 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep ResNet Blocks Sequentially using Boosting Theory
Jun 14, 2018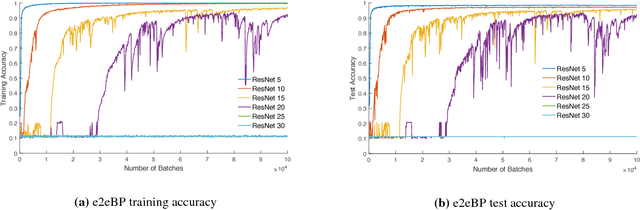
Deep neural networks are known to be difficult to train due to the instability of back-propagation. A deep \emph{residual network} (ResNet) with identity loops remedies this by stabilizing gradient computations. We prove a boosting theory for the ResNet architecture. We construct $T$ weak module classifiers, each contains two of the $T$ layers, such that the combined strong learner is a ResNet. Therefore, we introduce an alternative Deep ResNet training algorithm, \emph{BoostResNet}, which is particularly suitable in non-differentiable architectures. Our proposed algorithm merely requires a sequential training of $T$ "shallow ResNets" which are inexpensive. We prove that the training error decays exponentially with the depth $T$ if the \emph{weak module classifiers} that we train perform slightly better than some weak baseline. In other words, we propose a weak learning condition and prove a boosting theory for ResNet under the weak learning condition. Our results apply to general multi-class ResNets. A generalization error bound based on margin theory is proved and suggests ResNet's resistant to overfitting under network with $l_1$ norm bounded weights.
Efficient Contextual Bandits in Non-stationary Worlds
Jun 07, 2018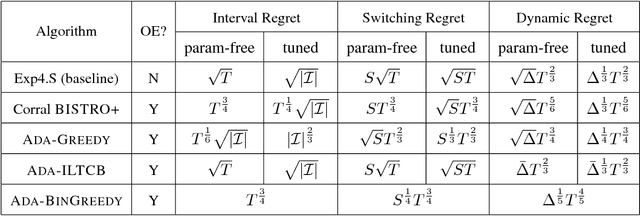
Most contextual bandit algorithms minimize regret against the best fixed policy, a questionable benchmark for non-stationary environments that are ubiquitous in applications. In this work, we develop several efficient contextual bandit algorithms for non-stationary environments by equipping existing methods for i.i.d. problems with sophisticated statistical tests so as to dynamically adapt to a change in distribution. We analyze various standard notions of regret suited to non-stationary environments for these algorithms, including interval regret, switching regret, and dynamic regret. When competing with the best policy at each time, one of our algorithms achieves regret $\mathcal{O}(\sqrt{ST})$ if there are $T$ rounds with $S$ stationary periods, or more generally $\mathcal{O}(\Delta^{1/3}T^{2/3})$ where $\Delta$ is some non-stationarity measure. These results almost match the optimal guarantees achieved by an inefficient baseline that is a variant of the classic Exp4 algorithm. The dynamic regret result is also the first one for efficient and fully adversarial contextual bandit. Furthermore, while the results above require tuning a parameter based on the unknown quantity $S$ or $\Delta$, we also develop a parameter free algorithm achieving regret $\min\{S^{1/4}T^{3/4}, \Delta^{1/5}T^{4/5}\}$. This improves and generalizes the best existing result $\Delta^{0.18}T^{0.82}$ by Karnin and Anava (2016) which only holds for the two-armed bandit problem.
A Contextual Bandit Bake-off
May 30, 2018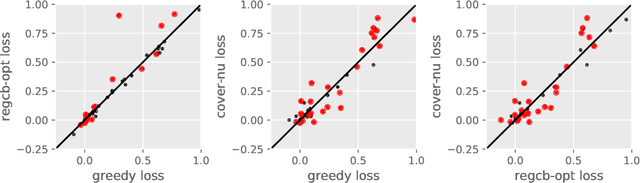

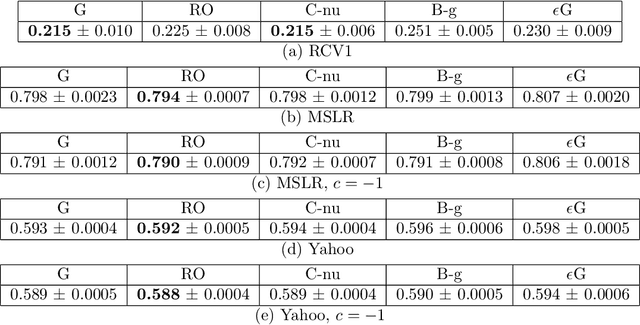
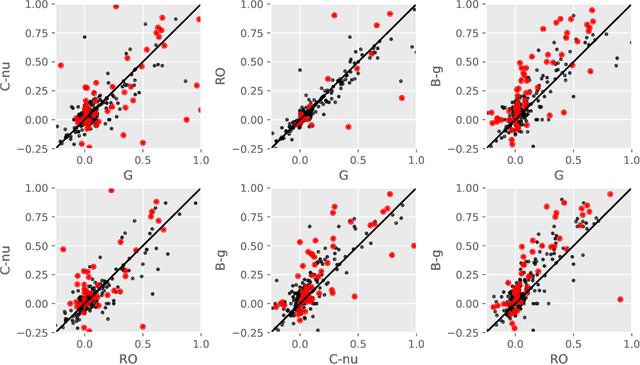
Contextual bandit algorithms are essential for solving many real-world interactive machine learning problems. Despite multiple recent successes on statistically and computationally efficient methods, the practical behavior of these algorithms is still poorly understood. We leverage the availability of large numbers of supervised learning datasets to compare and empirically optimize contextual bandit algorithms, focusing on practical methods that learn by relying on optimization oracles from supervised learning. We find that a recent method (Foster et al., 2018) using optimism under uncertainty works the best overall. A surprisingly close second is a simple greedy baseline that only explores implicitly through the diversity of contexts, followed by a variant of Online Cover (Agarwal et al., 2014) which tends to be more conservative but robust to problem specification by design. Along the way, we also evaluate and improve several internal components of contextual bandit algorithm design. Overall, this is a thorough study and review of contextual bandit methodology.
