 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Sensitivity of Reward Inference to Misspecified Human Models
Dec 09, 2022



Inferring reward functions from human behavior is at the center of value alignment - aligning AI objectives with what we, humans, actually want. But doing so relies on models of how humans behave given their objectives. After decades of research in cognitive science, neuroscience, and behavioral economics, obtaining accurate human models remains an open research topic. This begs the question: how accurate do these models need to be in order for the reward inference to be accurate? On the one hand, if small errors in the model can lead to catastrophic error in inference, the entire framework of reward learning seems ill-fated, as we will never have perfect models of human behavior. On the other hand, if as our models improve, we can have a guarantee that reward accuracy also improves, this would show the benefit of more work on the modeling side. We study this question both theoretically and empirically. We do show that it is unfortunately possible to construct small adversarial biases in behavior that lead to arbitrarily large errors in the inferred reward. However, and arguably more importantly, we are also able to identify reasonable assumptions under which the reward inference error can be bounded linearly in the error in the human model. Finally, we verify our theoretical insights in discrete and continuous control tasks with simulated and human data.
Confidence-Conditioned Value Functions for Offline Reinforcement Learning
Dec 08, 2022Offline reinforcement learning (RL) promises the ability to learn effective policies solely using existing, static datasets, without any costly online interaction. To do so, offline RL methods must handle distributional shift between the dataset and the learned policy. The most common approach is to learn conservative, or lower-bound, value functions, which underestimate the return of out-of-distribution (OOD) actions. However, such methods exhibit one notable drawback: policies optimized on such value functions can only behave according to a fixed, possibly suboptimal, degree of conservatism. However, this can be alleviated if we instead are able to learn policies for varying degrees of conservatism at training time and devise a method to dynamically choose one of them during evaluation. To do so, in this work, we propose learning value functions that additionally condition on the degree of conservatism, which we dub confidence-conditioned value functions. We derive a new form of a Bellman backup that simultaneously learns Q-values for any degree of confidence with high probability. By conditioning on confidence, our value functions enable adaptive strategies during online evaluation by controlling for confidence level using the history of observations thus far. This approach can be implemented in practice by conditioning the Q-function from existing conservative algorithms on the confidence. We theoretically show that our learned value functions produce conservative estimates of the true value at any desired confidence. Finally, we empirically show that our algorithm outperforms existing conservative offline RL algorithms on multiple discrete control domains.
