 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBOP Challenge 2022 on Detection, Segmentation and Pose Estimation of Specific Rigid Objects
Feb 25, 2023We present the evaluation methodology, datasets and results of the BOP Challenge 2022, the fourth in a series of public competitions organized with the goal to capture the status quo in the field of 6D object pose estimation from an RGB/RGB-D image. In 2022, we witnessed another significant improvement in the pose estimation accuracy -- the state of the art, which was 56.9 AR$_C$ in 2019 (Vidal et al.) and 69.8 AR$_C$ in 2020 (CosyPose), moved to new heights of 83.7 AR$_C$ (GDRNPP). Out of 49 pose estimation methods evaluated since 2019, the top 18 are from 2022. Methods based on point pair features, which were introduced in 2010 and achieved competitive results even in 2020, are now clearly outperformed by deep learning methods. The synthetic-to-real domain gap was again significantly reduced, with 82.7 AR$_C$ achieved by GDRNPP trained only on synthetic images from BlenderProc. The fastest variant of GDRNPP reached 80.5 AR$_C$ with an average time per image of 0.23s. Since most of the recent methods for 6D object pose estimation begin by detecting/segmenting objects, we also started evaluating 2D object detection and segmentation performance based on the COCO metrics. Compared to the Mask R-CNN results from CosyPose in 2020, detection improved from 60.3 to 77.3 AP$_C$ and segmentation from 40.5 to 58.7 AP$_C$. The online evaluation system stays open and is available at: \href{http://bop.felk.cvut.cz/}{bop.felk.cvut.cz}.
A Large Scale Homography Benchmark
Feb 20, 2023



We present a large-scale dataset of Planes in 3D, Pi3D, of roughly 1000 planes observed in 10 000 images from the 1DSfM dataset, and HEB, a large-scale homography estimation benchmark leveraging Pi3D. The applications of the Pi3D dataset are diverse, e.g. training or evaluating monocular depth, surface normal estimation and image matching algorithms. The HEB dataset consists of 226 260 homographies and includes roughly 4M correspondences. The homographies link images that often undergo significant viewpoint and illumination changes. As applications of HEB, we perform a rigorous evaluation of a wide range of robust estimators and deep learning-based correspondence filtering methods, establishing the current state-of-the-art in robust homography estimation. We also evaluate the uncertainty of the SIFT orientations and scales w.r.t. the ground truth coming from the underlying homographies and provide codes for comparing uncertainty of custom detectors. The dataset is available at \url{https://github.com/danini/homography-benchmark}.
Planar Object Tracking via Weighted Optical Flow
Jan 24, 2023We propose WOFT -- a novel method for planar object tracking that estimates a full 8 degrees-of-freedom pose, i.e. the homography w.r.t. a reference view. The method uses a novel module that leverages dense optical flow and assigns a weight to each optical flow correspondence, estimating a homography by weighted least squares in a fully differentiable manner. The trained module assigns zero weights to incorrect correspondences (outliers) in most cases, making the method robust and eliminating the need of the typically used non-differentiable robust estimators like RANSAC. The proposed weighted optical flow tracker (WOFT) achieves state-of-the-art performance on two benchmarks, POT-210 and POIC, tracking consistently well across a wide range of scenarios.
Fully Differentiable RANSAC
Dec 26, 2022We propose the fully differentiable $\nabla$-RANSAC.It predicts the inlier probabilities of the input data points, exploits the predictions in a guided sampler, and estimates the model parameters (e.g., fundamental matrix) and its quality while propagating the gradients through the entire procedure. The random sampler in $\nabla$-RANSAC is based on a clever re-parametrization strategy, i.e.\ the Gumbel Softmax sampler, that allows propagating the gradients directly into the subsequent differentiable minimal solver. The model quality function marginalizes over the scores from all models estimated within $\nabla$-RANSAC to guide the network learning accurate and useful probabilities.$\nabla$-RANSAC is the first to unlock the end-to-end training of geometric estimation pipelines, containing feature detection, matching and RANSAC-like randomized robust estimation. As a proof of its potential, we train $\nabla$-RANSAC together with LoFTR, i.e. a recent detector-free feature matcher, to find reliable correspondences in an end-to-end manner. We test $\nabla$-RANSAC on a number of real-world datasets on fundamental and essential matrix estimation. It is superior to the state-of-the-art in terms of accuracy while being among the fastest methods. The code and trained models will be made public.
