 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLattice-Based Methods Surpass Sum-of-Squares in Clustering
Jan 07, 2022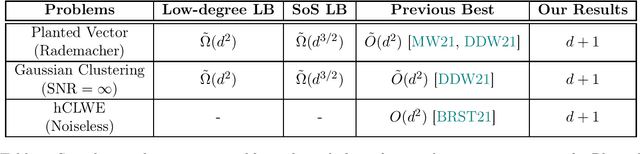
Clustering is a fundamental primitive in unsupervised learning which gives rise to a rich class of computationally-challenging inference tasks. In this work, we focus on the canonical task of clustering d-dimensional Gaussian mixtures with unknown (and possibly degenerate) covariance. Recent works (Ghosh et al. '20; Mao, Wein '21; Davis, Diaz, Wang '21) have established lower bounds against the class of low-degree polynomial methods and the sum-of-squares (SoS) hierarchy for recovering certain hidden structures planted in Gaussian clustering instances. Prior work on many similar inference tasks portends that such lower bounds strongly suggest the presence of an inherent statistical-to-computational gap for clustering, that is, a parameter regime where the clustering task is statistically possible but no polynomial-time algorithm succeeds. One special case of the clustering task we consider is equivalent to the problem of finding a planted hypercube vector in an otherwise random subspace. We show that, perhaps surprisingly, this particular clustering model does not exhibit a statistical-to-computational gap, even though the aforementioned low-degree and SoS lower bounds continue to apply in this case. To achieve this, we give a polynomial-time algorithm based on the Lenstra--Lenstra--Lovasz lattice basis reduction method which achieves the statistically-optimal sample complexity of d+1 samples. This result extends the class of problems whose conjectured statistical-to-computational gaps can be "closed" by "brittle" polynomial-time algorithms, highlighting the crucial but subtle role of noise in the onset of statistical-to-computational gaps.
Quantile Filtered Imitation Learning
Dec 02, 2021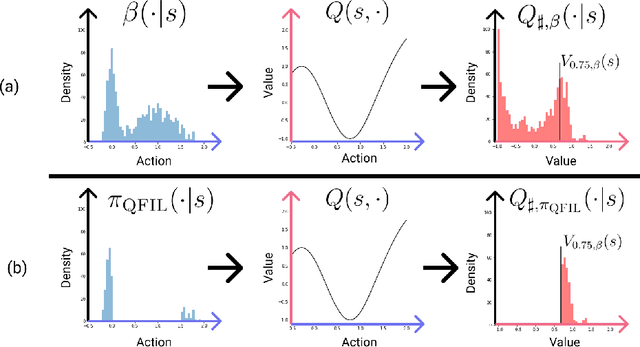
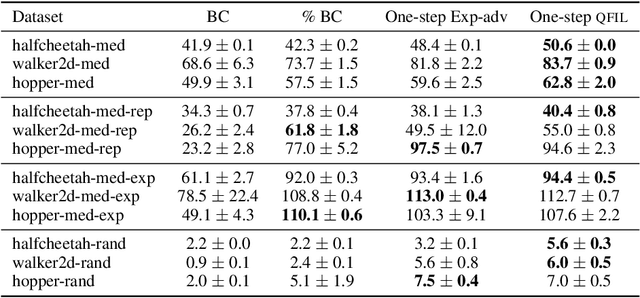
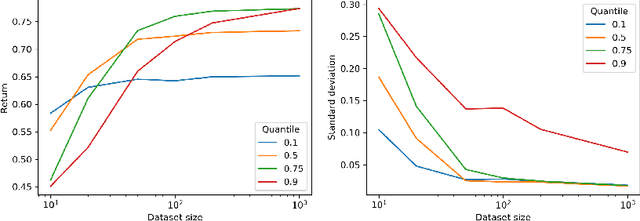
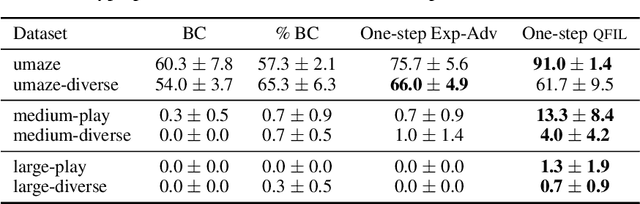
We introduce quantile filtered imitation learning (QFIL), a novel policy improvement operator designed for offline reinforcement learning. QFIL performs policy improvement by running imitation learning on a filtered version of the offline dataset. The filtering process removes $ s,a $ pairs whose estimated Q values fall below a given quantile of the pushforward distribution over values induced by sampling actions from the behavior policy. The definitions of both the pushforward Q distribution and resulting value function quantile are key contributions of our method. We prove that QFIL gives us a safe policy improvement step with function approximation and that the choice of quantile provides a natural hyperparameter to trade off bias and variance of the improvement step. Empirically, we perform a synthetic experiment illustrating how QFIL effectively makes a bias-variance tradeoff and we see that QFIL performs well on the D4RL benchmark.
