 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Multi Agent Active Search
Jun 25, 2020
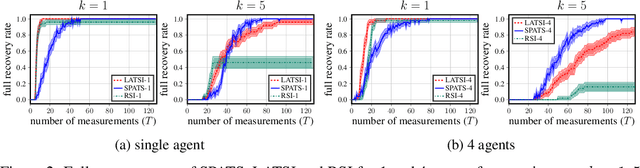
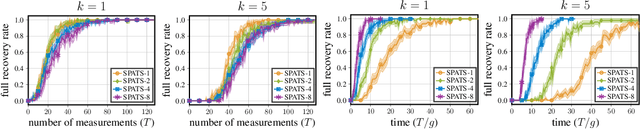
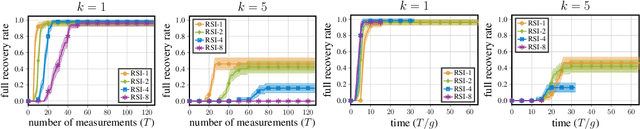
Active search refers to the problem of efficiently locating targets in an unknown environment by actively making data-collection decisions, and has many applications including detecting gas leaks, radiation sources or human survivors of disasters using aerial and/or ground robots (agents). Existing active search methods are in general only amenable to a single agent, or if they extend to multi agent they require a central control system to coordinate the actions of all agents. However, such control systems are often impractical in robotics applications. In this paper, we propose two distinct active search algorithms called SPATS (Sparse Parallel Asynchronous Thompson Sampling) and LATSI (LAplace Thompson Sampling with Information gain) that allow for multiple agents to independently make data-collection decisions without a central coordinator. Throughout we consider that targets are sparsely located around the environment in keeping with compressive sensing assumptions and its applicability in real world scenarios. Additionally, while most common search algorithms assume that agents can sense the entire environment (e.g. compressive sensing) or sense point-wise (e.g. Bayesian Optimization) at all times, we make a realistic assumption that each agent can only sense a contiguous region of space at a time. We provide simulation results as well as theoretical analysis to demonstrate the efficacy of our proposed algorithms.
Neural Dynamical Systems: Balancing Structure and Flexibility in Physical Prediction
Jun 23, 2020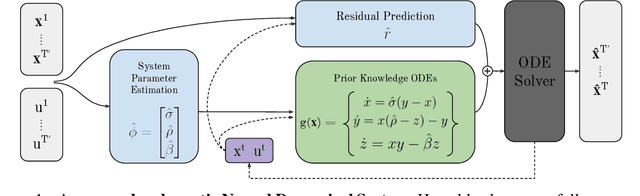
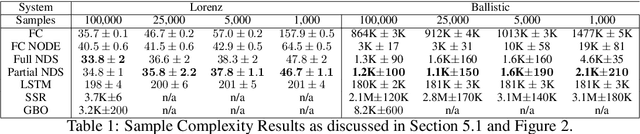
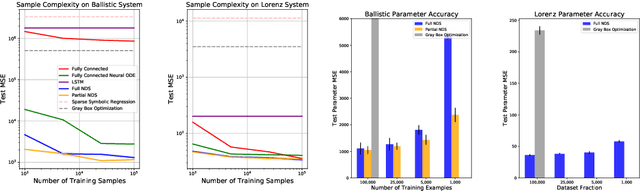

We introduce Neural Dynamical Systems (NDS), a method of learning dynamical models in various gray-box settings which incorporates prior knowledge in the form of systems of ordinary differential equations. NDS uses neural networks to estimate free parameters of the system, predicts residual terms, and numerically integrates over time to predict future states. A key insight is that many real dynamic systems of interest are hard to model because the dynamics may vary across rollouts. We mitigate this problem by taking a trajectory of prior states as the input to NDS and train it to re-estimate system parameters using the preceding trajectory. We find that NDS learns dynamics with higher accuracy and fewer samples than a variety of deep learning methods that do not incorporate the prior knowledge and methods from the system identification literature which do. We demonstrate these advantages first on synthetic dynamical systems and then on real data captured from deuterium shots from a nuclear fusion reactor.
