 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-device Federated Learning for Mobile Health Diagnostics: A First Study on COVID-19 Detection
Mar 13, 2023



Federated learning (FL) aided health diagnostic models can incorporate data from a large number of personal edge devices (e.g., mobile phones) while keeping the data local to the originating devices, largely ensuring privacy. However, such a cross-device FL approach for health diagnostics still imposes many challenges due to both local data imbalance (as extreme as local data consists of a single disease class) and global data imbalance (the disease prevalence is generally low in a population). Since the federated server has no access to data distribution information, it is not trivial to solve the imbalance issue towards an unbiased model. In this paper, we propose FedLoss, a novel cross-device FL framework for health diagnostics. Here the federated server averages the models trained on edge devices according to the predictive loss on the local data, rather than using only the number of samples as weights. As the predictive loss better quantifies the data distribution at a device, FedLoss alleviates the impact of data imbalance. Through a real-world dataset on respiratory sound and symptom-based COVID-$19$ detection task, we validate the superiority of FedLoss. It achieves competitive COVID-$19$ detection performance compared to a centralised model with an AUC-ROC of $79\%$. It also outperforms the state-of-the-art FL baselines in sensitivity and convergence speed. Our work not only demonstrates the promise of federated COVID-$19$ detection but also paves the way to a plethora of mobile health model development in a privacy-preserving fashion.
Indoor simultaneous localization and mapping based on fringe projection profilometry
Apr 23, 2022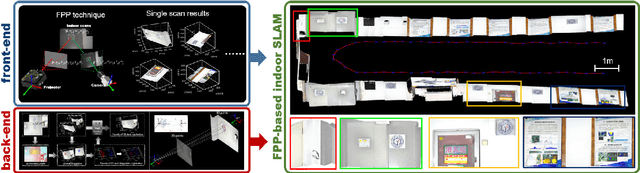
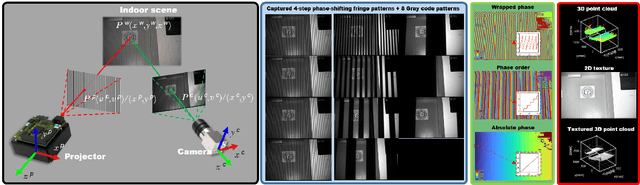
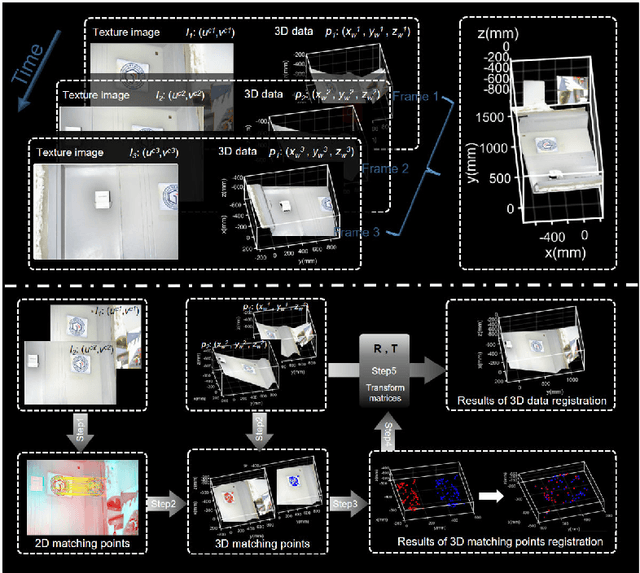
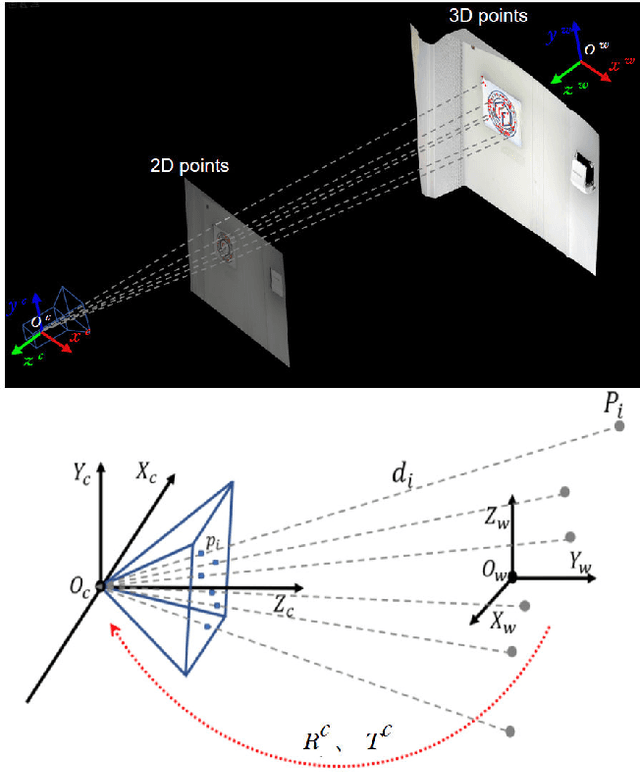
