 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Computational Complexity in Statistical Models with Second-Order Information
Feb 10, 2022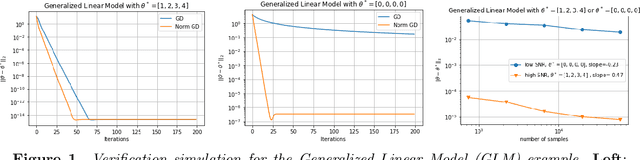
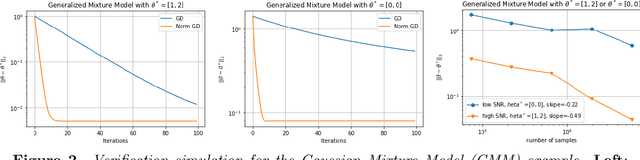
It is known that when the statistical models are singular, i.e., the Fisher information matrix at the true parameter is degenerate, the fixed step-size gradient descent algorithm takes polynomial number of steps in terms of the sample size $n$ to converge to a final statistical radius around the true parameter, which can be unsatisfactory for the application. To further improve that computational complexity, we consider the utilization of the second-order information in the design of optimization algorithms. Specifically, we study the normalized gradient descent (NormGD) algorithm for solving parameter estimation in parametric statistical models, which is a variant of gradient descent algorithm whose step size is scaled by the maximum eigenvalue of the Hessian matrix of the empirical loss function of statistical models. When the population loss function, i.e., the limit of the empirical loss function when $n$ goes to infinity, is homogeneous in all directions, we demonstrate that the NormGD iterates reach a final statistical radius around the true parameter after a logarithmic number of iterations in terms of $n$. Therefore, for fixed dimension $d$, the NormGD algorithm achieves the optimal overall computational complexity $\mathcal{O}(n)$ to reach the final statistical radius. This computational complexity is cheaper than that of the fixed step-size gradient descent algorithm, which is of the order $\mathcal{O}(n^{\tau})$ for some $\tau > 1$, to reach the same statistical radius. We illustrate our general theory under two statistical models: generalized linear models and mixture models, and experimental results support our prediction with general theory.
On the computational and statistical complexity of over-parameterized matrix sensing
Jan 27, 2021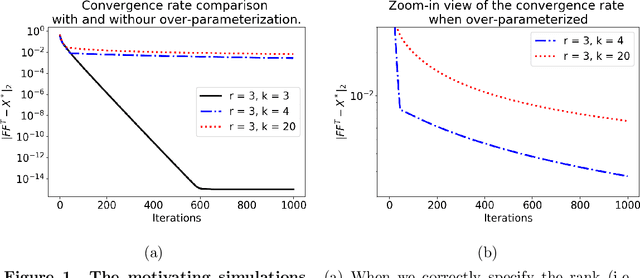
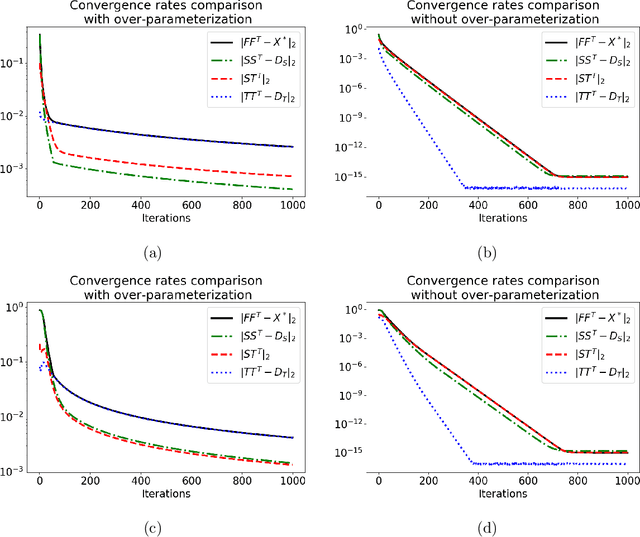
