 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpurious Valleys in Two-layer Neural Network Optimization Landscapes
Sep 26, 2018Neural networks provide a rich class of high-dimensional, non-convex optimization problems. Despite their non-convexity, gradient-descent methods often successfully optimize these models. This has motivated a recent spur in research attempting to characterize properties of their loss surface that may explain such success. In this paper, we address this phenomenon by studying a key topological property of the loss: the presence or absence of spurious valleys, defined as connected components of sub-level sets that do not include a global minimum. Focusing on a class of two-layer neural networks defined by smooth (but generally non-linear) activation functions, we identify a notion of intrinsic dimension and show that it provides necessary and sufficient conditions for the absence of spurious valleys. More concretely, finite intrinsic dimension guarantees that for sufficiently overparametrised models no spurious valleys exist, independently of the data distribution. Conversely, infinite intrinsic dimension implies that spurious valleys do exist for certain data distributions, independently of model overparametrisation. Besides these positive and negative results, we show that, although spurious valleys may exist in general, they are confined to low risk levels and avoided with high probability on overparametrised models.
Graph Neural Networks for IceCube Signal Classification
Sep 17, 2018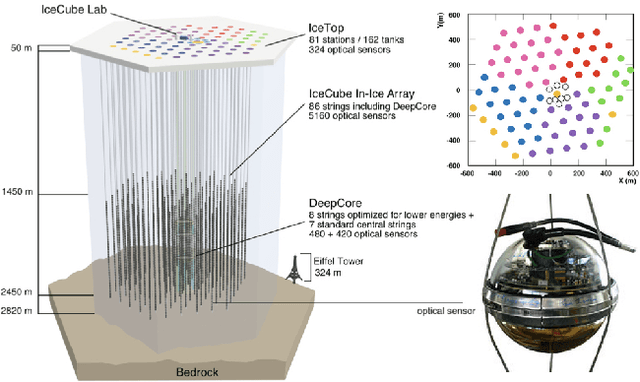
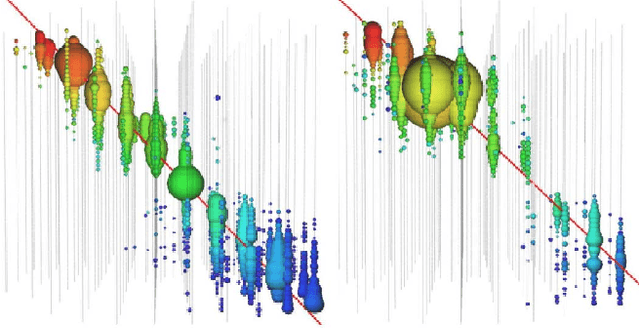
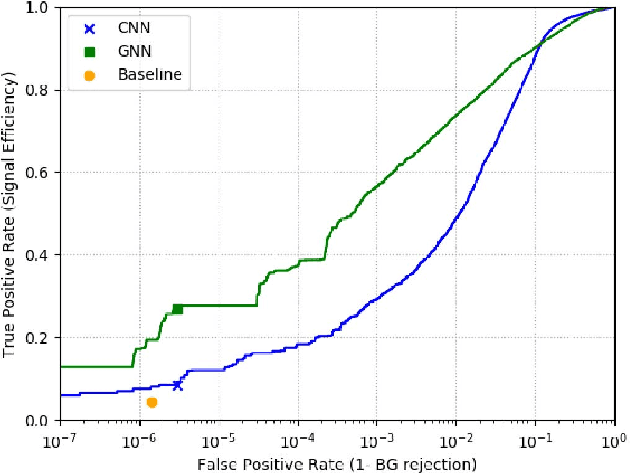
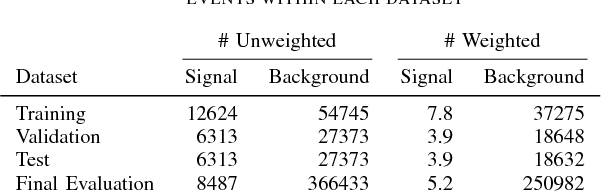
Tasks involving the analysis of geometric (graph- and manifold-structured) data have recently gained prominence in the machine learning community, giving birth to a rapidly developing field of geometric deep learning. In this work, we leverage graph neural networks to improve signal detection in the IceCube neutrino observatory. The IceCube detector array is modeled as a graph, where vertices are sensors and edges are a learned function of the sensors' spatial coordinates. As only a subset of IceCube's sensors is active during a given observation, we note the adaptive nature of our GNN, wherein computation is restricted to the input signal support. We demonstrate the effectiveness of our GNN architecture on a task classifying IceCube events, where it outperforms both a traditional physics-based method as well as classical 3D convolution neural networks.