Offline Contextual Bayesian Optimization for Nuclear Fusion
Jan 06, 2020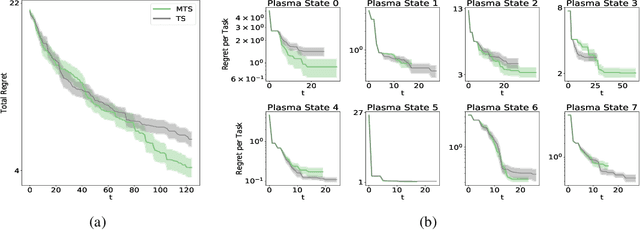
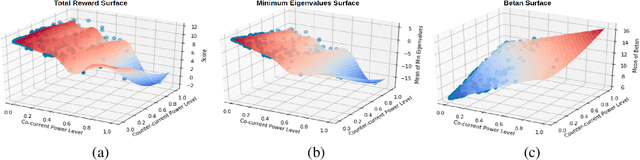
Nuclear fusion is regarded as the energy of the future since it presents the possibility of unlimited clean energy. One obstacle in utilizing fusion as a feasible energy source is the stability of the reaction. Ideally, one would have a controller for the reactor that makes actions in response to the current state of the plasma in order to prolong the reaction as long as possible. In this work, we make preliminary steps to learning such a controller. Since learning on a real world reactor is infeasible, we tackle this problem by attempting to learn optimal controls offline via a simulator, where the state of the plasma can be explicitly set. In particular, we introduce a theoretically grounded Bayesian optimization algorithm that recommends a state and action pair to evaluate at every iteration and show that this results in more efficient use of the simulator.
Human Driver Behavior Prediction based on UrbanFlow
Nov 09, 2019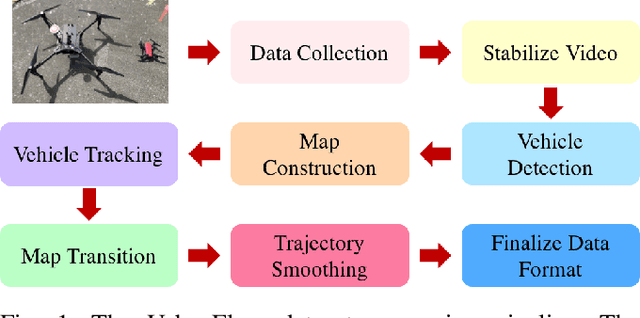
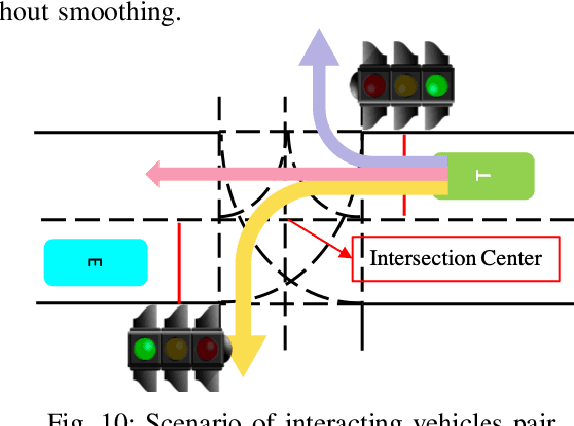
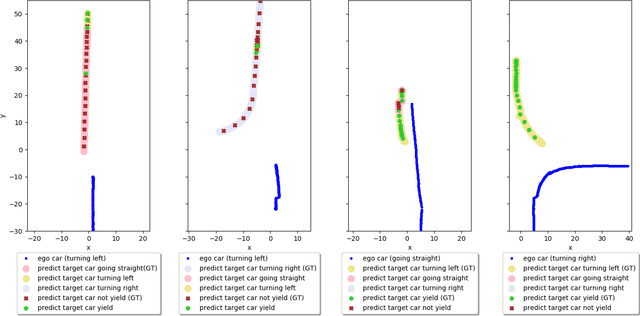
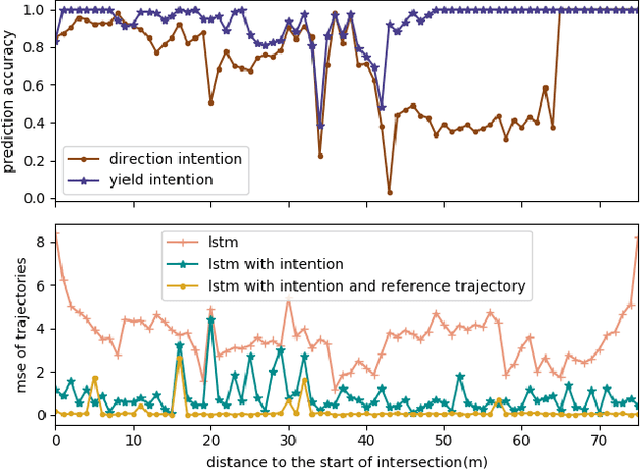
How autonomous vehicles and human drivers share public transportation systems is an important problem, as fully automatic transportation environments are still a long way off. Understanding human drivers' behavior can be beneficial for autonomous vehicle decision making and planning, especially when the autonomous vehicle is surrounded by human drivers who have various