We consider solving the low rank matrix sensing problem with Factorized Gradient Descend (FGD) method when the true rank is unknown and over-specified, which we refer to as over-parameterized matrix sensing. If the ground truth signal $\mathbf{X}^* \in \mathbb{R}^{d*d}$ is of rank $r$, but we try to recover it using $\mathbf{F} \mathbf{F}^\top$ where $\mathbf{F} \in \mathbb{R}^{d*k}$ and $k>r$, the existing statistical analysis falls short, due to a flat local curvature of the loss function around the global maxima. By decomposing the factorized matrix $\mathbf{F}$ into separate column spaces to capture the effect of extra ranks, we show that $\|\mathbf{F}_t \mathbf{F}_t - \mathbf{X}^*\|_{F}^2$ converges to a statistical error of $\tilde{\mathcal{O}} ({k d \sigma^2/n})$ after $\tilde{\mathcal{O}}(\frac{\sigma_{r}}{\sigma}\sqrt{\frac{n}{d}})$ number of iterations where $\mathbf{F}_t$ is the output of FGD after $t$ iterations, $\sigma^2$ is the variance of the observation noise, $\sigma_{r}$ is the $r$-th largest eigenvalue of $\mathbf{X}^*$, and $n$ is the number of sample. Our results, therefore, offer a comprehensive picture of the statistical and computational complexity of FGD for the over-parameterized matrix sensing problem.
Predicting What You Already Know Helps: Provable Self-Supervised Learning
Aug 03, 2020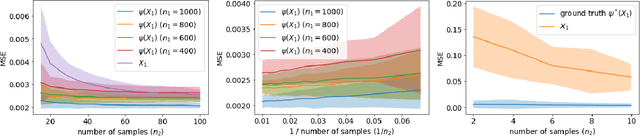
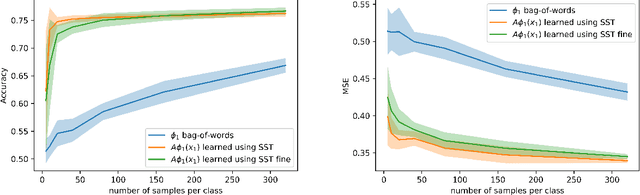
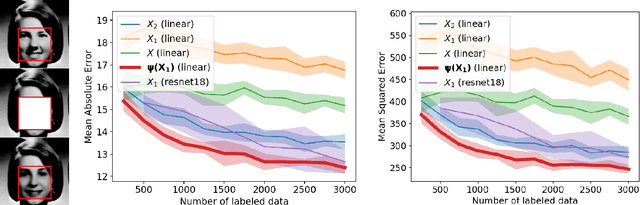
Self-supervised representation learning solves auxiliary prediction tasks (known as pretext tasks), that do not require labeled data, to learn semantic representations. These pretext tasks are created solely using the input features, such as predicting a missing image patch, recovering the color channels of an image from context, or predicting missing words, yet predicting this $known\ $information helps in learning representations effective for downstream prediction tasks. This paper posits a mechanism based on conditional independence to formalize how solving certain pretext tasks can learn representations that provably decreases the sample complexity of downstream supervised tasks. Formally, we quantify how approximate independence between the components of the pretext task (conditional on the label and latent variables) allows us to learn representations that can solve the downstream task with drastically reduced sample complexity by just training a linear layer on top of the learned representation.