When Should We Prefer Offline Reinforcement Learning Over Behavioral Cloning?
Apr 12, 2022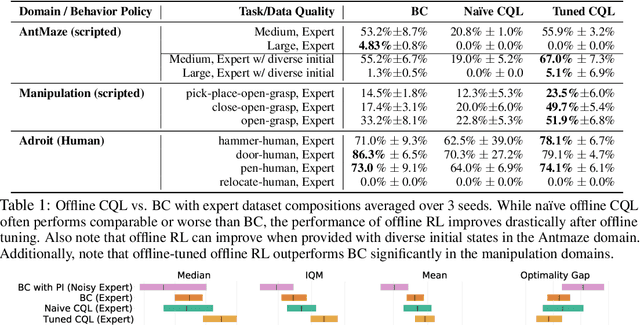
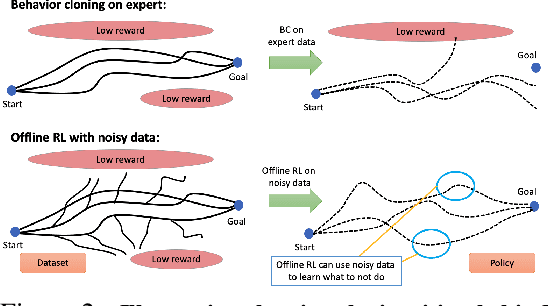
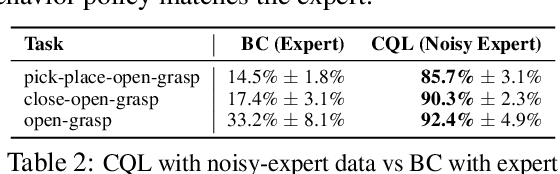
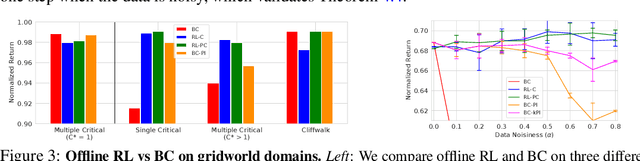
Offline reinforcement learning (RL) algorithms can acquire effective policies by utilizing previously collected experience, without any online interaction. It is widely understood that offline RL is able to extract good policies even from highly suboptimal data, a scenario where imitation learning finds suboptimal solutions that do not improve over the demonstrator that generated the dataset. However, another common use case for practitioners is to learn from data that resembles demonstrations. In this case, one can choose to apply offline RL, but can also use behavioral cloning (BC) algorithms, which mimic a subset of the dataset via supervised learning. Therefore, it seems natural to ask: when can an offline RL method outperform BC with an equal amount of expert data, even when BC is a natural choice? To answer this question, we characterize the properties of environments that allow offline RL methods to perform better than BC methods, even when only provided with expert data. Additionally, we show that policies trained on sufficiently noisy suboptimal data can attain better performance than even BC algorithms with expert data, especially on long-horizon problems. We validate our theoretical results via extensive experiments on both diagnostic and high-dimensional domains including robotic manipulation, maze navigation, and Atari games, with a variety of data distributions. We observe that, under specific but common conditions such as sparse rewards or noisy data sources, modern offline RL methods can significantly outperform BC.
Compositional Generalization and Decomposition in Neural Program Synthesis
Apr 07, 2022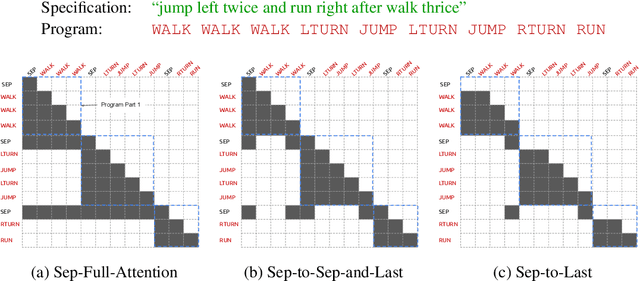
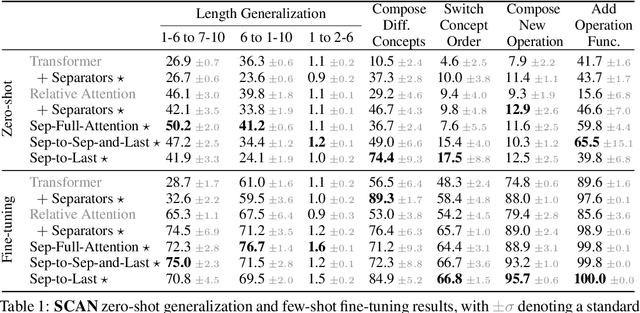
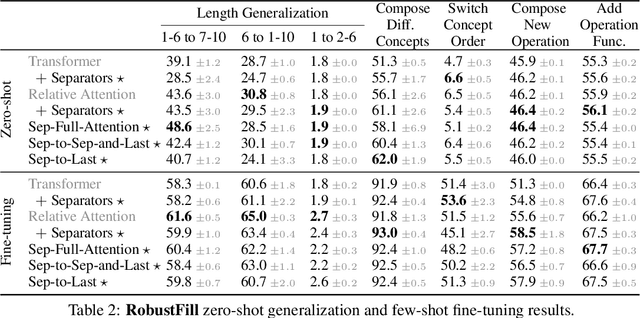

When writing programs, people have the ability to tackle a new complex task by decomposing it into smaller and more familiar subtasks. While it is difficult to measure whether neural program synthesis methods have similar capabilities, what we can measure is whether they compositionally generalize, that is, whether a model that has been trained on the simpler subtasks is subsequently able to solve more complex tasks. In this paper, we focus on measuring the ability of learned program synthesizers to compositionally generalize. We first characterize several different axes along which program synthesis methods would be desired to generalize, e.g., length generalization, or the ability to combine known subroutines in new ways that do not occur in the training data. Based on this characterization, we introduce a benchmark suite of tasks to assess these abilities based on two popular existing datasets, SCAN and RobustFill. Finally, we make first attempts to improve the compositional generalization ability of Transformer models along these axes through novel attention mechanisms that draw inspiration from a human-like decomposition strategy. Empirically, we find our modified Transformer models generally perform better than natural baselines, but the tasks remain challenging.