Trans2k: Unlocking the Power of Deep Models for Transparent Object Tracking
Oct 07, 2022

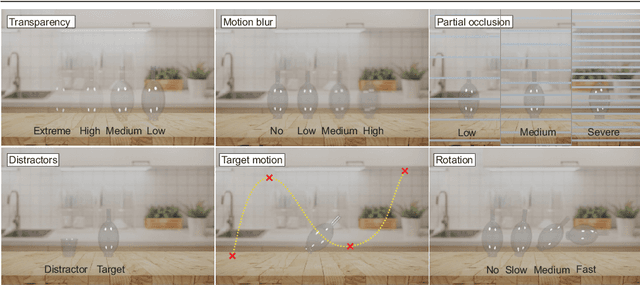
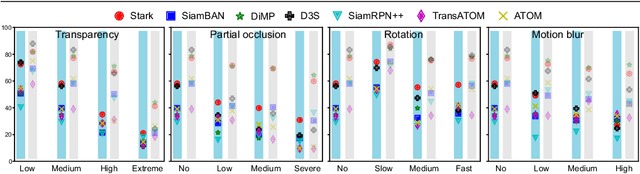
Visual object tracking has focused predominantly on opaque objects, while transparent object tracking received very little attention. Motivated by the uniqueness of transparent objects in that their appearance is directly affected by the background, the first dedicated evaluation dataset has emerged recently. We contribute to this effort by proposing the first transparent object tracking training dataset Trans2k that consists of over 2k sequences with 104,343 images overall, annotated by bounding boxes and segmentation masks. Noting that transparent objects can be realistically rendered by modern renderers, we quantify domain-specific attributes and render the dataset containing visual attributes and tracking situations not covered in the existing object training datasets. We observe a consistent performance boost (up to 16%) across a diverse set of modern tracking architectures when trained using Trans2k, and show insights not previously possible due to the lack of appropriate training sets. The dataset and the rendering engine will be publicly released to unlock the power of modern learning-based trackers and foster new designs in transparent object tracking.
HRF-Net: Holistic Radiance Fields from Sparse Inputs
Aug 09, 2022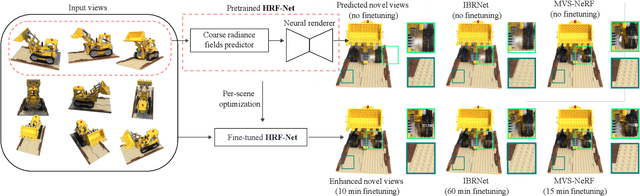
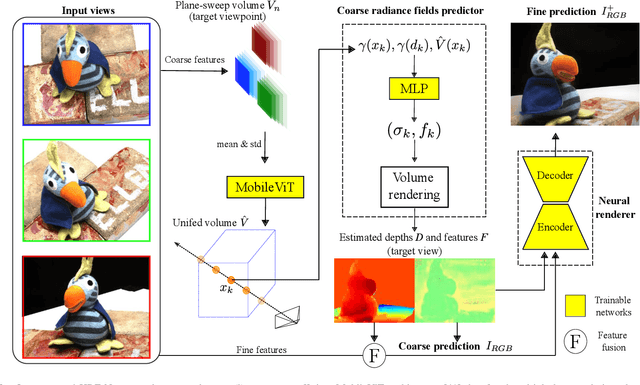
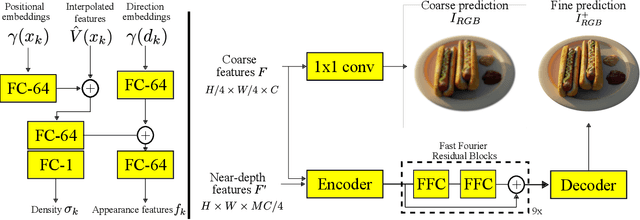
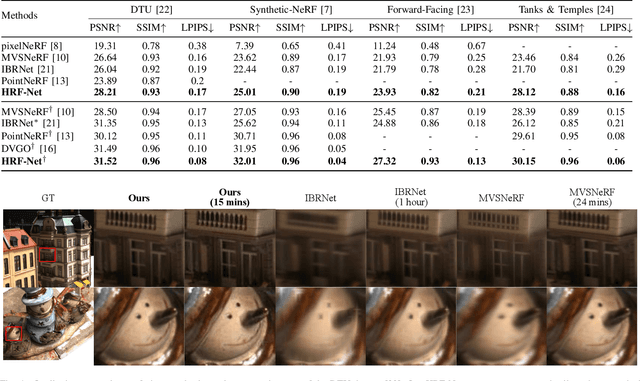
We present HRF-Net, a novel view synthesis method based on holistic radiance fields that renders novel views using a set of sparse inputs. Recent generalizing view synthesis methods also leverage the radiance fields but the rendering speed is not real-time. There are existing methods that can train and render novel views efficiently but they can not