Robust Structured Statistical Estimation via Conditional Gradient Type Methods
Jul 07, 2020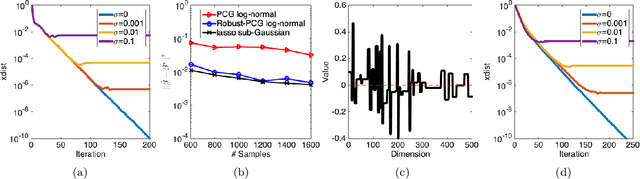
Structured statistical estimation problems are often solved by Conditional Gradient (CG) type methods to avoid the computationally expensive projection operation. However, the existing CG type methods are not robust to data corruption. To address this, we propose to robustify CG type methods against Huber's corruption model and heavy-tailed data. First, we show that the two Pairwise CG methods are stable, i.e., do not accumulate error. Combined with robust mean gradient estimation techniques, we can therefore guarantee robustness to a wide class of problems, but now in a projection-free algorithmic framework. Next, we consider high dimensional problems. Robust mean estimation based approaches may have an unacceptably high sample complexity. When the constraint set is a $\ell_0$ norm ball, Iterative-Hard-Thresholding-based methods have been developed recently. Yet extension is non-trivial even for general sets with $O(d)$ extreme points. For setting where the feasible set has $O(\text{poly}(d))$ extreme points, we develop a novel robustness method, based on a new condition we call the Robust Atom Selection Condition (RASC). When RASC is satisfied, our method converges linearly with a corresponding statistical error, with sample complexity that scales correctly in the sparsity of the problem, rather than the ambient dimension as would be required by any approach based on robust mean estimation.
Efficient Relaxed Gradient Support Pursuit for Sparsity Constrained Non-convex Optimization
Dec 02, 2019
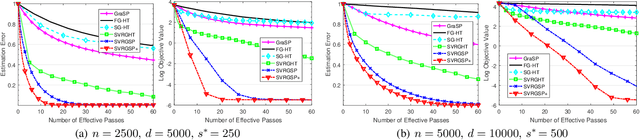
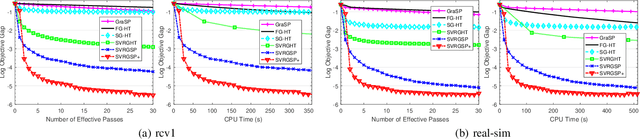
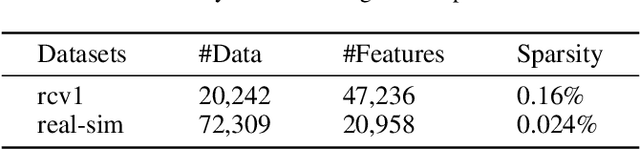
Large-scale non-convex sparsity-constrained problems have recently gained extensive attention. Most existing deterministic optimization methods (e.g., GraSP) are not suitable for large-scale and high-dimensional problems, and thus stochastic optimization methods with hard thresholding (e.g., SVRGHT) become more attractive. Inspired by GraSP, this paper proposes a new general relaxed gradient support pursuit (RGraSP) framework, in which the sub-algorithm only requires to satisfy a slack descent condition. We also design two specific semi-stochastic gradient hard thresholding algorithms. In particular, our algorithms have much less hard thresholding operations than SVRGHT, and their average per-iteration cost is much lower (i.e., O(d) vs. O(d log(d)) for SVRGHT), which leads to faster convergence. Our experimental results on both synthetic and real-world datasets show that our algorithms are superior to the state-of-the-art gradient hard thresholding methods.
