 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplex Spectral Mapping With Attention Based Convolution Recurrent Neural Network for Speech Enhancement
Apr 15, 2021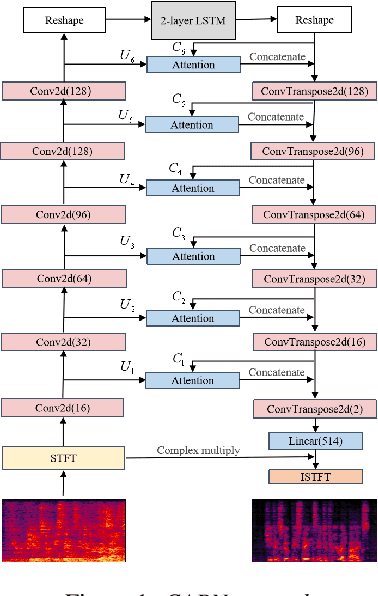
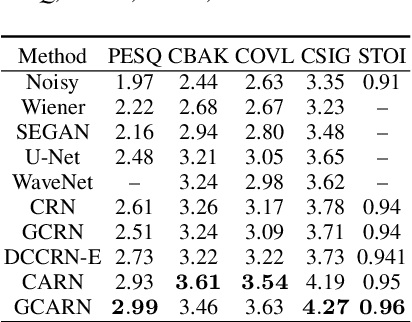
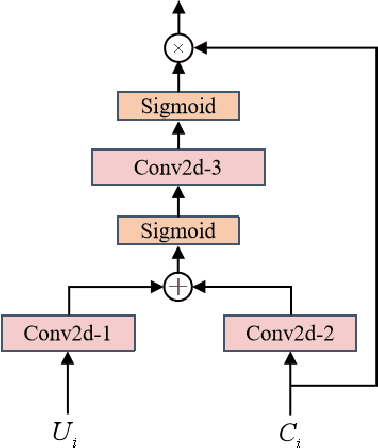
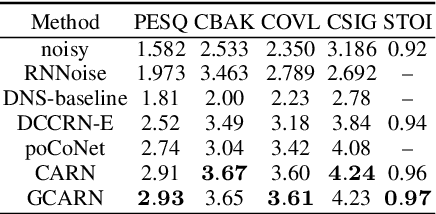
Speech enhancement has benefited from the success of deep learning in terms of intelligibility and perceptual quality. Conventional time-frequency (TF) domain methods focus on predicting TF-masks or speech spectrum,via a naive convolution neural network or recurrent neural network.Some recent studies were based on Complex spectral Mapping convolution recurrent neural network (CRN) . These models skiped directly from encoder layers' output and decoder layers' input ,which maybe thoughtless. We proposed an attention mechanism based skip connection between encoder and decoder layers,namely Complex Spectral Mapping With Attention Based Convolution Recurrent Neural Network (CARN).Compared with CRN model,the proposed CARN model improved more than 10% relatively at several metrics such as PESQ,CBAK,COVL,CSIG and son,and outperformed the place 1st model in both real time and non-real time track of the DNS Challenge 2020 at these metrics.
OpenViDial: A Large-Scale, Open-Domain Dialogue Dataset with Visual Contexts
Dec 30, 2020


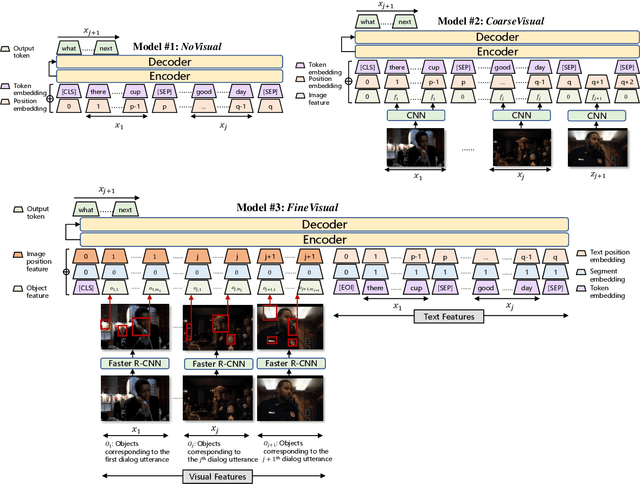
When humans converse, what a speaker will say next significantly depends on what he sees. Unfortunately, existing dialogue models generate dialogue utterances only based on preceding textual contexts, and visual contexts are rarely considered. This is due to a lack of a large-scale multi-module dialogue dataset with utterances paired with visual contexts. In this paper, we release {\bf OpenViDial}, a large-scale multi-module dialogue dataset. The dialogue turns and visual contexts are extracted from movies and TV series, where each dialogue turn is paired with the corresponding visual context in which it takes place. OpenViDial contains a total number of 1.1 million dialogue turns, and thus 1.1 million visual contexts stored in images. Based on this dataset, we propose a family of encoder-decoder models leveraging both textual and visual contexts, from coarse-grained image features extracted from CNNs to fine-grained object features extracted from Faster R-CNNs. We observe that visual information significantly improves dialogue generation qualities, verifying the necessity of integrating multi-modal features for dialogue learning. Our work marks an important step towards large-scale multi-modal dialogue learning.
