 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJing Jiang
Spatial-temporal Prompt Learning for Federated Weather Forecasting
May 23, 2023

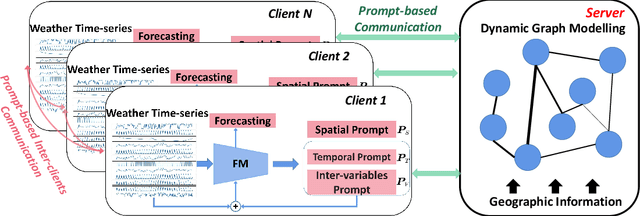

Federated weather forecasting is a promising collaborative learning framework for analyzing meteorological data across participants from different countries and regions, thus embodying a global-scale real-time weather data predictive analytics platform to tackle climate change. This paper is to model the meteorological data in a federated setting where many distributed low-resourced sensors are deployed in different locations. Specifically, we model the spatial-temporal weather data into a federated prompt learning framework that leverages lightweight prompts to share meaningful representation and structural knowledge among participants. Prompts-based communication allows the server to establish the structural topology relationships among participants and further explore the complex spatial-temporal correlations without transmitting private data while mitigating communication overhead. Moreover, in addition to a globally shared large model at the server, our proposed method enables each participant to acquire a personalized model that is highly customized to tackle climate changes in a specific geographic area. We have demonstrated the effectiveness of our method on classical weather forecasting tasks by utilizing three spatial-temporal multivariate time-series weather data.
Does Continual Learning Equally Forget All Parameters?
Apr 09, 2023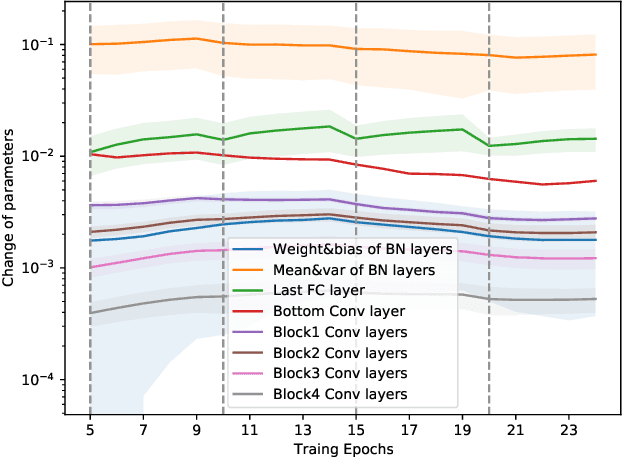
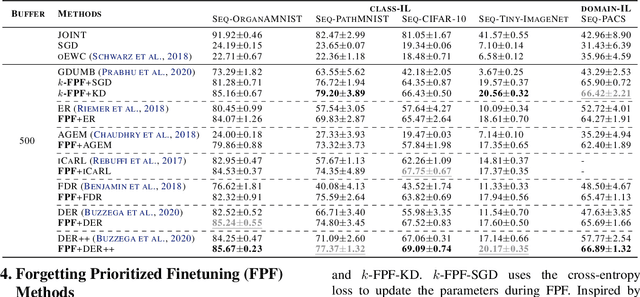
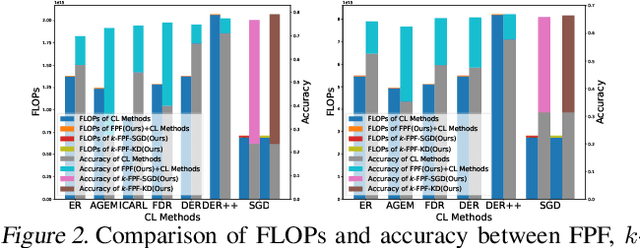
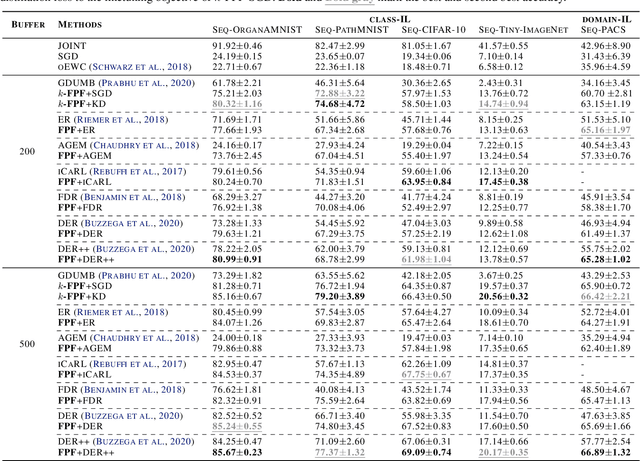
Distribution shift (e.g., task or domain shift) in continual learning (CL) usually results in catastrophic forgetting of neural networks. Although it can be alleviated by repeatedly replaying buffered data, the every-step replay is time-consuming. In this paper, we study which modules in neural networks are more prone to forgetting by investigating their training dynamics during CL. Our proposed metrics show that only a few modules are more task-specific and sensitively alter between tasks, while others can be shared across tasks as common knowledge. Hence, we attribute forgetting mainly to the former and find that finetuning them only on a small buffer at the end of any CL method can bring non-trivial