driving behaviors and patterns of interaction with other vehicles. In this paper, we propose an LSTM-based trajectory prediction method for human drivers which can help the autonomous vehicle make better decisions, especially in urban intersection scenarios. Meanwhile, in order to collect human drivers' driving behavior data in the urban scenario, we describe a system called UrbanFlow which includes the whole procedure from raw bird's-eye view data collection via drone to the final processed trajectories. The system is mainly intended for urban scenarios but can be extended to be used for any traffic scenarios.
Hierarchical Reinforcement Learning Method for Autonomous Vehicle Behavior Planning
Nov 09, 2019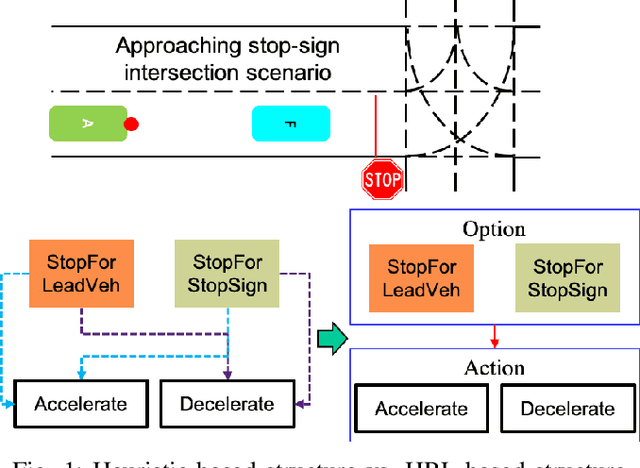
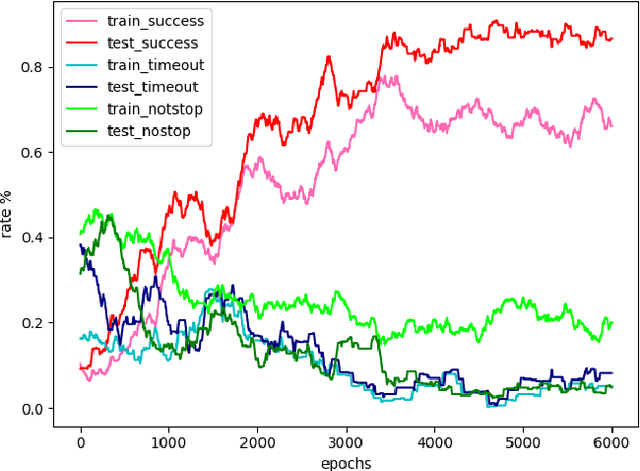
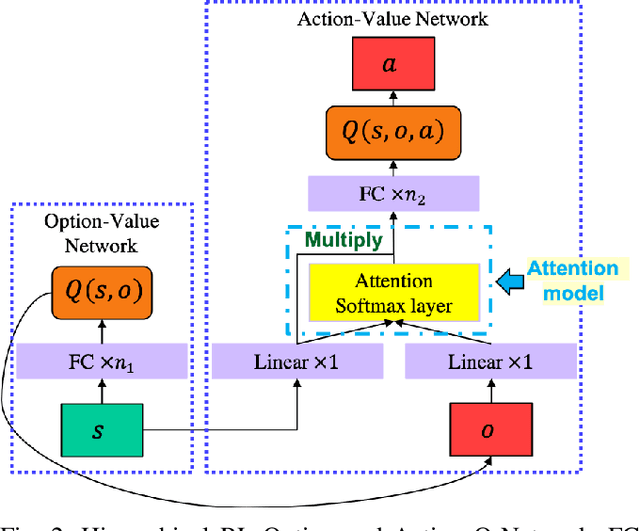
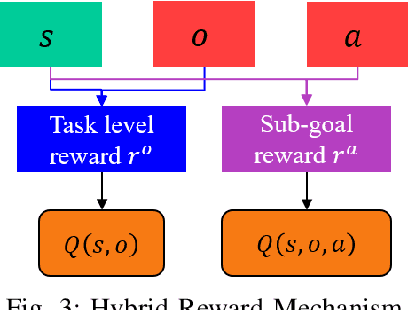
In this work, we propose a hierarchical reinforcement learning (HRL) structure which is capable of performing autonomous vehicle planning tasks in simulated environments with multiple sub-goals. In this hierarchical structure, the network is capable of 1) learning one task with multiple sub-goals simultaneously; 2) extracting attentions of states according to changing sub-goals during the learning process; 3) reusing the well-trained network of sub-goals for other similar tasks with the same sub-goals. The states are defined as processed observations which are transmitted from the perception system of the autonomous vehicle. A hybrid reward mechanism is designed for different hierarchical layers in the proposed HRL structure. Compared to