 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCore-Periphery Principle Guided State Space Model for Functional Connectome Classification
Mar 18, 2025Understanding the organization of human brain networks has become a central focus in neuroscience, particularly in the study of functional connectivity, which plays a crucial role in diagnosing neurological disorders. Advances in functional magnetic resonance imaging and machine learning techniques have significantly improved brain network analysis. However, traditional machine learning approaches struggle to capture the complex relationships between brain regions, while deep learning methods, particularly Transformer-based models, face computational challenges due to their quadratic complexity in long-sequence modeling. To address these limitations, we propose a Core-Periphery State-Space Model (CP-SSM), an innovative framework for functional connectome classification. Specifically, we introduce Mamba, a selective state-space model with linear complexity, to effectively capture long-range dependencies in functional brain networks. Furthermore, inspired by the core-periphery (CP) organization, a fundamental characteristic of brain networks that enhances efficient information transmission, we design CP-MoE, a CP-guided Mixture-of-Experts that improves the representation learning of brain connectivity patterns. We evaluate CP-SSM on two benchmark fMRI datasets: ABIDE and ADNI. Experimental results demonstrate that CP-SSM surpasses Transformer-based models in classification performance while significantly reducing computational complexity. These findings highlight the effectiveness and efficiency of CP-SSM in modeling brain functional connectivity, offering a promising direction for neuroimaging-based neurological disease diagnosis.
Addressing Information Loss and Interaction Collapse: A Dual Enhanced Attention Framework for Feature Interaction
Mar 14, 2025The Transformer has proven to be a significant approach in feature interaction for CTR prediction, achieving considerable success in previous works. However, it also presents potential challenges in handling feature interactions. Firstly, Transformers may encounter information loss when capturing feature interactions. By relying on inner products to represent pairwise relationships, they compress raw interaction information, which can result in a degradation of fidelity. Secondly, due to the long-tail features distribution, feature fields with low information-abundance embeddings constrain the information abundance of other fields, leading to collapsed embedding matrices. To tackle these issues, we propose a Dual Attention Framework for Enhanced Feature Interaction, known as Dual Enhanced Attention. This framework integrates two attention mechanisms: the Combo-ID attention mechanism and the collapse-avoiding attention mechanism. The Combo-ID attention mechanism directly retains feature interaction pairs to mitigate information loss, while the collapse-avoiding attention mechanism adaptively filters out low information-abundance interaction pairs to prevent interaction collapse. Extensive experiments conducted on industrial datasets have shown the effectiveness of Dual Enhanced Attention.
RoMA: Scaling up Mamba-based Foundation Models for Remote Sensing
Mar 13, 2025Recent advances in self-supervised learning for Vision Transformers (ViTs) have fueled breakthroughs in remote sensing (RS) foundation models. However, the quadratic complexity of self-attention poses a significant barrier to scalability, particularly for large models and high-resolution images. While the linear-complexity Mamba architecture offers a promising alternative, existing RS applications of Mamba remain limited to supervised tasks on small, domain-specific datasets. To address these challenges, we propose RoMA, a framework that enables scalable self-supervised pretraining of Mamba-based RS foundation models using large-scale, diverse, unlabeled data. RoMA enhances scalability for high-resolution images through a tailored auto-regressive learning strategy, incorporating two key innovations: 1) a rotation-aware pretraining mechanism combining adaptive cropping with angular embeddings to handle sparsely distributed objects with arbitrary orientations, and 2) multi-scale token prediction objectives that address the extreme variations in object scales inherent to RS imagery. Systematic empirical studies validate that Mamba adheres to RS data and parameter scaling laws, with performance scaling reliably as model and data size increase. Furthermore, experiments across scene classification, object detection, and semantic segmentation tasks demonstrate that RoMA-pretrained Mamba models consistently outperform ViT-based counterparts in both accuracy and computational efficiency. The source code and pretrained models will be released at https://github.com/MiliLab/RoMA.