improvement. Due to the small number of finetuned parameters, such ``Forgetting Prioritized Finetuning (FPF)'' is efficient in computation. We further propose a more efficient and simpler method that entirely removes the every-step replay and replaces them by only $k$-times of FPF periodically triggered during CL. Surprisingly, this ``$k$-FPF'' performs comparably to FPF and outperforms the SOTA CL methods but significantly reduces their computational overhead and cost. In experiments on several benchmarks of class- and domain-incremental CL, FPF consistently improves existing CL methods by a large margin, and $k$-FPF further excels in efficiency without degrading the accuracy. We also empirically studied the impact of buffer size, epochs per task, and finetuning modules on the cost and accuracy of our methods.
Adaptive Policy Learning for Offline-to-Online Reinforcement Learning
Mar 14, 2023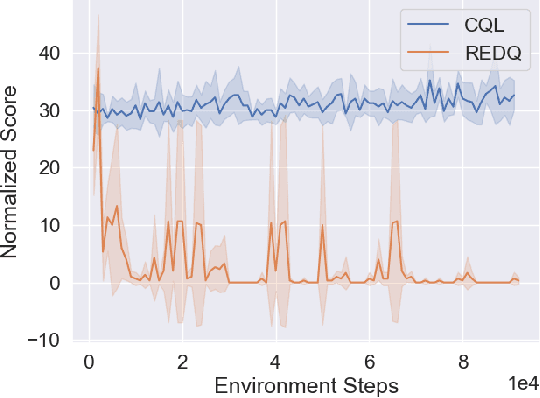
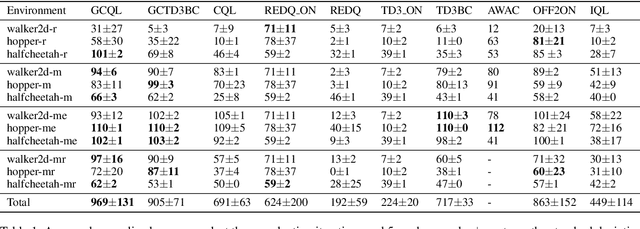
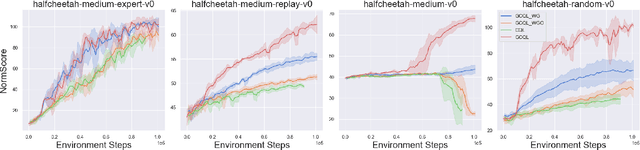
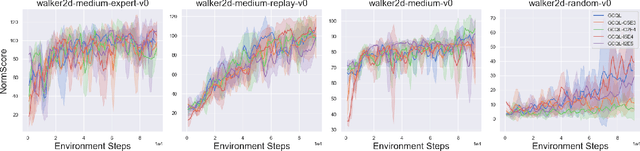
Conventional reinforcement learning (RL) needs an environment to collect fresh data, which is impractical when online interactions are costly. Offline RL provides an alternative solution by directly learning from the previously collected dataset. However, it will yield unsatisfactory performance if the quality of the offline datasets is poor. In this paper, we consider an offline-to-online setting where the agent is first learned from the offline dataset and then trained online, and propose a framework called Adaptive Policy Learning for effectively taking advantage of offline and online data. Specifically, we explicitly consider the difference between the online and offline data and apply an adaptive update scheme accordingly, that is, a pessimistic update strategy for the offline dataset and an optimistic/greedy update scheme for the online dataset. Such a simple and effective method provides a way to mix the offline and online RL and achieve the best of both worlds. We further provide two detailed algorithms for implementing the framework through embedding value or policy-based RL algorithms into it. Finally, we conduct extensive experiments on popular continuous control tasks, and results show that our algorithm can learn the expert policy with high sample efficiency even when the quality of offline dataset is poor, e.g., random dataset.