generalize to unseen scenes. Our approach addresses the problem of real-time rendering for generalizing view synthesis and consists of two main stages: a holistic radiance fields predictor and a convolutional-based neural renderer. This architecture infers not only consistent scene geometry based on the implicit neural fields but also renders new views efficiently using a single GPU. We first train HRF-Net on multiple 3D scenes of the DTU dataset and the network can produce plausible novel views on unseen real and synthetics data using only photometric losses. Moreover, our method can leverage a denser set of reference images of a single scene to produce accurate novel views without relying on additional explicit representations and still maintains the high-speed rendering of the pre-trained model. Experimental results show that HRF-Net outperforms state-of-the-art generalizable neural rendering methods on various synthetic and real datasets.
Human keypoint detection for close proximity human-robot interaction
Jul 15, 2022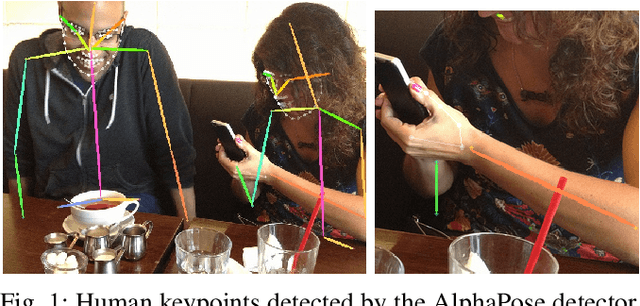
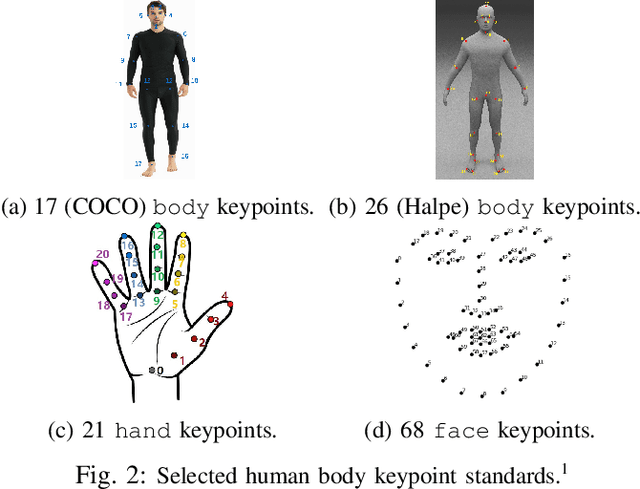

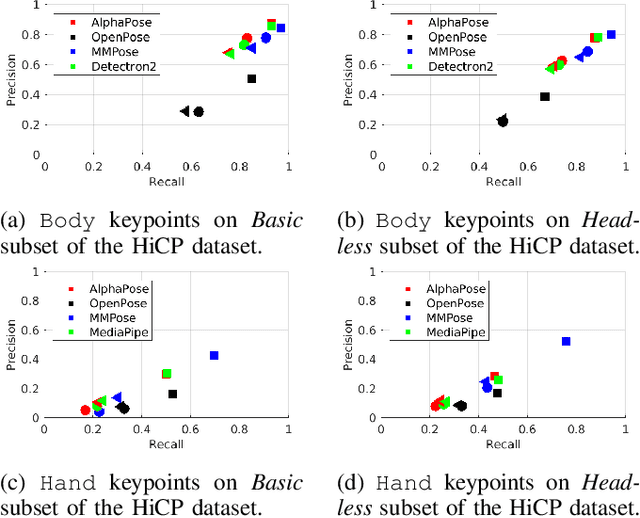
We study the performance of state-of-the-art human keypoint detectors in the context of close proximity human-robot interaction. The detection in this scenario is specific in that only a subset of body parts such as hands and torso are in the field of view. In particular, (i) we survey existing datasets with human pose annotation from the perspective of close proximity images and prepare and make publicly available a new Human in Close Proximity (HiCP) dataset; (ii) we quantitatively and qualitatively compare state-of-the-art human whole-body 2D keypoint detection methods (OpenPose, MMPose, AlphaPose, Detectron2) on this dataset; (iii) since accurate detection of hands and fingers is critical in applications with handovers, we evaluate the performance of the MediaPipe