 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLet 2D Diffusion Model Know 3D-Consistency for Robust Text-to-3D Generation
Mar 16, 2023



Text-to-3D generation has shown rapid progress in recent days with the advent of score distillation, a methodology of using pretrained text-to-2D diffusion models to optimize neural radiance field (NeRF) in the zero-shot setting. However, the lack of 3D awareness in the 2D diffusion models destabilizes score distillation-based methods from reconstructing a plausible 3D scene. To address this issue, we propose 3DFuse, a novel framework that incorporates 3D awareness into pretrained 2D diffusion models, enhancing the robustness and 3D consistency of score distillation-based methods. We realize this by first constructing a coarse 3D structure of a given text prompt and then utilizing projected, view-specific depth map as a condition for the diffusion model. Additionally, we introduce a training strategy that enables the 2D diffusion model learns to handle the errors and sparsity within the coarse 3D structure for robust generation, as well as a method for ensuring semantic consistency throughout all viewpoints of the scene. Our framework surpasses the limitations of prior arts, and has significant implications for 3D consistent generation of 2D diffusion models.
Unified Chest X-ray and Radiology Report Generation Model with Multi-view Chest X-rays
Mar 01, 2023



Generated synthetic data in medical research can substitute privacy and security-sensitive data with a large-scale curated dataset, reducing data collection and annotation costs. As part of this effort, we propose UniXGen, a unified chest X-ray and report generation model, with the following contributions. First, we design a unified model for bidirectional chest X-ray and report generation by adopting a vector quantization method to discretize chest X-rays into discrete visual tokens and formulating both tasks as sequence generation tasks. Second, we introduce several special tokens to generate chest X-rays with specific views that can be useful when the desired views are unavailable. Furthermore, UniXGen can flexibly take various inputs from single to multiple views to take advantage of the additional findings available in other X-ray views. We adopt an efficient transformer for computational and memory efficiency to handle the long-range input sequence of multi-view chest X-rays with high resolution and long paragraph reports. In extensive experiments, we show that our unified model has a synergistic effect on both generation tasks, as opposed to training only the task-specific models. We also find that view-specific special tokens can distinguish between different views and properly generate specific views even if they do not exist in the dataset, and utilizing multi-view chest X-rays can faithfully capture the abnormal findings in the additional X-rays. The source code is publicly available at: https://github.com/ttumyche/UniXGen.
3D-aware Blending with Generative NeRFs
Feb 13, 2023Image blending aims to combine multiple images seamlessly. It remains challenging for existing 2D-based methods, especially when input images are misaligned due to differences in 3D camera poses and object shapes. To tackle these issues, we propose a 3D-aware blending method using generative Neural Radiance Fields (NeRF), including two key components: 3D-aware alignment and 3D-aware blending. For 3D-aware alignment, we first estimate the camera pose of the reference image with respect to generative NeRFs and then perform 3D local alignment for each part. To further leverage 3D information of the generative NeRF, we propose 3D-aware blending that directly blends images on the NeRF's latent representation space, rather than raw pixel space. Collectively, our method outperforms existing 2D baselines, as validated by extensive quantitative and qualitative evaluations with FFHQ and AFHQ-Cat.
Robust Camera Pose Refinement for Multi-Resolution Hash Encoding
Feb 03, 2023



Multi-resolution hash encoding has recently been proposed to reduce the computational cost of neural renderings, such as NeRF. This method requires accurate camera poses for the neural renderings of given scenes. However, contrary to previous methods jointly optimizing camera poses and 3D scenes, the naive gradient-based camera pose refinement method using multi-resolution hash encoding severely deteriorates performance. We propose a joint optimization algorithm to calibrate the camera pose and learn a geometric representation using efficient multi-resolution hash encoding. Showing that the oscillating gradient flows of hash encoding interfere with the registration of camera poses, our method addresses the issue by utilizing smooth interpolation weighting to stabilize the gradient oscillation for the ray samplings across hash grids. Moreover, the curriculum training procedure helps to learn the level-wise hash encoding, further increasing the pose refinement. Experiments on the novel-view synthesis datasets validate that our learning frameworks achieve state-of-the-art performance and rapid convergence of neural rendering, even when initial camera poses are unknown.
Semi-Parametric Video-Grounded Text Generation
Jan 27, 2023



