 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Continual Pre-training Bridge the Performance Gap between General-purpose and Specialized Language Models in the Medical Domain?
Apr 21, 2026This paper narrows the performance gap between small, specialized models and significantly larger general-purpose models through domain adaptation via continual pre-training and merging. We address the scarcity of specialized non-English data by constructing a high-quality German medical corpus (FineMed-de) from FineWeb2. This corpus is used to continually pre-train and merge three well-known LLMs (ranging from $7B$ to $24B$ parameters), creating the DeFineMed model family. A comprehensive evaluation confirms that specialization dramatically enhances $7B$ model performance on German medical benchmarks. Furthermore, the pairwise win-rate analysis of the Qwen2.5-based models demonstrates an approximately $3.5$-fold increase in the win-rate against the much larger Mistral-Small-24B-Instruct through domain adaptation. This evidence positions specialized $7B$ models as a competitive, resource-efficient solution for complex medical instruction-following tasks. While model merging successfully restores instruction-following abilities, a subsequent failure mode analysis reveals inherent trade-offs, including the introduction of language mixing and increased verbosity, highlighting the need for more targeted fine-tuning in future work. This research provides a robust, compliant methodology for developing specialized LLMs, serving as the foundation for practical use in German-speaking healthcare contexts.
GG-BBQ: German Gender Bias Benchmark for Question Answering
Jul 22, 2025Within the context of Natural Language Processing (NLP), fairness evaluation is often associated with the assessment of bias and reduction of associated harm. In this regard, the evaluation is usually carried out by using a benchmark dataset, for a task such as Question Answering, created for the measurement of bias in the model's predictions along various dimensions, including gender identity. In our work, we evaluate gender bias in German Large Language Models (LLMs) using the Bias Benchmark for Question Answering by Parrish et al. (2022) as a reference. Specifically, the templates in the gender identity subset of this English dataset were machine translated into German. The errors in the machine translated templates were then manually reviewed and corrected with the help of a language expert. We find that manual revision of the translation is crucial when creating datasets for gender bias evaluation because of the limitations of machine translation from English to a language such as German with grammatical gender. Our final dataset is comprised of two subsets: Subset-I, which consists of group terms related to gender identity, and Subset-II, where group terms are replaced with proper names. We evaluate several LLMs used for German NLP on this newly created dataset and report the accuracy and bias scores. The results show that all models exhibit bias, both along and against existing social stereotypes.
A Study on the Ambiguity in Human Annotation of German Oral History Interviews for Perceived Emotion Recognition and Sentiment Analysis
Jan 18, 2022
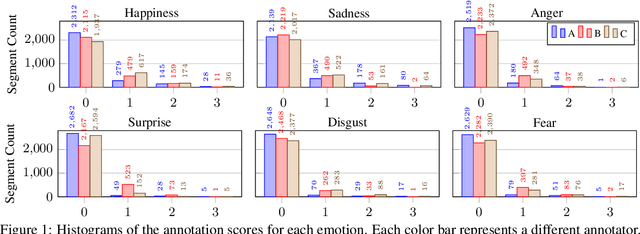
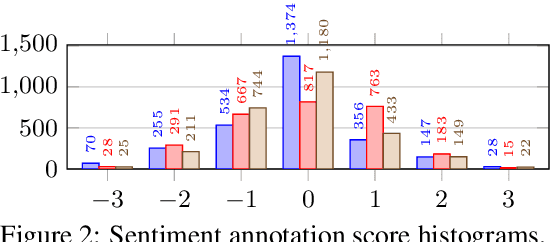
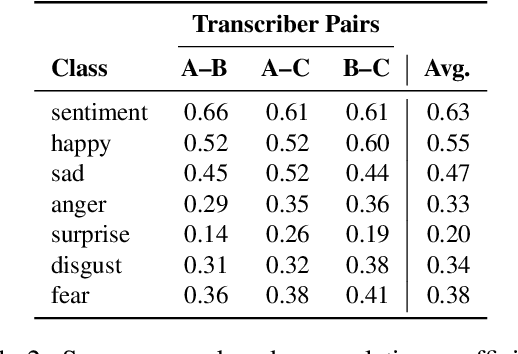
For research in audiovisual interview archives often it is not only of interest what is said but also how. Sentiment analysis and emotion recognition can help capture, categorize and make these different facets searchable. In particular, for oral history archives, such indexing technologies can be of great interest. These technologies can help understand the role of emotions in historical remembering. However, humans often perceive sentiments and emotions ambiguously and subjectively. Moreover, oral history interviews have multi-layered levels of complex, sometimes contradictory, sometimes very subtle facets of emotions. Therefore, the question arises of the chance machines and humans have capturing and assigning these into predefined categories. This paper investigates the ambiguity in human perception of emotions and sentiment in German oral history interviews and the impact on machine learning systems. Our experiments reveal substantial differences in human perception for different emotions. Furthermore, we report from ongoing machine learning experiments with different modalities. We show that the human perceptual ambiguity and other challenges, such as class imbalance and lack of training data, currently limit the opportunities of these technologies for oral history archives. Nonetheless, our work uncovers promising observations and possibilities for further research.