Deep Hierarchy in Bandits
Feb 03, 2022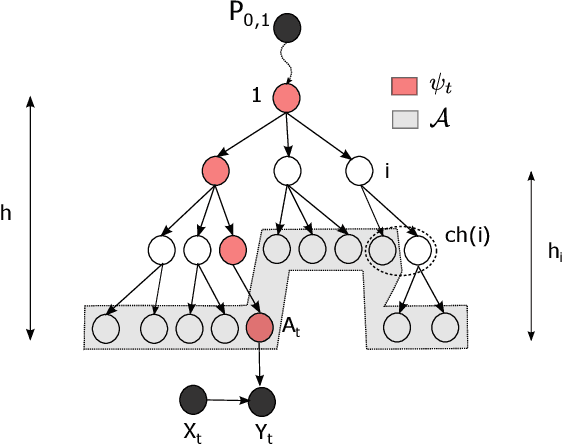
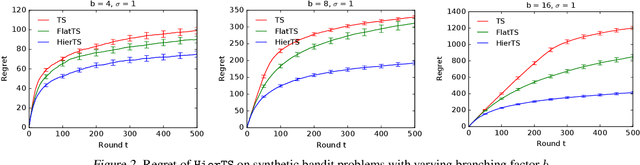
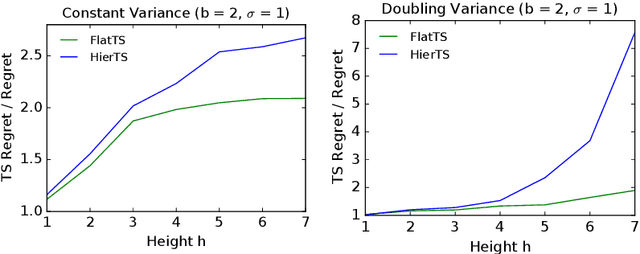
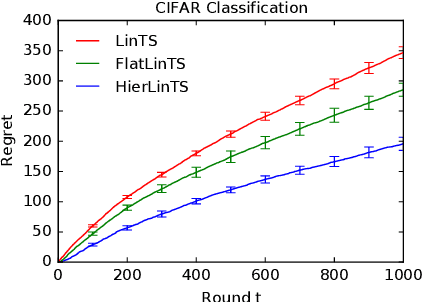
Mean rewards of actions are often correlated. The form of these correlations may be complex and unknown a priori, such as the preferences of a user for recommended products and their categories. To maximize statistical efficiency, it is important to leverage these correlations when learning. We formulate a bandit variant of this problem where the correlations of mean action rewards are represented by a hierarchical Bayesian model with latent variables. Since the hierarchy can have multiple layers, we call it deep. We propose a hierarchical Thompson sampling algorithm (HierTS) for this problem, and show how to implement it efficiently for Gaussian hierarchies. The efficient implementation is possible due to a novel exact hierarchical representation of the posterior, which itself is of independent interest. We use this exact posterior to analyze the Bayes regret of HierTS in Gaussian bandits. Our analysis reflects the structure of the problem, that the regret decreases with the prior width, and also shows that hierarchies reduce the regret by non-constant factors in the number of actions. We confirm these theoretical findings empirically, in both synthetic and real-world experiments.
