 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Constrained Reinforcement Learning Policy
Apr 19, 2023Evolutionary algorithms have been used to evolve a population of actors to generate diverse experiences for training reinforcement learning agents, which helps to tackle the temporal credit assignment problem and improves the exploration efficiency. However, when adapting this approach to address constrained problems, balancing the trade-off between the reward and constraint violation is hard. In this paper, we propose a novel evolutionary constrained reinforcement learning (ECRL) algorithm, which adaptively balances the reward and constraint violation with stochastic ranking, and at the same time, restricts the policy's behaviour by maintaining a set of Lagrange relaxation coefficients with a constraint buffer. Extensive experiments on robotic control benchmarks show that our ECRL achieves outstanding performance compared to state-of-the-art algorithms. Ablation analysis shows the benefits of introducing stochastic ranking and constraint buffer.
Side Channel-Assisted Inference Leakage from Machine Learning-based ECG Classification
Apr 04, 2023



The Electrocardiogram (ECG) measures the electrical cardiac activity generated by the heart to detect abnormal heartbeat and heart attack. However, the irregular occurrence of the abnormalities demands continuous monitoring of heartbeats. Machine learning techniques are leveraged to automate the task to reduce labor work needed during monitoring. In recent years, many companies have launched products with ECG monitoring and irregular heartbeat alert. Among all classification algorithms, the time series-based algorithm dynamic time warping (DTW) is widely adopted to undertake the ECG classification task. Though progress has been achieved, the DTW-based ECG classification also brings a new attacking vector of leaking the patients' diagnosis results. This paper shows that the ECG input samples' labels can be stolen via a side-channel attack, Flush+Reload. In particular, we first identify the vulnerability of DTW for ECG classification, i.e., the correlation between warping path choice and prediction results. Then we implement an attack that leverages Flush+Reload to monitor the warping path selection with known ECG data and then build a predictor for constructing the relation between warping path selection and labels of input ECG samples. Based on experiments, we find that the Flush+Reload-based inference leakage can achieve an 84.0\% attacking success rate to identify the labels of the two samples in DTW.
State Space Closure: Revisiting Endless Online Level Generation via Reinforcement Learning
Dec 06, 2022



In this paper we revisit endless online level generation with the recently proposed experience-driven procedural content generation via reinforcement learning (EDRL) framework, from an observation that EDRL tends to generate recurrent patterns. Inspired by this phenomenon, we formulate a notion of state space closure, which means that any state that may appear in an infinite-horizon online generation process can be found in a finite horizon. Through theoretical analysis we find that though state space closure arises a concern about diversity, it makes the EDRL trained on a finite-horizon generalised to the infinite-horizon scenario without deterioration of content quality. Moreover, we verify the quality and diversity of contents generated by EDRL via empirical studies on the widely used Super Mario Bros. benchmark. Experimental results reveal that the current EDRL approach's ability of generating diverse game levels is limited due to the state space closure, whereas it does not suffer from reward deterioration given a horizon longer than the one of training. Concluding our findings and analysis, we argue that future works in generating online diverse and high-quality contents via EDRL should address the issue of diversity on the premise of state space closure which ensures the quality.
