 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-based Facial Aesthetics Enhancement with 3D Structure Guidance
Mar 18, 2025Facial Aesthetics Enhancement (FAE) aims to improve facial attractiveness by adjusting the structure and appearance of a facial image while preserving its identity as much as possible. Most existing methods adopted deep feature-based or score-based guidance for generation models to conduct FAE. Although these methods achieved promising results, they potentially produced excessively beautified results with lower identity consistency or insufficiently improved facial attractiveness. To enhance facial aesthetics with less loss of identity, we propose the Nearest Neighbor Structure Guidance based on Diffusion (NNSG-Diffusion), a diffusion-based FAE method that beautifies a 2D facial image with 3D structure guidance. Specifically, we propose to extract FAE guidance from a nearest neighbor reference face. To allow for less change of facial structures in the FAE process, a 3D face model is recovered by referring to both the matched 2D reference face and the 2D input face, so that the depth and contour guidance can be extracted from the 3D face model. Then the depth and contour clues can provide effective guidance to Stable Diffusion with ControlNet for FAE. Extensive experiments demonstrate that our method is superior to previous relevant methods in enhancing facial aesthetics while preserving facial identity.
Enhancing Incomplete Multi-modal Brain Tumor Segmentation with Intra-modal Asymmetry and Inter-modal Dependency
Jun 14, 2024



Deep learning-based brain tumor segmentation (BTS) models for multi-modal MRI images have seen significant advancements in recent years. However, a common problem in practice is the unavailability of some modalities due to varying scanning protocols and patient conditions, making segmentation from incomplete MRI modalities a challenging issue. Previous methods have attempted to address this by fusing accessible multi-modal features, leveraging attention mechanisms, and synthesizing missing modalities using generative models. However, these methods ignore the intrinsic problems of medical image segmentation, such as the limited availability of training samples, particularly for cases with tumors. Furthermore, these methods require training and deploying a specific model for each subset of missing modalities. To address these issues, we propose a novel approach that enhances the BTS model from two perspectives. Firstly, we introduce a pre-training stage that generates a diverse pre-training dataset covering a wide range of different combinations of tumor shapes and brain anatomy. Secondly, we propose a post-training stage that enables the model to reconstruct missing modalities in the prediction results when only partial modalities are available. To achieve the pre-training stage, we conceptually decouple the MRI image into two parts: `anatomy' and `tumor'. We pre-train the BTS model using synthesized data generated from the anatomy and tumor parts across different training samples. ... Extensive experiments demonstrate that our proposed method significantly improves the performance over the baseline and achieves new state-of-the-art results on three brain tumor segmentation datasets: BRATS2020, BRATS2018, and BRATS2015.
Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
Nov 12, 2023



Multi-modality foundation models, as represented by GPT-4V, have brought a new paradigm for low-level visual perception and understanding tasks, that can respond to a broad range of natural human instructions in a model. While existing foundation models have shown exciting potentials on low-level visual tasks, their related abilities are still preliminary and need to be improved. In order to enhance these models, we conduct a large-scale subjective experiment collecting a vast number of real human feedbacks on low-level vision. Each feedback follows a pathway that starts with a detailed description on the low-level visual appearance (*e.g. clarity, color, brightness* of an image, and ends with an overall conclusion, with an average length of 45 words. The constructed **Q-Pathway** dataset includes 58K detailed human feedbacks on 18,973 images with diverse low-level appearance. Moreover, to enable foundation models to robustly respond to diverse types of questions, we design a GPT-participated conversion to process these feedbacks into diverse-format 200K instruction-response pairs. Experimental results indicate that the **Q-Instruct** consistently elevates low-level perception and understanding abilities across several foundational models. We anticipate that our datasets can pave the way for a future that general intelligence can perceive, understand low-level visual appearance and evaluate visual quality like a human. Our dataset, model zoo, and demo is published at: https://q-future.github.io/Q-Instruct.
TOPIQ: A Top-down Approach from Semantics to Distortions for Image Quality Assessment
Aug 06, 2023



