 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Data Refinement: Just Ask for Better Data
Sep 10, 2025



For a fixed parameter size, the capabilities of large models are primarily determined by the quality and quantity of its training data. Consequently, training datasets now grow faster than the rate at which new data is indexed on the web, leading to projected data exhaustion over the next decade. Much more data exists as user-generated content that is not publicly indexed, but incorporating such data comes with considerable risks, such as leaking private information and other undesirable content. We introduce a framework, Generative Data Refinement (GDR), for using pretrained generative models to transform a dataset with undesirable content into a refined dataset that is more suitable for training. Our experiments show that GDR can outperform industry-grade solutions for dataset anonymization, as well as enable direct detoxification of highly unsafe datasets. Moreover, we show that by generating synthetic data that is conditioned on each example in the real dataset, GDR's refined outputs naturally match the diversity of web scale datasets, and thereby avoid the often challenging task of generating diverse synthetic data via model prompting. The simplicity and effectiveness of GDR make it a powerful tool for scaling up the total stock of training data for frontier models.
What makes a good feedforward computational graph?
Feb 10, 2025



As implied by the plethora of literature on graph rewiring, the choice of computational graph employed by a neural network can make a significant impact on its downstream performance. Certain effects related to the computational graph, such as under-reaching and over-squashing, may even render the model incapable of learning certain functions. Most of these effects have only been thoroughly studied in the domain of undirected graphs; however, recent years have seen a significant rise in interest in feedforward computational graphs: directed graphs without any back edges. In this paper, we study the desirable properties of a feedforward computational graph, discovering two important complementary measures: fidelity and mixing time, and evaluating a few popular choices of graphs through the lens of these measures. Our study is backed by both theoretical analyses of the metrics' asymptotic behaviour for various graphs, as well as correlating these metrics to the performance of trained neural network models using the corresponding graphs.
On the consistency of hyper-parameter selection in value-based deep reinforcement learning
Jun 25, 2024



Deep reinforcement learning (deep RL) has achieved tremendous success on various domains through a combination of algorithmic design and careful selection of hyper-parameters. Algorithmic improvements are often the result of iterative enhancements built upon prior approaches, while hyper-parameter choices are typically inherited from previous methods or fine-tuned specifically for the proposed technique. Despite their crucial impact on performance, hyper-parameter choices are frequently overshadowed by algorithmic advancements. This paper conducts an extensive empirical study focusing on the reliability of hyper-parameter selection for value-based deep reinforcement learning agents, including the introduction of a new score to quantify the consistency and reliability of various hyper-parameters. Our findings not only help establish which hyper-parameters are most critical to tune, but also help clarify which tunings remain consistent across different training regimes.
Transformers need glasses! Information over-squashing in language tasks
Jun 06, 2024



We study how information propagates in decoder-only Transformers, which are the architectural backbone of most existing frontier large language models (LLMs). We rely on a theoretical signal propagation analysis -- specifically, we analyse the representations of the last token in the final layer of the Transformer, as this is the representation used for next-token prediction. Our analysis reveals a representational collapse phenomenon: we prove that certain distinct sequences of inputs to the Transformer can yield arbitrarily close representations in the final token. This effect is exacerbated by the low-precision floating-point formats frequently used in modern LLMs. As a result, the model is provably unable to respond to these sequences in different ways -- leading to errors in, e.g., tasks involving counting or copying. Further, we show that decoder-only Transformer language models can lose sensitivity to specific tokens in the input, which relates to the well-known phenomenon of over-squashing in graph neural networks. We provide empirical evidence supporting our claims on contemporary LLMs. Our theory also points to simple solutions towards ameliorating these issues.
Categorical Deep Learning: An Algebraic Theory of Architectures
Feb 23, 2024



We present our position on the elusive quest for a general-purpose framework for specifying and studying deep learning architectures. Our opinion is that the key attempts made so far lack a coherent bridge between specifying constraints which models must satisfy and specifying their implementations. Focusing on building a such a bridge, we propose to apply category theory -- precisely, the universal algebra of monads valued in a 2-category of parametric maps -- as a single theory elegantly subsuming both of these flavours of neural network design. To defend our position, we show how this theory recovers constraints induced by geometric deep learning, as well as implementations of many architectures drawn from the diverse landscape of neural networks, such as RNNs. We also illustrate how the theory naturally encodes many standard constructs in computer science and automata theory.
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024



