 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSFD: Dual Shot Face Detector
Oct 24, 2018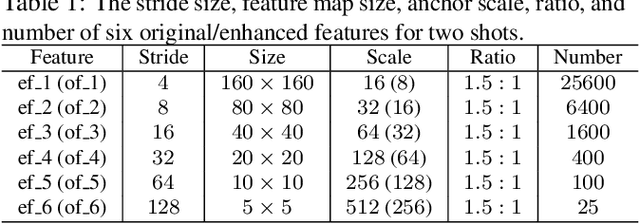
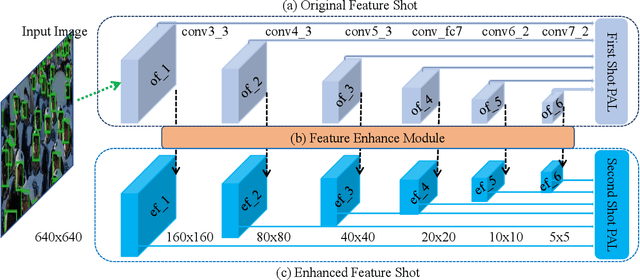

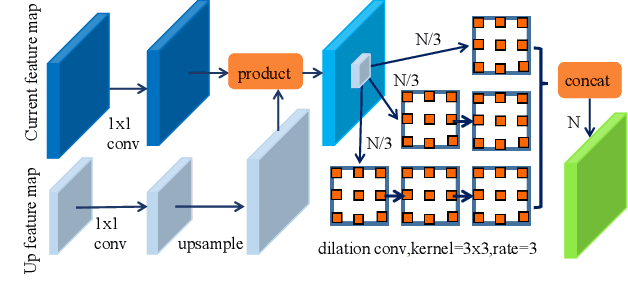
Recently, Convolutional Neural Network (CNN) has achieved great success in face detection. However, it remains a challenging problem for the current face detection methods owing to high degree of variability in scale, pose, occlusion, expression, appearance and illumination. In this paper, we propose a novel face detection network named Dual Shot face Detector(DSFD), which inherits the architecture of SSD and introduces a Feature Enhance Module (FEM) for transferring the original feature maps to extend the single shot detector to dual shot detector. Specially, Progressive Anchor Loss (PAL) computed by using two set of anchors is adopted to effectively facilitate the features. Additionally, we propose an Improved Anchor Matching (IAM) method by integrating novel data augmentation techniques and anchor design strategy in our DSFD to provide better initialization for the regressor. Extensive experiments on popular benchmarks: WIDER FACE (easy: $0.966$, medium: $0.957$, hard: $0.904$) and FDDB ( discontinuous: $0.991$, continuous: $0.862$) demonstrate the superiority of DSFD over the state-of-the-art face detectors (e.g., PyramidBox and SRN). Code will be made available upon publication.