hand detector; (iv) we deploy the algorithms on a humanoid robot with an RGB-D camera on its head and evaluate the performance in 3D human keypoint detection. A motion capture system is used as reference. The best performing whole-body keypoint detectors in close proximity were MMPose and AlphaPose, but both had difficulty with finger detection. Thus, we propose a combination of MMPose or AlphaPose for the body and MediaPipe for the hands in a single framework providing the most accurate and robust detection. We also analyse the failure modes of individual detectors -- for example, to what extent the absence of the head of the person in the image degrades performance. Finally, we demonstrate the framework in a scenario where a humanoid robot interacting with a person uses the detected 3D keypoints for whole-body avoidance maneuvers.
Fast Neural Architecture Search for Lightweight Dense Prediction Networks
Mar 09, 2022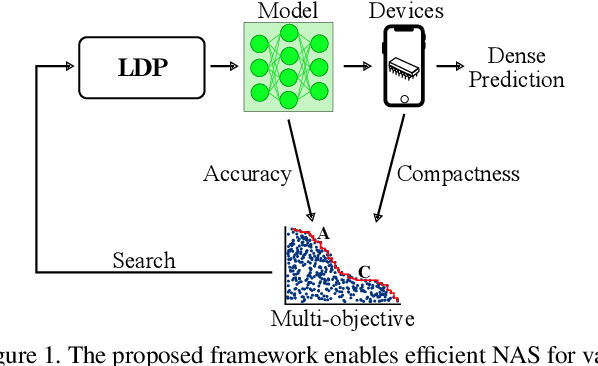
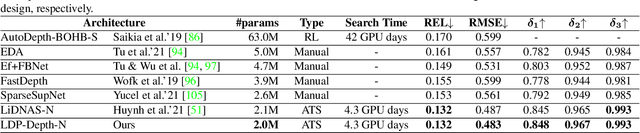
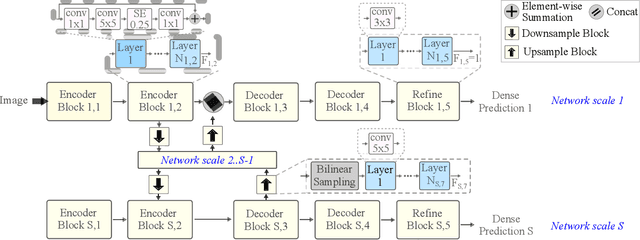
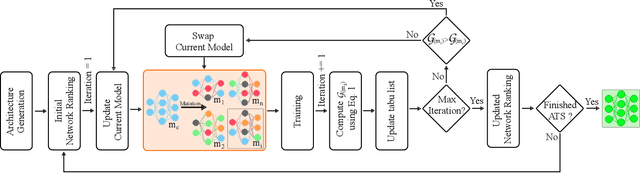
We present LDP, a lightweight dense prediction neural architecture search (NAS) framework. Starting from a pre-defined generic backbone, LDP applies the novel Assisted Tabu Search for efficient architecture exploration. LDP is fast and suitable for various dense estimation problems, unlike previous NAS methods that are either computational demanding or deployed only for a single subtask. The performance of LPD is evaluated on monocular depth estimation, semantic segmentation, and image super-resolution tasks on diverse datasets, including NYU-Depth-v2, KITTI, Cityscapes, COCO-stuff, DIV2K, Set5, Set14, BSD100, Urban100. Experiments show that the proposed framework yields consistent improvements on all tested dense prediction tasks, while being $5\%-315\%$ more compact in terms of the number of model parameters than prior arts.
