 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStereoMamba: Real-time and Robust Intraoperative Stereo Disparity Estimation via Long-range Spatial Dependencies
Apr 24, 2025Stereo disparity estimation is crucial for obtaining depth information in robot-assisted minimally invasive surgery (RAMIS). While current deep learning methods have made significant advancements, challenges remain in achieving an optimal balance between accuracy, robustness, and inference speed. To address these challenges, we propose the StereoMamba architecture, which is specifically designed for stereo disparity estimation in RAMIS. Our approach is based on a novel Feature Extraction Mamba (FE-Mamba) module, which enhances long-range spatial dependencies both within and across stereo images. To effectively integrate multi-scale features from FE-Mamba, we then introduce a novel Multidimensional Feature Fusion (MFF) module. Experiments against the state-of-the-art on the ex-vivo SCARED benchmark demonstrate that StereoMamba achieves superior performance on EPE of 2.64 px and depth MAE of 2.55 mm, the second-best performance on Bad2 of 41.49% and Bad3 of 26.99%, while maintaining an inference speed of 21.28 FPS for a pair of high-resolution images (1280*1024), striking the optimum balance between accuracy, robustness, and efficiency. Furthermore, by comparing synthesized right images, generated from warping left images using the generated disparity maps, with the actual right image, StereoMamba achieves the best average SSIM (0.8970) and PSNR (16.0761), exhibiting strong zero-shot generalization on the in-vivo RIS2017 and StereoMIS datasets.
Personalizing Federated Instrument Segmentation with Visual Trait Priors in Robotic Surgery
Aug 06, 2024



Personalized federated learning (PFL) for surgical instrument segmentation (SIS) is a promising approach. It enables multiple clinical sites to collaboratively train a series of models in privacy, with each model tailored to the individual distribution of each site. Existing PFL methods rarely consider the personalization of multi-headed self-attention, and do not account for appearance diversity and instrument shape similarity, both inherent in surgical scenes. We thus propose PFedSIS, a novel PFL method with visual trait priors for SIS, incorporating global-personalized disentanglement (GPD), appearance-regulation personalized enhancement (APE), and shape-similarity global enhancement (SGE), to boost SIS performance in each site. GPD represents the first attempt at head-wise assignment for multi-headed self-attention personalization. To preserve the unique appearance representation of each site and gradually leverage the inter-site difference, APE introduces appearance regulation and provides customized layer-wise aggregation solutions via hypernetworks for each site's personalized parameters. The mutual shape information of instruments is maintained and shared via SGE, which enhances the cross-style shape consistency on the image level and computes the shape-similarity contribution of each site on the prediction level for updating the global parameters. PFedSIS outperforms state-of-the-art methods with +1.51% Dice, +2.11% IoU, -2.79 ASSD, -15.55 HD95 performance gains. The corresponding code and models will be released at https://github.com/wzjialang/PFedSIS.
Think Step by Step: Chain-of-Gesture Prompting for Error Detection in Robotic Surgical Videos
Jun 27, 2024



Despite significant advancements in robotic systems and surgical data science, ensuring safe and optimal execution in robot-assisted minimally invasive surgery (RMIS) remains a complex challenge. Current surgical error detection methods involve two parts: identifying surgical gestures and then detecting errors within each gesture clip. These methods seldom consider the rich contextual and semantic information inherent in surgical videos, limiting their performance due to reliance on accurate gesture identification. Motivated by the chain-of-thought prompting in natural language processing, this letter presents a novel and real-time end-to-end error detection framework, Chain-of-Thought (COG) prompting, leveraging contextual information from surgical videos. This encompasses two reasoning modules designed to mimic the decision-making processes of expert surgeons. Concretely, we first design a Gestural-Visual Reasoning module, which utilizes transformer and attention architectures for gesture prompting, while the second, a Multi-Scale Temporal Reasoning module, employs a multi-stage temporal convolutional network with both slow and fast paths for temporal information extraction. We extensively validate our method on the public benchmark RMIS dataset JIGSAWS. Our method encapsulates the reasoning processes inherent to surgical activities enabling it to outperform the state-of-the-art by 4.6% in F1 score, 4.6% in Accuracy, and 5.9% in Jaccard index while processing each frame in 6.69 milliseconds on average, demonstrating the great potential of our approach in enhancing the safety and efficacy of RMIS procedures and surgical education. The code will be available.