Simultaneous Localization and Mapping (SLAM) plays an important role in outdoor and indoor applications ranging from autonomous driving to indoor robotics. Outdoor SLAM has been widely used with the assistance of LiDAR or GPS. For indoor applications, the LiDAR technique does not satisfy the accuracy requirement and the GPS signals will be lost. An accurate and efficient scene sensing technique is required for indoor SLAM. As the most promising 3D sensing technique, the opportunities for indoor SLAM with fringe projection profilometry (FPP) systems are obvious, but methods to date have not fully leveraged the accuracy and speed of sensing that such systems offer. In this paper, we propose a novel FPP-based indoor SLAM method based on the coordinate transformation relationship of FPP, where the 2D-to-3D descriptor-assisted is used for mapping and localization. The correspondences generated by matching descriptors are used for fast and accurate mapping, and the transform estimation between the 2D and 3D descriptors is used to localize the sensor. The provided experimental results demonstrate that the proposed indoor SLAM can achieve the localization and mapping accuracy around one millimeter.
A Summary of the ComParE COVID-19 Challenges
Feb 17, 2022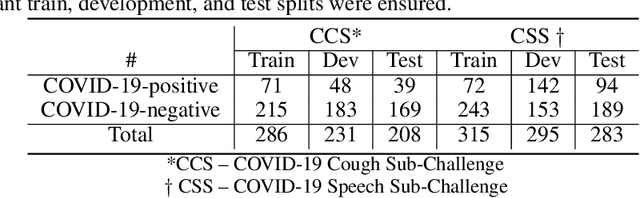
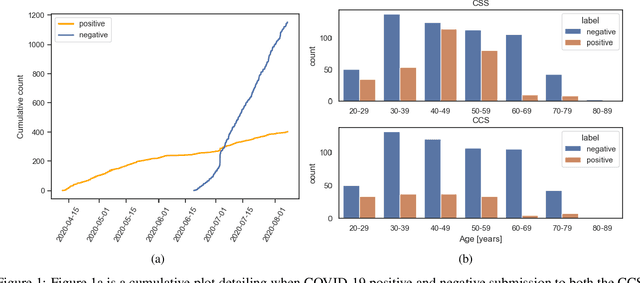
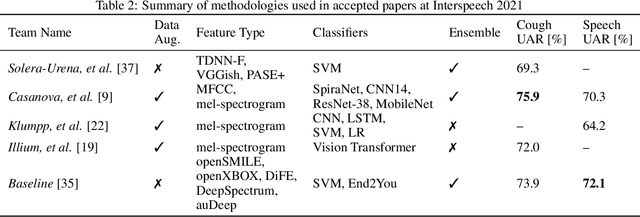
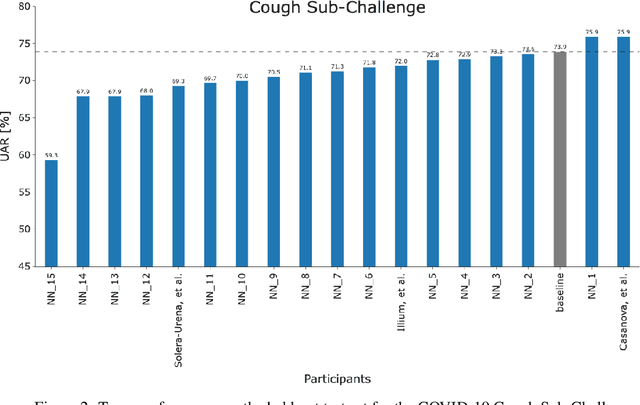
The COVID-19 pandemic has caused massive humanitarian and economic damage. Teams of scientists from a broad range of disciplines have searched for methods to help governments and communities combat the disease. One avenue from the machine learning field which has been explored is the prospect of a digital mass test which can detect COVID-19 from infected individuals' respiratory sounds. We present a summary of the results from the INTERSPEECH 2021 Computational Paralinguistics Challenges: COVID-19 Cough, (CCS) and COVID-19 Speech, (CSS).
