 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeshLoom: Feed-Forward Non-Rigid Registration of Mesh Sequences
Jun 15, 2026We present MeshLoom, a feed-forward registration network that directly reconstructs vertex deformations across mesh sequences. Our approach advances non-rigid registration beyond existing models, which are typically constrained by costly per-instance optimization, narrow object categories, pairwise-only inputs, or merely intermediate outputs. The network is simple and efficient, registering multiple meshes within seconds. At its core lies a topology-aware encoder--decoder design. Specifically, we first introduce a topology-aware point representation that encodes the anchor (reference) mesh's topology into its per-vertex features. This representation strengthens the network's understanding of the anchor-mesh geometry and disambiguates points that are Euclidean-close yet geodesically distant. We then propose a multi-modal encoder that fuses this anchor-mesh representation with complementary cues from each frame, such as shape latents and image features. These multi-source signals are compressed into a compact global motion embedding that captures dense inter-frame correspondence. A lightweight decoder then queries this global embedding with the anchor-mesh point representation, retrieving per-vertex deformations at target timestamps. Through extensive experiments across diverse motions and object categories, we show that MeshLoom achieves state-of-the-art results on non-rigid registration. In addition, we find that our global embedding-then-query paradigm naturally enables the network to generate deformations at intermediate timestamps, which extends MeshLoom to motion interpolation and mesh morphing. Project page: https://meshloom.github.io/ .
Helix4D: Complex 4D Mesh Generation
May 25, 2026Current video-to-4D methods struggle with complex topology changes, transparent materials, thin structures, and inner surfaces. We present Helix4D, a dynamic mesh generation framework by inheriting the expressive representation of Trellis2, adapting it from image-to-3D to video-conditioned 4D generation. Our design arises from two key questions: (a) how to enable Trellis2's frame-local attention to share information across frames while preserving its pretrained quality on rare cases such as transparent objects and inner surfaces, and (b) how to inject temporal information into a purely 3D positional encoding without breaking pretrained capabilities. We address (a) with a sliding-window cross-frame attention and anchor on the first frame. The first frame is generated by the base Trellis2 model and injected into our model, letting it inherit Trellis2's quality in rare cases through cross-frame attention. We address (b) with a 4D temporal encoding that repurposes redundant low-frequency spatial RoPE bands for time, extending the encoding from 3D with no additional parameters. Extensive experiments show the effectiveness of Helix4D for high-quality dynamic mesh generation on ActionBench and our own challenging complex dynamics set.
Image Sculpting: Precise Object Editing with 3D Geometry Control