Visual Object Tracking with Discriminative Filters and Siamese Networks: A Survey and Outlook
Dec 06, 2021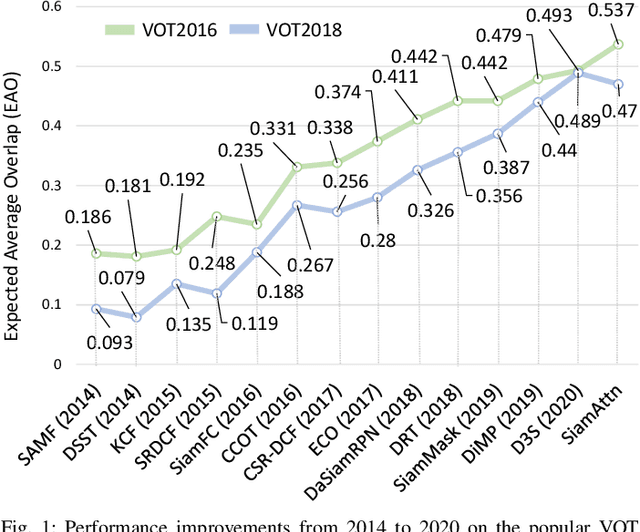
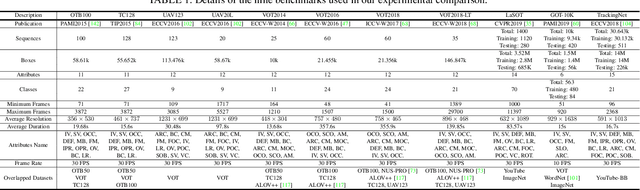
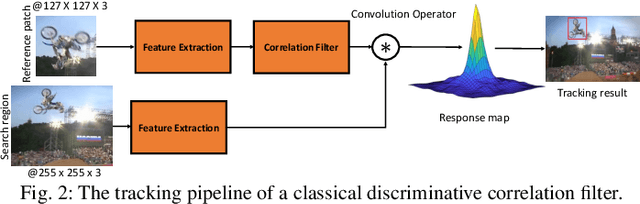
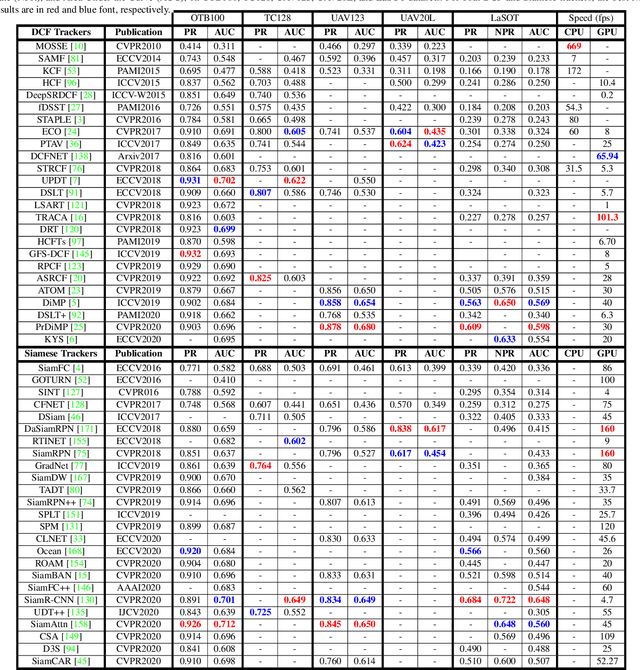
Accurate and robust visual object tracking is one of the most challenging and fundamental computer vision problems. It entails estimating the trajectory of the target in an image sequence, given only its initial location, and segmentation, or its rough approximation in the form of a bounding box. Discriminative Correlation Filters (DCFs) and deep Siamese Networks (SNs) have emerged as dominating tracking paradigms, which have led to significant progress. Following the rapid evolution of visual object tracking in the last decade, this survey presents a systematic and thorough review of more than 90 DCFs and Siamese trackers, based on results in nine tracking benchmarks. First, we present the background theory of both the DCF and Siamese tracking core formulations. Then, we distinguish and comprehensively review the shared as well as specific open research challenges in both these tracking paradigms. Furthermore, we thoroughly analyze the performance of DCF and Siamese trackers on nine benchmarks, covering different