Efficient video-language modeling should consider the computational cost because of a large, sometimes intractable, number of video frames. Parametric approaches such as the attention mechanism may not be ideal since its computational cost quadratically increases as the video length increases. Rather, previous studies have relied on offline feature extraction or frame sampling to represent the video efficiently, focusing on cross-modal modeling in short video clips. In this paper, we propose a semi-parametric video-grounded text generation model, SeViT, a novel perspective on scalable video-language modeling toward long untrimmed videos. Treating a video as an external data store, SeViT includes a non-parametric frame retriever to select a few query-relevant frames from the data store for a given query and a parametric generator to effectively aggregate the frames with the query via late fusion methods. Experimental results demonstrate our method has a significant advantage in longer videos and causal video understanding. Moreover, our model achieves the new state of the art on four video-language datasets, iVQA (+4.8), Next-QA (+6.9), and Activitynet-QA (+4.8) in accuracy, and MSRVTT-Caption (+3.6) in CIDEr.
SelecMix: Debiased Learning by Contradicting-pair Sampling
Nov 04, 2022Neural networks trained with ERM (empirical risk minimization) sometimes learn unintended decision rules, in particular when their training data is biased, i.e., when training labels are strongly correlated with undesirable features. To prevent a network from learning such features, recent methods augment training data such that examples displaying spurious correlations (i.e., bias-aligned examples) become a minority, whereas the other, bias-conflicting examples become prevalent. However, these approaches are sometimes difficult to train and scale to real-world data because they rely on generative models or disentangled representations. We propose an alternative based on mixup, a popular augmentation that creates convex combinations of training examples. Our method, coined SelecMix, applies mixup to contradicting pairs of examples, defined as showing either (i) the same label but dissimilar biased features, or (ii) different labels but similar biased features. Identifying such pairs requires comparing examples with respect to unknown biased features. For this, we utilize an auxiliary contrastive model with the popular heuristic that biased features are learned preferentially during training. Experiments on standard benchmarks demonstrate the effectiveness of the method, in particular when label noise complicates the identification of bias-conflicting examples.
Modal-specific Pseudo Query Generation for Video Corpus Moment Retrieval
Oct 23, 2022Video corpus moment retrieval (VCMR) is the task to retrieve the most relevant video moment from a large video corpus using a natural language query. For narrative videos, e.g., dramas or movies, the holistic understanding of temporal dynamics and multimodal reasoning is crucial. Previous works have shown promising results; however, they relied on the expensive query annotations for VCMR, i.e., the corresponding moment intervals. To overcome this problem, we propose a self-supervised learning framework: Modal-specific Pseudo Query Generation Network (MPGN). First, MPGN selects candidate temporal moments via subtitle-based moment sampling. Then, it generates pseudo queries exploiting both visual and textual information from the selected temporal moments. Through the multimodal information in the pseudo queries, we show that MPGN successfully learns to localize the video corpus moment without any explicit annotation. We validate the effectiveness of MPGN on the TVR dataset, showing competitive results compared with both supervised models and unsupervised setting models.
AlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Oct 08, 2022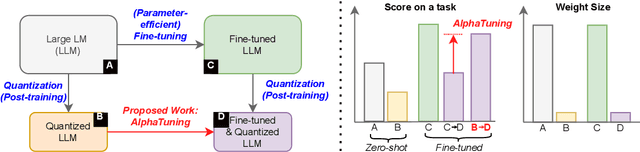

