 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePACZero: PAC-Private Fine-Tuning of Language Models via Sign Quantization
May 07, 2026We introduce PACZero, a family of PAC-private zeroth-order mechanisms for fine-tuning large language models that delivers usable utility at $I(S^*; Y_{1:T})=0$. This privacy regime bounds the membership-inference attack (MIA) posterior success rate at the prior, an MIA-resistance level the DP framework matches only at $\varepsilon=0$ and infinite noise. All DP-ZO comparisons below are matched at the MIA posterior level. The key insight is that PAC Privacy charges mutual information only when the release depends on which candidate subset is the secret. Sign-quantizing subset-aggregated zeroth-order gradients creates frequent unanimity, steps at which every candidate subset agrees on the update direction; at these steps the released sign costs zero conditional mutual information. We propose two variants that span the privacy-utility trade-off: PACZero-MI (budgeted MI via exact calibration on the binary release) and PACZero-ZPL ($I=0$ via a uniform coin flip on disagreement steps). We evaluate on SST-2 and SQuAD with OPT-1.3B and OPT-6.7B in both LoRA and full-parameter tracks. On SST-2 OPT-1.3B full fine-tuning at $I=0$, PACZero-ZPL reaches ${88.99\pm0.91}$, within $2.1$pp of the non-private MeZO baseline ($91.1$ FT). No prior method produces usable utility in the high-privacy regime $\varepsilon<1$, and PACZero-ZPL obtains competitive SST-2 accuracy and nontrivial SQuAD F1 across OPT-1.3B and OPT-6.7B at $I=0$.
Enabling AI ASICs for Zero Knowledge Proof
Apr 20, 2026Zero-knowledge proof (ZKP) provers remain costly because multi-scalar multiplication (MSM) and number-theoretic transforms (NTTs) dominate runtime as they need significant computation. AI ASICs such as TPUs provide massive matrix throughput and SotA energy efficiency. We present MORPH, the first framework that reformulates ZKP kernels to match AI-ASIC execution. We introduce Big-T complexity, a hardware-aware complexity model that exposes heterogeneous bottlenecks and layout-transformation costs ignored by Big-O. Guided by this analysis, (1) at arithmetic level, MORPH develops an MXU-centric extended-RNS lazy reduction that converts high-precision modular arithmetic into dense low-precision GEMMs, eliminating all carry chains, and (2) at dataflow level, MORPH constructs a unified-sharding layout-stationary TPU Pippenger MSM and optimized 3/5-step NTT that avoid on-TPU shuffles to minimize costly memory reorganization. Implemented in JAX, MORPH enables TPUv6e8 to achieve up-to 10x higher throughput on NTT and comparable throughput on MSM than GZKP. Our code: https://github.com/EfficientPPML/MORPH.
PAC-Private Responses with Adversarial Composition
Jan 20, 2026Modern machine learning models are increasingly deployed behind APIs. This renders standard weight-privatization methods (e.g. DP-SGD) unnecessarily noisy at the cost of utility. While model weights may vary significantly across training datasets, model responses to specific inputs are much lower dimensional and more stable. This motivates enforcing privacy guarantees directly on model outputs. We approach this under PAC privacy, which provides instance-based privacy guarantees for arbitrary black-box functions by controlling mutual information (MI). Importantly, PAC privacy explicitly rewards output stability with reduced noise levels. However, a central challenge remains: response privacy requires composing a large number of adaptively chosen, potentially adversarial queries issued by untrusted users, where existing composition results on PAC privacy are inadequate. We introduce a new algorithm that achieves adversarial composition via adaptive noise calibration and prove that mutual information guarantees accumulate linearly under adaptive and adversarial querying. Experiments across tabular, vision, and NLP tasks show that our method achieves high utility at extremely small per-query privacy budgets. On CIFAR-10, we achieve 87.79% accuracy with a per-step MI budget of $2^{-32}$. This enables serving one million queries while provably bounding membership inference attack (MIA) success rates to 51.08% -- the same guarantee of $(0.04, 10^{-5})$-DP. Furthermore, we show that private responses can be used to label public data to distill a publishable privacy-preserving model; using an ImageNet subset as a public dataset, our model distilled from 210,000 responses achieves 91.86% accuracy on CIFAR-10 with MIA success upper-bounded by 50.49%, which is comparable to $(0.02,10^{-5})$-DP.