experimental aspects of visual tracking: datasets, evaluation metrics, performance, and speed comparisons. We finish the survey by presenting recommendations and suggestions for distinguished open challenges based on our analysis.
Deep MAGSAC++
Nov 28, 2021
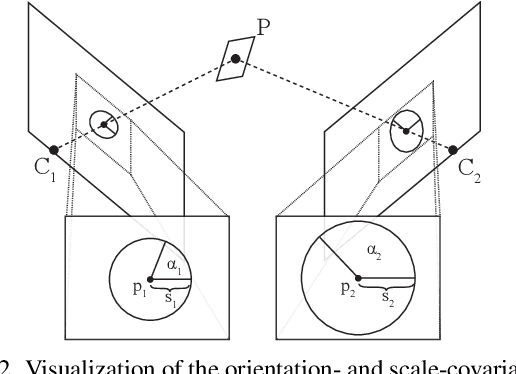
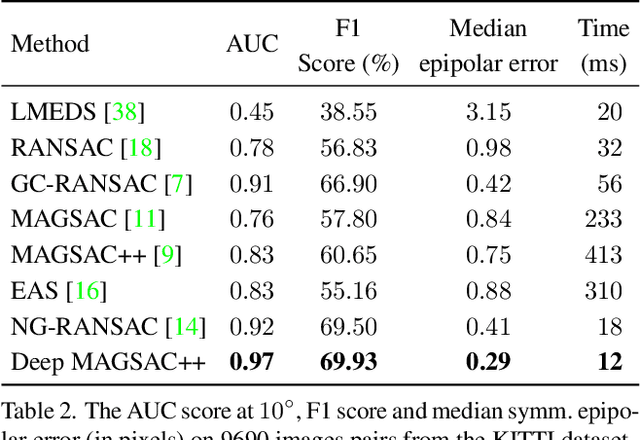
We propose Deep MAGSAC++ combining the advantages of traditional and deep robust estimators. We introduce a novel loss function that exploits the orientation and scale from partially affine covariant features, e.g., SIFT, in a geometrically justifiable manner. The new loss helps in learning higher-order information about the underlying scene geometry. Moreover, we propose a new sampler for RANSAC that always selects the sample with the highest probability of consisting only of inliers. After every unsuccessful iteration, the probabilities are updated in a principled way via a Bayesian approach. The prediction of the deep network is exploited as prior inside the sampler. Benefiting from the new loss, the proposed sampler, and a number of technical advancements, Deep MAGSAC++ is superior to the state-of-the-art both in terms of accuracy and run-time on thousands of image pairs from publicly available datasets for essential and fundamental matrix estimation.