Planning with Arithmetic and Geometric Attributes
Sep 06, 2018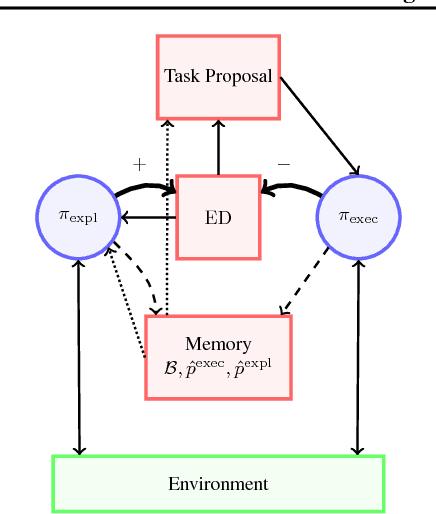



A desirable property of an intelligent agent is its ability to understand its environment to quickly generalize to novel tasks and compose simpler tasks into more complex ones. If the environment has geometric or arithmetic structure, the agent should exploit these for faster generalization. Building on recent work that augments the environment with user-specified attributes, we show that further equipping these attributes with the appropriate geometric and arithmetic structure brings substantial gains in sample complexity.
Revised Note on Learning Algorithms for Quadratic Assignment with Graph Neural Networks
Aug 30, 2018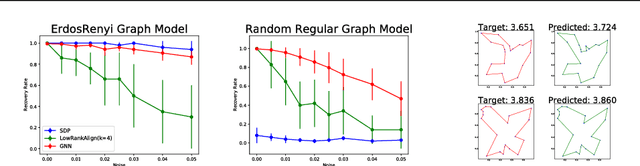
Inverse problems correspond to a certain type of optimization problems formulated over appropriate input distributions. Recently, there has been a growing interest in understanding the computational hardness of these optimization problems, not only in the worst case, but in an average-complexity sense under this same input distribution. In this revised note, we are interested in studying another aspect of hardness, related to the ability to learn how to solve a problem by simply observing a collection of previously solved instances. These 'planted solutions' are used to supervise the training of an appropriate predictive model that parametrizes a broad class of algorithms, with the hope that the resulting model will provide good accuracy-complexity tradeoffs in the average sense. We illustrate this setup on the Quadratic Assignment Problem, a fundamental problem in Network Science. We observe that data-driven models based on Graph Neural Networks offer intriguingly good performance, even in regimes where standard relaxation based techniques appear to suffer.
Diffusion Scattering Transforms on Graphs
Jun 22, 2018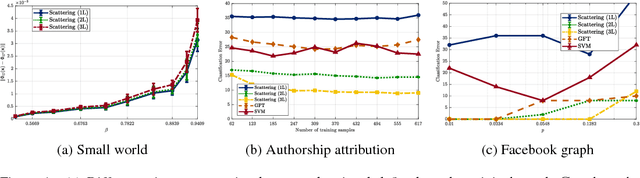
Stability is a key aspect of data analysis. In many applications, the natural notion of stability is geometric, as illustrated for example in computer vision. Scattering transforms construct deep convolutional representations which are certified stable to input deformations. This stability to deformations can be interpreted as stability with respect to changes in the metric structure of the domain. In this work, we show that scattering transforms can be generalized to non-Euclidean domains using diffusion wavelets, while preserving a notion of stability with respect to metric changes in the domain, measured with diffusion maps. The resulting representation is stable to metric perturbations of the domain while being able to capture "high-frequency" information, akin to the Euclidean Scattering.
