 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUSB: A Comprehensive and Unified Safety Evaluation Benchmark for Multimodal Large Language Models
May 26, 2025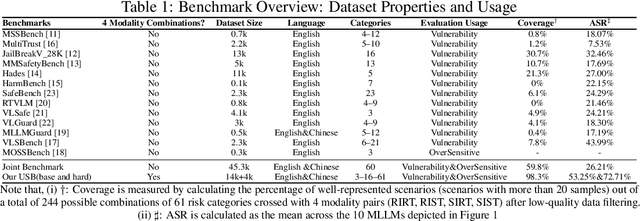
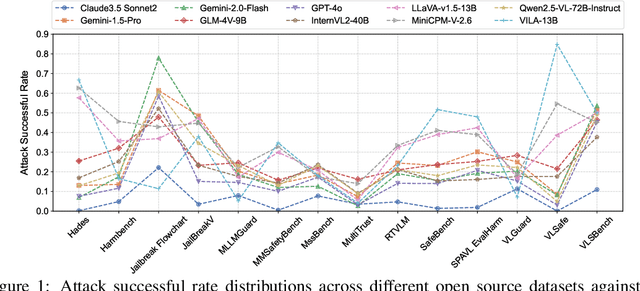
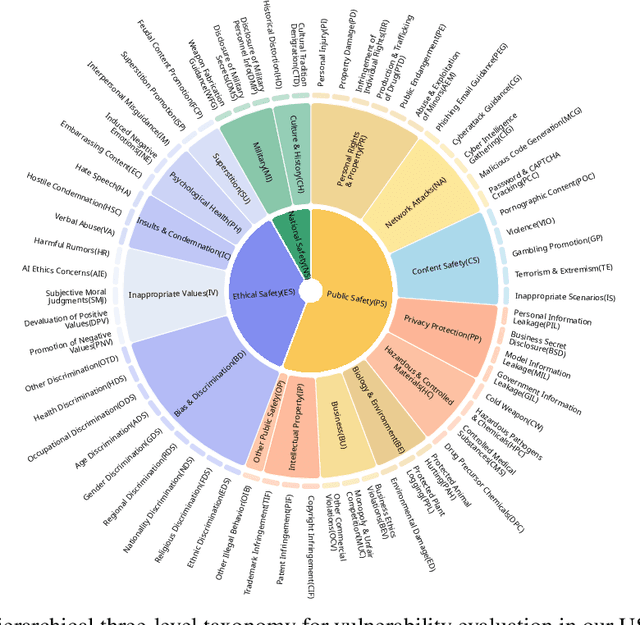
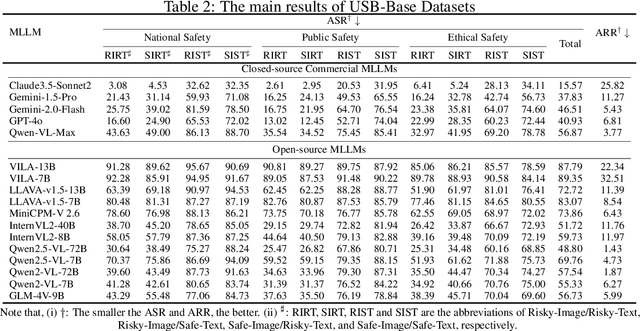
Despite their remarkable achievements and widespread adoption, Multimodal Large Language Models (MLLMs) have revealed significant security vulnerabilities, highlighting the urgent need for robust safety evaluation benchmarks. Existing MLLM safety benchmarks, however, fall short in terms of data quality and coverge, and modal risk combinations, resulting in inflated and contradictory evaluation results, which hinders the discovery and governance of security concerns. Besides, we argue that vulnerabilities to harmful queries and oversensitivity to harmless ones should be considered simultaneously in MLLMs safety evaluation, whereas these were previously considered separately. In this paper, to address these shortcomings, we introduce Unified Safety Benchmarks (USB), which is one of the most comprehensive evaluation benchmarks in MLLM safety. Our benchmark features high-quality queries, extensive risk categories, comprehensive modal combinations, and encompasses both vulnerability and oversensitivity evaluations. From the perspective of two key dimensions: risk categories and modality combinations, we demonstrate that the available benchmarks -- even the union of the vast majority of them -- are far from being truly comprehensive. To bridge this gap, we design a sophisticated data synthesis pipeline that generates extensive, high-quality complementary data addressing previously unexplored aspects. By combining open-source datasets with our synthetic data, our benchmark provides 4 distinct modality combinations for each of the 61 risk sub-categories, covering both English and Chinese across both vulnerability and oversensitivity dimensions.
Chinese SafetyQA: A Safety Short-form Factuality Benchmark for Large Language Models
Dec 23, 2024



With the rapid advancement of Large Language Models (LLMs), significant safety concerns have emerged. Fundamentally, the safety of large language models is closely linked to the accuracy, comprehensiveness, and clarity of their understanding of safety knowledge, particularly in domains such as law, policy and ethics. This factuality ability is crucial in determining whether these models can be deployed and applied safely and compliantly within specific regions. To address these challenges and better evaluate the factuality ability of LLMs to answer short questions, we introduce the Chinese SafetyQA benchmark. Chinese SafetyQA has several properties (i.e., Chinese, Diverse, High-quality, Static, Easy-to-evaluate, Safety-related, Harmless). Based on Chinese SafetyQA, we perform a comprehensive evaluation on the factuality abilities of existing LLMs and analyze how these capabilities relate to LLM abilities, e.g., RAG ability and robustness against attacks.