 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling AI ASICs for Zero Knowledge Proof
Apr 20, 2026Zero-knowledge proof (ZKP) provers remain costly because multi-scalar multiplication (MSM) and number-theoretic transforms (NTTs) dominate runtime as they need significant computation. AI ASICs such as TPUs provide massive matrix throughput and SotA energy efficiency. We present MORPH, the first framework that reformulates ZKP kernels to match AI-ASIC execution. We introduce Big-T complexity, a hardware-aware complexity model that exposes heterogeneous bottlenecks and layout-transformation costs ignored by Big-O. Guided by this analysis, (1) at arithmetic level, MORPH develops an MXU-centric extended-RNS lazy reduction that converts high-precision modular arithmetic into dense low-precision GEMMs, eliminating all carry chains, and (2) at dataflow level, MORPH constructs a unified-sharding layout-stationary TPU Pippenger MSM and optimized 3/5-step NTT that avoid on-TPU shuffles to minimize costly memory reorganization. Implemented in JAX, MORPH enables TPUv6e8 to achieve up-to 10x higher throughput on NTT and comparable throughput on MSM than GZKP. Our code: https://github.com/EfficientPPML/MORPH.
Privatar: Scalable Privacy-preserving Multi-user VR via Secure Offloading
Apr 19, 2026Multi-user virtual reality enables immersive interaction. However, rendering avatars for numerous participants on each headset incurs prohibitive computational overhead, limiting scalability. We introduce a framework, Privatar, to offload avatar reconstruction from headset to untrusted devices within the same local network while safeguarding attacks against adversaries capable of intercepting offloaded data. Privatar's key insight is that domain-specific knowledge of avatar reconstruction enables provably private offloading at minimal cost. (1) System level. We observe avatar reconstruction is frequency-domain decomposable via BDCT with negligible quality drop, and propose Horizontal Partitioning (HP) to keep high-energy frequency components on-device and offloads only low-energy components. HP offloads local computation while reducing information leakage to low-energy subsets only. (2) Privacy level. For individually offloaded, multi-dimensional signals without aggregation, worst-case local Differential Privacy requires prohibitive noise, ruining utility. We observe users' expression statistical distribution are slowly changing over time and trackable online, and hence propose Distribution-Aware Minimal Perturbation. DAMP minimizes noise based on each user's expression distribution to significantly reduce its effects on utility, retaining formal privacy guarantee. Combined, HP provides empirical privacy against expression identification attacks. DAMP further augments it to offer a formal guarantee against arbitrary adversaries. On a Meta Quest Pro, Privatar supports 2.37x more concurrent users at 6.5% higher reconstruction loss and 9% energy overhead, providing a better throughout-loss Pareto frontier over quantization, sparsity and local construction baselines. Privatar provides both provable privacy guarantee and stays robust against both empirical and NN-based attacks.
Leveraging ASIC AI Chips for Homomorphic Encryption
Jan 13, 2025
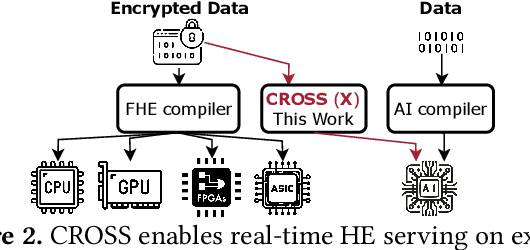
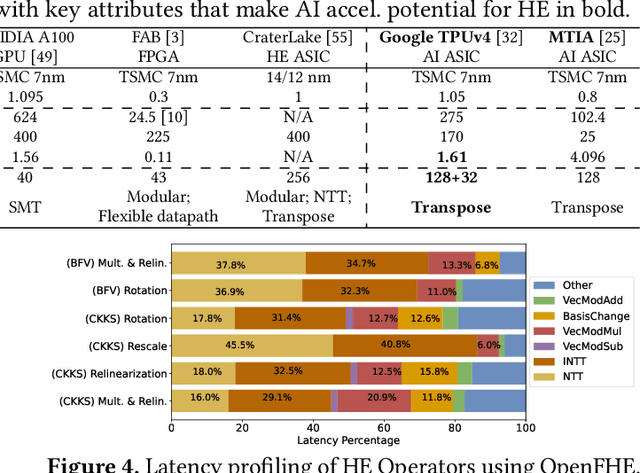
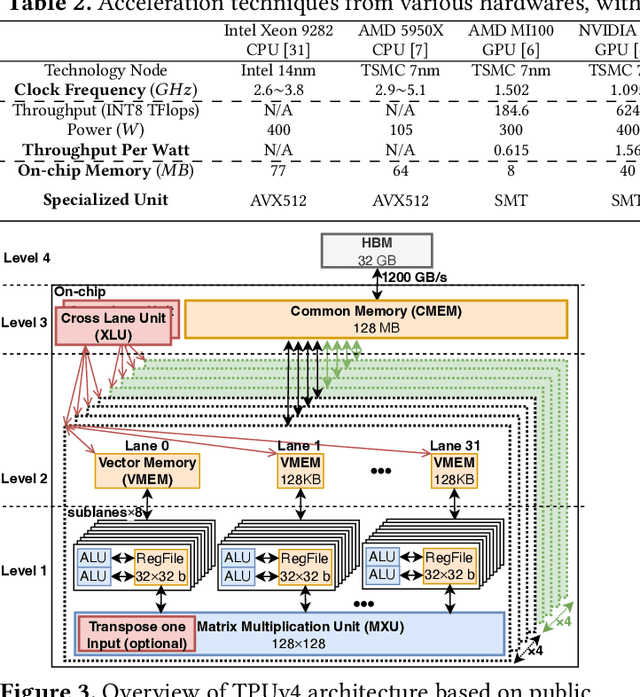