Surface Networks
Jun 18, 2018
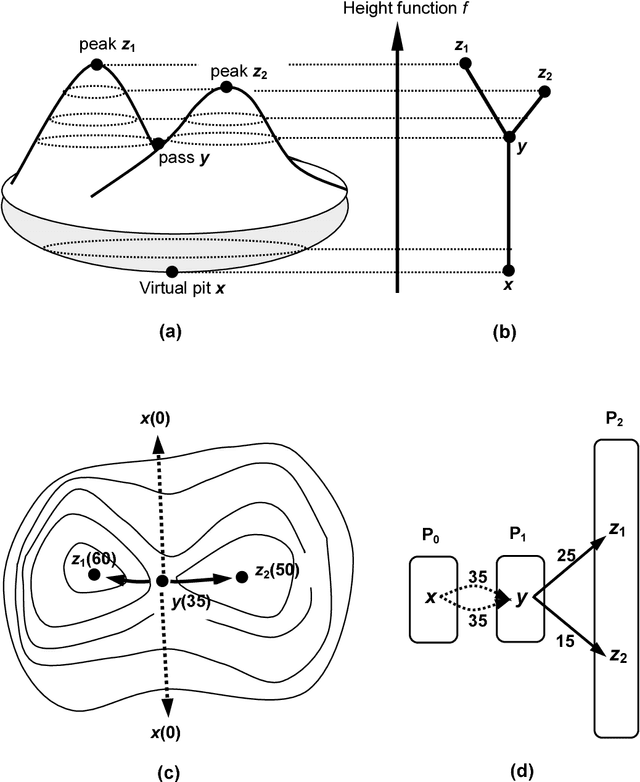
We study data-driven representations for three-dimensional triangle meshes, which are one of the prevalent objects used to represent 3D geometry. Recent works have developed models that exploit the intrinsic geometry of manifolds and graphs, namely the Graph Neural Networks (GNNs) and its spectral variants, which learn from the local metric tensor via the Laplacian operator. Despite offering excellent sample complexity and built-in invariances, intrinsic geometry alone is invariant to isometric deformations, making it unsuitable for many applications. To overcome this limitation, we propose several upgrades to GNNs to leverage extrinsic differential geometry properties of three-dimensional surfaces, increasing its modeling power. In particular, we propose to exploit the Dirac operator, whose spectrum detects principal curvature directions --- this is in stark contrast with the classical Laplace operator, which directly measures mean curvature. We coin the resulting models \emph{Surface Networks (SN)}. We prove that these models define shape representations that are stable to deformation and to discretization, and we demonstrate the efficiency and versatility of SNs on two challenging tasks: temporal prediction of mesh deformations under non-linear dynamics and generative models using a variational autoencoder framework with encoders/decoders given by SNs.