On Representing Mixed-Integer Linear Programs by Graph Neural Networks
Oct 19, 2022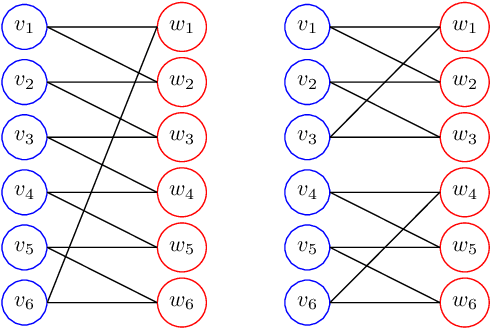
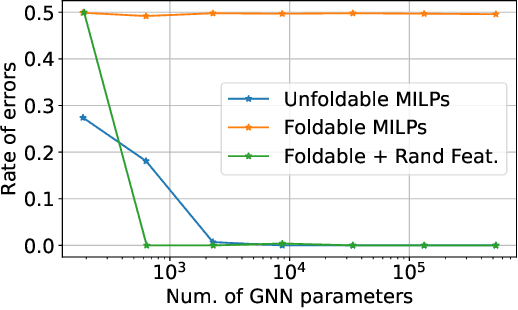
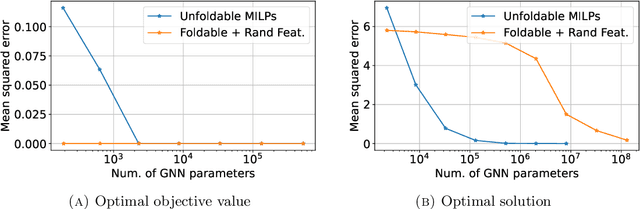
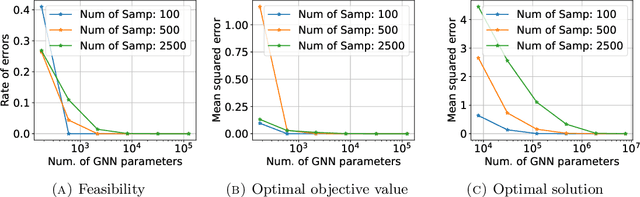
While Mixed-integer linear programming (MILP) is NP-hard in general, practical MILP has received roughly 100--fold speedup in the past twenty years. Still, many classes of MILPs quickly become unsolvable as their sizes increase, motivating researchers to seek new acceleration techniques for MILPs. With deep learning, they have obtained strong empirical results, and many results were obtained by applying graph neural networks (GNNs) to making decisions in various stages of MILP solution processes. This work discovers a fundamental limitation: there exist feasible and infeasible MILPs that all GNNs will, however, treat equally, indicating GNN's lacking power to express general MILPs. Then, we show that, by restricting the MILPs to unfoldable ones or by adding random features, there exist GNNs that can reliably predict MILP feasibility, optimal objective values, and optimal solutions up to prescribed precision. We conducted small-scale numerical experiments to validate our theoretical findings.
On Representing Linear Programs by Graph Neural Networks
Sep 25, 2022
Learning to optimize is a rapidly growing area that aims to solve optimization problems or improve existing optimization algorithms using machine learning (ML). In particular, the graph neural network (GNN) is considered a suitable ML model for optimization problems whose variables and constraints are permutation--invariant, for example, the linear program (LP). While the literature has reported encouraging numerical results, this paper establishes the theoretical foundation of applying GNNs to solving LPs. Given any size limit of LPs, we construct a GNN that maps different LPs to different outputs. We show that properly built GNNs can reliably predict feasibility, boundedness, and an optimal solution for each LP in a broad class. Our proofs are based upon the recently--discovered connections between the Weisfeiler--Lehman isomorphism test and the GNN. To validate our results, we train a simple GNN and present its accuracy in mapping LPs to their feasibilities and solutions.