Active Learning for Cost-Sensitive Classification
Nov 13, 2017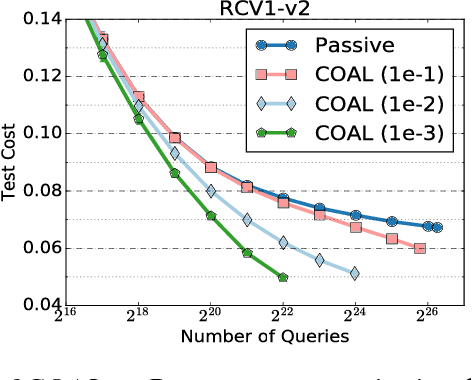
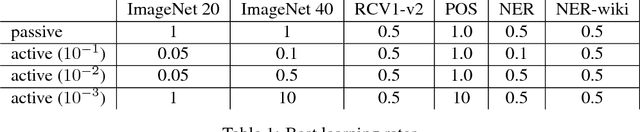
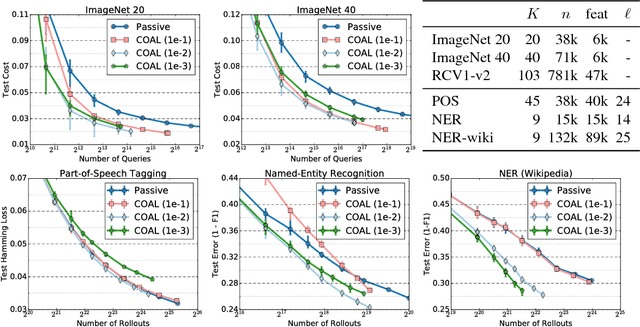
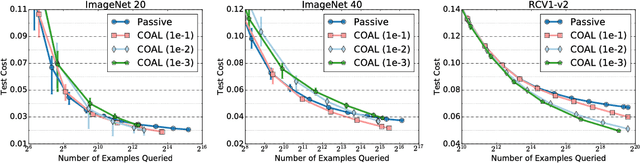
We design an active learning algorithm for cost-sensitive multiclass classification: problems where different errors have different costs. Our algorithm, COAL, makes predictions by regressing to each label's cost and predicting the smallest. On a new example, it uses a set of regressors that perform well on past data to estimate possible costs for each label. It queries only the labels that could be the best, ignoring the sure losers. We prove COAL can be efficiently implemented for any regression family that admits squared loss optimization; it also enjoys strong guarantees with respect to predictive performance and labeling effort. We empirically compare COAL to passive learning and several active learning baselines, showing significant improvements in labeling effort and test cost on real-world datasets.