Prompting for Multimodal Hateful Meme Classification
Feb 08, 2023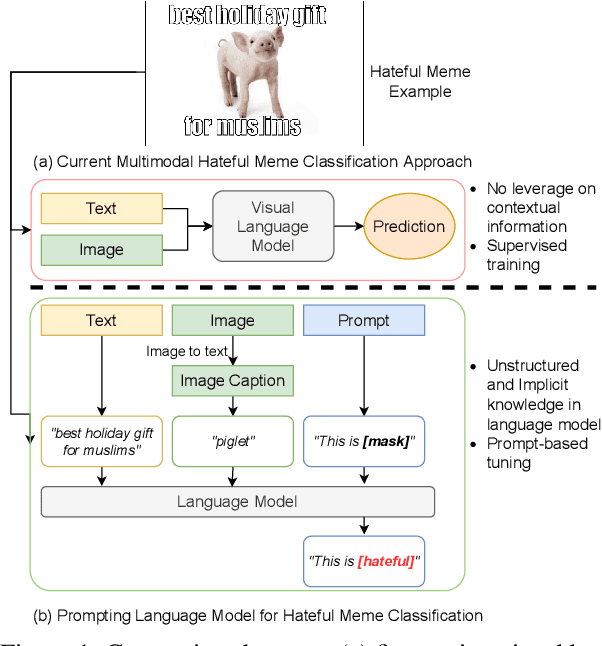
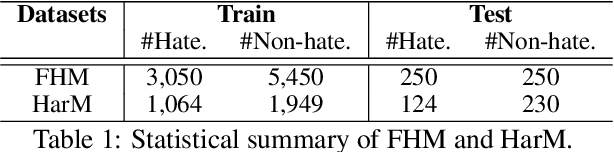

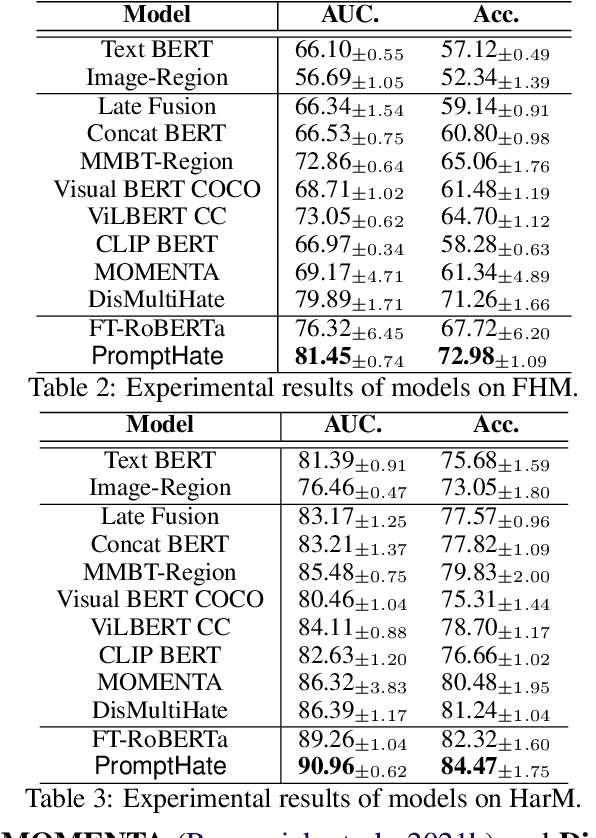
Hateful meme classification is a challenging multimodal task that requires complex reasoning and contextual background knowledge. Ideally, we could leverage an explicit external knowledge base to supplement contextual and cultural information in hateful memes. However, there is no known explicit external knowledge base that could provide such hate speech contextual information. To address this gap, we propose PromptHate, a simple yet effective prompt-based model that prompts pre-trained language models (PLMs) for hateful meme classification. Specifically, we construct simple prompts and provide a few in-context examples to exploit the implicit knowledge in the pre-trained RoBERTa language model for hateful meme classification. We conduct extensive experiments on two publicly available hateful and offensive meme datasets. Our experimental results show that PromptHate is able to achieve a high AUC of 90.96, outperforming state-of-the-art baselines on the hateful meme classification task. We also perform fine-grained analyses and case studies on various prompt settings and demonstrate the effectiveness of the prompts on hateful meme classification.