Communication-Efficient Asynchronous Stochastic Frank-Wolfe over Nuclear-norm Balls
Oct 17, 2019
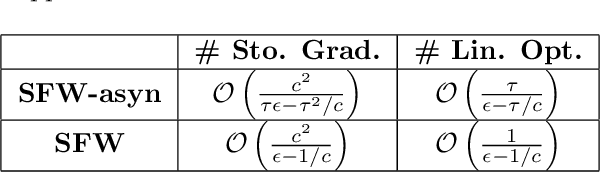
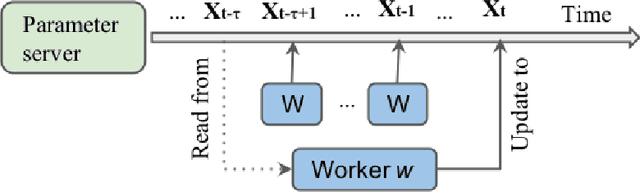
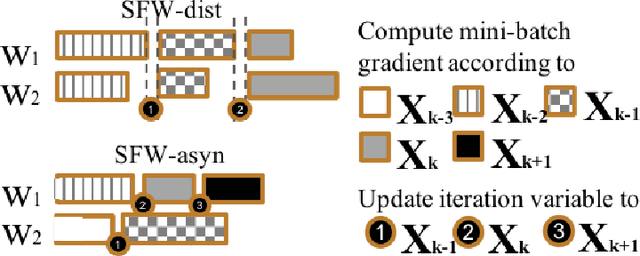
Large-scale machine learning training suffers from two prior challenges, specifically for nuclear-norm constrained problems with distributed systems: the synchronization slowdown due to the straggling workers, and high communication costs. In this work, we propose an asynchronous Stochastic Frank Wolfe (SFW-asyn) method, which, for the first time, solves the two problems simultaneously, while successfully maintaining the same convergence rate as the vanilla SFW. We implement our algorithm in python (with MPI) to run on Amazon EC2, and demonstrate that SFW-asyn yields speed-ups almost linear to the number of machines compared to the vanilla SFW.
Primal-Dual Block Frank-Wolfe
Jun 06, 2019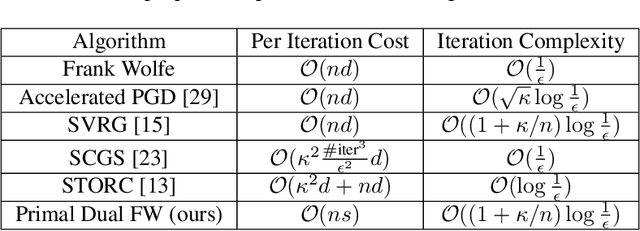
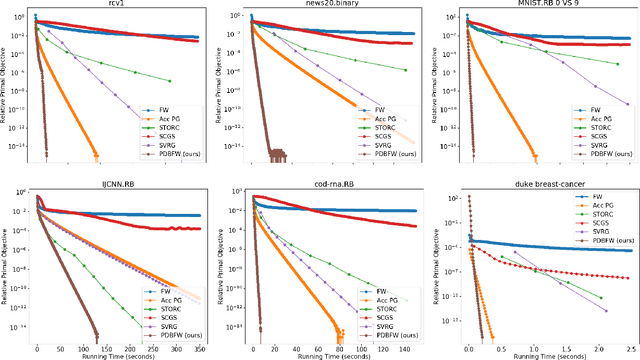
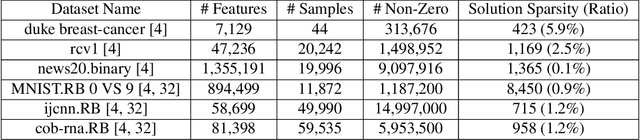
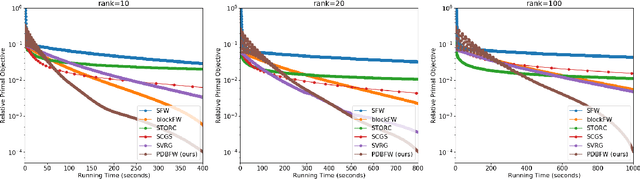
We propose a variant of the Frank-Wolfe algorithm for solving a class of sparse/low-rank optimization problems. Our formulation includes Elastic Net, regularized SVMs and phase retrieval as special cases. The proposed Primal-Dual Block Frank-Wolfe algorithm reduces the per-iteration cost while maintaining linear convergence rate. The per iteration cost of our method depends on the structural complexity of the solution (i.e. sparsity/low-rank) instead of the ambient dimension. We empirically show that our algorithm outperforms the state-of-the-art methods on (multi-class) classification tasks.