Off-policy evaluation for slate recommendation
Nov 06, 2017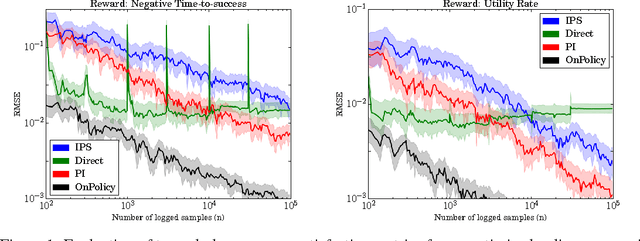
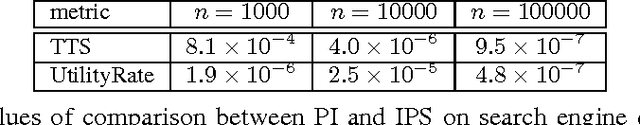
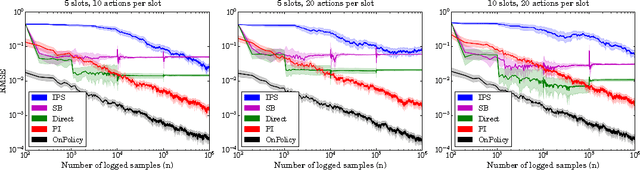
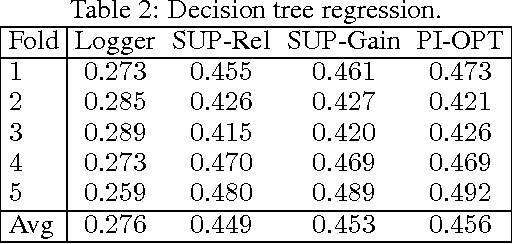
This paper studies the evaluation of policies that recommend an ordered set of items (e.g., a ranking) based on some context---a common scenario in web search, ads, and recommendation. We build on techniques from combinatorial bandits to introduce a new practical estimator that uses logged data to estimate a policy's performance. A thorough empirical evaluation on real-world data reveals that our estimator is accurate in a variety of settings, including as a subroutine in a learning-to-rank task, where it achieves competitive performance. We derive conditions under which our estimator is unbiased---these conditions are weaker than prior heuristics for slate evaluation---and experimentally demonstrate a smaller bias than parametric approaches, even when these conditions are violated. Finally, our theory and experiments also show exponential savings in the amount of required data compared with general unbiased estimators.
Efficient Second Order Online Learning by Sketching
Oct 17, 2017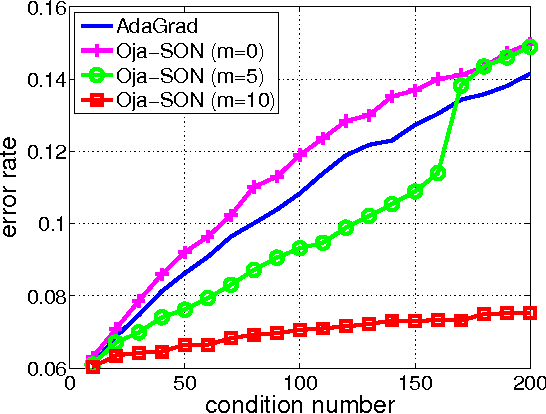
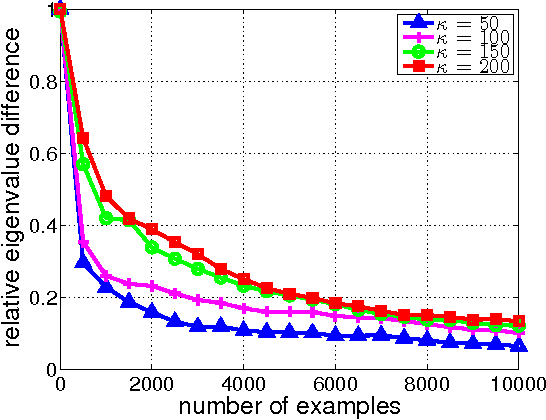
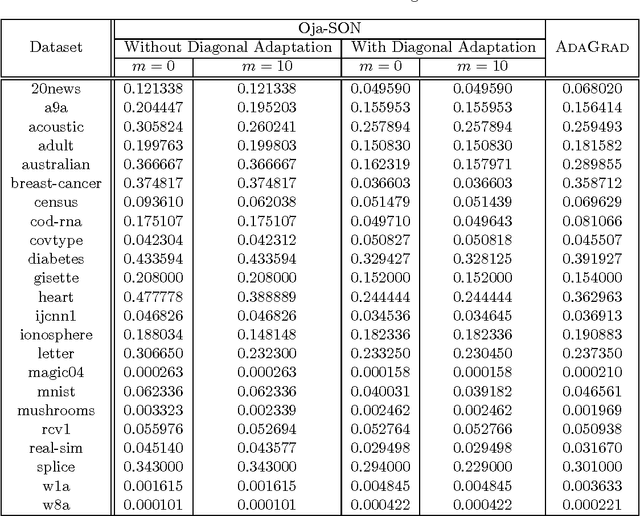
We propose Sketched Online Newton (SON), an online second order learning algorithm that enjoys substantially improved regret guarantees for ill-conditioned data. SON is an enhanced version of the Online Newton Step, which, via sketching techniques enjoys a running time linear in the dimension and sketch size. We further develop sparse forms of the sketching methods (such as Oja's rule), making the computation linear in the sparsity of features. Together, the algorithm eliminates all computational obstacles in previous second order online learning approaches.