Self-Explaining Structures Improve NLP Models
Dec 09, 2020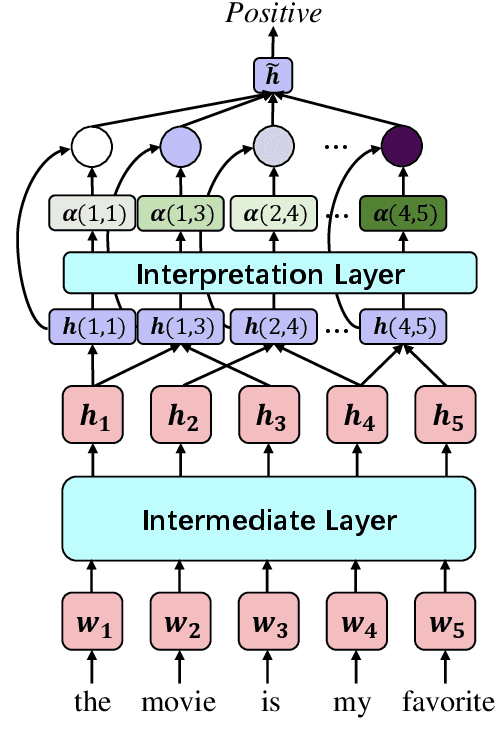
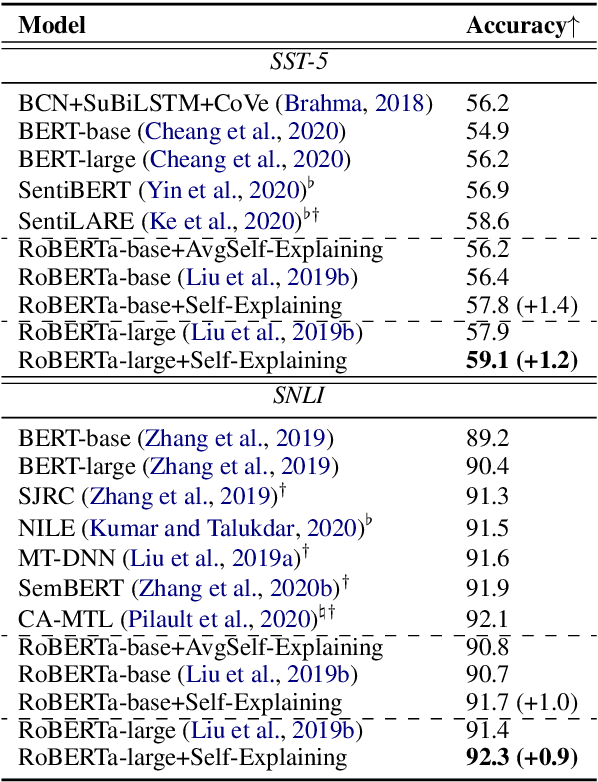

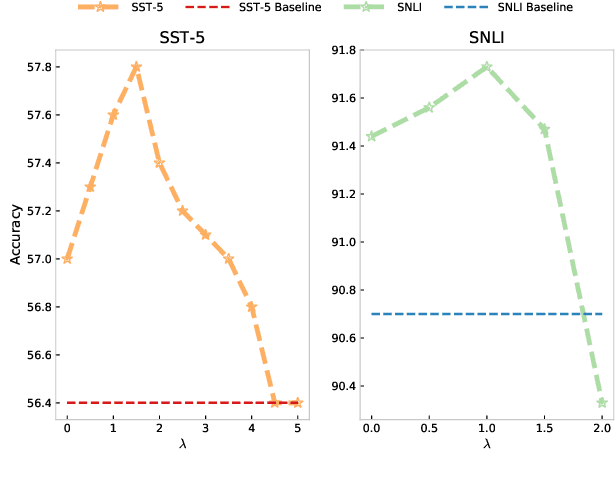
Existing approaches to explaining deep learning models in NLP usually suffer from two major drawbacks: (1) the main model and the explaining model are decoupled: an additional probing or surrogate model is used to interpret an existing model, and thus existing explaining tools are not self-explainable; (2) the probing model is only able to explain a model's predictions by operating on low-level features by computing saliency scores for individual words but are clumsy at high-level text units such as phrases, sentences, or paragraphs. To deal with these two issues, in this paper, we propose a simple yet general and effective self-explaining framework for deep learning models in NLP. The key point of the proposed framework is to put an additional layer, as is called by the interpretation layer, on top of any existing NLP model. This layer aggregates the information for each text span, which is then associated with a specific weight, and their weighted combination is fed to the softmax function for the final prediction. The proposed model comes with the following merits: (1) span weights make the model self-explainable and do not require an additional probing model for interpretation; (2) the proposed model is general and can be adapted to any existing deep learning structures in NLP; (3) the weight associated with each text span provides direct importance scores for higher-level text units such as phrases and sentences. We for the first time show that interpretability does not come at the cost of performance: a neural model of self-explaining features obtains better performances than its counterpart without the self-explaining nature, achieving a new SOTA performance of 59.1 on SST-5 and a new SOTA performance of 92.3 on SNLI.
