 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide-and-Rule: Self-Supervised Learning for Survival Analysis in Colorectal Cancer
Jul 07, 2020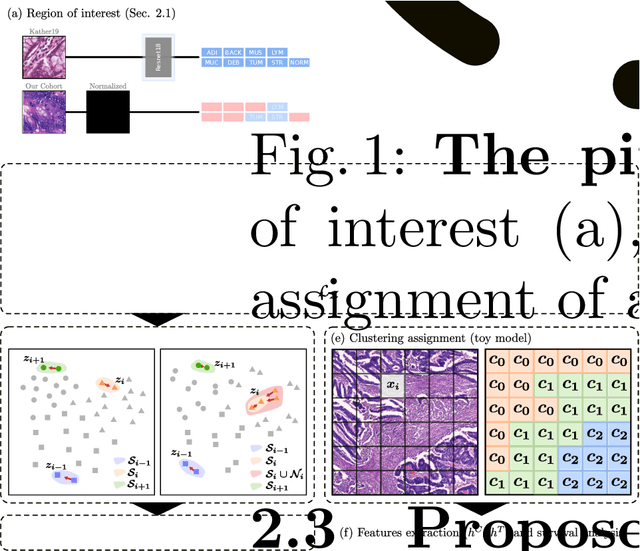
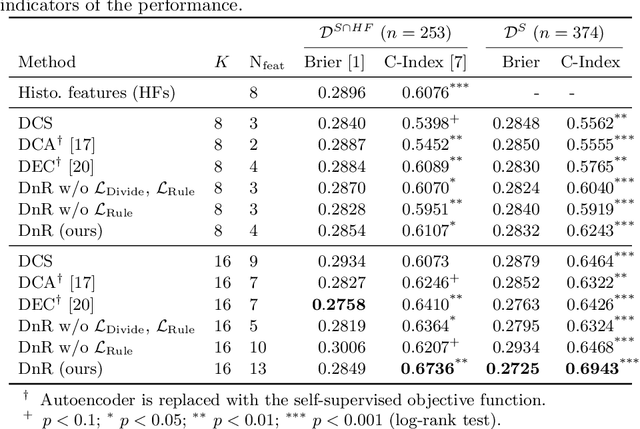
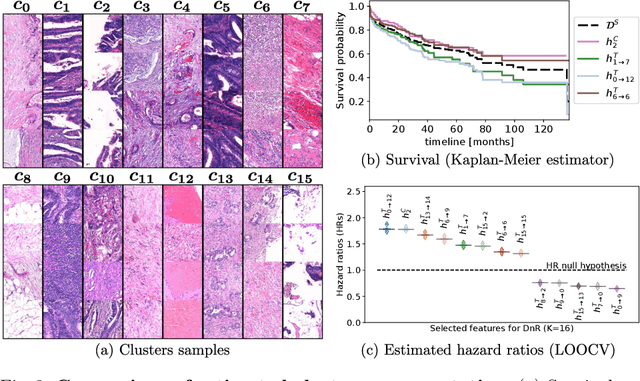
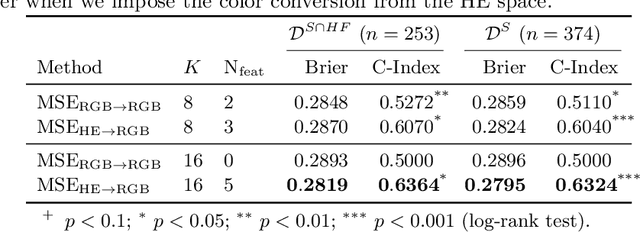
With the long-term rapid increase in incidences of colorectal cancer (CRC), there is an urgent clinical need to improve risk stratification. The conventional pathology report is usually limited to only a few histopathological features. However, most of the tumor microenvironments used to describe patterns of aggressive tumor behavior are ignored. In this work, we aim to learn histopathological patterns within cancerous tissue regions that can be used to improve prognostic stratification for colorectal cancer. To do so, we propose a self-supervised learning method that jointly learns a representation of tissue regions as well as a metric of the clustering to obtain their underlying patterns. These histopathological patterns are then used to represent the interaction between complex tissues and predict clinical outcomes directly. We furthermore show that the proposed approach can benefit from linear predictors to avoid overfitting in patient outcomes predictions. To this end, we introduce a new well-characterized clinicopathological dataset, including a retrospective collective of 374 patients, with their survival time and treatment information. Histomorphological clusters obtained by our method are evaluated by training survival models. The experimental results demonstrate statistically significant patient stratification, and our approach outperformed the state-of-the-art deep clustering methods.
