 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenClinicalAI: An Open and Dynamic Model for Alzheimer's Disease Diagnosis
Jul 03, 2023



Although Alzheimer's disease (AD) cannot be reversed or cured, timely diagnosis can significantly reduce the burden of treatment and care. Current research on AD diagnosis models usually regards the diagnosis task as a typical classification task with two primary assumptions: 1) All target categories are known a priori; 2) The diagnostic strategy for each patient is consistent, that is, the number and type of model input data for each patient are the same. However, real-world clinical settings are open, with complexity and uncertainty in terms of both subjects and the resources of the medical institutions. This means that diagnostic models may encounter unseen disease categories and need to dynamically develop diagnostic strategies based on the subject's specific circumstances and available medical resources. Thus, the AD diagnosis task is tangled and coupled with the diagnosis strategy formulation. To promote the application of diagnostic systems in real-world clinical settings, we propose OpenClinicalAI for direct AD diagnosis in complex and uncertain clinical settings. This is the first powerful end-to-end model to dynamically formulate diagnostic strategies and provide diagnostic results based on the subject's conditions and available medical resources. OpenClinicalAI combines reciprocally coupled deep multiaction reinforcement learning (DMARL) for diagnostic strategy formulation and multicenter meta-learning (MCML) for open-set recognition. The experimental results show that OpenClinicalAI achieves better performance and fewer clinical examinations than the state-of-the-art model. Our method provides an opportunity to embed the AD diagnostic system into the current health care system to cooperate with clinicians to improve current health care.
OpenAPMax: Abnormal Patterns-based Model for Real-World Alzheimer's Disease Diagnosis
Jul 03, 2023



Alzheimer's disease (AD) cannot be reversed, but early diagnosis will significantly benefit patients' medical treatment and care. In recent works, AD diagnosis has the primary assumption that all categories are known a prior -- a closed-set classification problem, which contrasts with the open-set recognition problem. This assumption hinders the application of the model in natural clinical settings. Although many open-set recognition technologies have been proposed in other fields, they are challenging to use for AD diagnosis directly since 1) AD is a degenerative disease of the nervous system with similar symptoms at each stage, and it is difficult to distinguish from its pre-state, and 2) diversified strategies for AD diagnosis are challenging to model uniformly. In this work, inspired by the concerns of clinicians during diagnosis, we propose an open-set recognition model, OpenAPMax, based on the anomaly pattern to address AD diagnosis in real-world settings. OpenAPMax first obtains the abnormal pattern of each patient relative to each known category through statistics or a literature search, clusters the patients' abnormal pattern, and finally, uses extreme value theory (EVT) to model the distance between each patient's abnormal pattern and the center of their category and modify the classification probability. We evaluate the performance of the proposed method with recent open-set recognition, where we obtain state-of-the-art results.
CMLCompiler: A Unified Compiler for Classical Machine Learning
Feb 01, 2023



Classical machine learning (CML) occupies nearly half of machine learning pipelines in production applications. Unfortunately, it fails to utilize the state-of-the-practice devices fully and performs poorly. Without a unified framework, the hybrid deployments of deep learning (DL) and CML also suffer from severe performance and portability issues. This paper presents the design of a unified compiler, called CMLCompiler, for CML inference. We propose two unified abstractions: operator representations and extended computational graphs. The CMLCompiler framework performs the conversion and graph optimization based on two unified abstractions, then outputs an optimized computational graph to DL compilers or frameworks. We implement CMLCompiler on TVM. The evaluation shows CMLCompiler's portability and superior performance. It achieves up to 4.38x speedup on CPU, 3.31x speedup on GPU, and 5.09x speedup on IoT devices, compared to the state-of-the-art solutions -- scikit-learn, intel sklearn, and hummingbird. Our performance of CML and DL mixed pipelines achieves up to 3.04x speedup compared with cross-framework implementations.
Quality at the Tail
Dec 25, 2022



Practical applications employing deep learning must guarantee inference quality. However, we found that the inference quality of state-of-the-art and state-of-the-practice in practical applications has a long tail distribution. In the real world, many tasks have strict requirements for the quality of deep learning inference, such as safety-critical and mission-critical tasks. The fluctuation of inference quality seriously affects its practical applications, and the quality at the tail may lead to severe consequences. State-of-the-art and state-of-the-practice with outstanding inference quality designed and trained under loose constraints still have poor inference quality under constraints with practical application significance. On the one hand, the neural network models must be deployed on complex systems with limited resources. On the other hand, safety-critical and mission-critical tasks need to meet more metric constraints while ensuring high inference quality. We coin a new term, ``tail quality,'' to characterize this essential requirement and challenge. We also propose a new metric, ``X-Critical-Quality,'' to measure the inference quality under certain constraints. This article reveals factors contributing to the failure of using state-of-the-art and state-of-the-practice algorithms and systems in real scenarios. Therefore, we call for establishing innovative methodologies and tools to tackle this enormous challenge.