Image Quality Assessment (IQA) is a fundamental task in computer vision that has witnessed remarkable progress with deep neural networks. Inspired by the characteristics of the human visual system, existing methods typically use a combination of global and local representations (\ie, multi-scale features) to achieve superior performance. However, most of them adopt simple linear fusion of multi-scale features, and neglect their possibly complex relationship and interaction. In contrast, humans typically first form a global impression to locate important regions and then focus on local details in those regions. We therefore propose a top-down approach that uses high-level semantics to guide the IQA network to focus on semantically important local distortion regions, named as \emph{TOPIQ}. Our approach to IQA involves the design of a heuristic coarse-to-fine network (CFANet) that leverages multi-scale features and progressively propagates multi-level semantic information to low-level representations in a top-down manner. A key component of our approach is the proposed cross-scale attention mechanism, which calculates attention maps for lower level features guided by higher level features. This mechanism emphasizes active semantic regions for low-level distortions, thereby improving performance. CFANet can be used for both Full-Reference (FR) and No-Reference (NR) IQA. We use ResNet50 as its backbone and demonstrate that CFANet achieves better or competitive performance on most public FR and NR benchmarks compared with state-of-the-art methods based on vision transformers, while being much more efficient (with only ${\sim}13\%$ FLOPS of the current best FR method). Codes are released at \url{https://github.com/chaofengc/IQA-PyTorch}.
Integrating Large Pre-trained Models into Multimodal Named Entity Recognition with Evidential Fusion
Jun 29, 2023Multimodal Named Entity Recognition (MNER) is a crucial task for information extraction from social media platforms such as Twitter. Most current methods rely on attention weights to extract information from both text and images but are often unreliable and lack interpretability. To address this problem, we propose incorporating uncertainty estimation into the MNER task, producing trustworthy predictions. Our proposed algorithm models the distribution of each modality as a Normal-inverse Gamma distribution, and fuses them into a unified distribution with an evidential fusion mechanism, enabling hierarchical characterization of uncertainties and promotion of prediction accuracy and trustworthiness. Additionally, we explore the potential of pre-trained large foundation models in MNER and propose an efficient fusion approach that leverages their robust feature representations. Experiments on two datasets demonstrate that our proposed method outperforms the baselines and achieves new state-of-the-art performance.
Towards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach
May 22, 2023



The proliferation of in-the-wild videos has greatly expanded the Video Quality Assessment (VQA) problem. Unlike early definitions that usually focus on limited distortion types, VQA on in-the-wild videos is especially challenging as it could be affected by complicated factors, including various distortions and diverse contents. Though subjective studies have collected overall quality scores for these videos, how the abstract quality scores relate with specific factors is still obscure, hindering VQA methods from more concrete quality evaluations (e.g. sharpness of a video). To solve this problem, we collect over two million opinions on 4,543 in-the-wild videos on 13 dimensions of quality-related factors, including in-capture authentic distortions (e.g. motion blur, noise, flicker), errors introduced by compression and transmission, and higher-level experiences on semantic contents and aesthetic issues (e.g. composition, camera trajectory), to establish the multi-dimensional Maxwell database. Specifically, we ask the subjects to label among a positive, a negative, and a neural choice for each dimension. These explanation-level opinions allow us to measure the relationships between specific quality factors and abstract subjective quality ratings, and to benchmark different categories of VQA algorithms on each dimension, so as to more comprehensively analyze their strengths and weaknesses. Furthermore, we propose the MaxVQA, a language-prompted VQA approach that modifies vision-language foundation model CLIP to better capture important quality issues as observed in our analyses. The MaxVQA can jointly evaluate various specific quality factors and final quality scores with state-of-the-art accuracy on all dimensions, and superb generalization ability on existing datasets. Code and data available at \url{https://github.com/VQAssessment/MaxVQA}.
Towards Robust Text-Prompted Semantic Criterion for In-the-Wild Video Quality Assessment
Apr 28, 2023



The proliferation of videos collected during in-the-wild natural settings has pushed the development of effective Video Quality Assessment (VQA) methodologies. Contemporary supervised opinion-driven VQA strategies predominantly hinge on training from expensive human annotations for quality scores, which limited the scale and distribution of VQA datasets and consequently led to unsatisfactory generalization capacity of methods driven by these data. On the other hand, although several handcrafted zero-shot quality indices do not require training from human opinions, they are unable to account for the semantics of videos, rendering them ineffective in comprehending complex authentic distortions (e.g., white balance, exposure) and assessing the quality of semantic content within videos. To address these challenges, we introduce the text-prompted Semantic Affinity Quality Index (SAQI) and its localized version (SAQI-Local) using Contrastive Language-Image Pre-training (CLIP) to ascertain the affinity between textual prompts and visual features, facilitating a comprehensive examination of semantic quality concerns without the reliance on human quality annotations. By amalgamating SAQI with existing low-level metrics, we propose the unified Blind Video Quality Index (BVQI) and its improved version, BVQI-Local, which demonstrates unprecedented performance, surpassing existing zero-shot indices by at least 24\% on all datasets. Moreover, we devise an efficient fine-tuning scheme for BVQI-Local that jointly optimizes text prompts and final fusion weights, resulting in state-of-the-art performance and superior generalization ability in comparison to prevalent opinion-driven VQA methods. We conduct comprehensive analyses to investigate different quality concerns of distinct indices, demonstrating the effectiveness and rationality of our design.
Exploring Opinion-unaware Video Quality Assessment with Semantic Affinity Criterion
Feb 26, 2023