LLM-PS: Empowering Large Language Models for Time Series Forecasting with Temporal Patterns and Semantics
Mar 12, 2025Time Series Forecasting (TSF) is critical in many real-world domains like financial planning and health monitoring. Recent studies have revealed that Large Language Models (LLMs), with their powerful in-contextual modeling capabilities, hold significant potential for TSF. However, existing LLM-based methods usually perform suboptimally because they neglect the inherent characteristics of time series data. Unlike the textual data used in LLM pre-training, the time series data is semantically sparse and comprises distinctive temporal patterns. To address this problem, we propose LLM-PS to empower the LLM for TSF by learning the fundamental \textit{Patterns} and meaningful \textit{Semantics} from time series data. Our LLM-PS incorporates a new multi-scale convolutional neural network adept at capturing both short-term fluctuations and long-term trends within the time series. Meanwhile, we introduce a time-to-text module for extracting valuable semantics across continuous time intervals rather than isolated time points. By integrating these patterns and semantics, LLM-PS effectively models temporal dependencies, enabling a deep comprehension of time series and delivering accurate forecasts. Intensive experimental results demonstrate that LLM-PS achieves state-of-the-art performance in both short- and long-term forecasting tasks, as well as in few- and zero-shot settings.
Task-Specific Knowledge Distillation from the Vision Foundation Model for Enhanced Medical Image Segmentation
Mar 10, 2025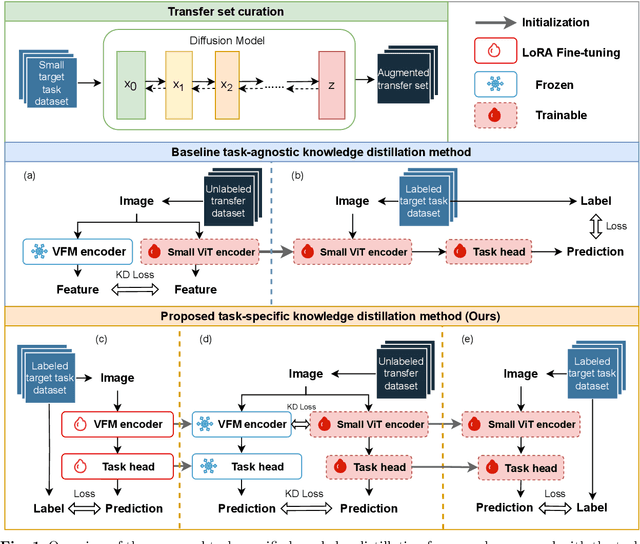
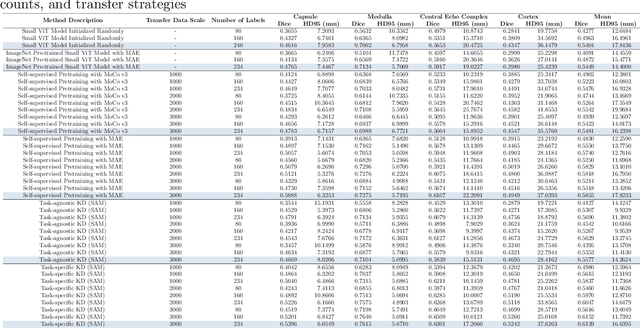
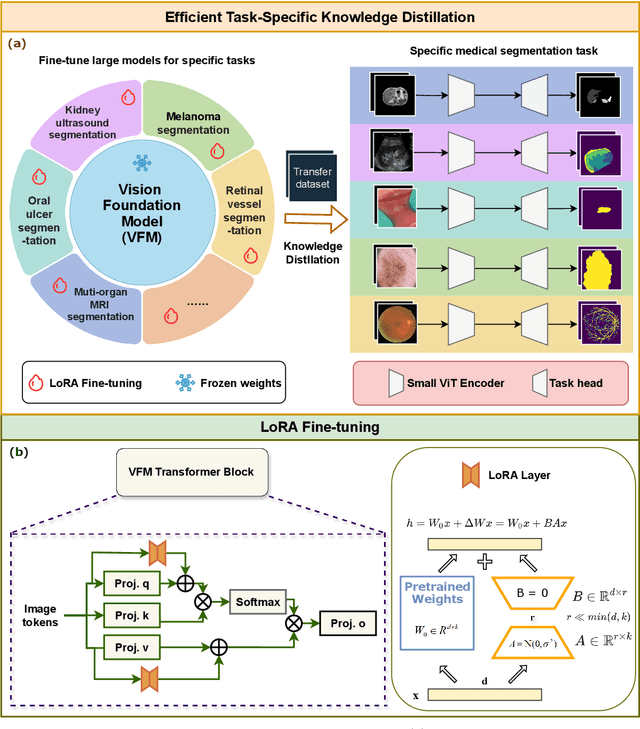
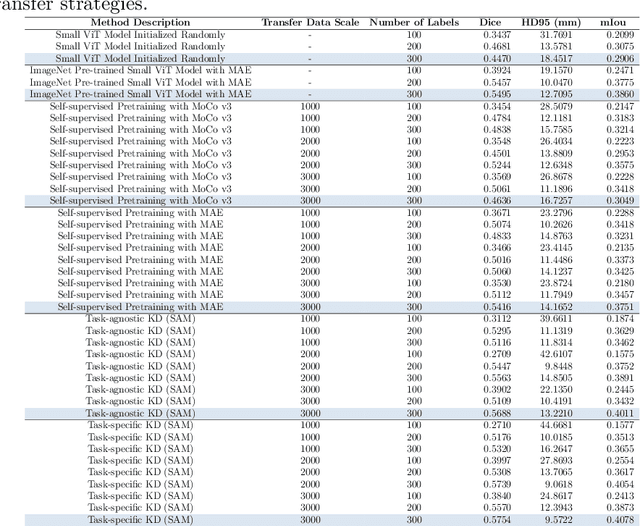
Large-scale pre-trained models, such as Vision Foundation Models (VFMs), have demonstrated impressive performance across various downstream tasks by transferring generalized knowledge, especially when target data is limited. However, their high computational cost and the domain gap between natural and medical images limit their practical application in medical segmentation tasks. Motivated by this, we pose the following important question: "How can we effectively utilize the knowledge of large pre-trained VFMs to train a small, task-specific model for medical image segmentation when training data is limited?" To address this problem, we propose a novel and generalizable task-specific knowledge distillation framework. Our method fine-tunes the VFM on the target segmentation task to capture task-specific features before distilling the knowledge to smaller models, leveraging Low-Rank Adaptation (LoRA) to reduce the computational cost of fine-tuning. Additionally, we incorporate synthetic data generated by diffusion models to augment the transfer set, enhancing model performance in data-limited scenarios. Experimental results across five medical image datasets demonstrate that our method consistently outperforms task-agnostic knowledge distillation and self-supervised pretraining approaches like MoCo v3 and Masked Autoencoders (MAE). For example, on the KidneyUS dataset, our method achieved a 28% higher Dice score than task-agnostic KD using 80 labeled samples for fine-tuning. On the CHAOS dataset, it achieved an 11% improvement over MAE with 100 labeled samples. These results underscore the potential of task-specific knowledge distillation to train accurate, efficient models for medical image segmentation in data-constrained settings.
LLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model
Mar 10, 2025



Index recommendation is essential for improving query performance in database management systems (DBMSs) through creating an optimal set of indexes under specific constraints. Traditional methods, such as heuristic and learning-based approaches, are effective but face challenges like lengthy recommendation time, resource-intensive training, and poor generalization across different workloads and database schemas. To address these issues, we propose LLMIdxAdvis, a resource-efficient index advisor that uses large language models (LLMs) without extensive fine-tuning. LLMIdxAdvis frames index recommendation as a sequence-to-sequence task, taking target workload, storage constraint, and corresponding database environment as input, and directly outputting recommended indexes. It constructs a high-quality demonstration pool offline, using GPT-4-Turbo to synthesize diverse SQL queries and applying integrated heuristic methods to collect both default and refined labels. During recommendation, these demonstrations are ranked to inject database expertise via in-context learning. Additionally, LLMIdxAdvis extracts workload features involving specific column statistical information to strengthen LLM's understanding, and introduces a novel inference scaling strategy combining vertical scaling (via ''Index-Guided Major Voting'' and Best-of-N) and horizontal scaling (through iterative ''self-optimization'' with database feedback) to enhance reliability. Experiments on 3 OLAP and 2 real-world benchmarks reveal that LLMIdxAdvis delivers competitive index recommendation with reduced runtime, and generalizes effectively across different workloads and database schemas.
VisualSimpleQA: A Benchmark for Decoupled Evaluation of Large Vision-Language Models in Fact-Seeking Question Answering
Mar 09, 2025Large vision-language models (LVLMs) have demonstrated remarkable achievements, yet the generation of non-factual responses remains prevalent in fact-seeking question answering (QA). Current multimodal fact-seeking benchmarks primarily focus on comparing model outputs to ground truth answers, providing limited insights into the performance of modality-specific modules. To bridge this gap, we introduce VisualSimpleQA, a multimodal fact-seeking benchmark with two key features. First, it enables streamlined and decoupled evaluation of LVLMs in visual and linguistic modalities. Second, it incorporates well-defined difficulty criteria to guide human annotation and facilitates the extraction of a challenging subset, VisualSimpleQA-hard. Experiments on 15 LVLMs show that even state-of-the-art models such as GPT-4o achieve merely 60%+ correctness in multimodal fact-seeking QA on VisualSimpleQA and 30%+ on VisualSimpleQA-hard. Furthermore, the decoupled evaluation across these models highlights substantial opportunities for improvement in both visual and linguistic modules. The dataset is available at https://huggingface.co/datasets/WYLing/VisualSimpleQA.