Neural Fields as Learnable Kernels for 3D Reconstruction
Nov 26, 2021

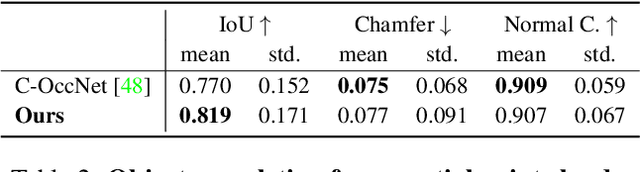
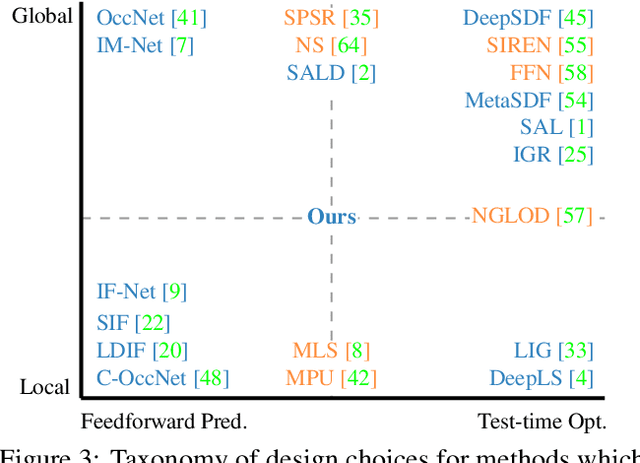
We present Neural Kernel Fields: a novel method for reconstructing implicit 3D shapes based on a learned kernel ridge regression. Our technique achieves state-of-the-art results when reconstructing 3D objects and large scenes from sparse oriented points, and can reconstruct shape categories outside the training set with almost no drop in accuracy. The core insight of our approach is that kernel methods are extremely effective for reconstructing shapes when the chosen kernel has an appropriate inductive bias. We thus factor the problem of shape reconstruction into two parts: (1) a backbone neural network which learns kernel parameters from data, and (2) a kernel ridge regression that fits the input points on-the-fly by solving a simple positive definite linear system using the learned kernel. As a result of this factorization, our reconstruction gains the benefits of data-driven methods under sparse point density while maintaining interpolatory behavior, which converges to the ground truth shape as input sampling density increases. Our experiments demonstrate a strong generalization capability to objects outside the train-set category and scanned scenes. Source code and pretrained models are available at https://nv-tlabs.github.io/nkf.
Multi-fidelity Stability for Graph Representation Learning
Nov 25, 2021In the problem of structured prediction with graph representation learning (GRL for short), the hypothesis returned by the algorithm maps the set of features in the \emph{receptive field} of the targeted vertex to its label. To understand the learnability of those algorithms, we introduce a weaker form of uniform stability termed \emph{multi-fidelity stability} and give learning guarantees for weakly dependent graphs. We testify that ~\citet{london2016stability}'s claim on the generalization of a single sample holds for GRL when the receptive field is sparse. In addition, we study the stability induced bound for two popular algorithms: \textbf{(1)} Stochastic gradient descent under convex and non-convex landscape. In this example, we provide non-asymptotic bounds that highly depend on the sparsity of the receptive field constructed by the algorithm. \textbf{(2)} The constrained regression problem on a 1-layer linear equivariant GNN. In this example, we present lower bounds for the discrepancy between the two types of stability, which justified the multi-fidelity design.