traditional RL methods, our algorithm is more sample-efficient since its modular design allows reusing the policies of sub-goals across similar tasks. The results show that the proposed method converges to an optimal policy faster than traditional RL methods.
ChemBO: Bayesian Optimization of Small Organic Molecules with Synthesizable Recommendations
Aug 05, 2019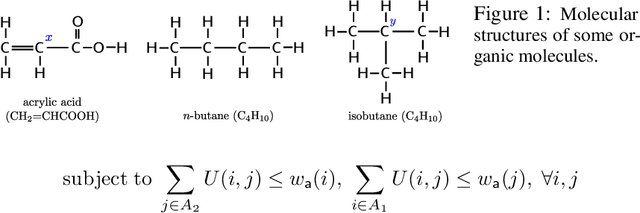

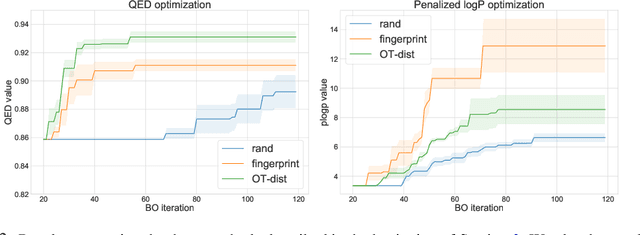
We describe ChemBO, a Bayesian Optimization framework for generating and optimizing organic molecules for desired molecular properties. This framework is useful in applications such as drug discovery, where an algorithm recommends new candidate molecules; these molecules first need to be synthesized and then tested for drug-like properties. The algorithm uses the results of past tests to recommend new ones so as to find good molecules efficiently. Most existing data-driven methods for this problem do not account for sample efficiency and/or fail to enforce realistic constraints on synthesizability. In this work, we explore existing kernels for molecules in the literature as well as propose a novel kernel which views a molecule as a graph. In ChemBO, we implement these kernels in a Gaussian process model. Then we explore the chemical space by traversing possible paths of molecular synthesis. Consequently, our approach provides a proposal synthesis path every time it recommends a new molecule to test, a crucial advantage when compared to existing methods. In our experiments, we demonstrate the efficacy of the proposed approach on several molecular optimization problems.
