 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStablePDENet: Enhancing Stability of Operator Learning for Solving Differential Equations
Jan 10, 2026Learning solution operators for differential equations with neural networks has shown great potential in scientific computing, but ensuring their stability under input perturbations remains a critical challenge. This paper presents a robust self-supervised neural operator framework that enhances stability through adversarial training while preserving accuracy. We formulate operator learning as a min-max optimization problem, where the model is trained against worst-case input perturbations to achieve consistent performance under both normal and adversarial conditions. We demonstrate that our method not only achieves good performance on standard inputs, but also maintains high fidelity under adversarial perturbed inputs. The results highlight the importance of stability-aware training in operator learning and provide a foundation for developing reliable neural PDE solvers in real-world applications, where input noise and uncertainties are inevitable.
Towards a Golden Classifier-Free Guidance Path via Foresight Fixed Point Iterations
Oct 24, 2025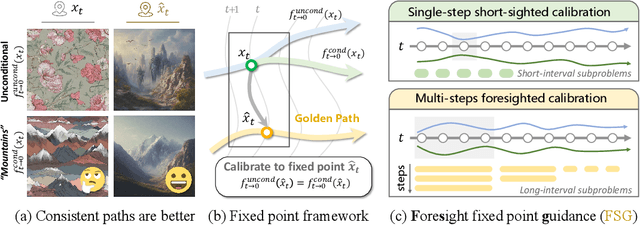

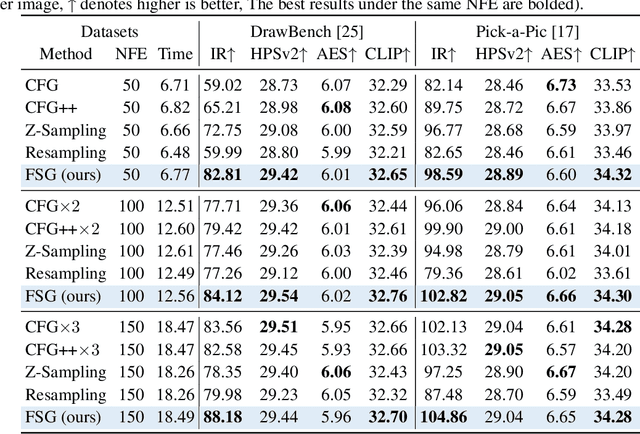
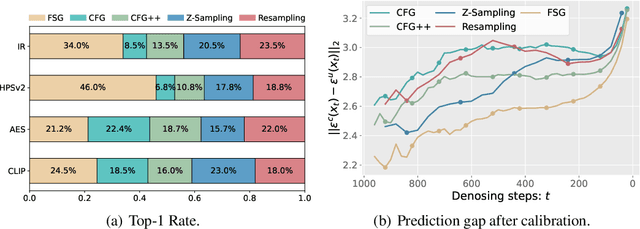
Classifier-Free Guidance (CFG) is an essential component of text-to-image diffusion models, and understanding and advancing its operational mechanisms remains a central focus of research. Existing approaches stem from divergent theoretical interpretations, thereby limiting the design space and obscuring key design choices. To address this, we propose a unified perspective that reframes conditional guidance as fixed point iterations, seeking to identify a golden path where latents produce consistent outputs under both conditional and unconditional generation. We demonstrate that CFG and its variants constitute a special case of single-step short-interval iteration, which is theoretically proven to exhibit inefficiency. To this end, we introduce Foresight Guidance (FSG), which prioritizes solving longer-interval subproblems in early diffusion stages with increased iterations. Extensive experiments across diverse datasets and model architectures validate the superiority of FSG over state-of-the-art methods in both image quality and computational efficiency. Our work offers novel perspectives for conditional guidance and unlocks the potential of adaptive design.
FakeWake: Understanding and Mitigating Fake Wake-up Words of Voice Assistants
Sep 21, 2021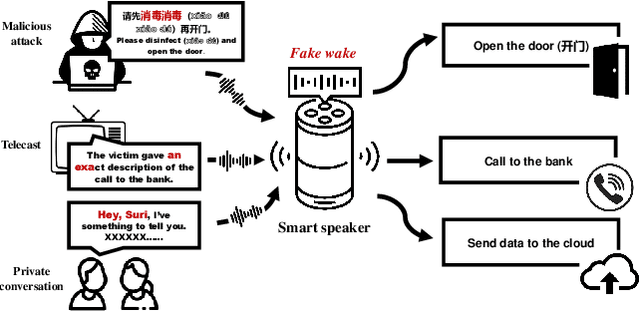
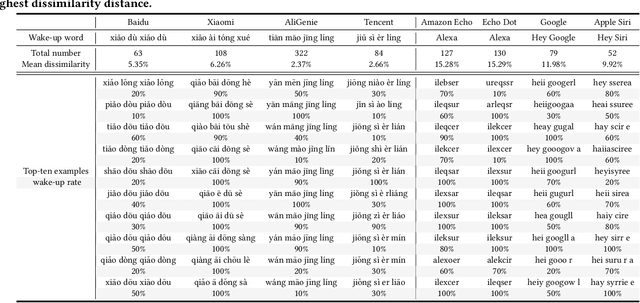
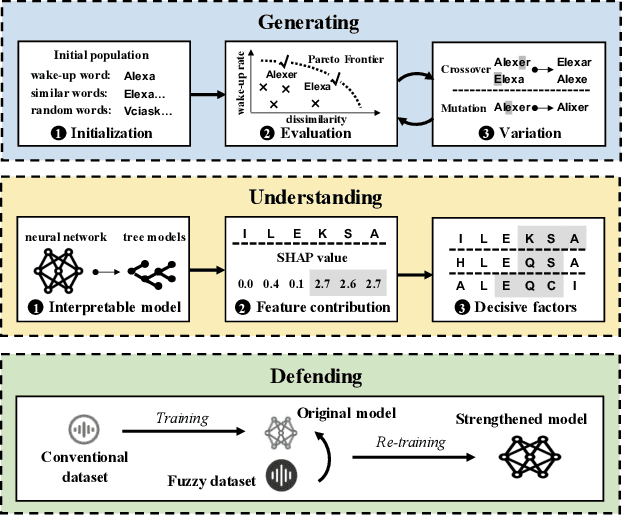