Cartoon Explanations of Image Classifiers
Nov 02, 2021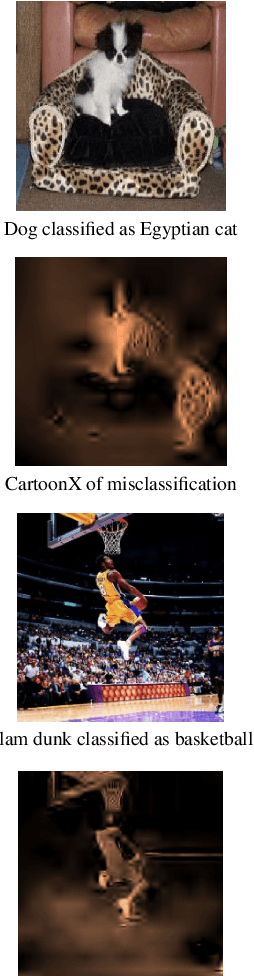
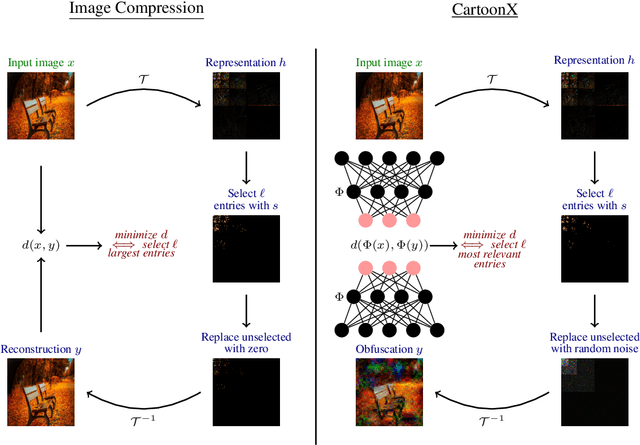
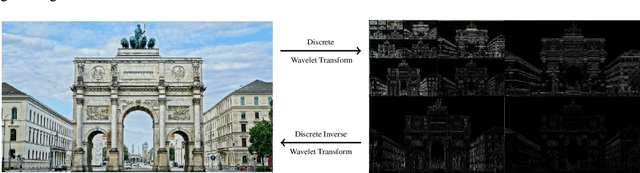
We present CartoonX (Cartoon Explanation), a novel model-agnostic explanation method tailored towards image classifiers and based on the rate-distortion explanation (RDE) framework. Natural images are roughly piece-wise smooth signals -- also called cartoon images -- and tend to be sparse in the wavelet domain. CartoonX is the first explanation method to exploit this by requiring its explanations to be sparse in the wavelet domain, thus extracting the \emph{relevant piece-wise smooth} part of an image instead of relevant pixel-sparse regions. We demonstrate experimentally that CartoonX is not only highly interpretable due to its piece-wise smooth nature but also particularly apt at explaining misclassifications.
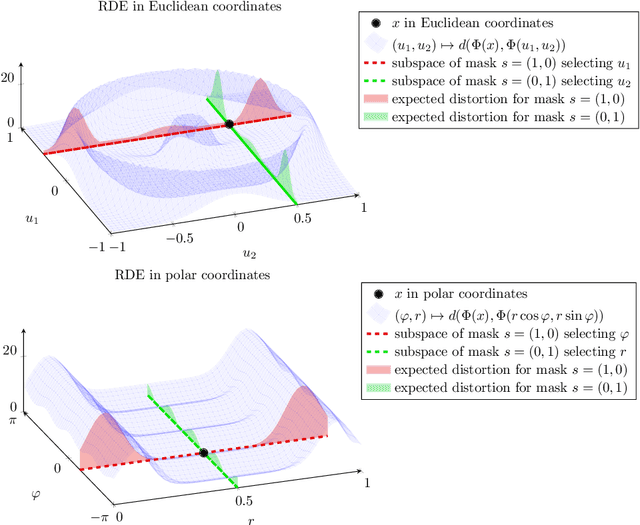
A Rate-Distortion Framework for Explaining Black-box Model Decisions
Oct 12, 2021


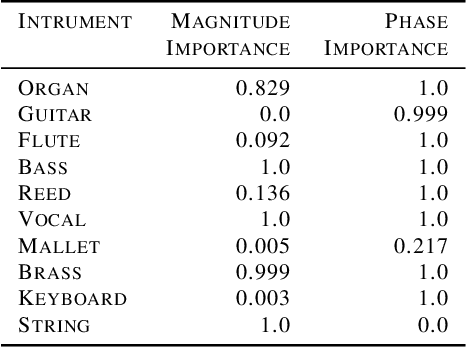
We present the Rate-Distortion Explanation (RDE) framework, a mathematically well-founded method for explaining black-box model decisions. The framework is based on perturbations of the target input signal and applies to any differentiable pre-trained model such as neural networks. Our experiments demonstrate the framework's adaptability to diverse data modalities, particularly images, audio, and physical simulations of urban environments.