Online Game Level Generation from Music
Jul 12, 2022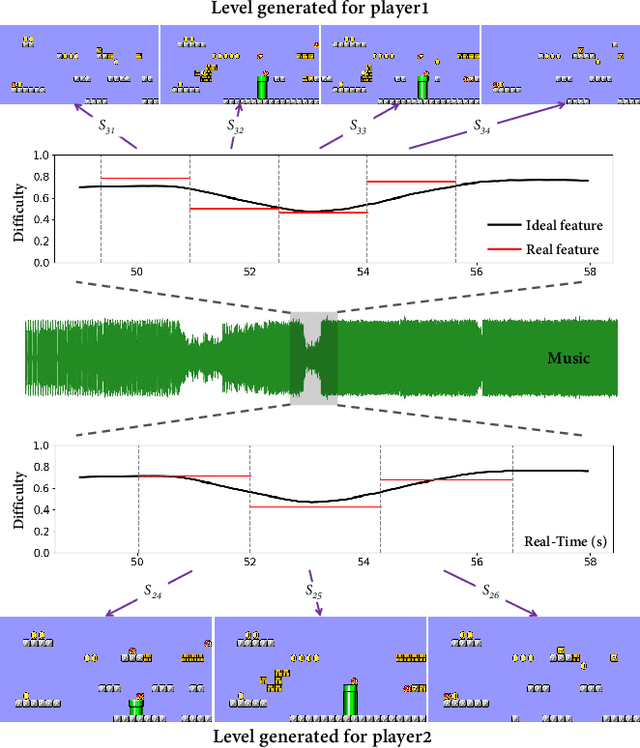
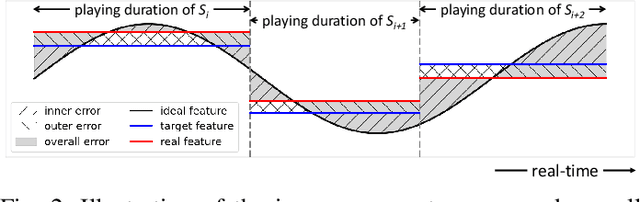
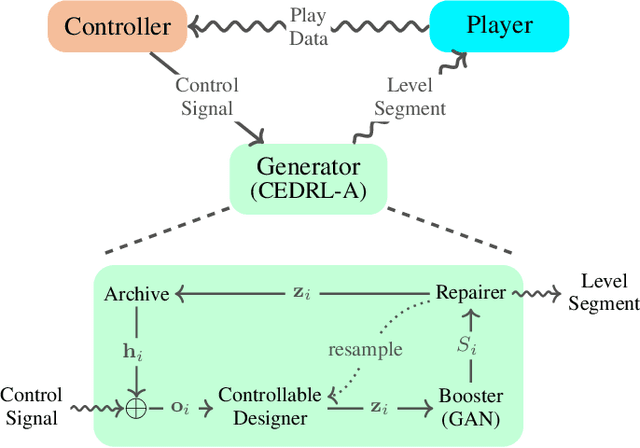
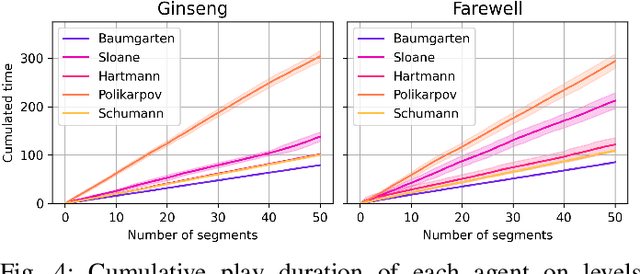
Game consists of multiple types of content, while the harmony of different content types play an essential role in game design. However, most works on procedural content generation consider only one type of content at a time. In this paper, we propose and formulate online level generation from music, in a way of matching a level feature to a music feature in real-time, while adapting to players' play speed. A generic framework named online player-adaptive procedural content generation via reinforcement learning, OPARL for short, is built upon the experience-driven reinforcement learning and controllable reinforcement learning, to enable online level generation from music. Furthermore, a novel control policy based on local search and k-nearest neighbours is proposed and integrated into OPARL to control the level generator considering the play data collected online. Results of simulation-based experiments show that our implementation of OPARL is competent to generate playable levels with difficulty degree matched to the ``energy'' dynamic of music for different artificial players in an online fashion.
Generating Game Levels of Diverse Behaviour Engagement
Jul 05, 2022

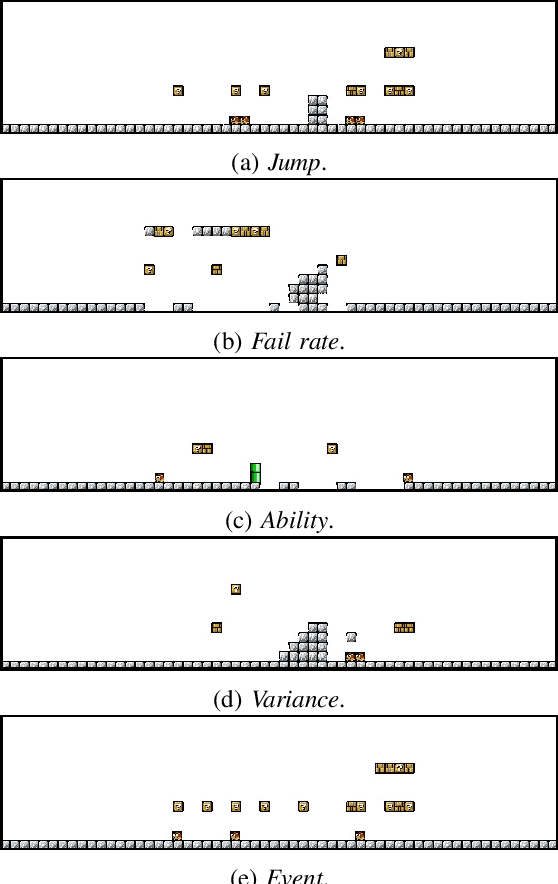
Recent years, there has been growing interests in experience-driven procedural level generation. Various metrics have been formulated to model player experience and help generate personalised levels. In this work, we question whether experience metrics can adapt to agents with different personas. We start by reviewing existing metrics for evaluating game levels. Then, focusing on platformer games, we design a framework integrating various agents and evaluation metrics. Experimental studies on \emph{Super Mario Bros.} indicate that using the same evaluation metrics but agents with different personas can generate levels for particular persona. It implies that, for simple games, using a game-playing agent of specific player archetype as a level tester is probably all we need to generate levels of diverse behaviour engagement.