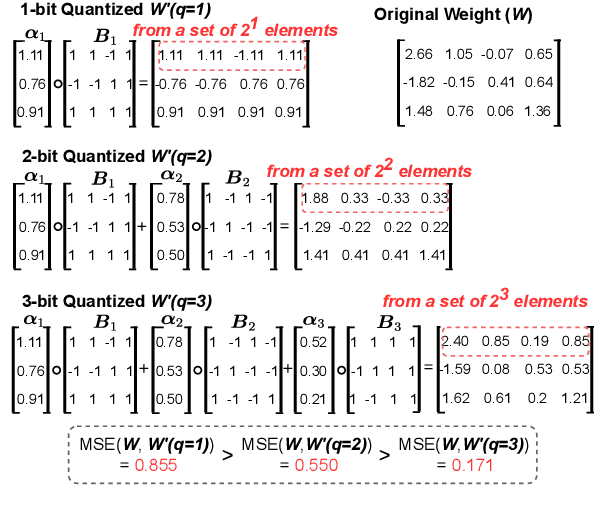
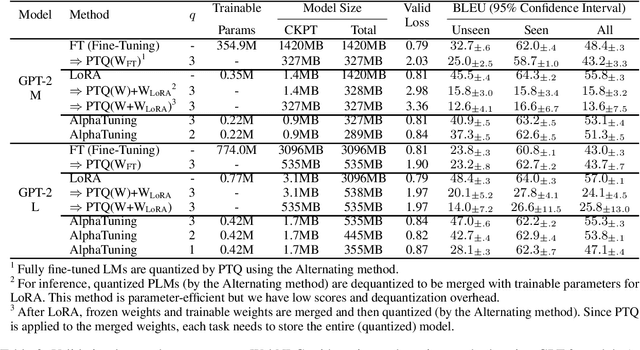
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.
Mutual Information Divergence: A Unified Metric for Multimodal Generative Models
May 25, 2022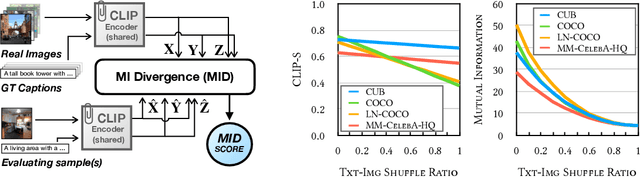
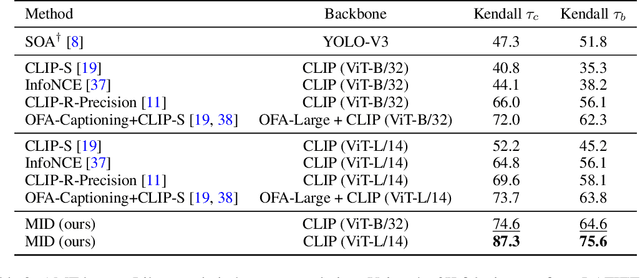
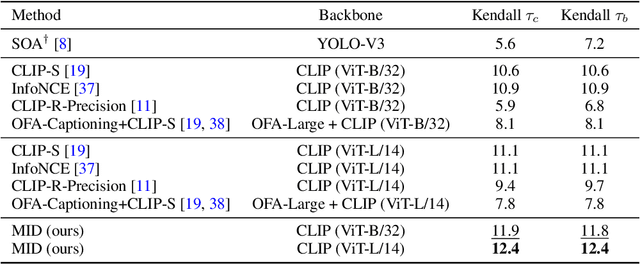
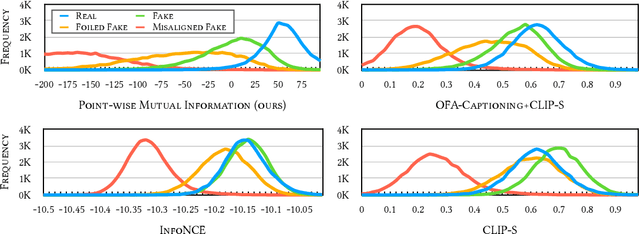
Text-to-image generation and image captioning are recently emerged as a new experimental paradigm to assess machine intelligence. They predict continuous quantity accompanied by their sampling techniques in the generation, making evaluation complicated and intractable to get marginal distributions. Based on a recent trend that multimodal generative evaluations exploit a vison-and-language pre-trained model, we propose the negative Gaussian cross-mutual information using the CLIP features as a unified metric, coined by Mutual Information Divergence (MID). To validate, we extensively compare it with competing metrics using carefully-generated or human-annotated judgments in text-to-image generation and image captioning tasks. The proposed MID significantly outperforms the competitive methods by having consistency across benchmarks, sample parsimony, and robustness toward the exploited CLIP model. We look forward to seeing the underrepresented implications of the Gaussian cross-mutual information in multimodal representation learning and the future works based on this novel proposition.
The Dialog Must Go On: Improving Visual Dialog via Generative Self-Training
May 25, 2022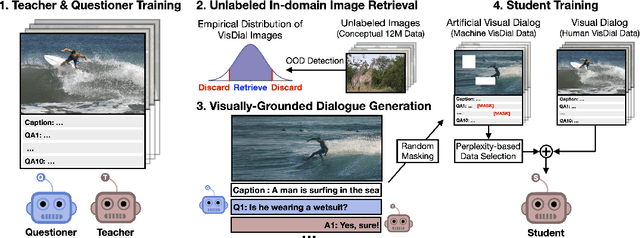
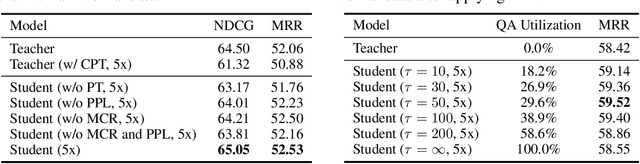


Visual dialog (VisDial) is a task of answering a sequence of questions grounded in an image, using the dialog history as context. Prior work has trained the dialog agents solely on VisDial data via supervised learning or leveraged pre-training on related vision-and-language datasets. This paper presents a semi-supervised learning approach for visually-grounded dialog, called Generative Self-Training (GST), to leverage unlabeled images on the Web. Specifically, GST first retrieves in-domain images through out-of-distribution detection and generates synthetic dialogs regarding the images via multimodal conditional text generation. GST then trains a dialog agent on the synthetic and the original VisDial data. As a result, GST scales the amount of training data up to an order of magnitude that of VisDial (1.2M to 12.9M QA data). For robust training of the generated dialogs, we also propose perplexity-based data selection and multimodal consistency regularization. Evaluation on VisDial v1.0 and v0.9 datasets shows that GST achieves new state-of-the-art results on both datasets. We further observe strong performance gains in the low-data regime (up to 9.35 absolute points on NDCG).