SEDMamba: Enhancing Selective State Space Modelling with Bottleneck Mechanism and Fine-to-Coarse Temporal Fusion for Efficient Error Detection in Robot-Assisted Surgery
Jun 22, 2024



Automated detection of surgical errors can improve robotic-assisted surgery. Despite promising progress, existing methods still face challenges in capturing rich temporal context to establish long-term dependencies while maintaining computational efficiency. In this paper, we propose a novel hierarchical model named SEDMamba, which incorporates the selective state space model (SSM) into surgical error detection, facilitating efficient long sequence modelling with linear complexity. SEDMamba enhances selective SSM with bottleneck mechanism and fine-to-coarse temporal fusion (FCTF) to detect and temporally localize surgical errors in long videos. The bottleneck mechanism compresses and restores features within their spatial dimension, thereby reducing computational complexity. FCTF utilizes multiple dilated 1D convolutional layers to merge temporal information across diverse scale ranges, accommodating errors of varying durations. Besides, we deploy an established observational clinical human reliability assessment tool (OCHRA) to annotate the errors of suturing tasks in an open-source radical prostatectomy dataset (SAR-RARP50), constructing the first frame-level in-vivo surgical error detection dataset to support error detection in real-world scenarios. Experimental results demonstrate that our SEDMamba outperforms state-of-the-art methods with at least 1.82% AUC and 3.80% AP performance gain with significantly reduced computational complexity.
Deep Learning Based Automatic Modulation Recognition: Models, Datasets, and Challenges
Jul 20, 2022



Automatic modulation recognition (AMR) detects the modulation scheme of the received signals for further signal processing without needing prior information, and provides the essential function when such information is missing. Recent breakthroughs in deep learning (DL) have laid the foundation for developing high-performance DL-AMR approaches for communications systems. Comparing with traditional modulation detection methods, DL-AMR approaches have achieved promising performance including high recognition accuracy and low false alarms due to the strong feature extraction and classification abilities of deep neural networks. Despite the promising potential, DL-AMR approaches also bring concerns to complexity and explainability, which affect the practical deployment in wireless communications systems. This paper aims to present a review of the current DL-AMR research, with a focus on appropriate DL models and benchmark datasets. We further provide comprehensive experiments to compare the state of the art models for single-input-single-output (SISO) systems from both accuracy and complexity perspectives, and propose to apply DL-AMR in the new multiple-input-multiple-output (MIMO) scenario with precoding. Finally, existing challenges and possible future research directions are discussed.