Benchmarking Uncertainty Quantification on Biosignal Classification Tasks under Dataset Shift
Jan 25, 2022
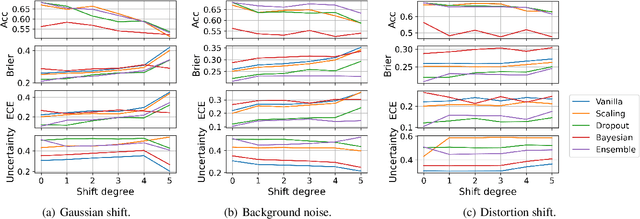
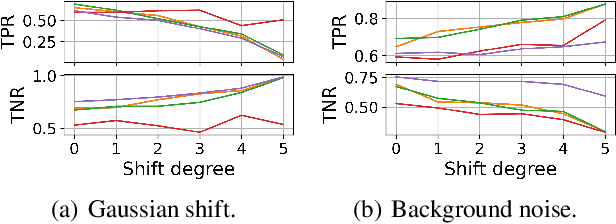
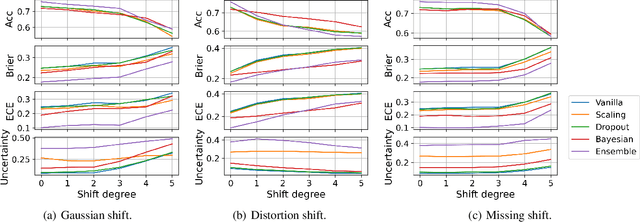
A biosignal is a signal that can be continuously measured from human bodies, such as respiratory sounds, heart activity (ECG), brain waves (EEG), etc, based on which, machine learning models have been developed with very promising performance for automatic disease detection and health status monitoring. However, dataset shift, i.e., data distribution of inference varies from the distribution of the training, is not uncommon for real biosignal-based applications. To improve the robustness, probabilistic models with uncertainty quantification are adapted to capture how reliable a prediction is. Yet, assessing the quality of the estimated uncertainty remains a challenge. In this work, we propose a framework to evaluate the capability of the estimated uncertainty in capturing different types of biosignal dataset shifts with various degrees. In particular, we use three classification tasks based on respiratory sounds and electrocardiography signals to benchmark five representative uncertainty quantification methods. Extensive experiments show that, although Ensemble and Bayesian models could provide relatively better uncertainty estimations under dataset shifts, all tested models fail to meet the promise in trustworthy prediction and model calibration. Our work paves the way for a comprehensive evaluation for any newly developed biosignal classifiers.
COVID-19 Disease Progression Prediction via Audio Signals: A Longitudinal Study
Jan 04, 2022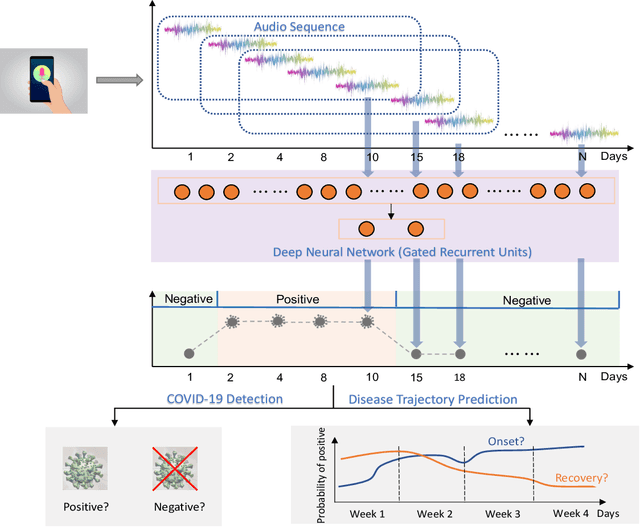