ToL: A Tensor of List-Based Unified Computation Model
Dec 21, 2022



Previous computation models either have equivalent abilities in representing all computations but fail to provide primitive operators for programming complex algorithms or lack generalized expression ability to represent newly-added computations. This article presents a unified computation model with generalized expression ability and a concise set of primitive operators for programming high-level algorithms. We propose a unified data abstraction -- Tensor of List, and offer a unified computation model based on Tensor of List, which we call the ToL model (in short, ToL). ToL introduces five atomic computations that can represent any elementary computation by finite composition, ensured with strict formal proof. Based on ToL, we design a pure-functional language -- ToLang. ToLang provides a concise set of primitive operators that can be used to program complex big data and AI algorithms. Our evaluations show ToL has generalized expression ability and a built-in performance indicator, born with a strictly defined computation metric -- elementary operation count (EOPs), consistent with FLOPs within a small error range.
SAIBench: Benchmarking AI for Science
Jun 11, 2022
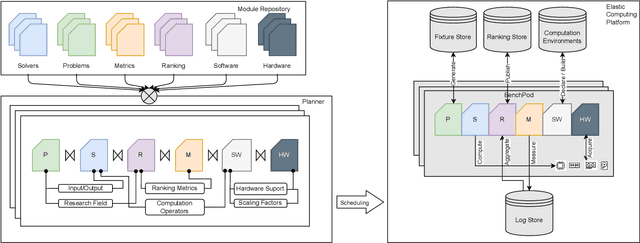


Scientific research communities are embracing AI-based solutions to target tractable scientific tasks and improve research workflows. However, the development and evaluation of such solutions are scattered across multiple disciplines. We formalize the problem of scientific AI benchmarking, and propose a system called SAIBench in the hope of unifying the efforts and enabling low-friction on-boarding of new disciplines. The system approaches this goal with SAIL, a domain-specific language to decouple research problems, AI models, ranking criteria, and software/hardware configuration into reusable modules. We show that this approach is flexible and can adapt to problems, AI models, and evaluation methods defined in different perspectives. The project homepage is https://www.computercouncil.org/SAIBench
OpenClinicalAI: enabling AI to diagnose diseases in real-world clinical settings
Sep 09, 2021This paper quantitatively reveals the state-of-the-art and state-of-the-practice AI systems only achieve acceptable performance on the stringent conditions that all categories of subjects are known, which we call closed clinical settings, but fail to work in real-world clinical settings. Compared to the diagnosis task in the closed setting, real-world clinical settings pose severe challenges, and we must treat them differently. We build a clinical AI benchmark named Clinical AIBench to set up real-world clinical settings to facilitate researches. We propose an open, dynamic machine learning framework and develop an AI system named OpenClinicalAI to diagnose diseases in real-world clinical settings. The first versions of Clinical AIBench and OpenClinicalAI target Alzheimer's disease. In the real-world clinical setting, OpenClinicalAI significantly outperforms the state-of-the-art AI system. In addition, OpenClinicalAI develops personalized diagnosis strategies to avoid unnecessary testing and seamlessly collaborates with clinicians. It is promising to be embedded in the current medical systems to improve medical services.