Neural Semi-supervised Learning for Text Classification Under Large-Scale Pretraining
Nov 19, 2020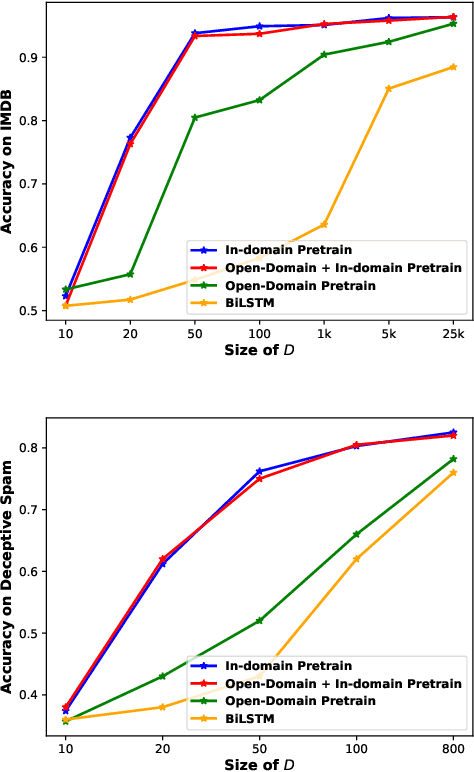
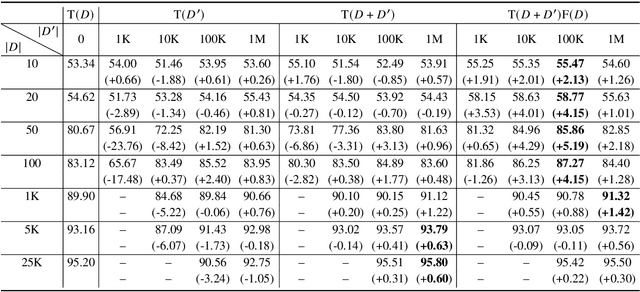
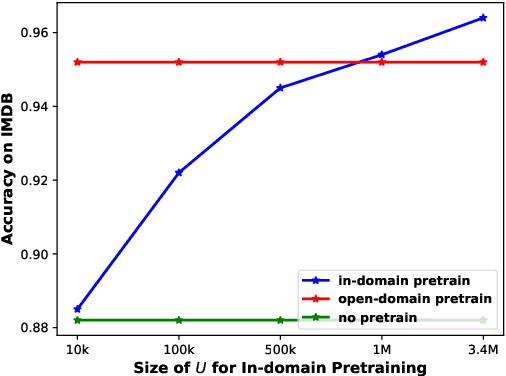

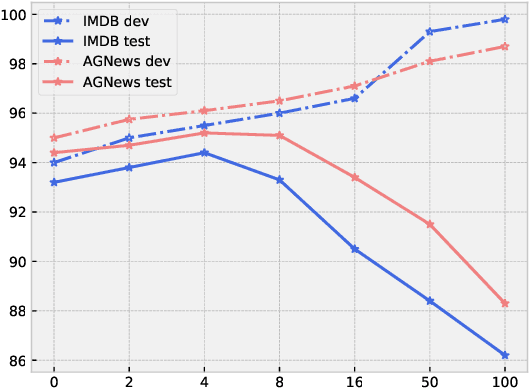
The goal of semi-supervised learning is to utilize the unlabeled, in-domain dataset U to improve models trained on the labeled dataset D. Under the context of large-scale language-model (LM) pretraining, how we can make the best use of U is poorly understood: is semi-supervised learning still beneficial with the presence of large-scale pretraining? should U be used for in-domain LM pretraining or pseudo-label generation? how should the pseudo-label based semi-supervised model be actually implemented? how different semi-supervised strategies affect performances regarding D of different sizes, U of different sizes, etc. In this paper, we conduct comprehensive studies on semi-supervised learning in the task of text classification under the context of large-scale LM pretraining. Our studies shed important lights on the behavior of semi-supervised learning methods: (1) with the presence of in-domain pretraining LM on U, open-domain LM pretraining is unnecessary; (2) both the in-domain pretraining strategy and the pseudo-label based strategy introduce significant performance boosts, with the former performing better with larger U, the latter performing better with smaller U, and the combination leading to the largest performance boost; (3) self-training (pretraining first on pseudo labels D' and then fine-tuning on D) yields better performances when D is small, while joint training on the combination of pseudo labels D' and the original dataset D yields better performances when D is large. Using semi-supervised learning strategies, we are able to achieve a performance of around 93.8% accuracy with only 50 training data points on the IMDB dataset, and a competitive performance of 96.6% with the full IMDB dataset. Our work marks an initial step in understanding the behavior of semi-supervised learning models under the context of large-scale pretraining.