Differentially Private Deep Learning with ModelMix
Oct 07, 2022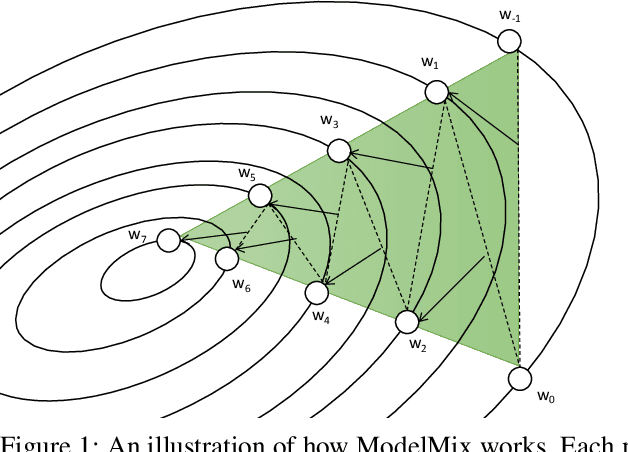
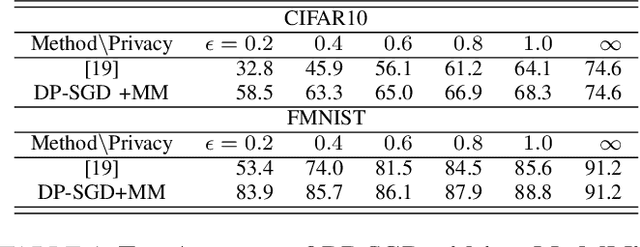
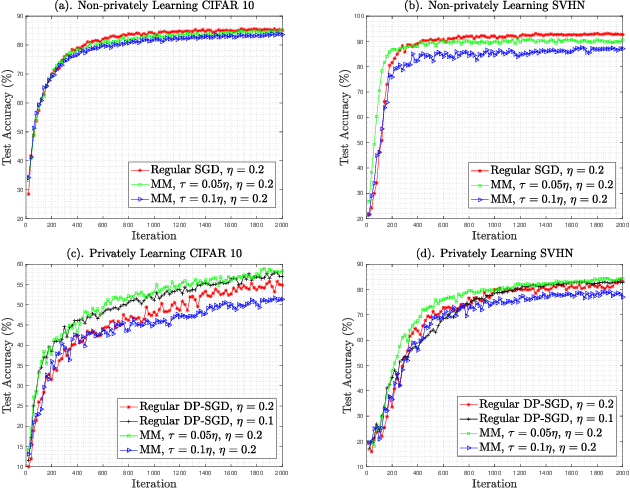
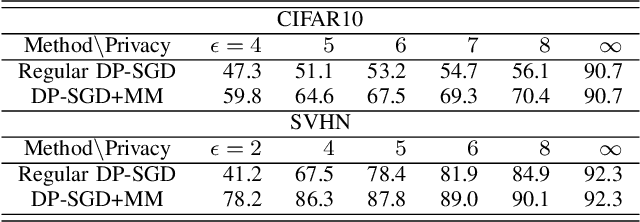
Training large neural networks with meaningful/usable differential privacy security guarantees is a demanding challenge. In this paper, we tackle this problem by revisiting the two key operations in Differentially Private Stochastic Gradient Descent (DP-SGD): 1) iterative perturbation and 2) gradient clipping. We propose a generic optimization framework, called {\em ModelMix}, which performs random aggregation of intermediate model states. It strengthens the composite privacy analysis utilizing the entropy of the training trajectory and improves the $(\epsilon, \delta)$ DP security parameters by an order of magnitude. We provide rigorous analyses for both the utility guarantees and privacy amplification of ModelMix. In particular, we present a formal study on the effect of gradient clipping in DP-SGD, which provides theoretical instruction on how hyper-parameters should be selected. We also introduce a refined gradient clipping method, which can further sharpen the privacy loss in private learning when combined with ModelMix. Thorough experiments with significant privacy/utility improvement are presented to support our theory. We train a Resnet-20 network on CIFAR10 with $70.4\%$ accuracy via ModelMix given $(\epsilon=8, \delta=10^{-5})$ DP-budget, compared to the same performance but with $(\epsilon=145.8,\delta=10^{-5})$ using regular DP-SGD; assisted with additional public low-dimensional gradient embedding, one can further improve the accuracy to $79.1\%$ with $(\epsilon=6.1, \delta=10^{-5})$ DP-budget, compared to the same performance but with $(\epsilon=111.2, \delta=10^{-5})$ without ModelMix.