Voting from Nearest Tasks: Meta-Vote Pruning of Pre-trained Models for Downstream Tasks
Jan 27, 2023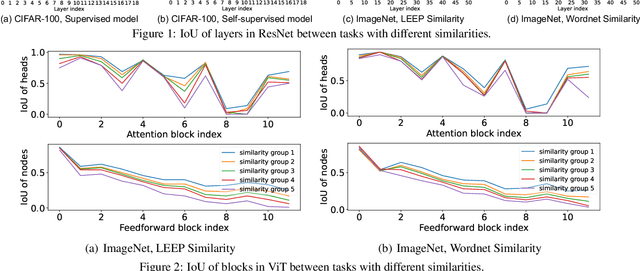
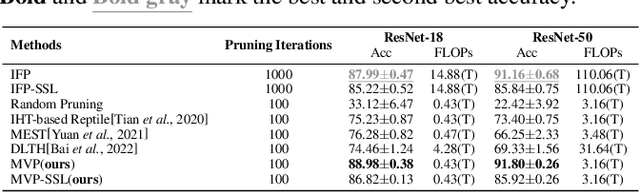
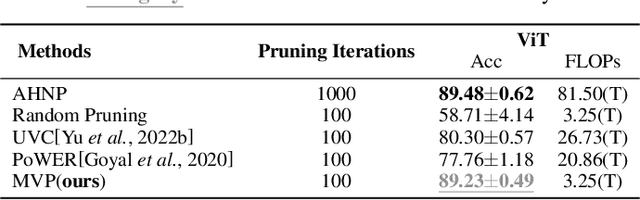
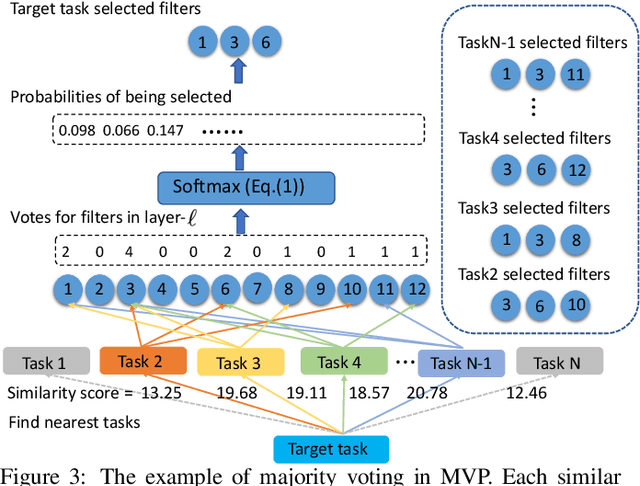
As a few large-scale pre-trained models become the major choices of various applications, new challenges arise for model pruning, e.g., can we avoid pruning the same model from scratch for every downstream task? How to reuse the pruning results of previous tasks to accelerate the pruning for a new task? To address these challenges, we create a small model for a new task from the pruned models of similar tasks. We show that a few fine-tuning steps on this model suffice to produce a promising pruned-model for the new task. We study this ''meta-pruning'' from nearest tasks on two major classes of pre-trained models, convolutional neural network (CNN) and vision transformer (ViT), under a limited budget of pruning iterations. Our study begins by investigating the overlap of pruned models for similar tasks and how the overlap changes over different layers and blocks. Inspired by these discoveries, we develop a simple but effective ''Meta-Vote Pruning (MVP)'' method that significantly reduces the pruning iterations for a new task by initializing a sub-network from the pruned models of its nearest tasks. In experiments, we demonstrate MVP's advantages in accuracy, efficiency, and generalization through extensive empirical studies and comparisons with popular pruning methods over several datasets.