An Efficient Deep Learning Model for Automatic Modulation Recognition Based on Parameter Estimation and Transformation
Oct 11, 2021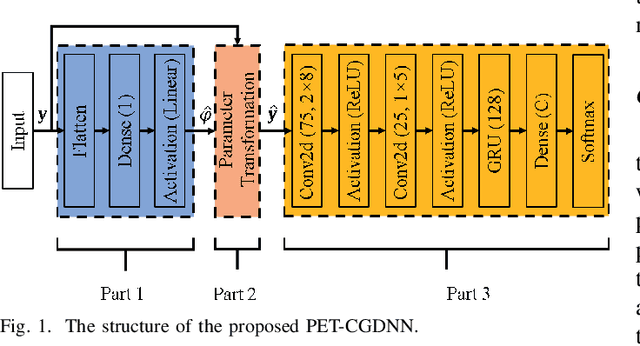
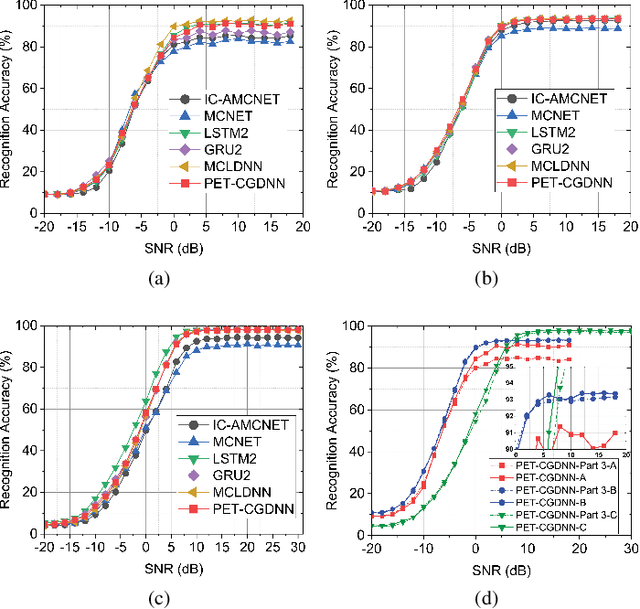
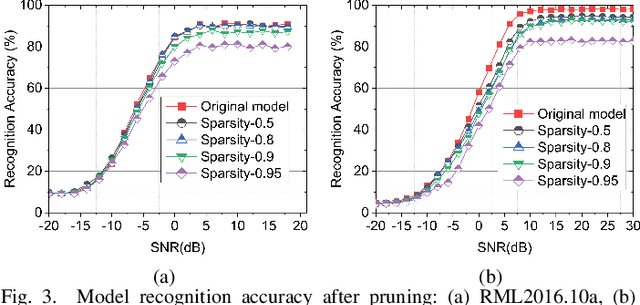
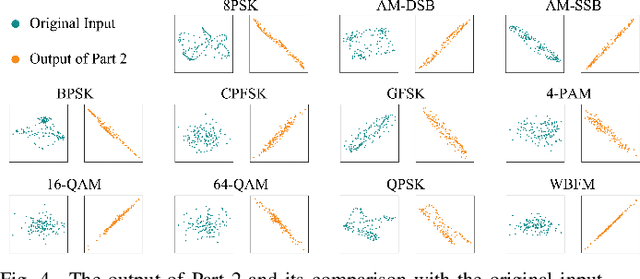
Automatic modulation recognition (AMR) is a promising technology for intelligent communication receivers to detect signal modulation schemes. Recently, the emerging deep learning (DL) research has facilitated high-performance DL-AMR approaches. However, most DL-AMR models only focus on recognition accuracy, leading to huge model sizes and high computational complexity, while some lightweight and low-complexity models struggle to meet the accuracy requirements. This letter proposes an efficient DL-AMR model based on phase parameter estimation and transformation, with convolutional neural network (CNN) and gated recurrent unit (GRU) as the feature extraction layers, which can achieve high recognition accuracy equivalent to the existing state-of-the-art models but reduces more than a third of the volume of their parameters. Meanwhile, our model is more competitive in training time and test time than the benchmark models with similar recognition accuracy. Moreover, we further propose to compress our model by pruning, which maintains the recognition accuracy higher than 90% while has less than 1/8 of the number of parameters comparing with state-of-the-art models.
OH-Former: Omni-Relational High-Order Transformer for Person Re-Identification
Sep 23, 2021
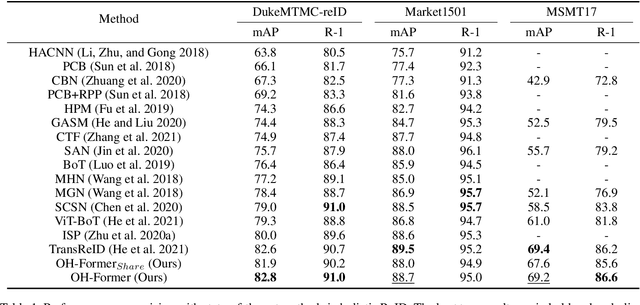
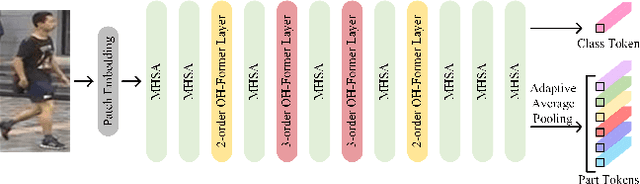
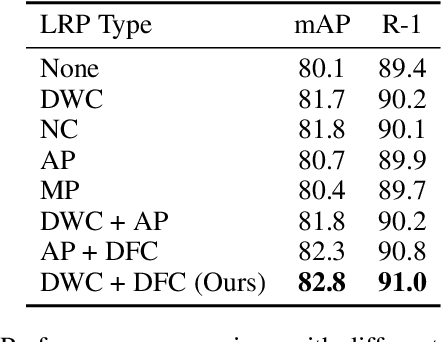
Transformers have shown preferable performance on many vision tasks. However, for the task of person re-identification (ReID), vanilla transformers leave the rich contexts on high-order feature relations under-exploited and deteriorate local feature details, which are insufficient due to the dramatic variations of pedestrians. In this work, we propose an Omni-Relational High-Order Transformer (OH-Former) to model omni-relational features for ReID. First, to strengthen the capacity of visual representation, instead of obtaining the attention matrix based on pairs of queries and isolated keys at each spatial location, we take a step further to model high-order statistics information for the non-local mechanism. We share the attention weights in the corresponding layer of each order with a prior mixing mechanism to reduce the computation cost. Then, a convolution-based local relation perception module is proposed to extract the local relations and 2D position information. The experimental results of our model are superior promising, which show state-of-the-art performance on Market-1501, DukeMTMC, MSMT17 and Occluded-Duke datasets.