Hyperparameter Tuning is All You Need for LISTA
Oct 29, 2021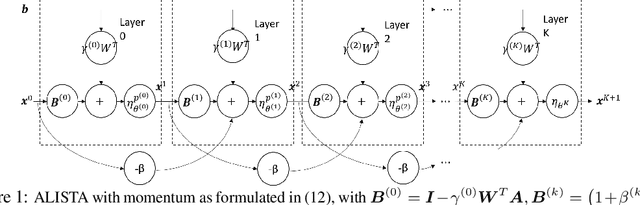
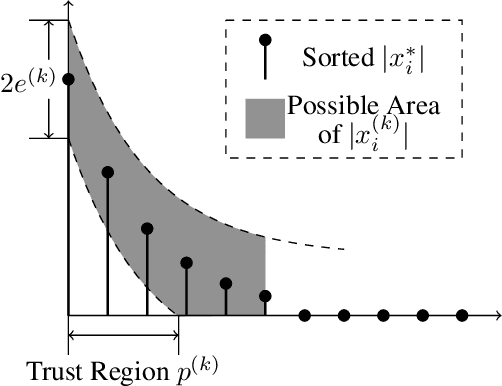
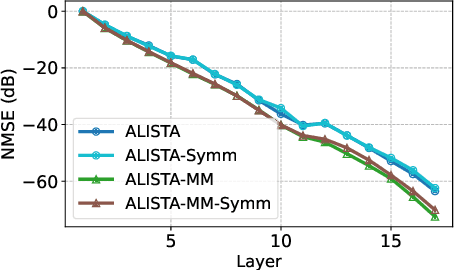
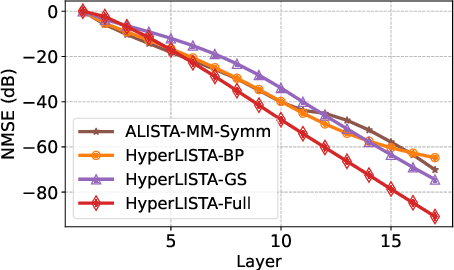
Learned Iterative Shrinkage-Thresholding Algorithm (LISTA) introduces the concept of unrolling an iterative algorithm and training it like a neural network. It has had great success on sparse recovery. In this paper, we show that adding momentum to intermediate variables in the LISTA network achieves a better convergence rate and, in particular, the network with instance-optimal parameters is superlinearly convergent. Moreover, our new theoretical results lead to a practical approach of automatically and adaptively calculating the parameters of a LISTA network layer based on its previous layers. Perhaps most surprisingly, such an adaptive-parameter procedure reduces the training of LISTA to tuning only three hyperparameters from data: a new record set in the context of the recent advances on trimming down LISTA complexity. We call this new ultra-light weight network HyperLISTA. Compared to state-of-the-art LISTA models, HyperLISTA achieves almost the same performance on seen data distributions and performs better when tested on unseen distributions (specifically, those with different sparsity levels and nonzero magnitudes). Code is available: https://github.com/VITA-Group/HyperLISTA.