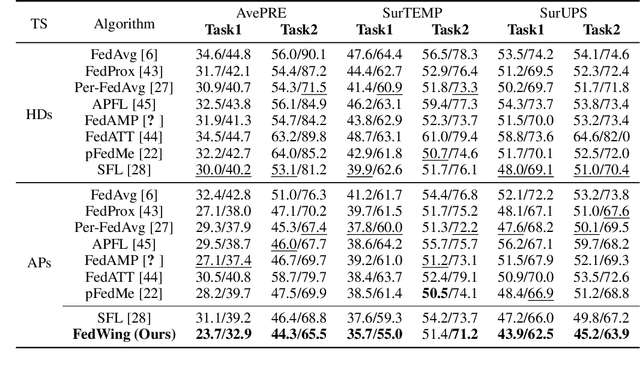
Prompt Federated Learning for Weather Forecasting: Toward Foundation Models on Meteorological Data
Jan 22, 2023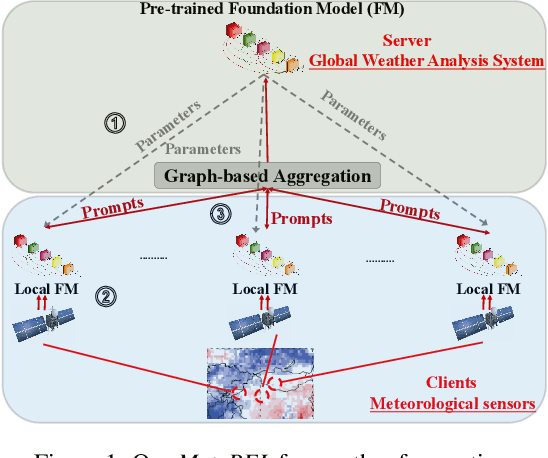
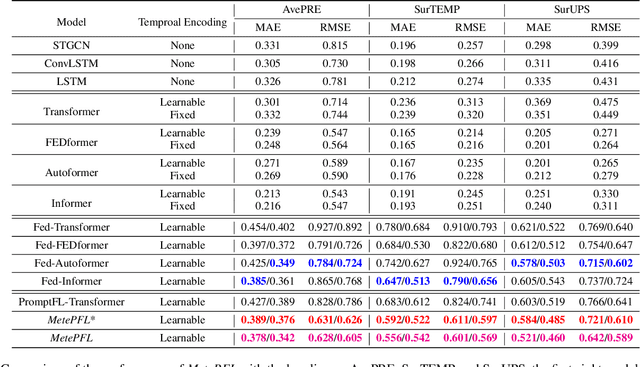
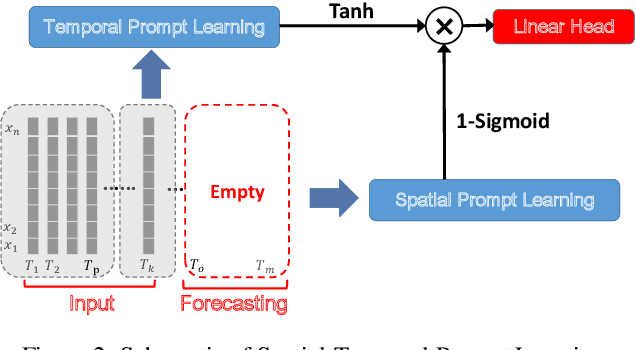
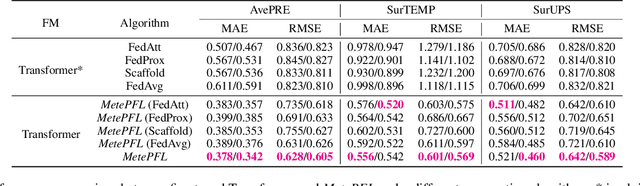
To tackle the global climate challenge, it urgently needs to develop a collaborative platform for comprehensive weather forecasting on large-scale meteorological data. Despite urgency, heterogeneous meteorological sensors across countries and regions, inevitably causing multivariate heterogeneity and data exposure, become the main barrier. This paper develops a foundation model across regions capable of understanding complex meteorological data and providing weather forecasting. To relieve the data exposure concern across regions, a novel federated learning approach has been proposed to collaboratively learn a brand-new spatio-temporal Transformer-based foundation model across participants with heterogeneous meteorological data. Moreover, a novel prompt learning mechanism has been adopted to satisfy low-resourced sensors' communication and computational constraints. The effectiveness of the proposed method has been demonstrated on classical weather forecasting tasks using three meteorological datasets with multivariate time series.