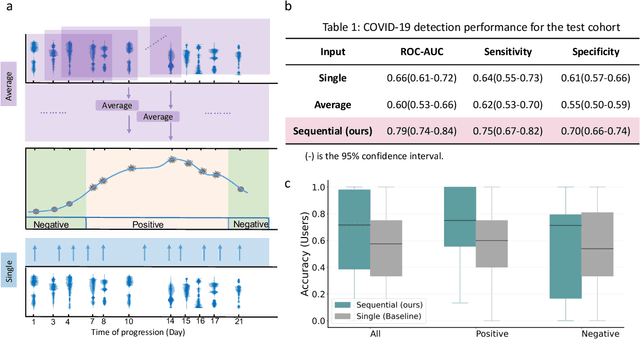
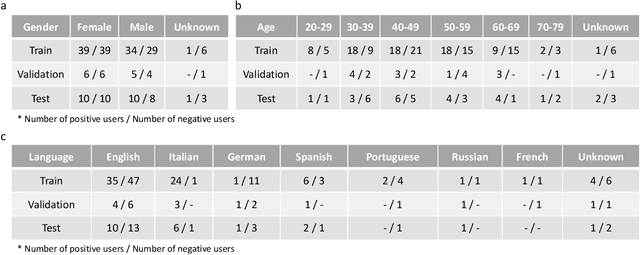
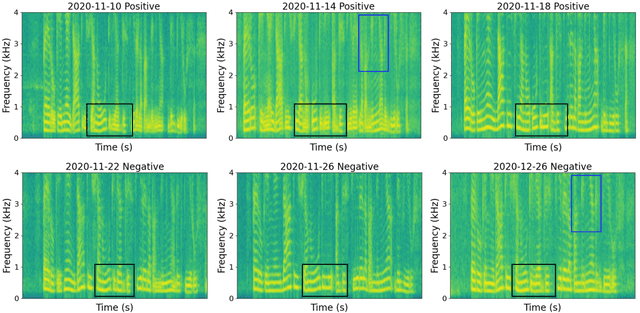
Recent work has shown the potential of the use of audio data in screening for COVID-19. However, very little exploration has been done of monitoring disease progression, especially recovery in COVID-19 through audio. Tracking disease progression characteristics and patterns of recovery could lead to tremendous insights and more timely treatment or treatment adjustment, as well as better resources management in health care systems. The primary objective of this study is to explore the potential of longitudinal audio dynamics for COVID-19 monitoring using sequential deep learning techniques, focusing on prediction of disease progression and, especially, recovery trend prediction. We analysed crowdsourced respiratory audio data from 212 individuals over 5 days to 385 days, alongside their self-reported COVID-19 test results. We first explore the benefits of capturing longitudinal dynamics of audio biomarkers for COVID-19 detection. The strong performance, yielding an AUC-ROC of 0.79, sensitivity of 0.75 and specificity of 0.70, supports the effectiveness of the approach compared to methods that do not leverage longitudinal dynamics. We further examine the predicted disease progression trajectory, which displays high consistency with the longitudinal test results with a correlation of 0.76 in the test cohort, and 0.86 in a subset of the test cohort with 12 participants who report disease recovery. Our findings suggest that monitoring COVID-19 progression via longitudinal audio data has enormous potential in the tracking of individuals' disease progression and recovery.