Var-CNN and DynaFlow: Improved Attacks and Defenses for Website Fingerprinting
Feb 28, 2018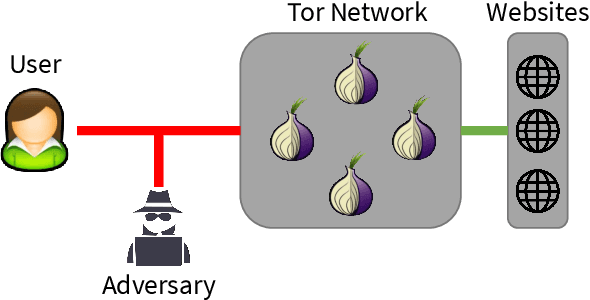

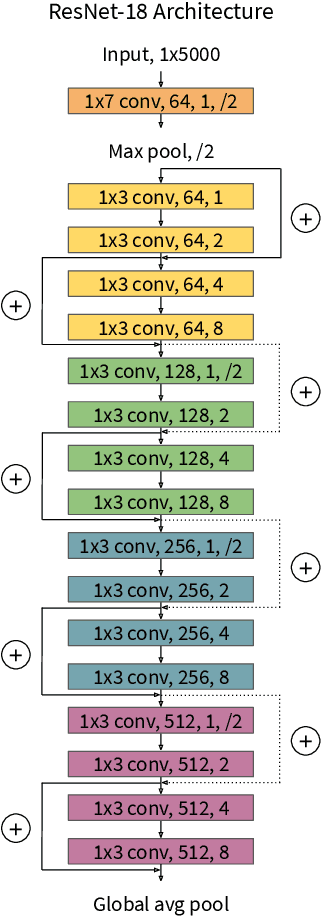
In recent years, there have been many works that use website fingerprinting techniques to enable a local adversary to determine which website a Tor user is visiting. However, most of these works rely on manually extracted features, and thus are fragile: a small change in the protocol or a simple defense often renders these attacks useless. In this work, we leverage deep learning techniques to create a more robust attack that does not require any manually extracted features. Specifically, we propose Var-CNN, an attack that uses model variations on convolutional neural networks with both the packet sequence and packet timing data. In open-world settings, Var-CNN attains higher true positive rate and lower false positive rate than any prior work at 90.9% and 0.3%, respectively. Moreover, these improvements are observed even with low amounts of training data, where deep learning techniques often suffer. Given the severity of our attacks, we also introduce a new countermeasure, DynaFlow, based on dynamically adjusting flows to protect against website fingerprinting attacks. DynaFlow provides a similar level of security as current state-of-the-art and defeats all attacks, including our own, while being over 40% more efficient than existing defenses. Moreover, unlike many prior defenses, DynaFlow can protect dynamically generated websites as well.