Pair the Dots: Jointly Examining Training History and Test Stimuli for Model Interpretability
Oct 31, 2020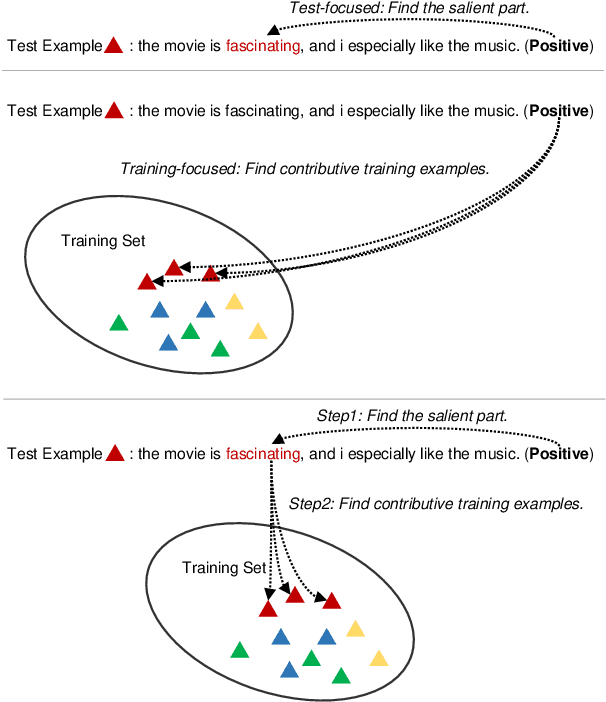
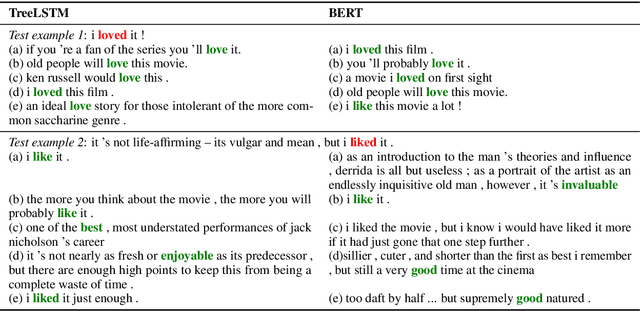

Any prediction from a model is made by a combination of learning history and test stimuli. This provides significant insights for improving model interpretability: {\it because of which part(s) of which training example(s), the model attends to which part(s) of a test example}. Unfortunately, existing methods to interpret a model's predictions are only able to capture a single aspect of either test stimuli or learning history, and evidences from both are never combined or integrated. In this paper, we propose an efficient and differentiable approach to make it feasible to interpret a model's prediction by jointly examining training history and test stimuli. Test stimuli is first identified by gradient-based methods, signifying {\it the part of a test example that the model attends to}. The gradient-based saliency scores are then propagated to training examples using influence functions to identify {\it which part(s) of which training example(s)} make the model attends to the test stimuli. The system is differentiable and time efficient: the adoption of saliency scores from gradient-based methods allows us to efficiently trace a model's prediction through test stimuli, and then back to training examples through influence functions. We demonstrate that the proposed methodology offers clear explanations about neural model decisions, along with being useful for performing error analysis, crafting adversarial examples and fixing erroneously classified examples.