A Reinforcement Learning-based Adaptive Control Model for Future Street Planning, An Algorithm and A Case Study
Dec 10, 2021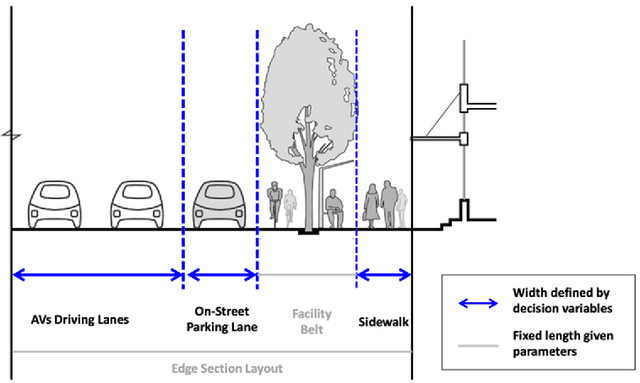
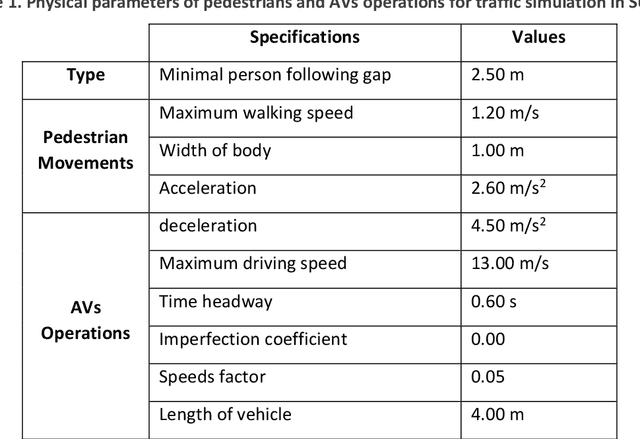
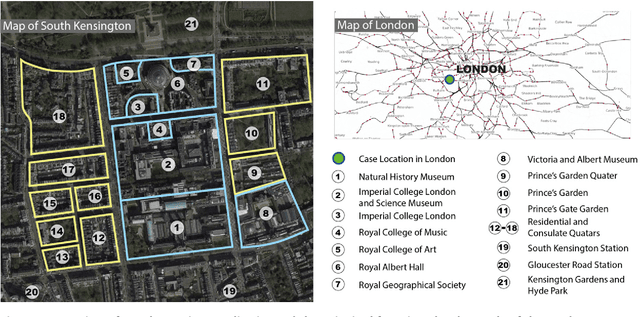
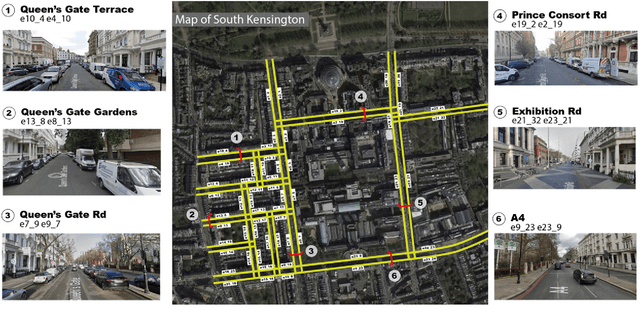
With the emerging technologies in Intelligent Transportation System (ITS), the adaptive operation of road space is likely to be realised within decades. An intelligent street can learn and improve its decision-making on the right-of-way (ROW) for road users, liberating more active pedestrian space while maintaining traffic safety and efficiency. However, there is a lack of effective controlling techniques for these adaptive street infrastructures. To fill this gap in existing studies, we formulate this control problem as a Markov Game and develop a solution based on the multi-agent Deep Deterministic Policy Gradient (MADDPG) algorithm. The proposed model can dynamically assign ROW for sidewalks, autonomous vehicles (AVs) driving lanes and on-street parking areas in real-time. Integrated with the SUMO traffic simulator, this model was evaluated using the road network of the South Kensington District against three cases of divergent traffic conditions: pedestrian flow rates, AVs traffic flow rates and parking demands. Results reveal that our model can achieve an average reduction of 3.87% and 6.26% in street space assigned for on-street parking and vehicular operations. Combined with space gained by limiting the number of driving lanes, the average proportion of sidewalks to total widths of streets can significantly increase by 10.13%.