In the area of Internet of Things (IoT) voice assistants have become an important interface to operate smart speakers, smartphones, and even automobiles. To save power and protect user privacy, voice assistants send commands to the cloud only if a small set of pre-registered wake-up words are detected. However, voice assistants are shown to be vulnerable to the FakeWake phenomena, whereby they are inadvertently triggered by innocent-sounding fuzzy words. In this paper, we present a systematic investigation of the FakeWake phenomena from three aspects. To start with, we design the first fuzzy word generator to automatically and efficiently produce fuzzy words instead of searching through a swarm of audio materials. We manage to generate 965 fuzzy words covering 8 most popular English and Chinese smart speakers. To explain the causes underlying the FakeWake phenomena, we construct an interpretable tree-based decision model, which reveals phonetic features that contribute to false acceptance of fuzzy words by wake-up word detectors. Finally, we propose remedies to mitigate the effect of FakeWake. The results show that the strengthened models are not only resilient to fuzzy words but also achieve better overall performance on original training datasets.
JST-RR Model: Joint Modeling of Ratings and Reviews in Sentiment-Topic Prediction
Feb 18, 2021
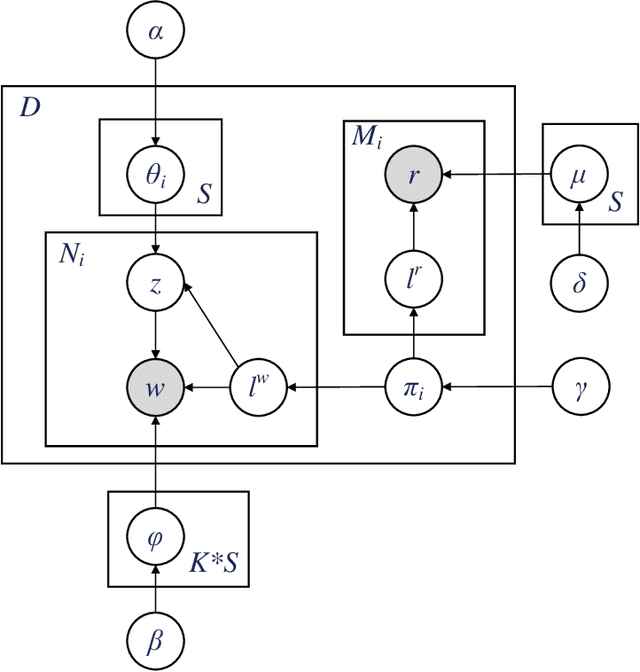

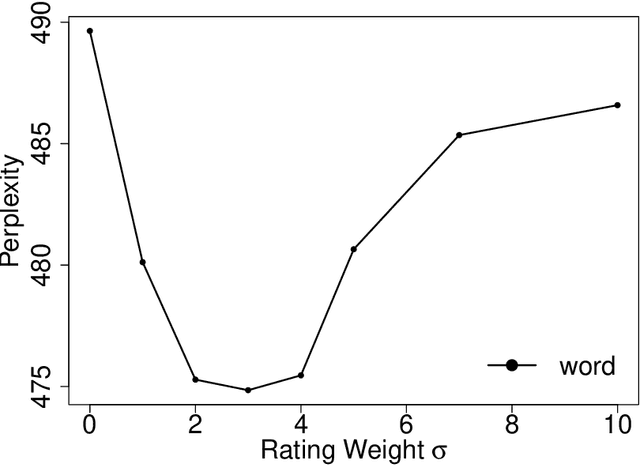
Analysis of online reviews has attracted great attention with broad applications. Often times, the textual reviews are coupled with the numerical ratings in the data. In this work, we propose a probabilistic model to accommodate both textual reviews and overall ratings with consideration of their intrinsic connection for a joint sentiment-topic prediction. The key of the proposed method is to develop a unified generative model where the topic modeling is constructed based on review texts and the sentiment prediction is obtained by combining review texts and overall ratings. The inference of model parameters are obtained by an efficient Gibbs sampling procedure. The proposed method can enhance the prediction accuracy of review data and achieve an effective detection of interpretable topics and sentiments. The merits of the proposed method are elaborated by the case study from Amazon datasets and simulation studies.