Deep Kinematic Models for Physically Realistic Prediction of Vehicle Trajectories
Aug 01, 2019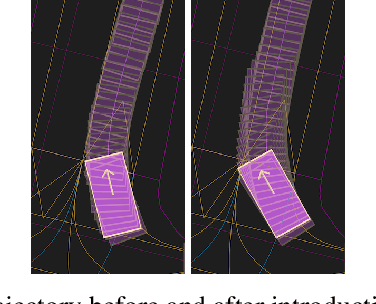
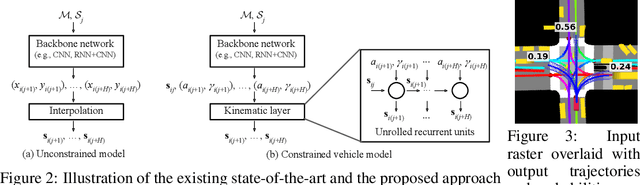
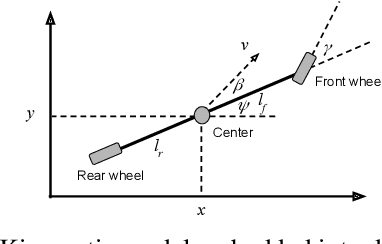
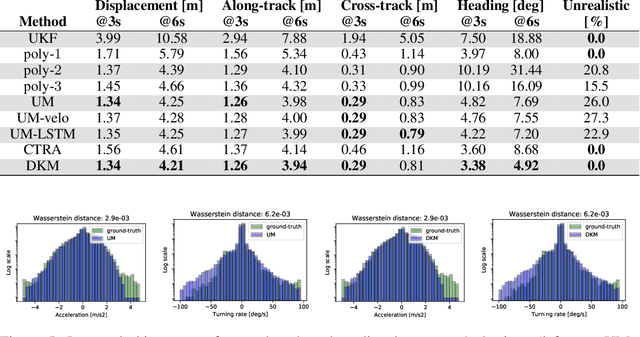
Self-driving vehicles (SDVs) hold great potential for improving traffic safety and are poised to positively affect the quality of life of millions of people. One of the critical aspects of the autonomous technology is understanding and predicting future movement of vehicles surrounding the SDV. This work presents a deep-learning-based method for physically realistic motion prediction of such traffic actors. Previous work did not explicitly encode physical realism and instead relied on the models to learn the laws of physics directly from the data, potentially resulting in implausible trajectory predictions. To account for this issue we propose a method that seamlessly combines ideas from the AI with physically grounded vehicle motion models. In this way we employ best of the both worlds, coupling powerful learning models with strong physical guarantees for their outputs. The proposed approach is general, being applicable to any type of learning method. Extensive experiments using deep convnets on large-scale, real-world data strongly indicate its benefits, outperforming the existing state-of-the-art.
Predicting Motion of Vulnerable Road Users using High-Definition Maps and Efficient ConvNets
Jun 20, 2019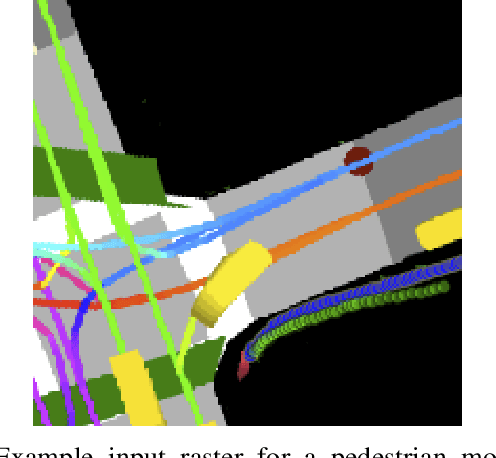
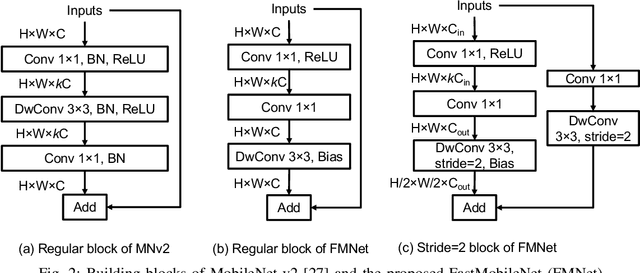
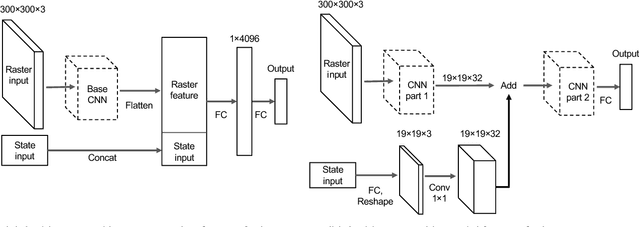
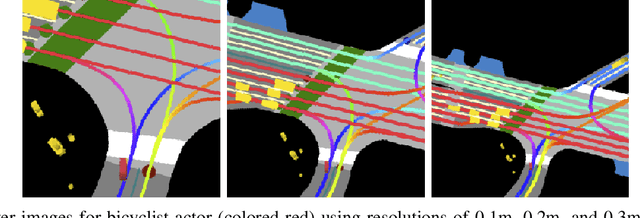
Following detection and tracking of traffic actors, prediction of their future motion is the next critical component of a self-driving vehicle (SDV) technology, allowing the SDV to operate safely and efficiently in its environment. This is particularly important when it comes to vulnerable road users (VRUs), such as pedestrians and bicyclists. These actors need to be handled with special care due to an increased risk of injury, as well as the fact that their behavior is less predictable than that of motorized