P-Transformer: Towards Better Document-to-Document Neural Machine Translation
Dec 12, 2022
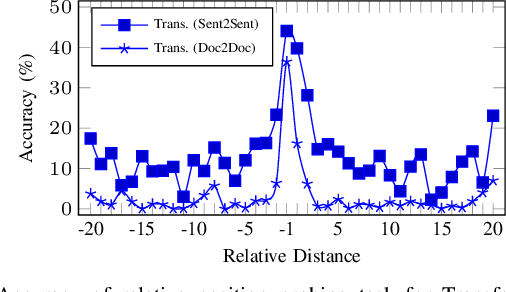
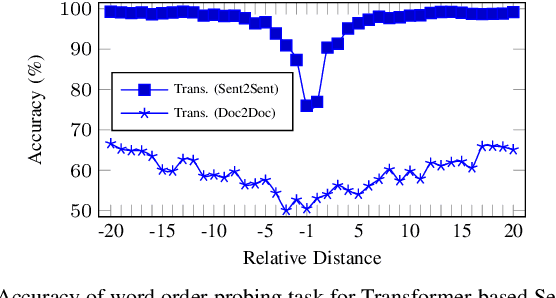
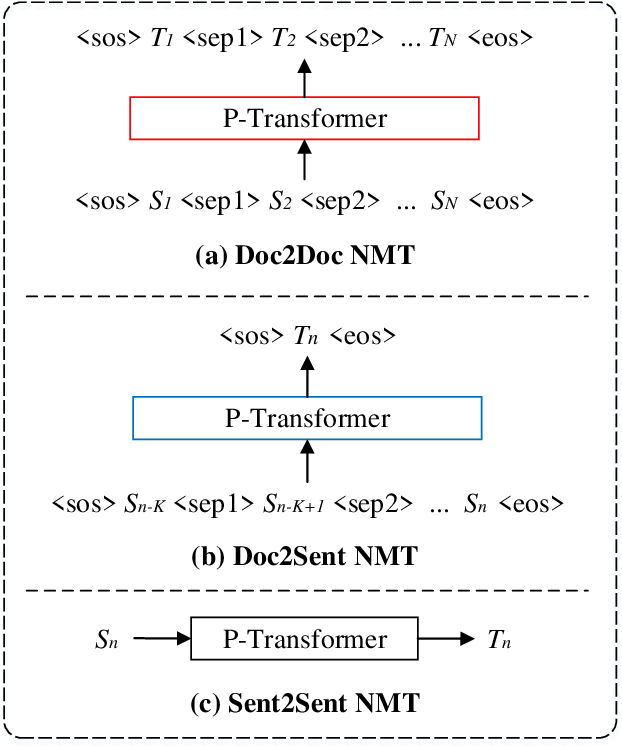
Directly training a document-to-document (Doc2Doc) neural machine translation (NMT) via Transformer from scratch, especially on small datasets usually fails to converge. Our dedicated probing tasks show that 1) both the absolute position and relative position information gets gradually weakened or even vanished once it reaches the upper encoder layers, and 2) the vanishing of absolute position information in encoder output causes the training failure of Doc2Doc NMT. To alleviate this problem, we propose a position-aware Transformer (P-Transformer) to enhance both the absolute and relative position information in both self-attention and cross-attention. Specifically, we integrate absolute positional information, i.e., position embeddings, into the query-key pairs both in self-attention and cross-attention through a simple yet effective addition operation. Moreover, we also integrate relative position encoding in self-attention. The proposed P-Transformer utilizes sinusoidal position encoding and does not require any task-specified position embedding, segment embedding, or attention mechanism. Through the above methods, we build a Doc2Doc NMT model with P-Transformer, which ingests the source document and completely generates the target document in a sequence-to-sequence (seq2seq) way. In addition, P-Transformer can be applied to seq2seq-based document-to-sentence (Doc2Sent) and sentence-to-sentence (Sent2Sent) translation. Extensive experimental results of Doc2Doc NMT show that P-Transformer significantly outperforms strong baselines on widely-used 9 document-level datasets in 7 language pairs, covering small-, middle-, and large-scales, and achieves a new state-of-the-art. Experimentation on discourse phenomena shows that our Doc2Doc NMT models improve the translation quality in both BLEU and discourse coherence. We make our code available on Github.
