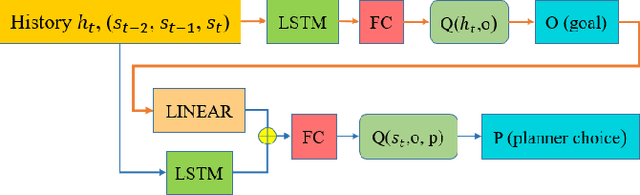
Planning safe trajectories under uncertain and dynamic conditions makes the autonomous driving problem significantly complex. Current sampling-based methods such as Rapidly Exploring Random Trees (RRTs) are not ideal for this problem because of the high computational cost. Supervised learning methods such as Imitation Learning lack generalization and safety guarantees. To address these problems and in order to ensure a robust framework, we propose a Hierarchical Reinforcement Learning (HRL) structure combined with a Proportional-Integral-Derivative (PID) controller for trajectory planning. HRL helps divide the task of autonomous vehicle driving into sub-goals and supports the network to learn policies for both high-level options and low-level trajectory planner choices. The introduction of sub-goals decreases convergence time and enables the policies learned to be reused for other scenarios. In addition, the proposed planner is made robust by guaranteeing smooth trajectories and by handling the noisy perception system of the ego-car. The PID controller is used for tracking the waypoints, which ensures smooth trajectories and reduces jerk. The problem of incomplete observations is handled by using a Long-Short-Term-Memory (LSTM) layer in the network. Results from the high-fidelity CARLA simulator indicate that the proposed method reduces convergence time, generates smoother trajectories, and is able to handle dynamic surroundings and noisy observations.
Safe Trajectory Planning Using Reinforcement Learning for Self Driving
Nov 09, 2020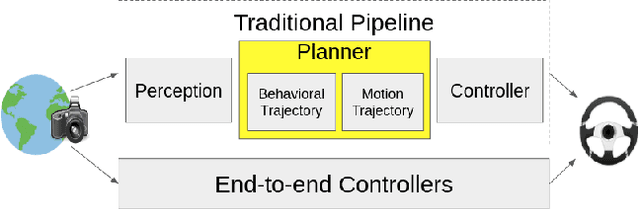

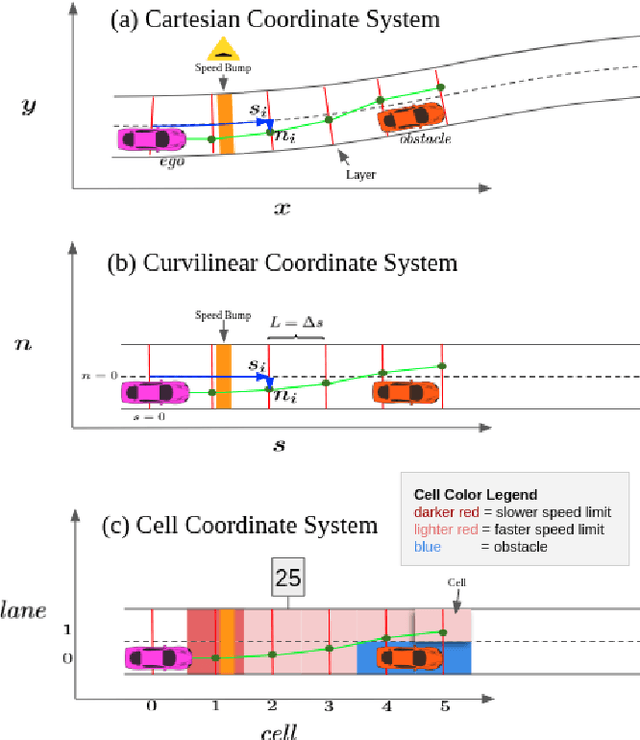
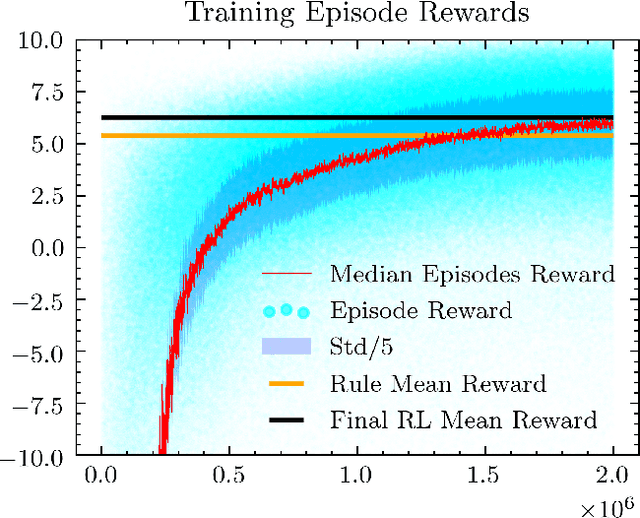
Self-driving vehicles must be able to act intelligently in diverse and difficult environments, marked by high-dimensional state spaces, a myriad of optimization objectives and complex behaviors. Traditionally, classical optimization and search techniques have been applied to the problem of self-driving; but they do not fully address operations in environments with high-dimensional states and complex behaviors. Recently, imitation learning has been proposed for the task of self-driving; but it is labor-intensive to obtain enough training data. Reinforcement learning has been proposed as a way to directly control the car, but this has safety and comfort concerns. We propose using model-free reinforcement learning for the trajectory planning stage of self-driving and show that this approach allows us to operate the car in a more safe, general and comfortable manner, required for the task of self driving.