Summarize, Outline, and Elaborate: Long-Text Generation via Hierarchical Supervision from Extractive Summaries
Oct 14, 2020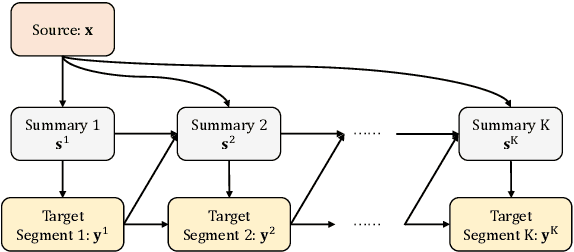
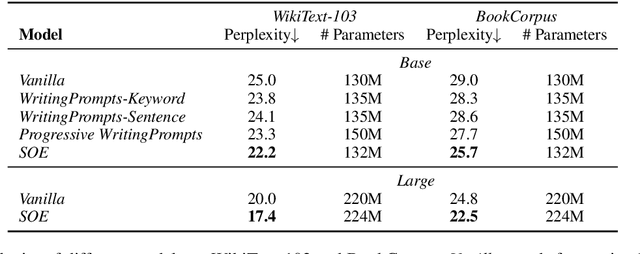
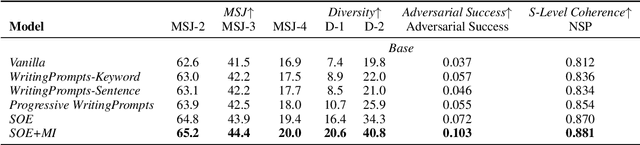
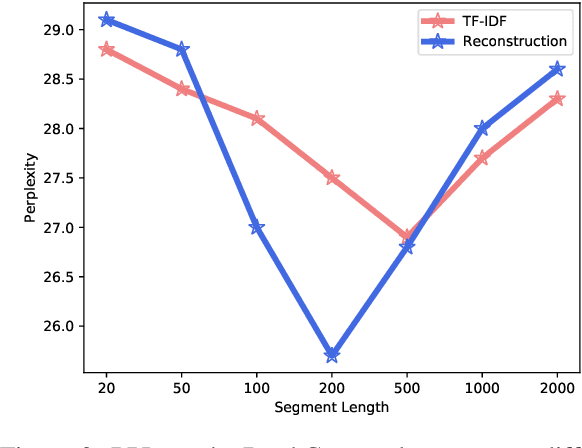
Long-text generation remains a challenge. The difficulty of generating coherent long texts lies in the fact that existing models overwhelmingly focus on the tasks of local word prediction, and cannot make high level plans on what to generate or capture the high-level discourse dependencies between chunks of texts. Inspired by how humans write, where a list of bullet points or a catalog is first outlined, and then each bullet point is expanded to form the whole article, we propose {\it SOE}, a pipelined system that involves of summarizing, outlining and elaborating for long text generation: the model first outlines the summaries for different segments of long texts, and then elaborates on each bullet point to generate the corresponding segment. To avoid the labor-intensive process of summary soliciting, we propose the {\it reconstruction} strategy, which extracts segment summaries in an unsupervised manner by selecting its most informative part to reconstruct the segment.The proposed generation system comes with the following merits: (1) the summary provides high-level guidances for text generation and avoids the local minimum of individual word predictions; (2) the high-level discourse dependencies are captured in the conditional dependencies between summaries and are preserved during the summary expansion process and (3) additionally, we are able to consider significantly more contexts by representing contexts as concise summaries. Extensive experiments demonstrate that SOE produces long texts with significantly better quality, along with faster convergence speed.
