 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Golden Classifier-Free Guidance Path via Foresight Fixed Point Iterations
Oct 24, 2025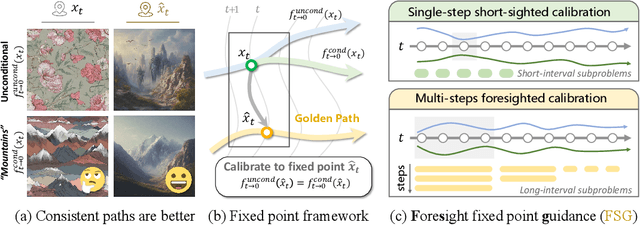

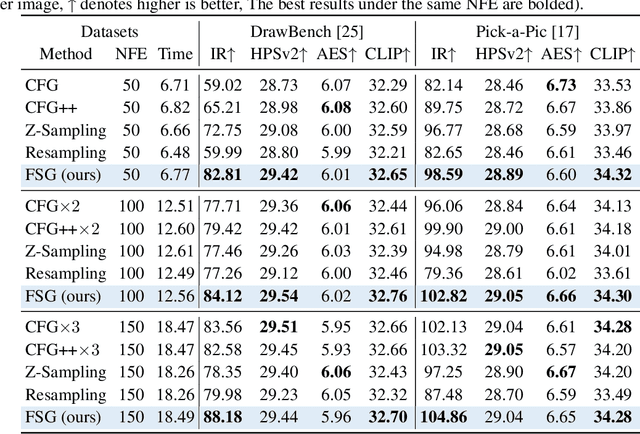
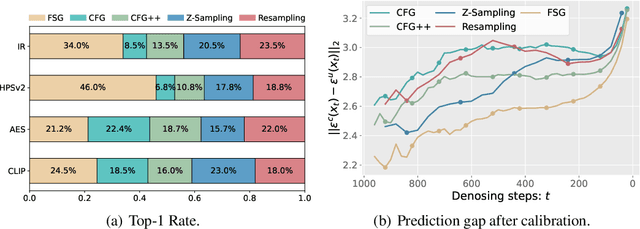
Classifier-Free Guidance (CFG) is an essential component of text-to-image diffusion models, and understanding and advancing its operational mechanisms remains a central focus of research. Existing approaches stem from divergent theoretical interpretations, thereby limiting the design space and obscuring key design choices. To address this, we propose a unified perspective that reframes conditional guidance as fixed point iterations, seeking to identify a golden path where latents produce consistent outputs under both conditional and unconditional generation. We demonstrate that CFG and its variants constitute a special case of single-step short-interval iteration, which is theoretically proven to exhibit inefficiency. To this end, we introduce Foresight Guidance (FSG), which prioritizes solving longer-interval subproblems in early diffusion stages with increased iterations. Extensive experiments across diverse datasets and model architectures validate the superiority of FSG over state-of-the-art methods in both image quality and computational efficiency. Our work offers novel perspectives for conditional guidance and unlocks the potential of adaptive design.
Chain of Attack: On the Robustness of Vision-Language Models Against Transfer-Based Adversarial Attacks
Nov 24, 2024



Pre-trained vision-language models (VLMs) have showcased remarkable performance in image and natural language understanding, such as image captioning and response generation. As the practical applications of vision-language models become increasingly widespread, their potential safety and robustness issues raise concerns that adversaries may evade the system and cause these models to generate toxic content through malicious attacks. Therefore, evaluating the robustness of open-source VLMs against adversarial attacks has garnered growing attention, with transfer-based attacks as a representative black-box attacking strategy. However, most existing transfer-based attacks neglect the importance of the semantic correlations between vision and text modalities, leading to sub-optimal adversarial example generation and attack performance. To address this issue, we present Chain of Attack (CoA), which iteratively enhances the generation of adversarial examples based on the multi-modal semantic update using a series of intermediate attacking steps, achieving superior adversarial transferability and efficiency. A unified attack success rate computing method is further proposed for automatic evasion evaluation. Extensive experiments conducted under the most realistic and high-stakes scenario, demonstrate that our attacking strategy can effectively mislead models to generate targeted responses using only black-box attacks without any knowledge of the victim models. The comprehensive robustness evaluation in our paper provides insight into the vulnerabilities of VLMs and offers a reference for the safety considerations of future model developments.