Benefitting from Bicubically Down-Sampled Images for Learning Real-World Image Super-Resolution
Jul 06, 2020
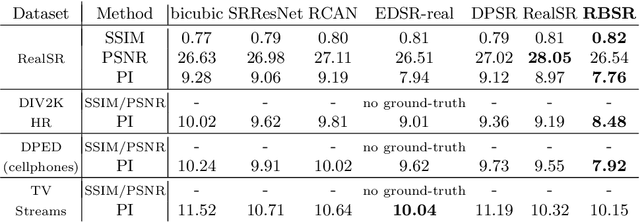
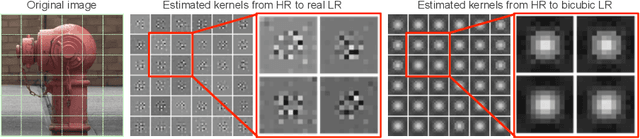
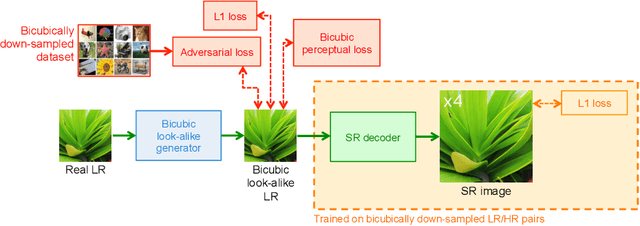
Super-resolution (SR) has traditionally been based on pairs of high-resolution images (HR) and their low-resolution (LR) counterparts obtained artificially with bicubic downsampling. However, in real-world SR, there is a large variety of realistic image degradations and analytically modeling these realistic degradations can prove quite difficult. In this work, we propose to handle real-world SR by splitting this ill-posed problem into two comparatively more well-posed steps. First, we train a network to transform real LR images to the space of bicubically downsampled images in a supervised manner, by using both real LR/HR pairs and synthetic pairs. Second, we take a generic SR network trained on bicubically downsampled images to super-resolve the transformed LR image. The first step of the pipeline addresses the problem by registering the large variety of degraded images to a common, well understood space of images. The second step then leverages the already impressive performance of SR on bicubically downsampled images, sidestepping the issues of end-to-end training on datasets with many different image degradations. We demonstrate the effectiveness of our proposed method by comparing it to recent methods in real-world SR and show that our proposed approach outperforms the state-of-the-art works in terms of both qualitative and quantitative results, as well as results of an extensive user study conducted on several real image datasets.
HACT-Net: A Hierarchical Cell-to-Tissue Graph Neural Network for Histopathological Image Classification
Jul 01, 2020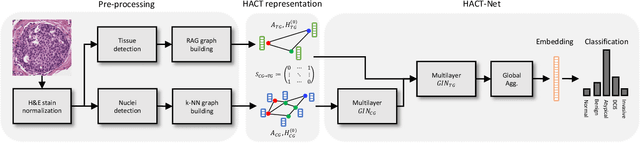
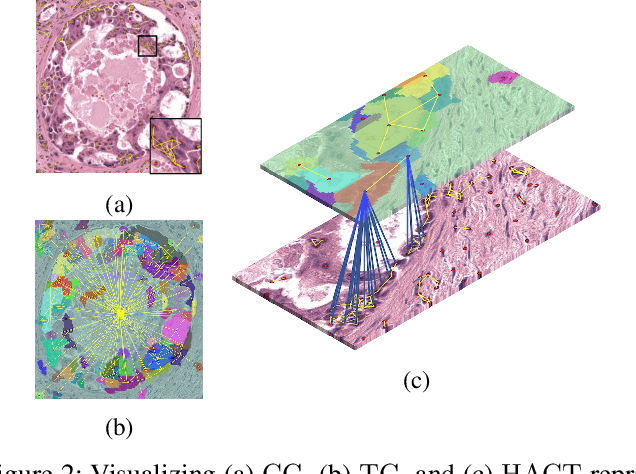
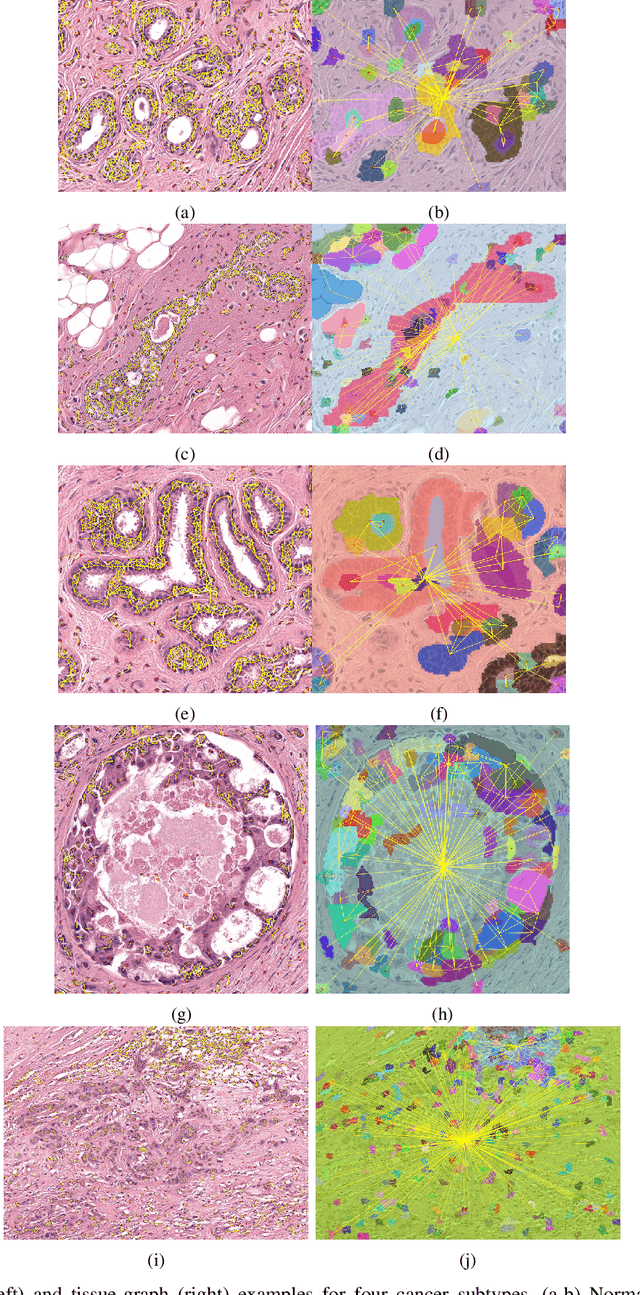