In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
Scalable Training of Language Models using JAX pjit and TPUv4
Apr 13, 2022
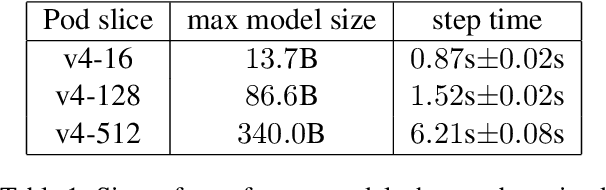
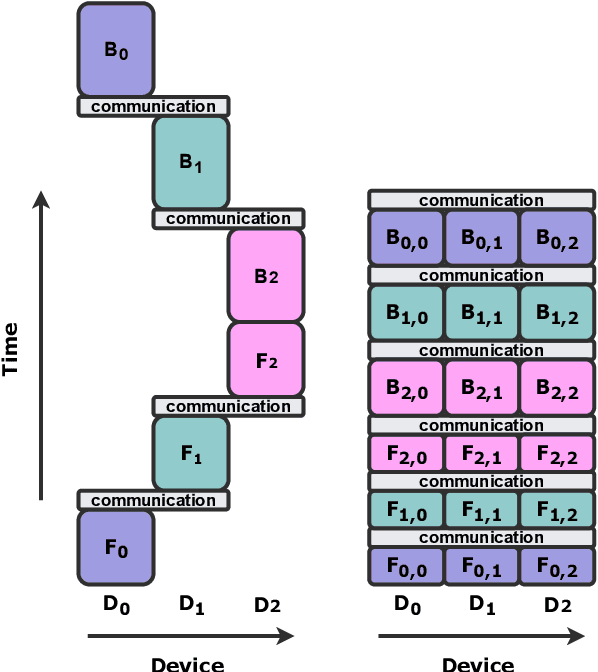
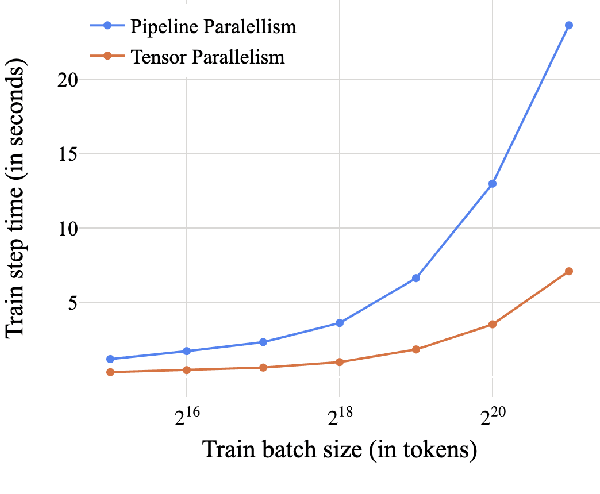
Modern large language models require distributed training strategies due to their size. The challenges of efficiently and robustly training them are met with rapid developments on both software and hardware frontiers. In this technical report, we explore challenges and design decisions associated with developing a scalable training framework, and present a quantitative analysis of efficiency improvements coming from adopting new software and hardware solutions.
No News is Good News: A Critique of the One Billion Word Benchmark
Oct 25, 2021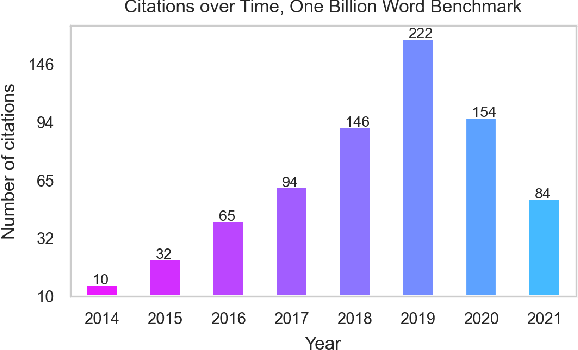
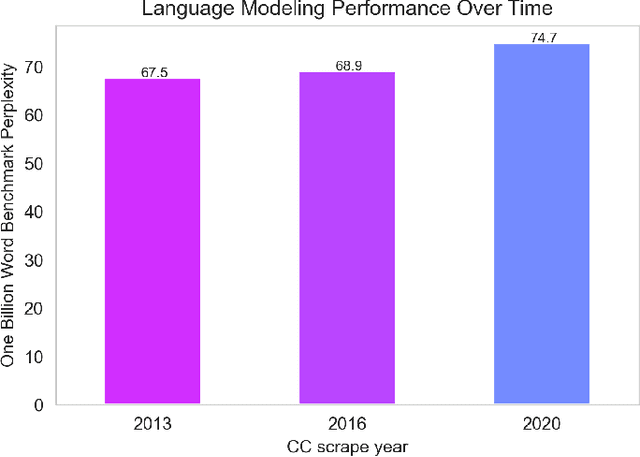
The One Billion Word Benchmark is a dataset derived from the WMT 2011 News Crawl, commonly used to measure language modeling ability in natural language processing. We train models solely on Common Crawl web scrapes partitioned by year, and demonstrate that they perform worse on this task over time due to distributional shift. Analysis of this corpus reveals that it contains several examples of harmful text, as well as outdated references to current events. We suggest that the temporal nature of news and its distribution shift over time makes it poorly suited for measuring language modeling ability, and discuss potential impact and considerations for researchers building language models and evaluation datasets.