actors. To address this issue, in this paper we present a deep learning-based method for predicting VRU movement, where we rasterize high-definition maps and actor's surroundings into bird's-eye view image used as an input to deep convolutional networks. In addition, we propose a fast architecture suitable for real-time inference, and present a detailed ablation study of various rasterization choices. The results strongly indicate benefits of using the proposed approach for motion prediction of VRUs, both in terms of accuracy and latency.
Tuning Hyperparameters without Grad Students: Scalable and Robust Bayesian Optimisation with Dragonfly
Mar 15, 2019
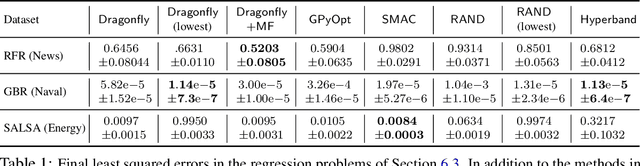
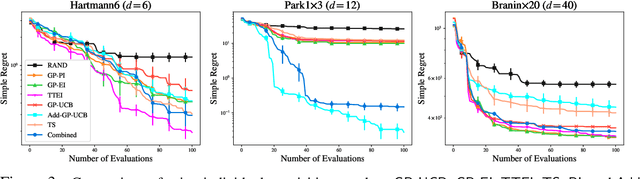
Bayesian Optimisation (BO), refers to a suite of techniques for global optimisation of expensive black box functions, which use introspective Bayesian models of the function to efficiently find the optimum. While BO has been applied successfully in many applications, modern optimisation tasks usher in new challenges where conventional methods fail spectacularly. In this work, we present Dragonfly, an open source Python library for scalable and robust BO. Dragonfly incorporates multiple recently developed methods that allow BO to be applied in challenging real world settings; these include better methods for handling higher dimensional domains, methods for handling multi-fidelity evaluations when cheap approximations of an expensive function are available, methods for optimising over structured combinatorial spaces, such as the space of neural network architectures, and methods for handling parallel evaluations. Additionally, we develop new methodological improvements in BO for selecting the Bayesian model, selecting the acquisition function, and optimising over complex domains with different variable types and additional constraints. We compare Dragonfly to a suite of other packages and algorithms for global optimisation and demonstrate that when the above methods are integrated, they enable significant improvements in the performance of BO. The Dragonfly library is available at dragonfly.github.io.