Bottom-up Object Detection by Grouping Extreme and Center Points
Feb 03, 2019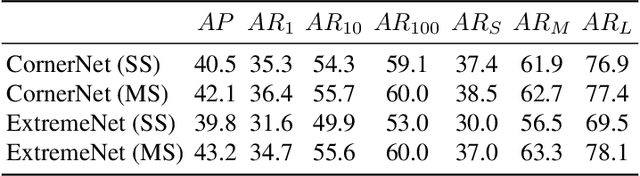
With the advent of deep learning, object detection drifted from a bottom-up to a top-down recognition problem. State of the art algorithms enumerate a near-exhaustive list of object locations and classify each into: object or not. In this paper, we show that bottom-up approaches still perform competitively. We detect four extreme points (top-most, left-most, bottom-most, right-most) and one center point of objects using a standard keypoint estimation network. We group the five keypoints into a bounding box if they are geometrically aligned. Object detection is then a purely appearance-based keypoint estimation problem, without region classification or implicit feature learning. The proposed method performs on-par with the state-of-the-art region based detection methods, with a bounding box AP of 43.2% on COCO test-dev. In addition, our estimated extreme points directly span a coarse octagonal mask, with a COCO Mask AP of 18.9%, much better than the Mask AP of vanilla bounding boxes. Extreme point guided segmentation further improves this to 34.6% Mask AP.
Fast Stochastic Variance Reduced Gradient Method with Momentum Acceleration for Machine Learning
Apr 17, 2017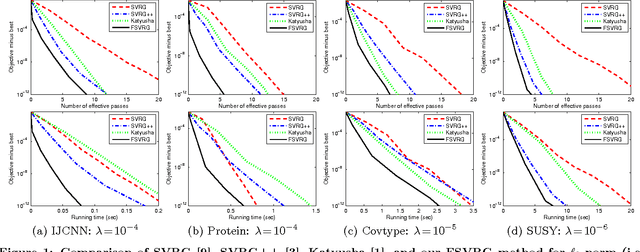

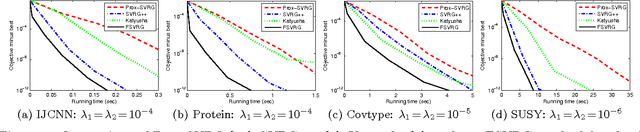
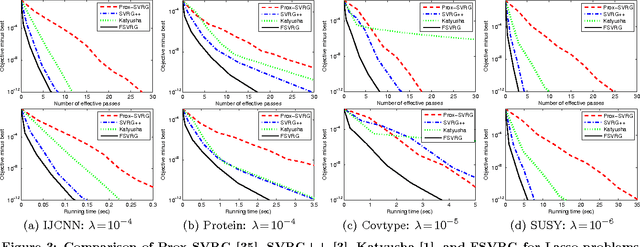
Recently, research on accelerated stochastic gradient descent methods (e.g., SVRG) has made exciting progress (e.g., linear convergence for strongly convex problems). However, the best-known methods (e.g., Katyusha) requires at least two auxiliary variables and two momentum parameters. In this paper, we propose a fast stochastic variance reduction gradient (FSVRG) method, in which we design a novel update rule with the Nesterov's momentum and incorporate the technique of growing epoch size. FSVRG has only one auxiliary variable and one momentum weight, and thus it is much simpler and has much lower per-iteration complexity. We prove that FSVRG achieves linear convergence for strongly convex problems and the optimal $\mathcal{O}(1/T^2)$ convergence rate for non-strongly convex problems, where $T$ is the number of outer-iterations. We also extend FSVRG to directly solve the problems with non-smooth component functions, such as SVM. Finally, we empirically study the performance of FSVRG for solving various machine learning problems such as logistic regression, ridge regression, Lasso and SVM. Our results show that FSVRG outperforms the state-of-the-art stochastic methods, including Katyusha.