Learned Robust PCA: A Scalable Deep Unfolding Approach for High-Dimensional Outlier Detection
Oct 11, 2021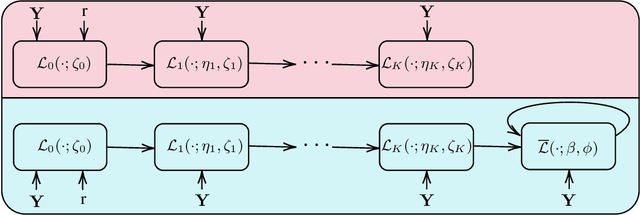

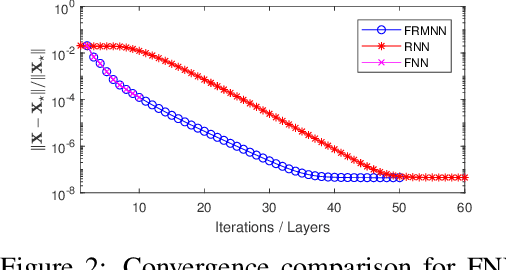
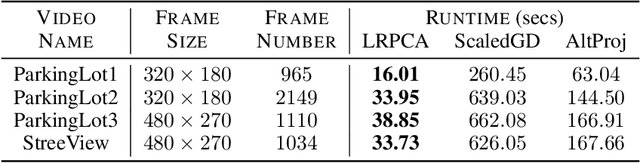
Robust principal component analysis (RPCA) is a critical tool in modern machine learning, which detects outliers in the task of low-rank matrix reconstruction. In this paper, we propose a scalable and learnable non-convex approach for high-dimensional RPCA problems, which we call Learned Robust PCA (LRPCA). LRPCA is highly efficient, and its free parameters can be effectively learned to optimize via deep unfolding. Moreover, we extend deep unfolding from finite iterations to infinite iterations via a novel feedforward-recurrent-mixed neural network model. We establish the recovery guarantee of LRPCA under mild assumptions for RPCA. Numerical experiments show that LRPCA outperforms the state-of-the-art RPCA algorithms, such as ScaledGD and AltProj, on both synthetic datasets and real-world applications.
Keiki: Towards Realistic Danmaku Generation via Sequential GANs
Jul 07, 2021
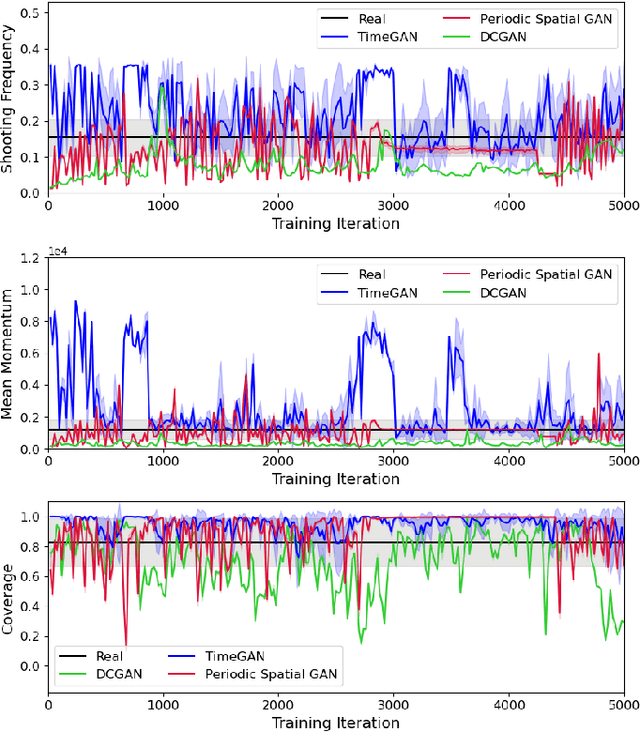
Search-based procedural content generation methods have recently been introduced for the autonomous creation of bullet hell games. Search-based methods, however, can hardly model patterns of danmakus -- the bullet hell shooting entity -- explicitly and the resulting levels often look non-realistic. In this paper, we present a novel bullet hell game platform named Keiki, which allows the representation of danmakus as a parametric sequence which, in turn, can model the sequential behaviours of danmakus. We employ three types of generative adversarial networks (GANs) and test Keiki across three metrics designed to quantify the quality of the generated danmakus. The time-series GAN and periodic spatial GAN show different yet competitive performance in terms of the evaluation metrics adopted, their deviation from human-designed danmakus, and the diversity of generated danmakus. The preliminary experimental studies presented here showcase that potential of time-series GANs for sequential content generation in games.