Jan 02, 2024We present Image Sculpting, a new framework for editing 2D images by incorporating tools from 3D geometry and graphics. This approach differs markedly from existing methods, which are confined to 2D spaces and typically rely on textual instructions, leading to ambiguity and limited control. Image Sculpting converts 2D objects into 3D, enabling direct interaction with their 3D geometry. Post-editing, these objects are re-rendered into 2D, merging into the original image to produce high-fidelity results through a coarse-to-fine enhancement process. The framework supports precise, quantifiable, and physically-plausible editing options such as pose editing, rotation, translation, 3D composition, carving, and serial addition. It marks an initial step towards combining the creative freedom of generative models with the precision of graphics pipelines.
Gotcha: A Challenge-Response System for Real-Time Deepfake Detection
Oct 12, 2022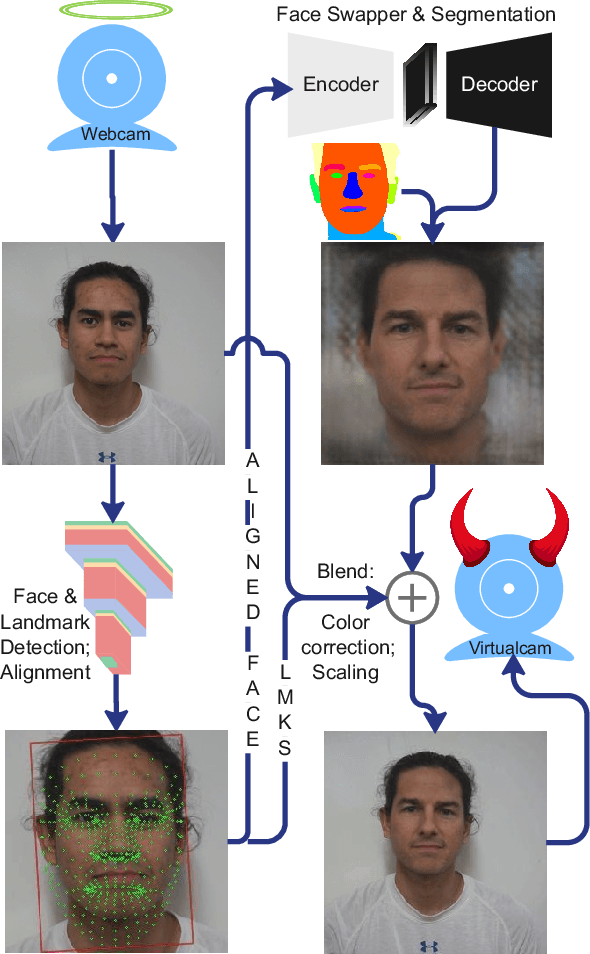
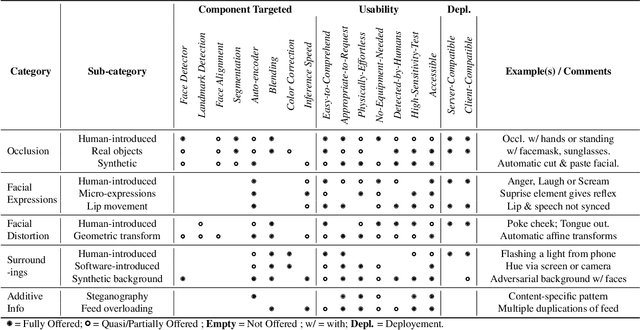
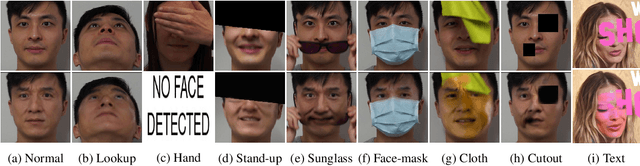
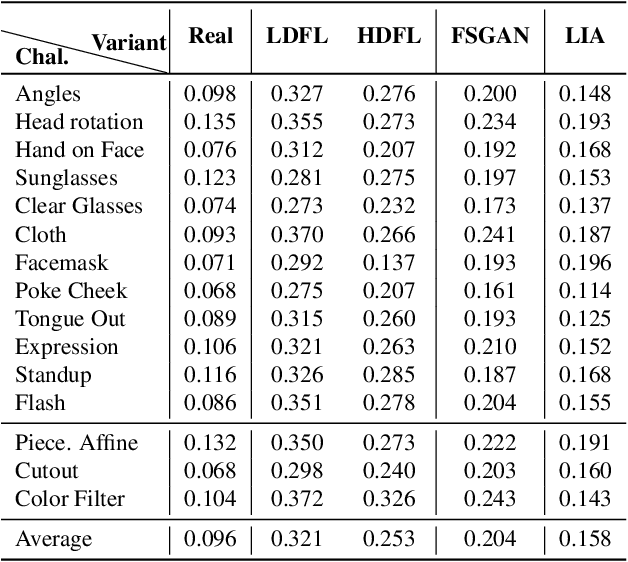
The integrity of online video interactions is threatened by the widespread rise of AI-enabled high-quality deepfakes that are now deployable in real-time. This paper presents Gotcha, a real-time deepfake detection system for live video interactions. The core principle underlying Gotcha is the presentation of a specially chosen cascade of both active and passive challenges to video conference participants. Active challenges include inducing changes in face occlusion, face expression, view angle, and ambiance; passive challenges include digital manipulation of the webcam feed. The challenges are designed to target vulnerabilities in the structure of modern deepfake generators and create perceptible artifacts for the human eye while inducing robust signals for ML-based automatic deepfake detectors. We present a comprehensive taxonomy of a large set of challenge tasks, which reveals a natural hierarchy among different challenges. Our system leverages this hierarchy by cascading progressively more demanding challenges to a suspected deepfake. We evaluate our system on a novel dataset of live users emulating deepfakes and show that our system provides consistent, measurable degradation of deepfake quality, showcasing its promise for robust real-time deepfake detection when deployed in the wild.
NeX: Real-time View Synthesis with Neural Basis Expansion
Mar 09, 2021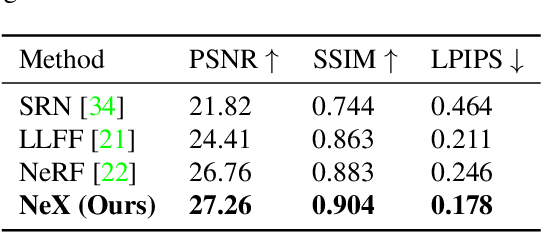
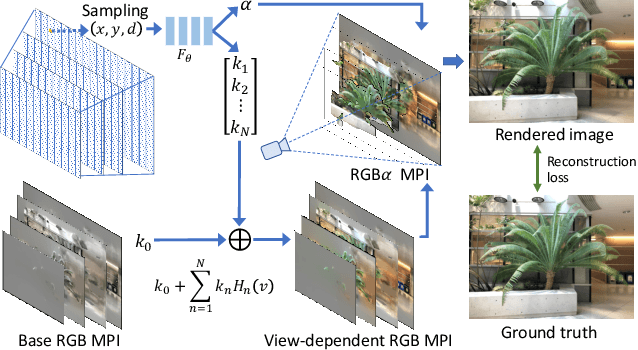
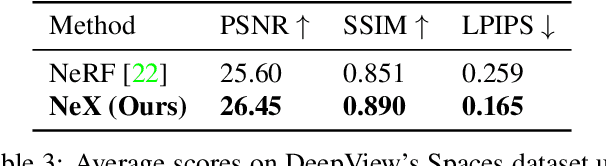
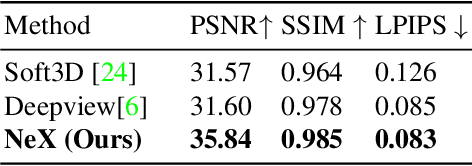
We present NeX, a new approach to novel view synthesis based on enhancements of multiplane image (MPI) that can reproduce next-level view-dependent effects -- in real time. Unlike traditional MPI that uses a set of simple RGB$\alpha$ planes, our technique models view-dependent effects by instead parameterizing each pixel as a linear combination of basis functions learned from a neural network. Moreover, we propose a hybrid implicit-explicit modeling strategy that improves upon fine detail and produces state-of-the-art results. Our method is evaluated on benchmark forward-facing datasets as well as our newly-introduced dataset designed to test the limit of view-dependent modeling with significantly more challenging effects such as rainbow reflections on a CD. Our method achieves the best overall scores across all major metrics on these datasets with more than 1000$\times$ faster rendering time than the state of the art. For real-time demos, visit https://nex-mpi.github.io/