An Extensible Benchmark Suite for Learning to Simulate Physical Systems
Aug 09, 2021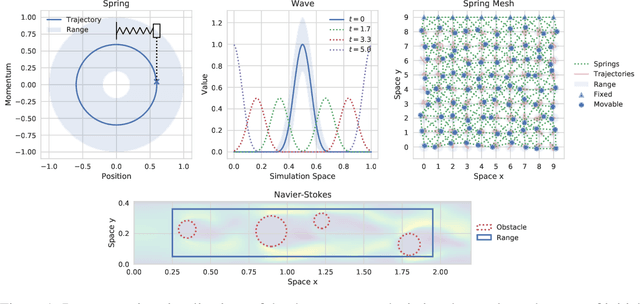

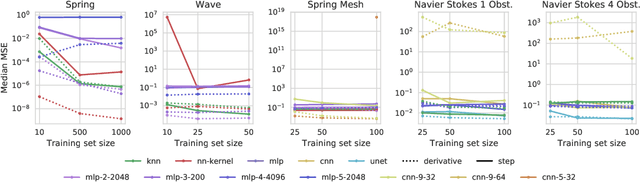
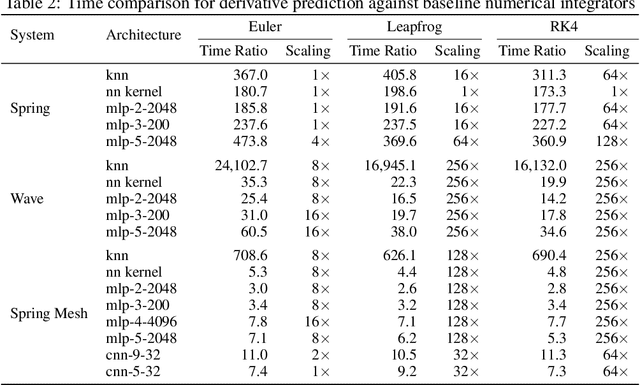
Simulating physical systems is a core component of scientific computing, encompassing a wide range of physical domains and applications. Recently, there has been a surge in data-driven methods to complement traditional numerical simulations methods, motivated by the opportunity to reduce computational costs and/or learn new physical models leveraging access to large collections of data. However, the diversity of problem settings and applications has led to a plethora of approaches, each one evaluated on a different setup and with different evaluation metrics. We introduce a set of benchmark problems to take a step towards unified benchmarks and evaluation protocols. We propose four representative physical systems, as well as a collection of both widely used classical time integrators and representative data-driven methods (kernel-based, MLP, CNN, nearest neighbors). Our framework allows evaluating objectively and systematically the stability, accuracy, and computational efficiency of data-driven methods. Additionally, it is configurable to permit adjustments for accommodating other learning tasks and for establishing a foundation for future developments in machine learning for scientific computing.