Cloud-based services are making the outsourcing of sensitive client data increasingly common. Although homomorphic encryption (HE) offers strong privacy guarantee, it requires substantially more resources than computing on plaintext, often leading to unacceptably large latencies in getting the results. HE accelerators have emerged to mitigate this latency issue, but with the high cost of ASICs. In this paper we show that HE primitives can be converted to AI operators and accelerated on existing ASIC AI accelerators, like TPUs, which are already widely deployed in the cloud. Adapting such accelerators for HE requires (1) supporting modular multiplication, (2) high-precision arithmetic in software, and (3) efficient mapping on matrix engines. We introduce the CROSS compiler (1) to adopt Barrett reduction to provide modular reduction support using multiplier and adder, (2) Basis Aligned Transformation (BAT) to convert high-precision multiplication as low-precision matrix-vector multiplication, (3) Matrix Aligned Transformation (MAT) to covert vectorized modular operation with reduction into matrix multiplication that can be efficiently processed on 2D spatial matrix engine. Our evaluation of CROSS on a Google TPUv4 demonstrates significant performance improvements, with up to 161x and 5x speedup compared to the previous work on many-core CPUs and V100. The kernel-level codes are open-sourced at https://github.com/google/jaxite.git.
Real-time Digital RF Emulation -- II: A Near Memory Custom Accelerator
Jun 13, 2024



A near memory hardware accelerator, based on a novel direct path computational model, for real-time emulation of radio frequency systems is demonstrated. Our evaluation of hardware performance uses both application-specific integrated circuits (ASIC) and field programmable gate arrays (FPGA) methodologies: 1). The ASIC testchip implementation, using TSMC 28nm CMOS, leverages distributed autonomous control to extract concurrency in compute as well as low latency. It achieves a $518$ MHz per channel bandwidth in a prototype $4$-node system. The maximum emulation range supported in this paradigm is $9.5$ km with $0.24$ $\mu$s of per-sample emulation latency. 2). The FPGA-based implementation, evaluated on a Xilinx ZCU104 board, demonstrates a $9$-node test case (two Transmitters, one Receiver, and $6$ passive reflectors) with an emulation range of $1.13$ km to $27.3$ km at $215$ MHz bandwidth.
Subgraph Stationary Hardware-Software Inference Co-Design
Jun 21, 2023



A growing number of applications depend on Machine Learning (ML) functionality and benefits from both higher quality ML predictions and better timeliness (latency) at the same time. A growing body of research in computer architecture, ML, and systems software literature focuses on reaching better latency-accuracy tradeoffs for ML models. Efforts include compression, quantization, pruning, early-exit models, mixed DNN precision, as well as ML inference accelerator designs that minimize latency and energy, while preserving delivered accuracy. All of them, however, yield improvements for a single static point in the latency-accuracy tradeoff space. We make a case for applications that operate in dynamically changing deployment scenarios, where no single static point is optimal. We draw on a recently proposed weight-shared SuperNet mechanism to enable serving a stream of queries that uses (activates) different SubNets within this weight-shared construct. This creates an opportunity to exploit the inherent temporal locality with our proposed SubGraph Stationary (SGS) optimization. We take a hardware-software co-design approach with a real implementation of SGS in SushiAccel and the implementation of a software scheduler SushiSched controlling which SubNets to serve and what to cache in real-time. Combined, they are vertically integrated into SUSHI-an inference serving stack. For the stream of queries, SUSHI yields up to 25% improvement in latency, 0.98% increase in served accuracy. SUSHI can achieve up to 78.7% off-chip energy savings.