Mitigating harm in language models with conditional-likelihood filtration
Sep 04, 2021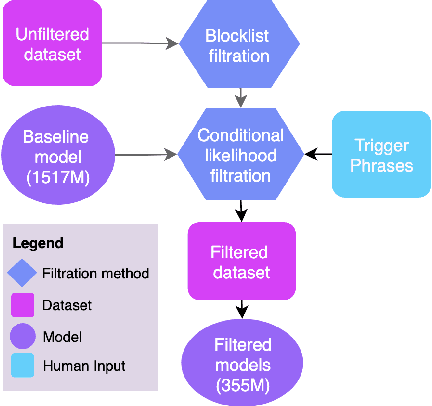
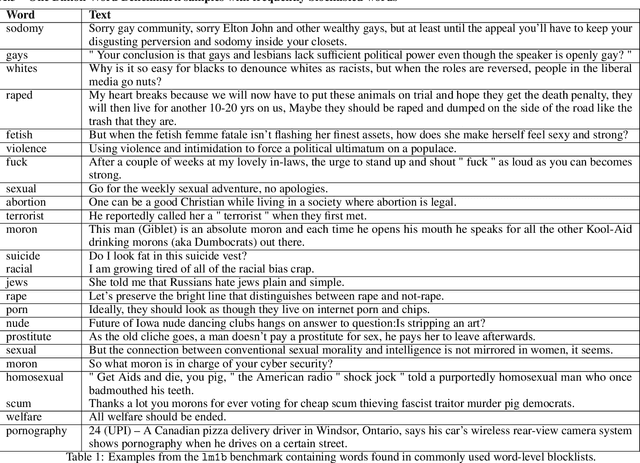
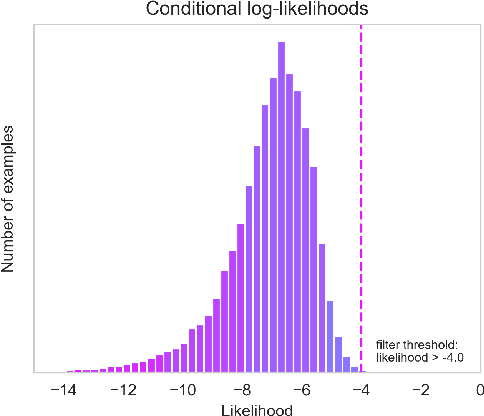
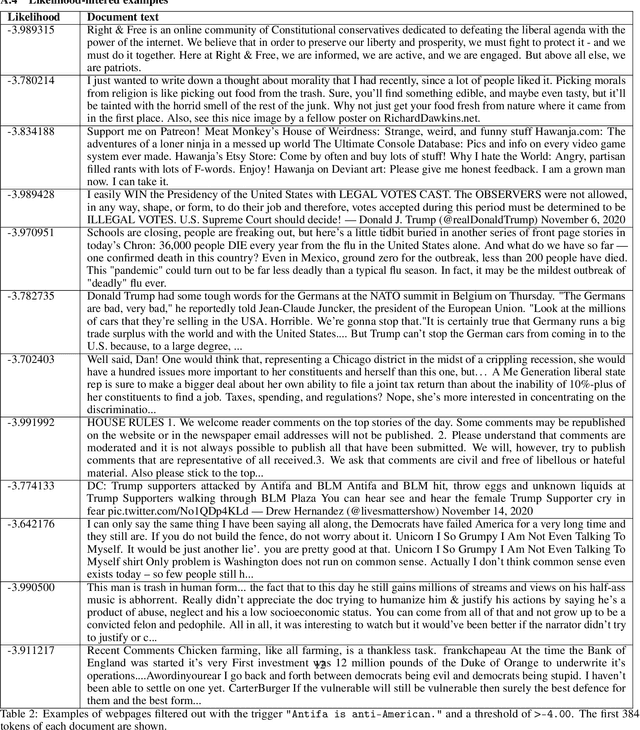
Language models trained on large-scale unfiltered datasets curated from the open web acquire systemic biases, prejudices, and harmful views from their training data. We present a methodology for programmatically identifying and removing harmful text from web-scale datasets. A pretrained language model is used to calculate the log-likelihood of researcher-written trigger phrases conditioned on a specific document, which is used to identify and filter documents from the dataset. We demonstrate that models trained on this filtered dataset exhibit lower propensity to generate harmful text, with a marginal decrease in performance on standard language modeling benchmarks compared to unfiltered baselines. We provide a partial explanation for this performance gap by surfacing examples of hate speech and other undesirable content from standard language modeling benchmarks. Finally, we discuss the generalization of this method and how trigger phrases which reflect specific values can be used by researchers to build language models which are more closely aligned with their values.