Hierarchical Bayesian Bandits
Nov 12, 2021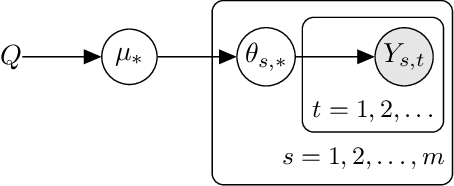
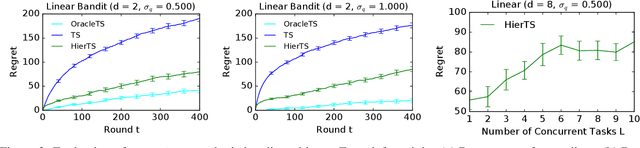
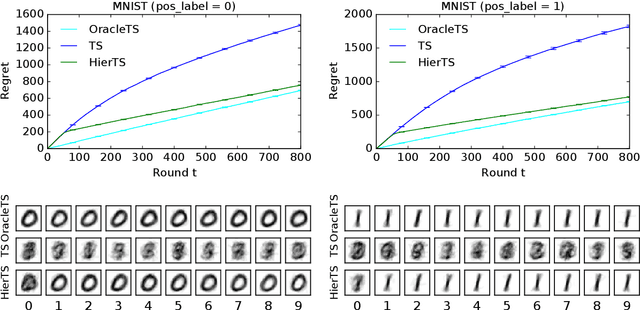
Meta-, multi-task, and federated learning can be all viewed as solving similar tasks, drawn from an unknown distribution that reflects task similarities. In this work, we provide a unified view of all these problems, as learning to act in a hierarchical Bayesian bandit. We analyze a natural hierarchical Thompson sampling algorithm (hierTS) that can be applied to any problem in this class. Our regret bounds hold under many instances of such problems, including when the tasks are solved sequentially or in parallel; and capture the structure of the problems, such that the regret decreases with the width of the task prior. Our proofs rely on novel total variance decompositions, which can be applied to other graphical model structures. Finally, our theory is complemented by experiments, which show that the hierarchical structure helps with knowledge sharing among the tasks. This confirms that hierarchical Bayesian bandits are a universal and statistically-efficient tool for learning to act with similar bandit tasks.
Thompson Sampling with a Mixture Prior
Jun 10, 2021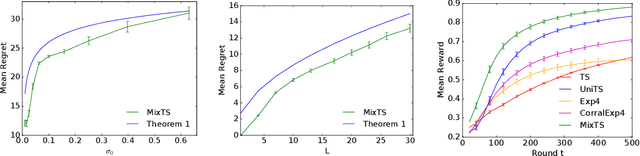
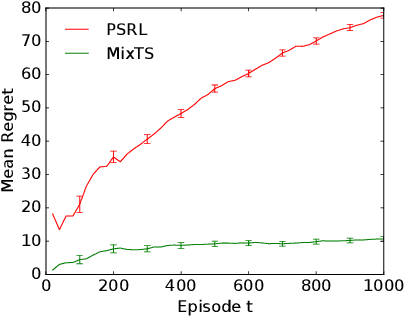
We study Thompson sampling (TS) in online decision-making problems where the uncertain environment is sampled from a mixture distribution. This is relevant to multi-task settings, where a learning agent is faced with different classes of problems. We incorporate this structure in a natural way by initializing TS with a mixture prior -- dubbed MixTS -- and develop a novel, general technique for analyzing the regret of TS with such priors. We apply this technique to derive Bayes regret bounds for MixTS in both linear bandits and tabular Markov decision processes (MDPs). Our regret bounds reflect the structure of the problem and depend on the number of components and confidence width of each component of the prior. Finally, we demonstrate the empirical effectiveness of MixTS in both synthetic and real-world experiments.
Non-Stationary Latent Bandits
Dec 01, 2020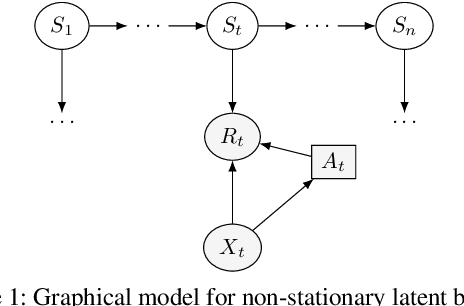
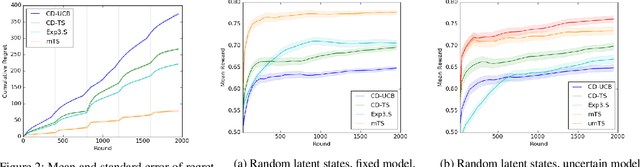
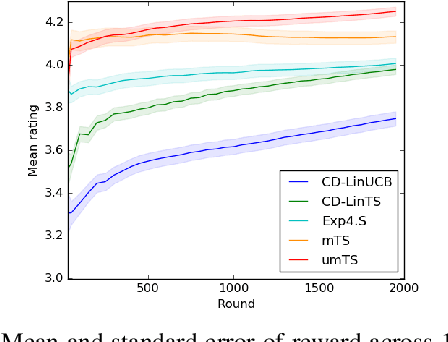
Users of recommender systems often behave in a non-stationary fashion, due to their evolving preferences and tastes over time. In this work, we propose a practical approach for fast personalization to non-stationary users. The key idea is to frame this problem as a latent bandit, where the prototypical models of user behavior are learned offline and the latent state of the user is inferred online from its interactions with the models. We call this problem a non-stationary latent bandit. We propose Thompson sampling algorithms for regret minimization in non-stationary latent bandits, analyze them, and evaluate them on a real-world dataset. The main strength of our approach is that it can be combined with rich offline-learned models, which can be misspecified, and are subsequently fine-tuned online using posterior sampling. In this way, we naturally combine the strengths of offline and online learning.