Mapping Instructions and Visual Observations to Actions with Reinforcement Learning
Jul 22, 2017
We propose to directly map raw visual observations and text input to actions for instruction execution. While existing approaches assume access to structured environment representations or use a pipeline of separately trained models, we learn a single model to jointly reason about linguistic and visual input. We use reinforcement learning in a contextual bandit setting to train a neural network agent. To guide the agent's exploration, we use reward shaping with different forms of supervision. Our approach does not require intermediate representations, planning procedures, or training different models. We evaluate in a simulated environment, and show significant improvements over supervised learning and common reinforcement learning variants.
Making Contextual Decisions with Low Technical Debt
May 09, 2017

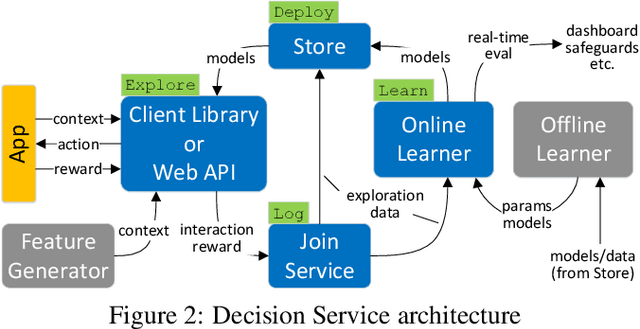
Applications and systems are constantly faced with decisions that require picking from a set of actions based on contextual information. Reinforcement-based learning algorithms such as contextual bandits can be very effective in these settings, but applying them in practice is fraught with technical debt, and no general system exists that supports them completely. We address this and create the first general system for contextual learning, called the Decision Service. Existing systems often suffer from technical debt that arises from issues like incorrect data collection and weak debuggability, issues we systematically address through our ML methodology and system abstractions. The Decision Service enables all aspects of contextual bandit learning using four system abstractions which connect together in a loop: explore (the decision space), log, learn, and deploy. Notably, our new explore and log abstractions ensure the system produces correct, unbiased data, which our learner uses for online learning and to enable real-time safeguards, all in a fully reproducible manner. The Decision Service has a simple user interface and works with a variety of applications: we present two live production deployments for content recommendation that achieved click-through improvements of 25-30%, another with 18% revenue lift in the landing page, and ongoing applications in tech support and machine failure handling. The service makes real-time decisions and learns continuously and scalably, while significantly lowering technical debt.
Contextual Decision Processes with Low Bellman Rank are PAC-Learnable
Dec 01, 2016
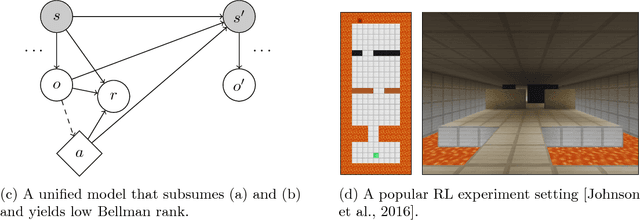
This paper studies systematic exploration for reinforcement learning with rich observations and function approximation. We introduce a new model called contextual decision processes, that unifies and generalizes most prior settings. Our first contribution is a complexity measure, the Bellman rank, that we show enables tractable learning of near-optimal behavior in these processes and is naturally small for many well-studied reinforcement learning settings. Our second contribution is a new reinforcement learning algorithm that engages in systematic exploration to learn contextual decision processes with low Bellman rank. Our algorithm provably learns near-optimal behavior with a number of samples that is polynomial in all relevant parameters but independent of the number of unique observations. The approach uses Bellman error minimization with optimistic exploration and provides new insights into efficient exploration for reinforcement learning with function approximation.
Logarithmic Time One-Against-Some
Dec 01, 2016


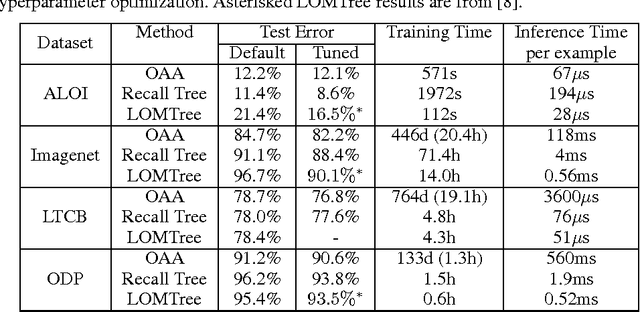
We create a new online reduction of multiclass classification to binary classification for which training and prediction time scale logarithmically with the number of classes. Compared to previous approaches, we obtain substantially better statistical performance for two reasons: First, we prove a tighter and more complete boosting theorem, and second we translate the results more directly into an algorithm. We show that several simple techniques give rise to an algorithm that can compete with one-against-all in both space and predictive power while offering exponential improvements in speed when the number of classes is large.