Federated Learning on Non-IID Graphs via Structural Knowledge Sharing
Nov 23, 2022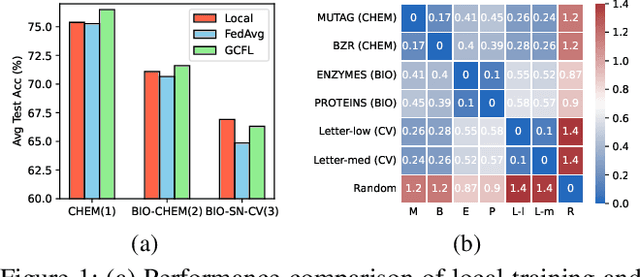
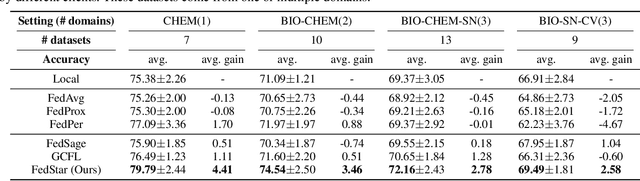
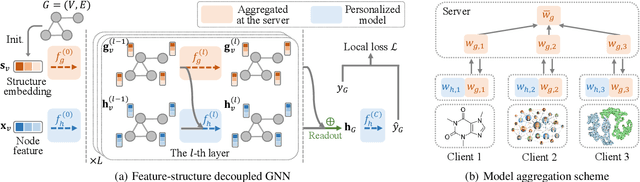
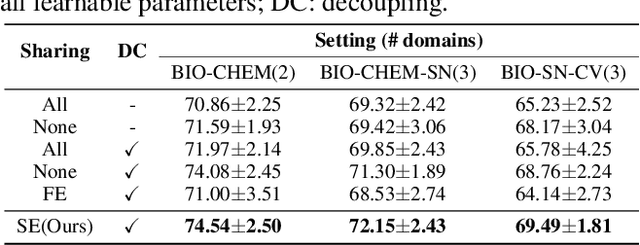
Graph neural networks (GNNs) have shown their superiority in modeling graph data. Owing to the advantages of federated learning, federated graph learning (FGL) enables clients to train strong GNN models in a distributed manner without sharing their private data. A core challenge in federated systems is the non-IID problem, which also widely exists in real-world graph data. For example, local data of clients may come from diverse datasets or even domains, e.g., social networks and molecules, increasing the difficulty for FGL methods to capture commonly shared knowledge and learn a generalized encoder. From real-world graph datasets, we observe that some structural properties are shared by various domains, presenting great potential for sharing structural knowledge in FGL. Inspired by this, we propose FedStar, an FGL framework that extracts and shares the common underlying structure information for inter-graph federated learning tasks. To explicitly extract the structure information rather than encoding them along with the node features, we define structure embeddings and encode them with an independent structure encoder. Then, the structure encoder is shared across clients while the feature-based knowledge is learned in a personalized way, making FedStar capable of capturing more structure-based domain-invariant information and avoiding feature misalignment issues. We perform extensive experiments over both cross-dataset and cross-domain non-IID FGL settings, demonstrating the superiority of FedStar.
CCPrompt: Counterfactual Contrastive Prompt-Tuning for Many-Class Classification
Nov 11, 2022
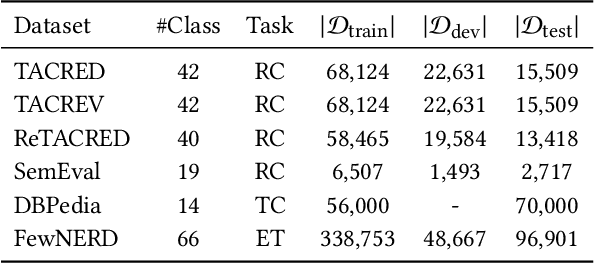
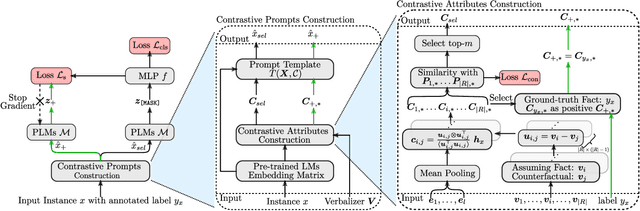
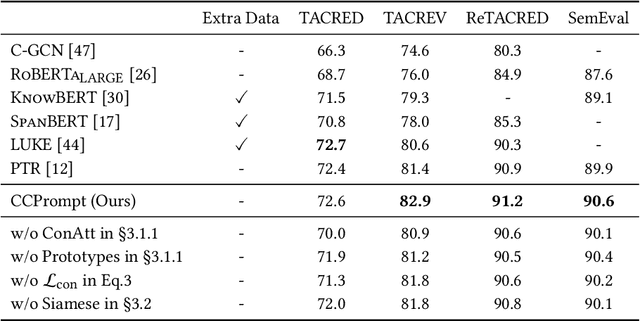
With the success of the prompt-tuning paradigm in Natural Language Processing (NLP), various prompt templates have been proposed to further stimulate specific knowledge for serving downstream tasks, e.g., machine translation, text generation, relation extraction, and so on. Existing prompt templates are mainly shared among all training samples with the information of task description. However, training samples are quite diverse. The sharing task description is unable to