Improving Robustness and Generality of NLP Models Using Disentangled Representations
Sep 21, 2020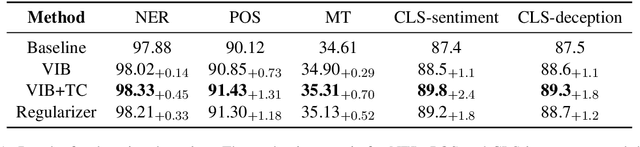
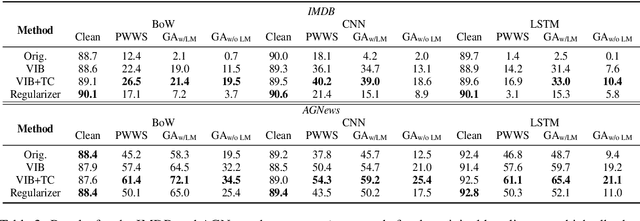
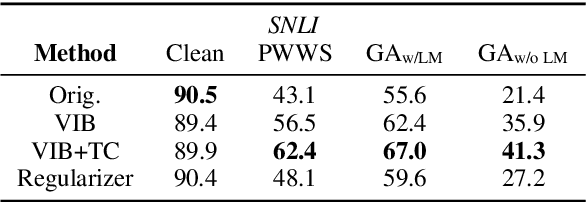
Supervised neural networks, which first map an input $x$ to a single representation $z$, and then map $z$ to the output label $y$, have achieved remarkable success in a wide range of natural language processing (NLP) tasks. Despite their success, neural models lack for both robustness and generality: small perturbations to inputs can result in absolutely different outputs; the performance of a model trained on one domain drops drastically when tested on another domain. In this paper, we present methods to improve robustness and generality of NLP models from the standpoint of disentangled representation learning. Instead of mapping $x$ to a single representation $z$, the proposed strategy maps $x$ to a set of representations $\{z_1,z_2,...,z_K\}$ while forcing them to be disentangled. These representations are then mapped to different logits $l$s, the ensemble of which is used to make the final prediction $y$. We propose different methods to incorporate this idea into currently widely-used models, including adding an $L$2 regularizer on $z$s or adding Total Correlation (TC) under the framework of variational information bottleneck (VIB). We show that models trained with the proposed criteria provide better robustness and domain adaptation ability in a wide range of supervised learning tasks.
Receptive Multi-granularity Representation for Person Re-Identification
Aug 31, 2020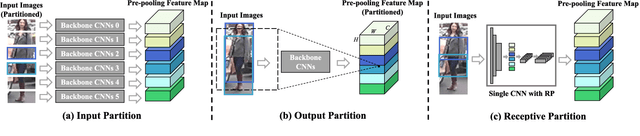
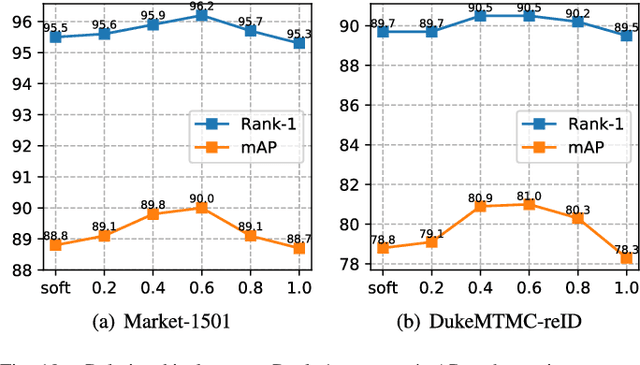
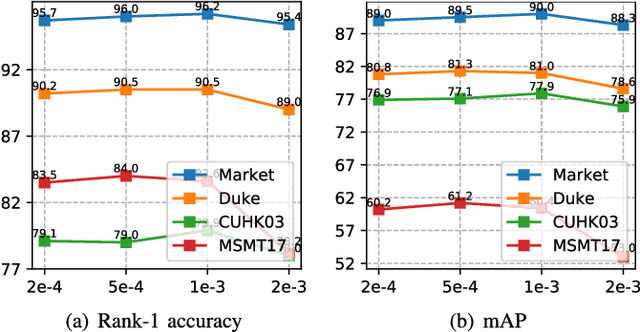
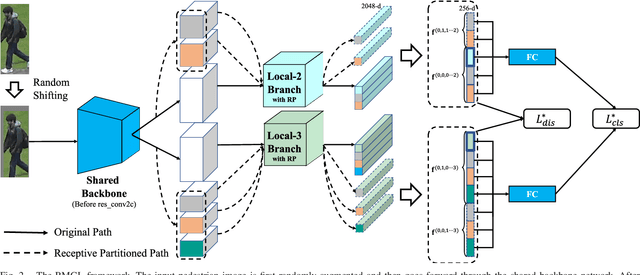