SAQ-SAM: Semantically-Aligned Quantization for Segment Anything Model
Mar 09, 2025



Segment Anything Model (SAM) exhibits remarkable zero-shot segmentation capability; however, its prohibitive computational costs make edge deployment challenging. Although post-training quantization (PTQ) offers a promising compression solution, existing methods yield unsatisfactory results when applied to SAM, owing to its specialized model components and promptable workflow: (i) The mask decoder's attention exhibits extreme outliers, and we find that aggressive clipping (ranging down to even 100$\times$), instead of smoothing or isolation, is effective in suppressing outliers while maintaining semantic capabilities. Unfortunately, traditional metrics (e.g., MSE) fail to provide such large-scale clipping. (ii) Existing reconstruction methods potentially neglect prompts' intention, resulting in distorted visual encodings during prompt interactions. To address the above issues, we propose SAQ-SAM in this paper, which boosts PTQ of SAM with semantic alignment. Specifically, we propose Perceptual-Consistency Clipping, which exploits attention focus overlap as clipping metric, to significantly suppress outliers. Furthermore, we propose Prompt-Aware Reconstruction, which incorporates visual-prompt interactions by leveraging cross-attention responses in mask decoder, thus facilitating alignment in both distribution and semantics. To ensure the interaction efficiency, we also introduce a layer-skipping strategy for visual tokens. Extensive experiments are conducted on different segmentation tasks and SAMs of various sizes, and the results show that the proposed SAQ-SAM consistently outperforms baselines. For example, when quantizing SAM-B to 4-bit, our method achieves 11.7% higher mAP than the baseline in instance segmentation task.
Semi-Supervised Learning for Dose Prediction in Targeted Radionuclide: A Synthetic Data Study
Mar 07, 2025Targeted Radionuclide Therapy (TRT) is a modern strategy in radiation oncology that aims to administer a potent radiation dose specifically to cancer cells using cancer-targeting radiopharmaceuticals. Accurate radiation dose estimation tailored to individual patients is crucial. Deep learning, particularly with pre-therapy imaging, holds promise for personalizing TRT doses. However, current methods require large time series of SPECT imaging, which is hardly achievable in routine clinical practice, and thus raises issues of data availability. Our objective is to develop a semi-supervised learning (SSL) solution to personalize dosimetry using pre-therapy images. The aim is to develop an approach that achieves accurate results when PET/CT images are available, but are associated with only a few post-therapy dosimetry data provided by SPECT images. In this work, we introduce an SSL method using a pseudo-label generation approach for regression tasks inspired by the FixMatch framework. The feasibility of the proposed solution was preliminarily evaluated through an in-silico study using synthetic data and Monte Carlo simulation. Experimental results for organ dose prediction yielded promising outcomes, showing that the use of pseudo-labeled data provides better accuracy compared to using only labeled data.
OmniSQL: Synthesizing High-quality Text-to-SQL Data at Scale
Mar 04, 2025Text-to-SQL, the task of translating natural language questions into SQL queries, plays a crucial role in enabling non-experts to interact with databases. While recent advancements in large language models (LLMs) have significantly enhanced text-to-SQL performance, existing approaches face notable limitations in real-world text-to-SQL applications. Prompting-based methods often depend on closed-source LLMs, which are expensive, raise privacy concerns, and lack customization. Fine-tuning-based methods, on the other hand, suffer from poor generalizability due to the limited coverage of publicly available training data. To overcome these challenges, we propose a novel and scalable text-to-SQL data synthesis framework for automatically synthesizing large-scale, high-quality, and diverse datasets without extensive human intervention. Using this framework, we introduce SynSQL-2.5M, the first million-scale text-to-SQL dataset, containing 2.5 million samples spanning over 16,000 synthetic databases. Each sample includes a database, SQL query, natural language question, and chain-of-thought (CoT) solution. Leveraging SynSQL-2.5M, we develop OmniSQL, a powerful open-source text-to-SQL model available in three sizes: 7B, 14B, and 32B. Extensive evaluations across nine datasets demonstrate that OmniSQL achieves state-of-the-art performance, matching or surpassing leading closed-source and open-source LLMs, including GPT-4o and DeepSeek-V3, despite its smaller size. We release all code, datasets, and models to support further research.