End to end hyperspectral imaging system with coded compression imaging process
Sep 06, 2021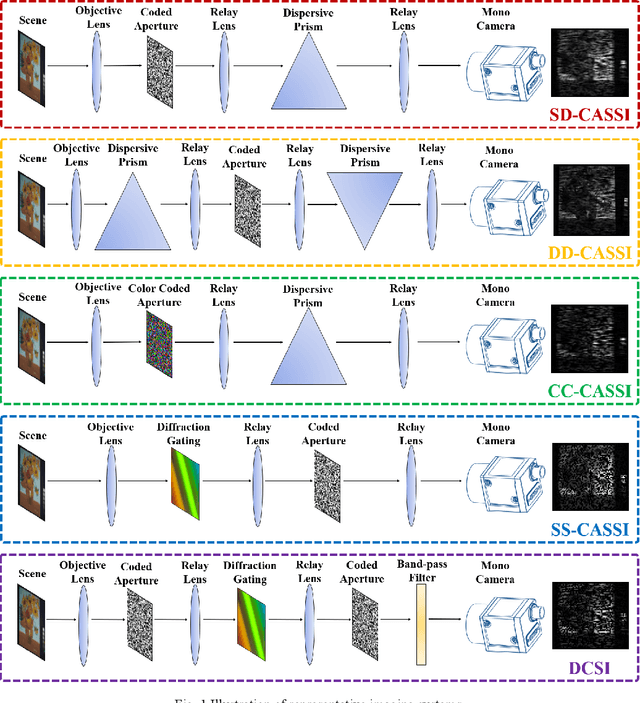
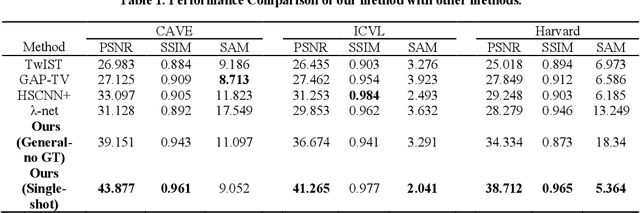
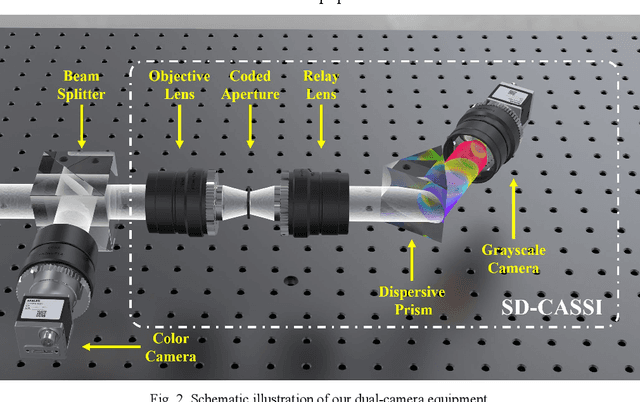

Hyperspectral images (HSIs) can provide rich spatial and spectral information with extensive application prospects. Recently, several methods using convolutional neural networks (CNNs) to reconstruct HSIs have been developed. However, most deep learning methods fit a brute-force mapping relationship between the compressive and standard HSIs. Thus, the learned mapping would be invalid when the observation data deviate from the training data. To recover the three-dimensional HSIs from two-dimensional compressive images, we present dual-camera equipment with a physics-informed self-supervising CNN method based on a coded aperture snapshot spectral imaging system. Our method effectively exploits the spatial-spectral relativization from the coded spectral information and forms a self-supervising system based on the camera quantum effect model. The experimental results show that our method can be adapted to a wide imaging environment with good performance. In addition, compared with most of the network-based methods, our system does not require a dedicated dataset for pre-training. Therefore, it has greater scenario adaptability and better generalization ability. Meanwhile, our system can be constantly fine-tuned and self-improved in real-life scenarios.
Segmentation-free Heart Pathology Detection Using Deep Learning
Aug 09, 2021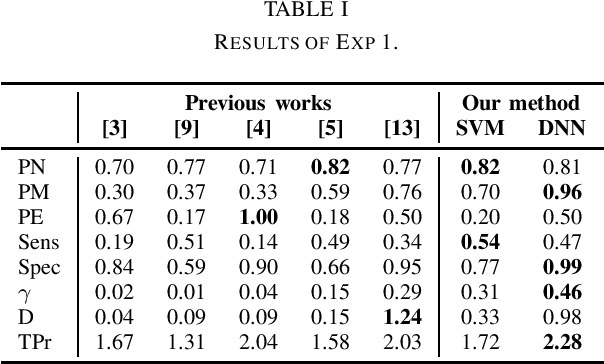
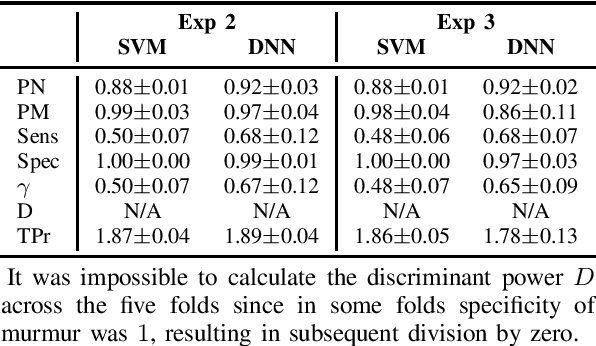
Cardiovascular (CV) diseases are the leading cause of death in the world, and auscultation is typically an essential part of a cardiovascular examination. The ability to diagnose a patient based on their heart sounds is a rather difficult skill to master. Thus, many approaches for automated heart auscultation have been explored. However, most of the previously proposed methods involve a segmentation step, the performance of which drops significantly for high pulse rates or noisy signals. In this work, we propose a novel segmentation-free heart sound classification method. Specifically, we apply discrete wavelet transform to denoise the signal, followed by feature extraction and feature reduction. Then, Support Vector Machines and Deep Neural Networks are utilised for classification. On the PASCAL heart sound dataset our approach showed superior performance compared to others, achieving 81% and 96% precision on normal and murmur classes, respectively. In addition, for the first time, the data were further explored under a user-independent setting, where the proposed method achieved 92% and 86% precision on normal and murmur, demonstrating the potential of enabling automatic murmur detection for practical use.