Dual Training of Energy-Based Models with Overparametrized Shallow Neural Networks
Jul 11, 2021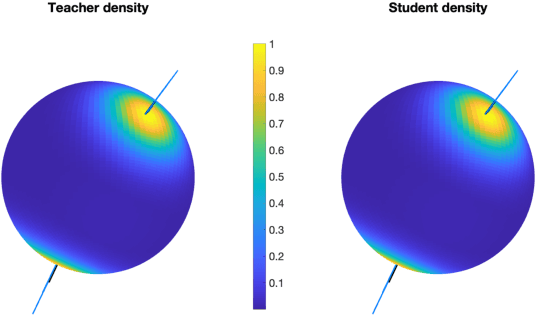
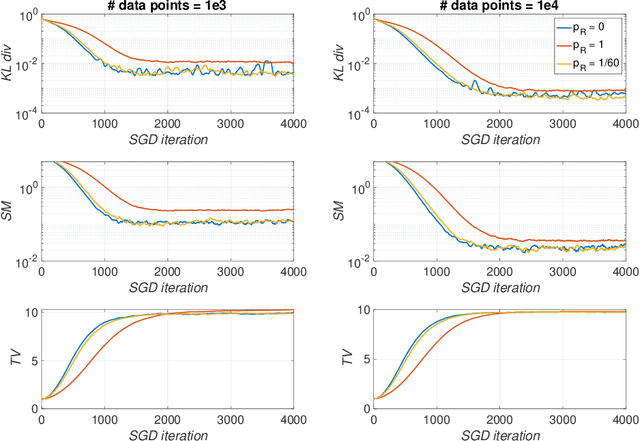
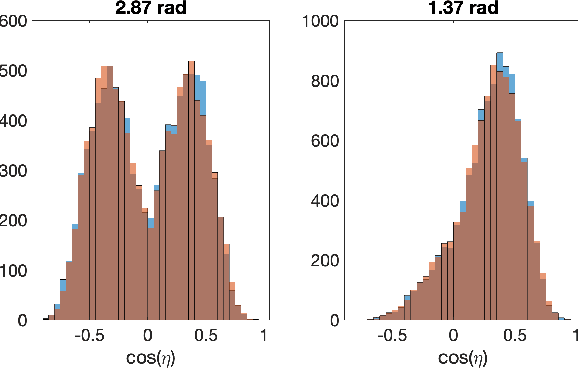
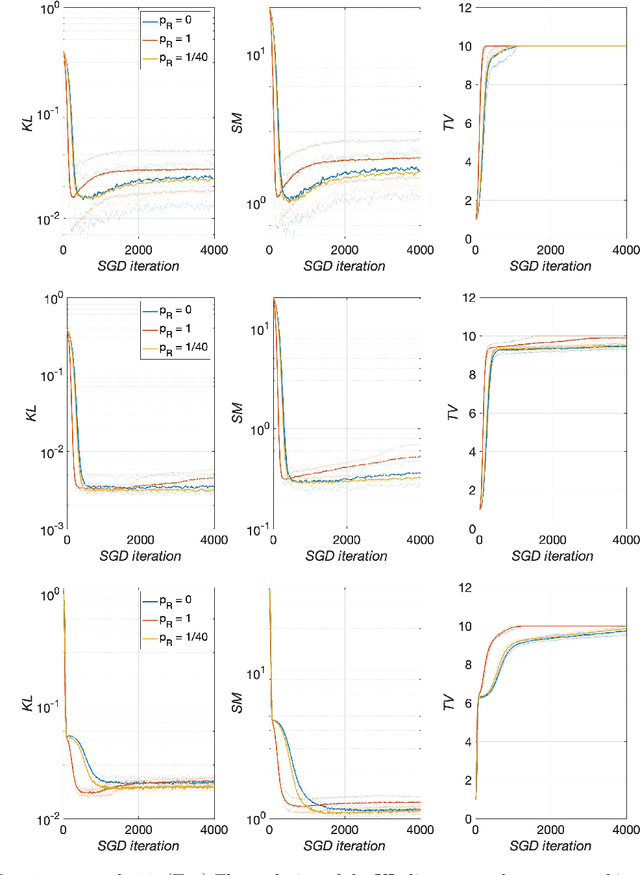
Energy-based models (EBMs) are generative models that are usually trained via maximum likelihood estimation. This approach becomes challenging in generic situations where the trained energy is nonconvex, due to the need to sample the Gibbs distribution associated with this energy. Using general Fenchel duality results, we derive variational principles dual to maximum likelihood EBMs with shallow overparametrized neural network energies, both in the active (aka feature-learning) and lazy regimes. In the active regime, this dual formulation leads to a training algorithm in which one updates concurrently the particles in the sample space and the neurons in the parameter space of the energy. We also consider a variant of this algorithm in which the particles are sometimes restarted at random samples drawn from the data set, and show that performing these restarts at every iteration step corresponds to score matching training. Using intermediate parameter setups in our dual algorithm thereby gives a way to interpolate between maximum likelihood and score matching training. These results are illustrated in simple numerical experiments.