Recent learning-based video quality assessment (VQA) algorithms are expensive to implement due to the cost of data collection of human quality opinions, and are less robust across various scenarios due to the biases of these opinions. This motivates our exploration on opinion-unaware (a.k.a zero-shot) VQA approaches. Existing approaches only considers low-level naturalness in spatial or temporal domain, without considering impacts from high-level semantics. In this work, we introduce an explicit semantic affinity index for opinion-unaware VQA using text-prompts in the contrastive language-image pre-training (CLIP) model. We also aggregate it with different traditional low-level naturalness indexes through gaussian normalization and sigmoid rescaling strategies. Composed of aggregated semantic and technical metrics, the proposed Blind Unified Opinion-Unaware Video Quality Index via Semantic and Technical Metric Aggregation (BUONA-VISTA) outperforms existing opinion-unaware VQA methods by at least 20% improvements, and is more robust than opinion-aware approaches.
Disentangling Aesthetic and Technical Effects for Video Quality Assessment of User Generated Content
Nov 16, 2022User-generated-content (UGC) videos have dominated the Internet during recent years. While it is well-recognized that the perceptual quality of these videos can be affected by diverse factors, few existing methods explicitly explore the effects of different factors in video quality assessment (VQA) for UGC videos, i.e. the UGC-VQA problem. In this work, we make the first attempt to disentangle the effects of aesthetic quality issues and technical quality issues risen by the complicated video generation processes in the UGC-VQA problem. To overcome the absence of respective supervisions during disentanglement, we propose the Limited View Biased Supervisions (LVBS) scheme where two separate evaluators are trained with decomposed views specifically designed for each issue. Composed of an Aesthetic Quality Evaluator (AQE) and a Technical Quality Evaluator (TQE) under the LVBS scheme, the proposed Disentangled Objective Video Quality Evaluator (DOVER) reach excellent performance (0.91 SRCC for KoNViD-1k, 0.89 SRCC for LSVQ, 0.88 SRCC for YouTube-UGC) in the UGC-VQA problem. More importantly, our blind subjective studies prove that the separate evaluators in DOVER can effectively match human perception on respective disentangled quality issues. Codes and demos are released in https://github.com/teowu/dover.
Neighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Oct 11, 2022
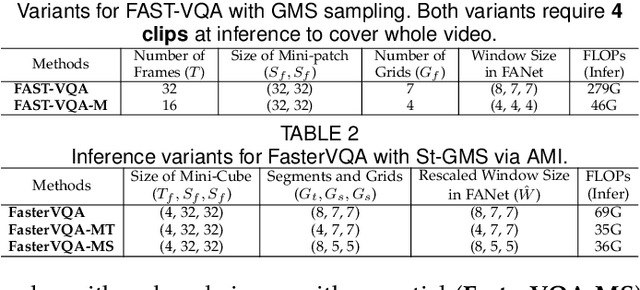
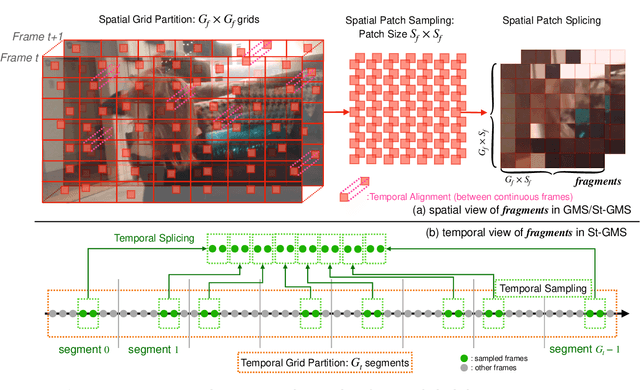
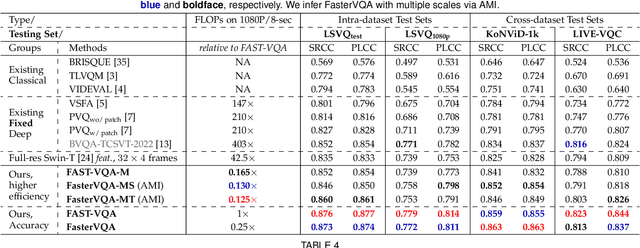
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.