stimulate the unique task-related information in each training sample, especially for tasks with the finite-label space. To exploit the unique task-related information, we imitate the human decision process which aims to find the contrastive attributes between the objective factual and their potential counterfactuals. Thus, we propose the \textbf{C}ounterfactual \textbf{C}ontrastive \textbf{Prompt}-Tuning (CCPrompt) approach for many-class classification, e.g., relation classification, topic classification, and entity typing. Compared with simple classification tasks, these tasks have more complex finite-label spaces and are more rigorous for prompts. First of all, we prune the finite label space to construct fact-counterfactual pairs. Then, we exploit the contrastive attributes by projecting training instances onto every fact-counterfactual pair. We further set up global prototypes corresponding with all contrastive attributes for selecting valid contrastive attributes as additional tokens in the prompt template. Finally, a simple Siamese representation learning is employed to enhance the robustness of the model. We conduct experiments on relation classification, topic classification, and entity typing tasks in both fully supervised setting and few-shot setting. The results indicate that our model outperforms former baselines.
ngram-OAXE: Phrase-Based Order-Agnostic Cross Entropy for Non-Autoregressive Machine Translation
Oct 08, 2022
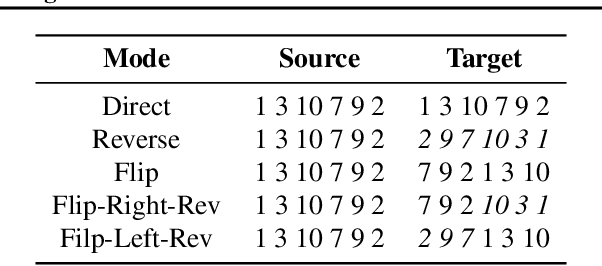
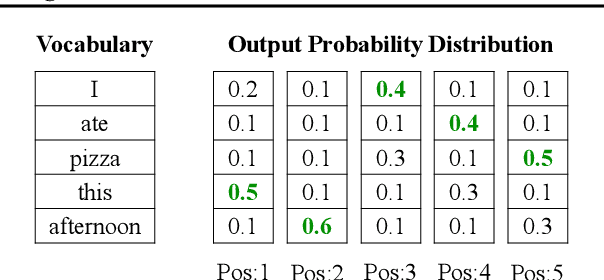
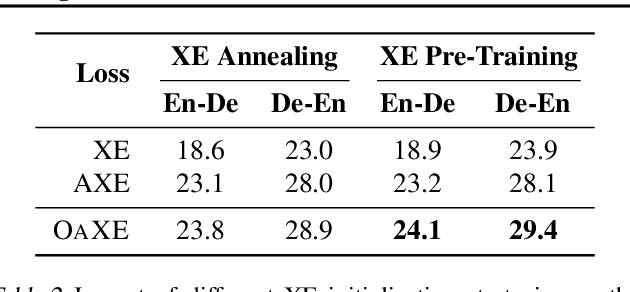
Recently, a new training oaxe loss has proven effective to ameliorate the effect of multimodality for non-autoregressive translation (NAT), which removes the penalty of word order errors in the standard cross-entropy loss. Starting from the intuition that reordering generally occurs between phrases, we extend oaxe by only allowing reordering between ngram phrases and still requiring a strict match of word order within the phrases. Extensive experiments on NAT benchmarks across language pairs and data scales demonstrate the effectiveness and universality of our approach. %Further analyses show that the proposed ngram-oaxe alleviates the multimodality problem with a better modeling of phrase translation. Further analyses show that ngram-oaxe indeed improves the translation of ngram phrases, and produces more fluent translation with a better modeling of sentence structure.