On the Cryptographic Hardness of Learning Single Periodic Neurons
Jun 20, 2021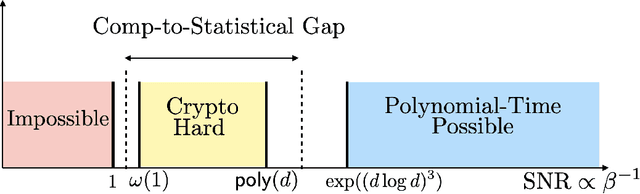
We show a simple reduction which demonstrates the cryptographic hardness of learning a single periodic neuron over isotropic Gaussian distributions in the presence of noise. More precisely, our reduction shows that any polynomial-time algorithm (not necessarily gradient-based) for learning such functions under small noise implies a polynomial-time quantum algorithm for solving worst-case lattice problems, whose hardness form the foundation of lattice-based cryptography. Our core hard family of functions, which are well-approximated by one-layer neural networks, take the general form of a univariate periodic function applied to an affine projection of the data. These functions have appeared in previous seminal works which demonstrate their hardness against gradient-based (Shamir'18), and Statistical Query (SQ) algorithms (Song et al.'17). We show that if (polynomially) small noise is added to the labels, the intractability of learning these functions applies to all polynomial-time algorithms under the aforementioned cryptographic assumptions. Moreover, we demonstrate the necessity of noise in the hardness result by designing a polynomial-time algorithm for learning certain families of such functions under exponentially small adversarial noise. Our proposed algorithm is not a gradient-based or an SQ algorithm, but is rather based on the celebrated Lenstra-Lenstra-Lov\'asz (LLL) lattice basis reduction algorithm. Furthermore, in the absence of noise, this algorithm can be directly applied to solve CLWE detection (Bruna et al.'21) and phase retrieval with an optimal sample complexity of $d+1$ samples. In the former case, this improves upon the quadratic-in-$d$ sample complexity required in (Bruna et al.'21). In the latter case, this improves upon the state-of-the-art AMP-based algorithm, which requires approximately $1.128d$ samples (Barbier et al.'19).
Offline RL Without Off-Policy Evaluation
Jun 16, 2021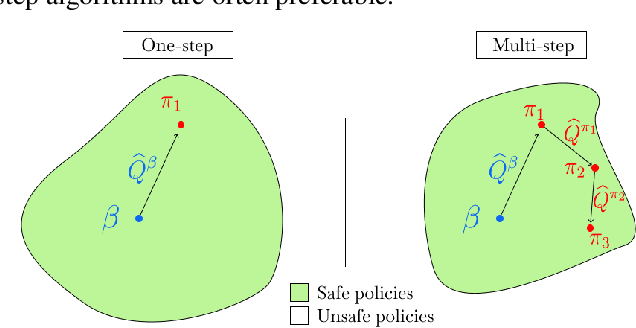
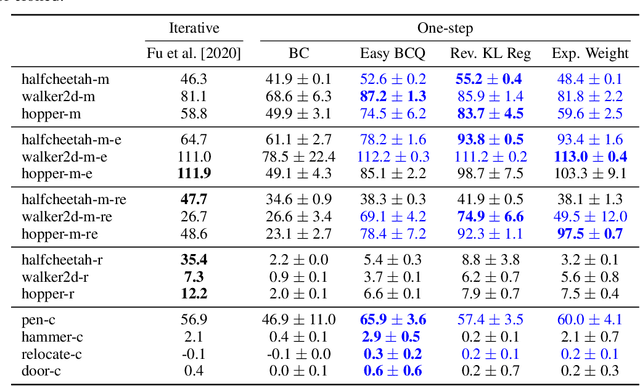

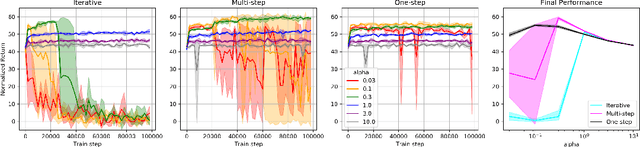
Most prior approaches to offline reinforcement learning (RL) have taken an iterative actor-critic approach involving off-policy evaluation. In this paper we show that simply doing one step of constrained/regularized policy improvement using an on-policy Q estimate of the behavior policy performs surprisingly well. This one-step algorithm beats the previously reported results of iterative algorithms on a large portion of the D4RL benchmark. The simple one-step baseline achieves this strong performance without many of the tricks used by previously proposed iterative algorithms and is more robust to hyperparameters. We argue that the relatively poor performance of iterative approaches is a result of the high variance inherent in doing off-policy evaluation and magnified by the repeated optimization of policies against those high-variance estimates. In addition, we hypothesize that the strong performance of the one-step algorithm is due to a combination of favorable structure in the environment and behavior policy.