Shift-and-Balance Attention
Mar 24, 2021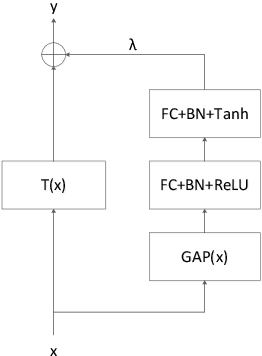
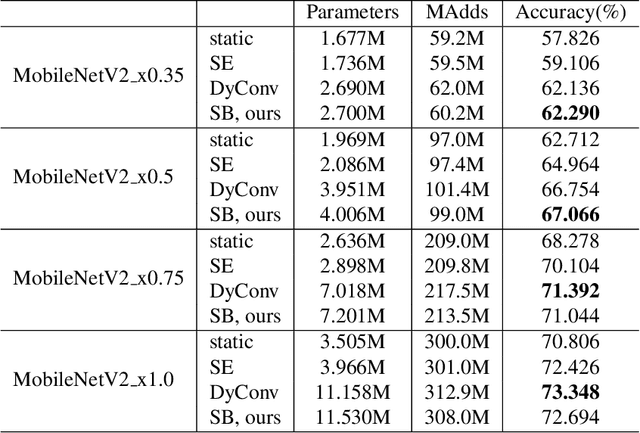
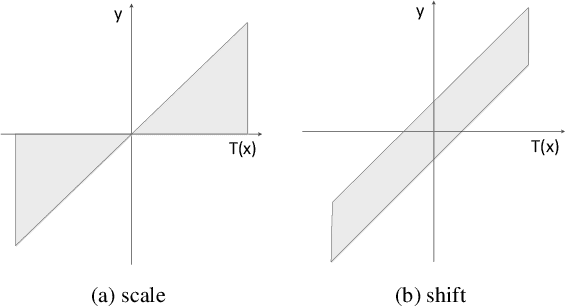
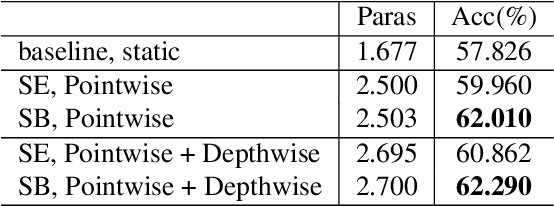
Attention is an effective mechanism to improve the deep model capability. Squeeze-and-Excite (SE) introduces a light-weight attention branch to enhance the network's representational power. The attention branch is gated using the Sigmoid function and multiplied by the feature map's trunk branch. It is too sensitive to coordinate and balance the trunk and attention branches' contributions. To control the attention branch's influence, we propose a new attention method, called Shift-and-Balance (SB). Different from Squeeze-and-Excite, the attention branch is regulated by the learned control factor to control the balance, then added into the feature map's trunk branch. Experiments show that Shift-and-Balance attention significantly improves the accuracy compared to Squeeze-and-Excite when applied in more layers, increasing more size and capacity of a network. Moreover, Shift-and-Balance attention achieves better or close accuracy compared to the state-of-art Dynamic Convolution.
An Isolated Data Island Benchmark Suite for Federated Learning
Aug 17, 2020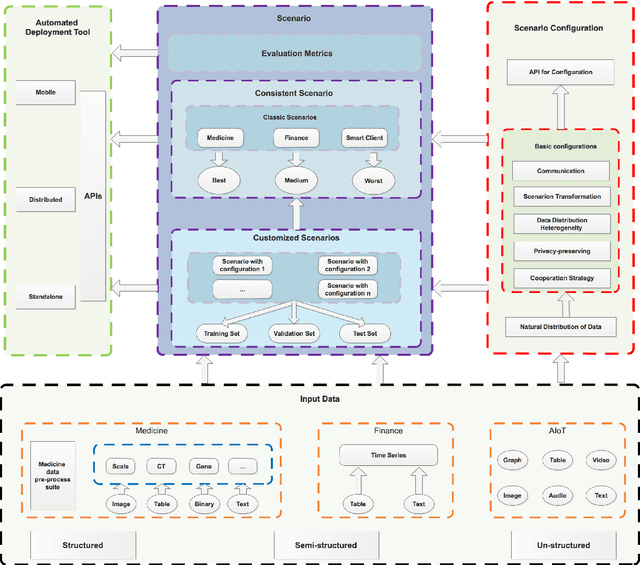
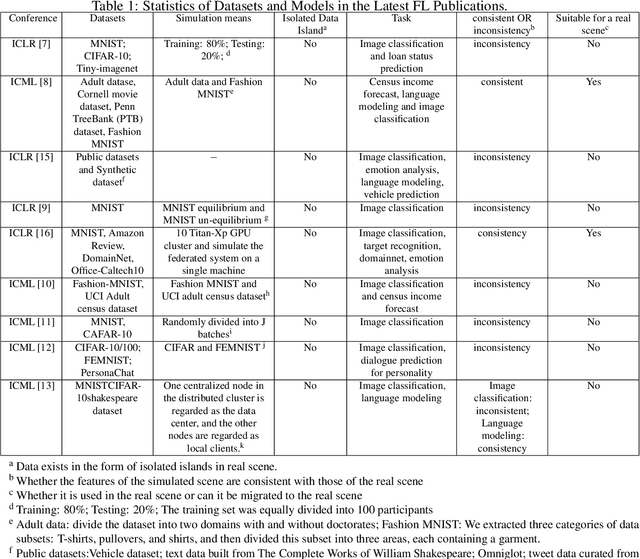
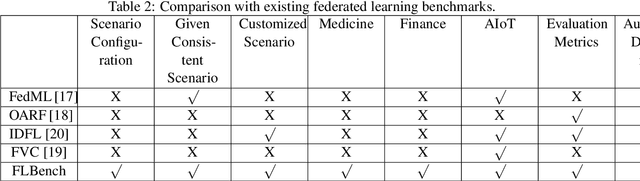
Federated learning (FL) is a new machine learning paradigm, the goal of which is to build a machine learning model based on data sets distributed on multiple devices--so called Isolated Data Island--while keeping their data secure and private. Most existing work manually splits commonly-used public datasets into partitions to simulate real-world Isolated Data Island while failing to capture the intrinsic characteristics of real-world domain data, like medicine, finance or AIoT. To bridge this huge gap, this paper presents and characterizes an Isolated Data Island benchmark suite, named FLBench, for benchmarking federated learning algorithms. FLBench contains three domains: medical, financial and AIoT. By configuring various domains, FLBench is qualified for evaluating the important research aspects of federated learning, and hence become a promising platform for developing novel federated learning algorithms. Finally, FLBench is fully open-sourced and in fast-evolution. We package it as an automated deployment tool. The benchmark suite will be publicly available from http://www.benchcouncil.org/FLBench.