A key for person re-identification is achieving consistent local details for discriminative representation across variable environments. Current stripe-based feature learning approaches have delivered impressive accuracy, but do not make a proper trade-off between diversity, locality, and robustness, which easily suffers from part semantic inconsistency for the conflict between rigid partition and misalignment. This paper proposes a receptive multi-granularity learning approach to facilitate stripe-based feature learning. This approach performs local partition on the intermediate representations to operate receptive region ranges, rather than current approaches on input images or output features, thus can enhance the representation of locality while remaining proper local association. Toward this end, the local partitions are adaptively pooled by using significance-balanced activations for uniform stripes. Random shifting augmentation is further introduced for a higher variance of person appearing regions within bounding boxes to ease misalignment. By two-branch network architecture, different scales of discriminative identity representation can be learned. In this way, our model can provide a more comprehensive and efficient feature representation without larger model storage costs. Extensive experiments on intra-dataset and cross-dataset evaluations demonstrate the effectiveness of the proposed approach. Especially, our approach achieves a state-of-the-art accuracy of 96.2%@Rank-1 or 90.0%@mAP on the challenging Market-1501 benchmark.
* 14 pages, 9 figures. Championship solution of NAIC 2019 Person re-ID Track
Analyzing COVID-19 on Online Social Media: Trends, Sentiments and Emotions
Jun 05, 2020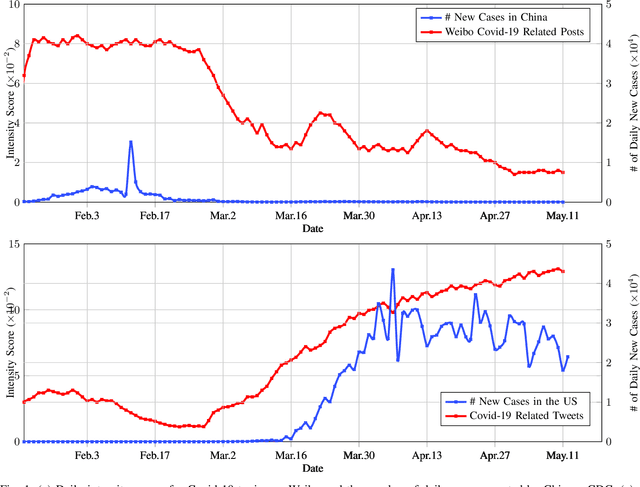
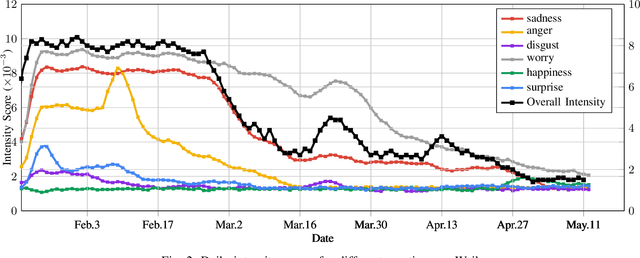
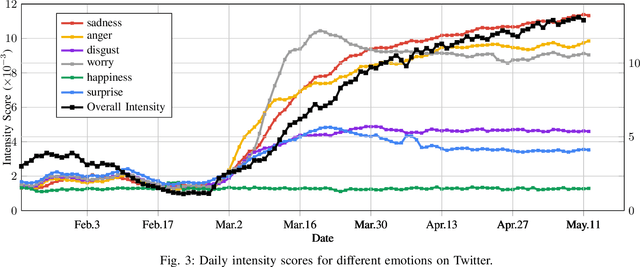
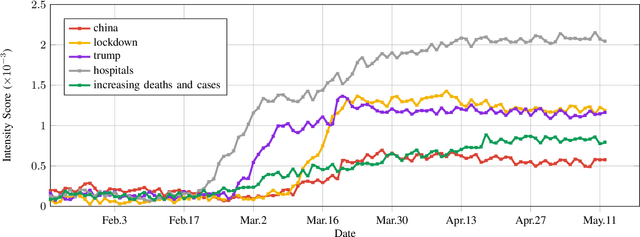
At the time of writing, the ongoing pandemic of coronavirus disease (COVID-19) has caused severe impacts on society, economy and people's daily lives. People constantly express their opinions on various aspects of the pandemic on social media, making user-generated content an important source for understanding public emotions and concerns. In this paper, we perform a comprehensive analysis on the affective trajectories of the American people and the Chinese