Few-Shot Learning with Graph Neural Networks
Feb 20, 2018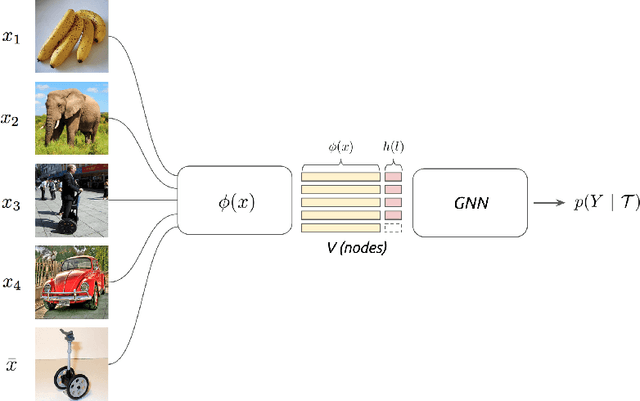
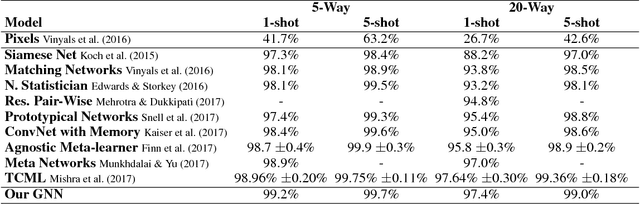
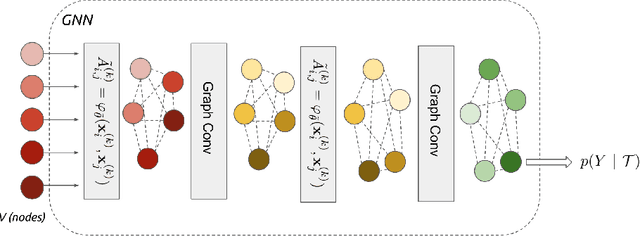
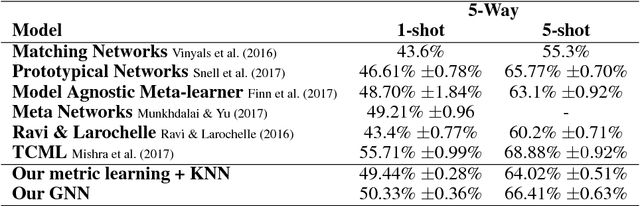
We propose to study the problem of few-shot learning with the prism of inference on a partially observed graphical model, constructed from a collection of input images whose label can be either observed or not. By assimilating generic message-passing inference algorithms with their neural-network counterparts, we define a graph neural network architecture that generalizes several of the recently proposed few-shot learning models. Besides providing improved numerical performance, our framework is easily extended to variants of few-shot learning, such as semi-supervised or active learning, demonstrating the ability of graph-based models to operate well on 'relational' tasks.
Multiscale Sparse Microcanonical Models
Jan 06, 2018
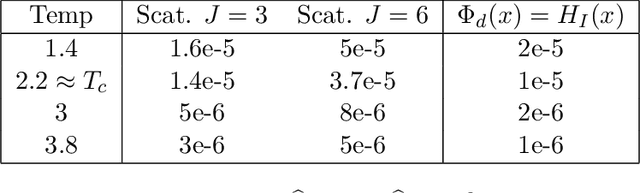
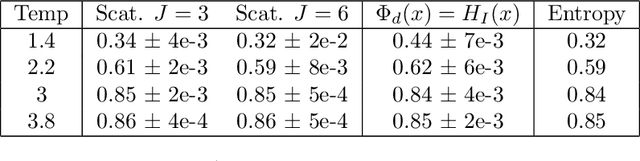

We study density estimation of stationary processes defined over an infinite grid from a single, finite realization. Gaussian Processes and Markov Random Fields avoid the curse of dimensionality by focusing on low-order and localized potentials respectively, but its application to complex datasets is limited by their inability to capture singularities and long-range interactions, and their expensive inference and learning respectively. These are instances of Gibbs models, defined as maximum entropy distributions under moment constraints determined by an energy vector. The Boltzmann equivalence principle states that under appropriate ergodicity, such \emph{macrocanonical} models are approximated by their \emph{microcanonical} counterparts, which replace the expectation by the sample average. Microcanonical models are appealing since they avoid computing expensive Lagrange multipliers to meet the constraints. This paper introduces microcanonical measures whose energy vector is given by a wavelet scattering transform, built by cascading wavelet decompositions and point-wise nonlinearities. We study asymptotic properties of generic microcanonical measures, which reveal the fundamental role of the differential structure of the energy vector in controlling e.g. the entropy rate. Gradient information is also used to define a microcanonical sampling algorithm, for which we provide convergence analysis to the microcanonical measure. Whereas wavelet transforms capture local regularity at different scales, scattering transforms provide scale interaction information, critical to restore the geometry of many physical phenomena. We demonstrate the efficiency of sparse multiscale microcanonical measures on several processes and real data exhibiting long-range interactions, such as Ising, Cox Processes and image and audio textures.