Finet: Using Fine-grained Batch Normalization to Train Light-weight Neural Networks
May 14, 2020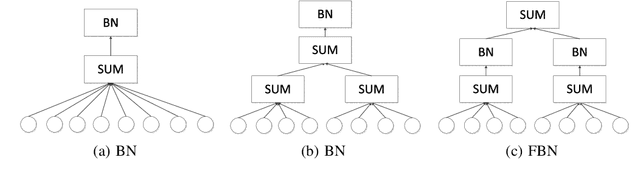
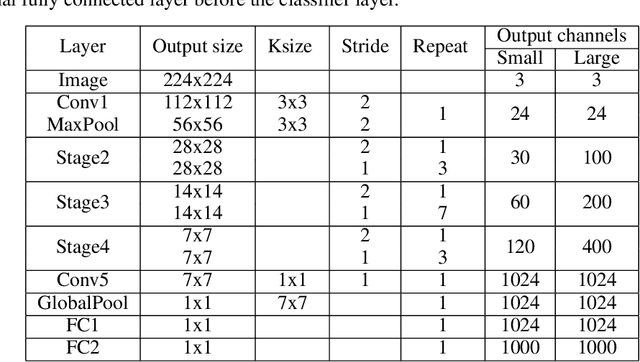
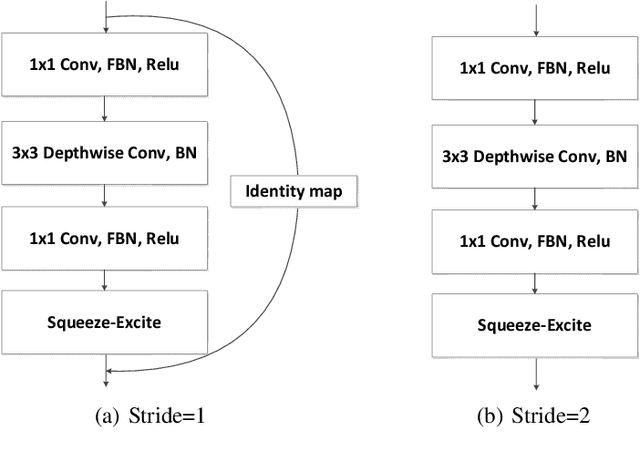
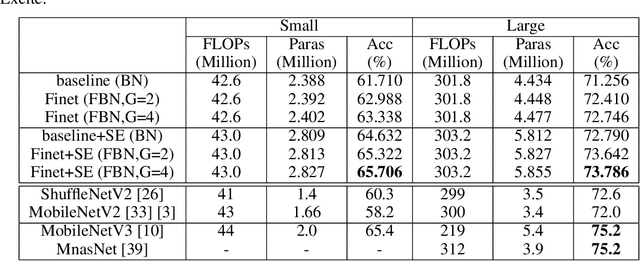
To build light-weight network, we propose a new normalization, Fine-grained Batch Normalization (FBN). Different from Batch Normalization (BN), which normalizes the final summation of the weighted inputs, FBN normalizes the intermediate state of the summation. We propose a novel light-weight network based on FBN, called Finet. At training time, the convolutional layer with FBN can be seen as an inverted bottleneck mechanism. FBN can be fused into convolution at inference time. After fusion, Finet uses the standard convolution with equal channel width, thus makes the inference more efficient. On ImageNet classification dataset, Finet achieves the state-of-art performance (65.706% accuracy with 43M FLOPs, and 73.786% accuracy with 303M FLOPs), Moreover, experiments show that Finet is more efficient than other state-of-art light-weight networks.