people based on Twitter and Weibo posts between January 20th, 2020 and May 11th 2020. Specifically, by identifying people's sentiments, emotions (i.e., anger, disgust, fear, happiness, sadness, surprise) and the emotional triggers (e.g., what a user is angry/sad about) we are able to depict the dynamics of public affect in the time of COVID-19. By contrasting two very different countries, China and the Unites States, we reveal sharp differences in people's views on COVID-19 in different cultures. Our study provides a computational approach to unveiling public emotions and concerns on the pandemic in real-time, which would potentially help policy-makers better understand people's need and thus make optimal policy.
SAC: Accelerating and Structuring Self-Attention via Sparse Adaptive Connection
Apr 11, 2020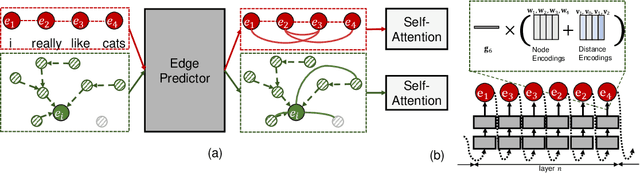
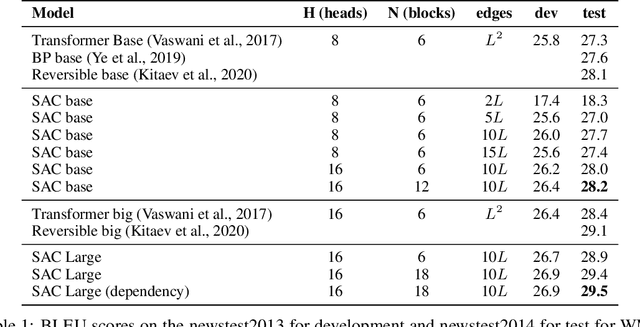
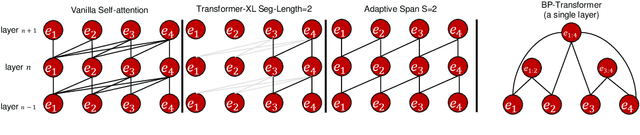
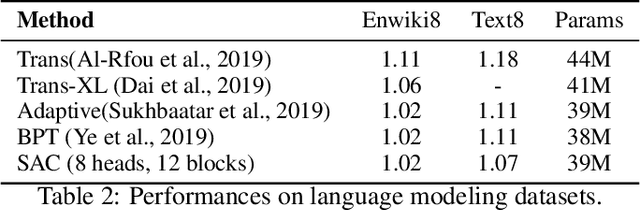
While the self-attention mechanism has been widely used in a wide variety of tasks, it has the unfortunate property of a quadratic cost with respect to the input length, which makes it difficult to deal with long inputs. In this paper, we present a method for accelerating and structuring self-attentions: Sparse Adaptive Connection (SAC). In SAC, we regard the input sequence as a graph and attention operations are performed between linked nodes. In contrast with previous self-attention models with pre-defined structures (edges), the model learns to construct attention edges to improve task-specific performances. In this way, the model is able to select the most salient nodes and reduce the quadratic complexity regardless of the sequence length. Based on SAC, we show that previous variants of self-attention models are its special cases. Through extensive experiments on neural machine translation, language modeling, graph representation learning and image classification, we demonstrate SAC is competitive with state-of-the-art models while significantly reducing memory cost.