Sounds of COVID-19: exploring realistic performance of audio-based digital testing
Jun 29, 2021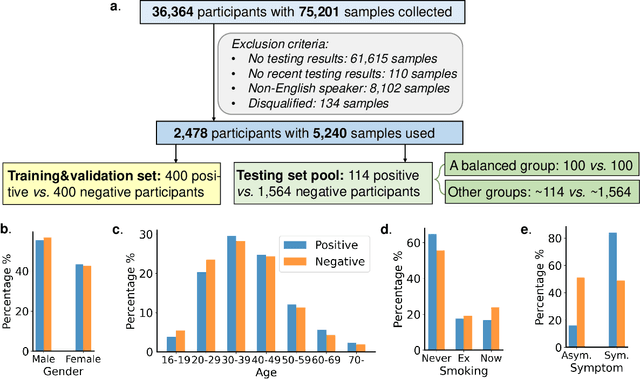
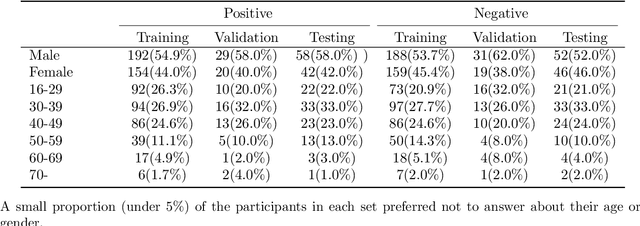
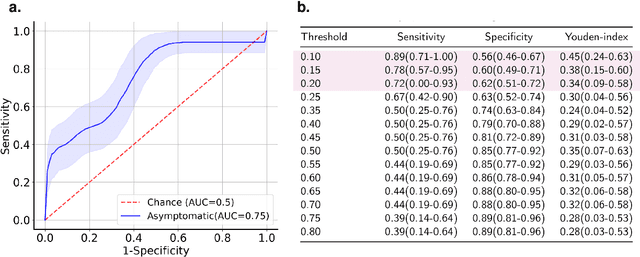
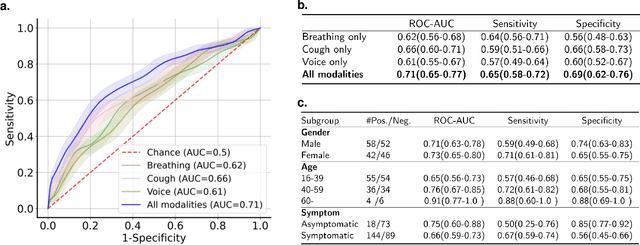
Researchers have been battling with the question of how we can identify Coronavirus disease (COVID-19) cases efficiently, affordably and at scale. Recent work has shown how audio based approaches, which collect respiratory audio data (cough, breathing and voice) can be used for testing, however there is a lack of exploration of how biases and methodological decisions impact these tools' performance in practice. In this paper, we explore the realistic performance of audio-based digital testing of COVID-19. To investigate this, we collected a large crowdsourced respiratory audio dataset through a mobile app, alongside recent COVID-19 test result and symptoms intended as a ground truth. Within the collected dataset, we selected 5,240 samples from 2,478 participants and split them into different participant-independent sets for model development and validation. Among these, we controlled for potential confounding factors (such as demographics and language). The unbiased model takes features extracted from breathing, coughs, and voice signals as predictors and yields an AUC-ROC of 0.71 (95\% CI: 0.65$-$0.77). We further explore different unbalanced distributions to show how biases and participant splits affect performance. Finally, we discuss how the realistic model presented could be integrated in clinical practice to realize continuous, ubiquitous, sustainable and affordable testing at population scale.