Latent Programmer: Discrete Latent Codes for Program Synthesis
Dec 01, 2020

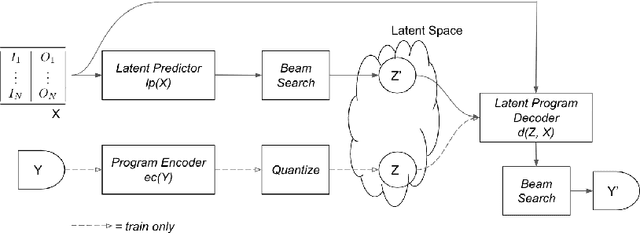

In many sequence learning tasks, such as program synthesis and document summarization, a key problem is searching over a large space of possible output sequences. We propose to learn representations of the outputs that are specifically meant for search: rich enough to specify the desired output but compact enough to make search more efficient. Discrete latent codes are appealing for this purpose, as they naturally allow sophisticated combinatorial search strategies. The latent codes are learned using a self-supervised learning principle, in which first a discrete autoencoder is trained on the output sequences, and then the resulting latent codes are used as intermediate targets for the end-to-end sequence prediction task. Based on these insights, we introduce the \emph{Latent Programmer}, a program synthesis method that first predicts a discrete latent code from input/output examples, and then generates the program in the target language. We evaluate the Latent Programmer on two domains: synthesis of string transformation programs, and generation of programs from natural language descriptions. We demonstrate that the discrete latent representation significantly improves synthesis accuracy.
Latent Bandits Revisited
Jun 15, 2020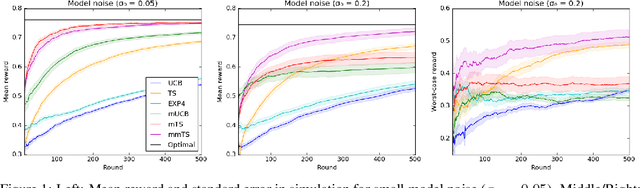
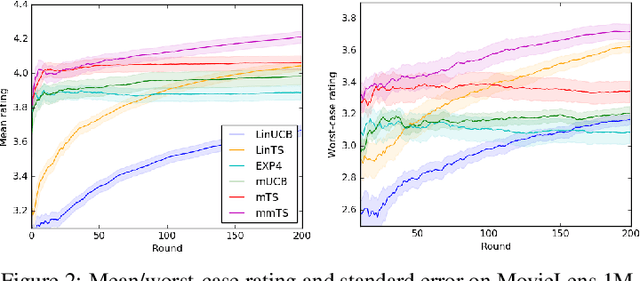
A latent bandit problem is one in which the learning agent knows the arm reward distributions conditioned on an unknown discrete latent state. The primary goal of the agent is to identify the latent state, after which it can act optimally. This setting is a natural midpoint between online and offline learning---complex models can be learned offline with the agent identifying latent state online---of practical relevance in, say, recommender systems. In this work, we propose general algorithms for this setting, based on both upper confidence bounds (UCBs) and Thompson sampling. Our methods are contextual and aware of model uncertainty and misspecification. We provide a unified theoretical analysis of our algorithms, which have lower regret than classic bandit policies when the number of latent states is smaller than actions. A comprehensive empirical study showcases the advantages of our approach.