Mathematics of Deep Learning
Dec 13, 2017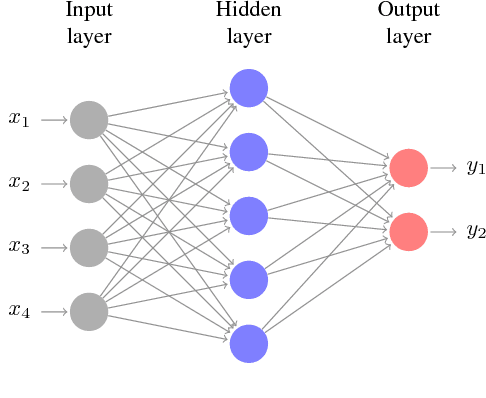
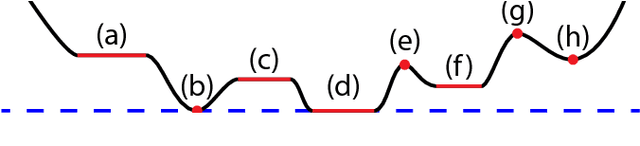
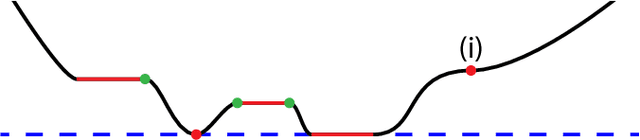
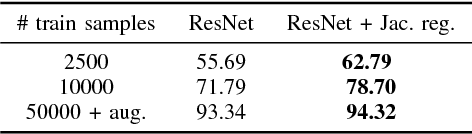
Recently there has been a dramatic increase in the performance of recognition systems due to the introduction of deep architectures for representation learning and classification. However, the mathematical reasons for this success remain elusive. This tutorial will review recent work that aims to provide a mathematical justification for several properties of deep networks, such as global optimality, geometric stability, and invariance of the learned representations.
Understanding the Learned Iterative Soft Thresholding Algorithm with matrix factorization
Jun 02, 2017

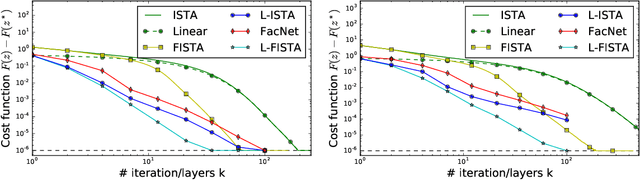
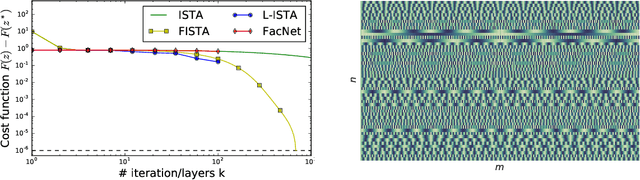
Sparse coding is a core building block in many data analysis and machine learning pipelines. Typically it is solved by relying on generic optimization techniques, such as the Iterative Soft Thresholding Algorithm and its accelerated version (ISTA, FISTA). These methods are optimal in the class of first-order methods for non-smooth, convex functions. However, they do not exploit the particular structure of the problem at hand nor the input data distribution. An acceleration using neural networks, coined LISTA, was proposed in Gregor and Le Cun (2010), which showed empirically that one could achieve high quality estimates with few iterations by modifying the parameters of the proximal splitting appropriately. In this paper we study the reasons for such acceleration. Our mathematical analysis reveals that it is related to a specific matrix factorization of the Gram kernel of the dictionary, which attempts to nearly diagonalise the kernel with a basis that produces a small perturbation of the $\ell_1$ ball. When this factorization succeeds, we prove that the resulting splitting algorithm enjoys an improved convergence bound with respect to the non-adaptive version. Moreover, our analysis also shows that conditions for acceleration occur mostly at the beginning of the iterative process, consistent with numerical experiments. We further validate our analysis by showing that on dictionaries where this factorization does not exist, adaptive acceleration fails.