Fitbeat: COVID-19 Estimation based on Wristband Heart Rate
Apr 19, 2021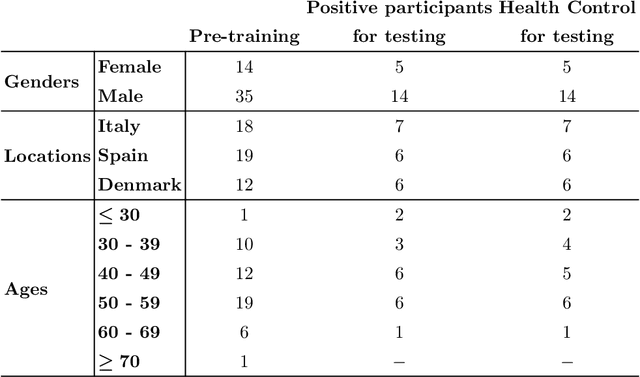

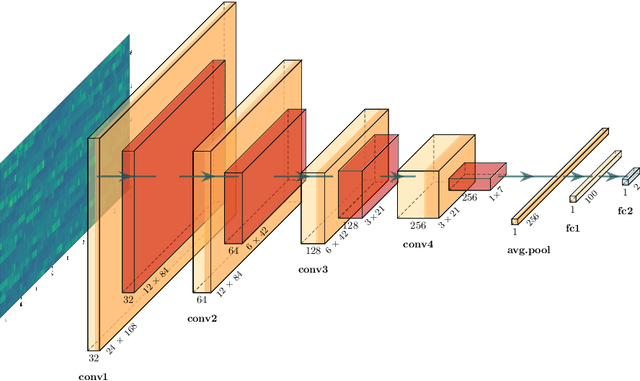
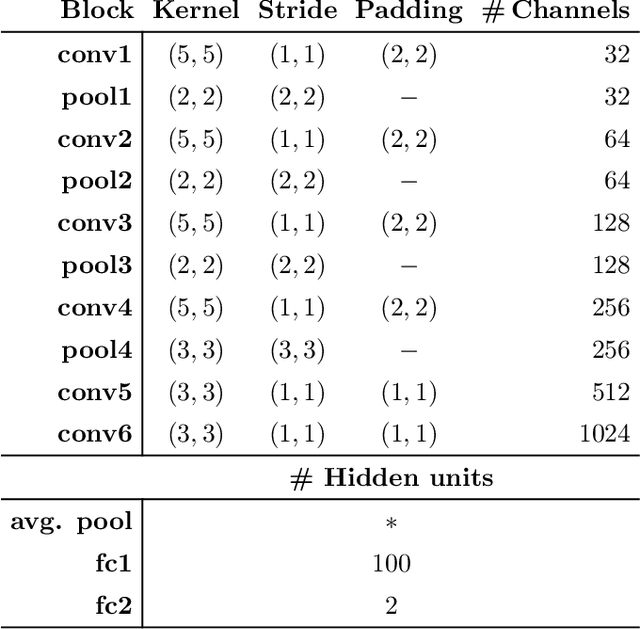
This study investigates the potential of deep learning methods to identify individuals with suspected COVID-19 infection using remotely collected heart-rate data. The study utilises data from the ongoing EU IMI RADAR-CNS research project that is investigating the feasibility of wearable devices and smart phones to monitor individuals with multiple sclerosis (MS), depression or epilepsy. Aspart of the project protocol, heart-rate data was collected from participants using a Fitbit wristband. The presence of COVID-19 in the cohort in this work was either confirmed through a positive swab test, or inferred through the self-reporting of a combination of symptoms including fever, respiratory symptoms, loss of smell or taste, tiredness and gastrointestinal symptoms. Experimental results indicate that our proposed contrastive convolutional auto-encoder (contrastive CAE), i. e., a combined architecture of an auto-encoder and contrastive loss, outperforms a conventional convolutional neural network (CNN), as well as a convolutional auto-encoder (CAE) without using contrastive loss. Our final contrastive CAE achieves 95.3% unweighted average recall, 86.4% precision, anF1 measure of 88.2%, a sensitivity of 100% and a specificity of 90.6% on a testset of 19 participants with MS who reported symptoms of COVID-19. Each of these participants was paired with a participant with MS with no COVID-19 symptoms.