Multimodal Trajectory Predictions for Autonomous Driving using Deep Convolutional Networks
Mar 01, 2019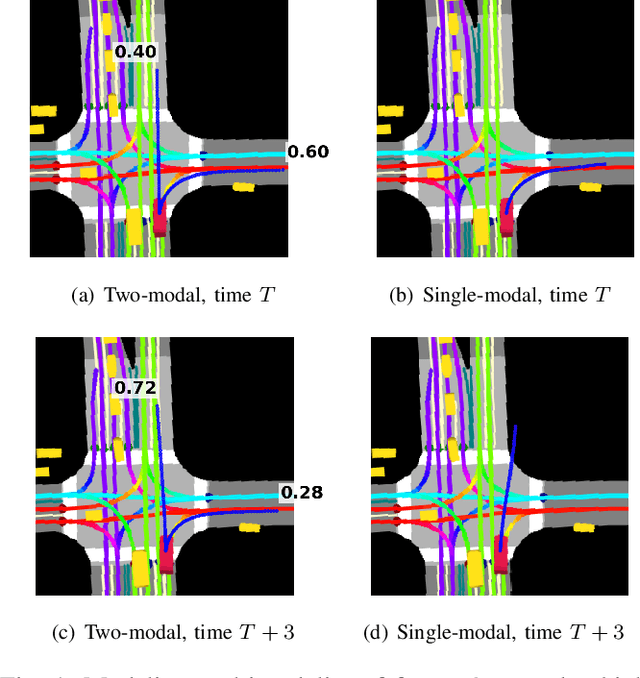
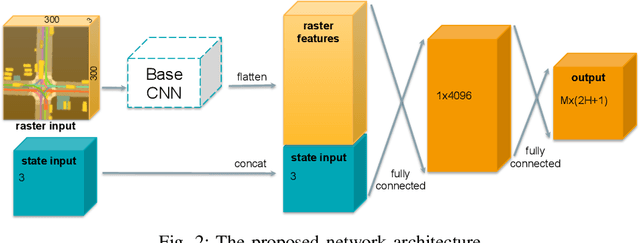
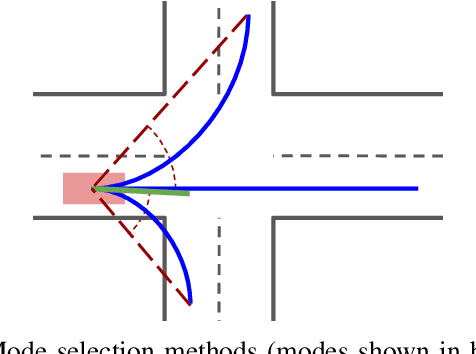
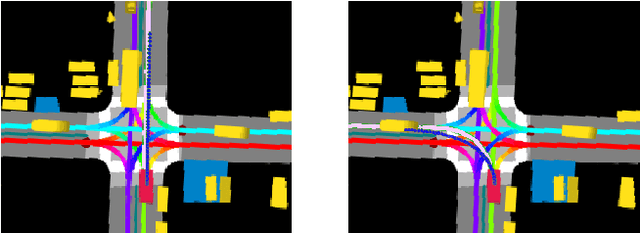
Autonomous driving presents one of the largest problems that the robotics and artificial intelligence communities are facing at the moment, both in terms of difficulty and potential societal impact. Self-driving vehicles (SDVs) are expected to prevent road accidents and save millions of lives while improving the livelihood and life quality of many more. However, despite large interest and a number of industry players working in the autonomous domain, there still remains more to be done in order to develop a system capable of operating at a level comparable to best human drivers. One reason for this is high uncertainty of traffic behavior and large number of situations that an SDV may encounter on the roads, making it very difficult to create a fully generalizable system. To ensure safe and efficient operations, an autonomous vehicle is required to account for this uncertainty and to anticipate a multitude of possible behaviors of traffic actors in its surrounding. We address this critical problem and present a method to predict multiple possible trajectories of actors while also estimating their probabilities. The method encodes each actor's surrounding context into a raster image, used as input by deep convolutional networks to automatically derive relevant features for the task. Following extensive offline evaluation and comparison to state-of-the-art baselines, the method was successfully tested on SDVs in closed-course tests.