Cancer diagnosis, prognosis, and therapeutic response prediction are heavily influenced by the relationship between the histopathological structures and the function of the tissue. Recent approaches acknowledging the structure-function relationship, have linked the structural and spatial patterns of cell organization in tissue via cell-graphs to tumor grades. Though cell organization is imperative, it is insufficient to entirely represent the histopathological structure. We propose a novel hierarchical cell-to-tissue-graph (HACT) representation to improve the structural depiction of the tissue. It consists of a low-level cell-graph, capturing cell morphology and interactions, a high-level tissue-graph, capturing morphology and spatial distribution of tissue parts, and cells-to-tissue hierarchies, encoding the relative spatial distribution of the cells with respect to the tissue distribution. Further, a hierarchical graph neural network (HACT-Net) is proposed to efficiently map the HACT representations to histopathological breast cancer subtypes. We assess the methodology on a large set of annotated tissue regions of interest from H\&E stained breast carcinoma whole-slides. Upon evaluation, the proposed method outperformed recent convolutional neural network and graph neural network approaches for breast cancer multi-class subtyping. The proposed entity-based topological analysis is more inline with the pathological diagnostic procedure of the tissue. It provides more command over the tissue modelling, therefore encourages the further inclusion of pathological priors into task-specific tissue representation.
Towards Explainable Graph Representations in Digital Pathology
Jul 01, 2020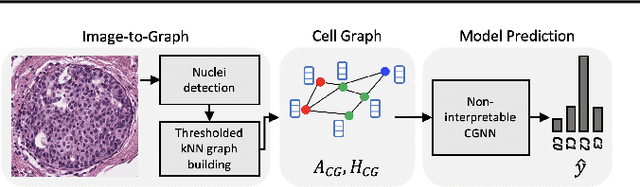
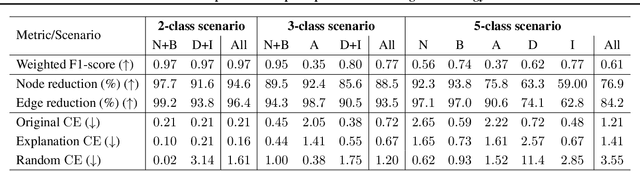
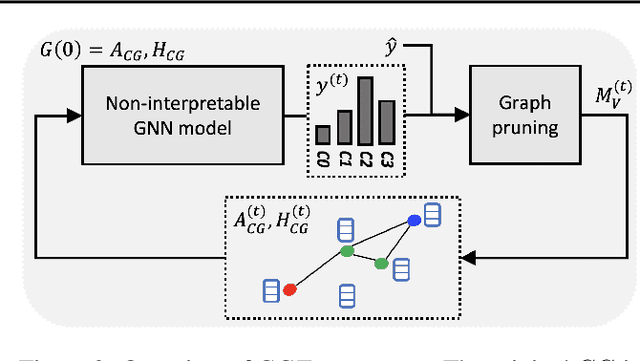
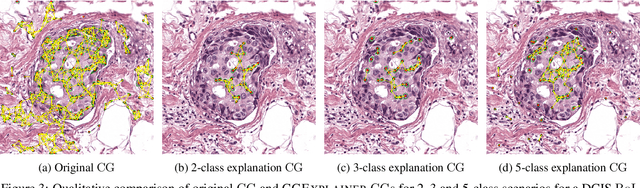
Explainability of machine learning (ML) techniques in digital pathology (DP) is of great significance to facilitate their wide adoption in clinics. Recently, graph techniques encoding relevant biological entities have been employed to represent and assess DP images. Such paradigm shift from pixel-wise to entity-wise analysis provides more control over concept representation. In this paper, we introduce a post-hoc explainer to derive compact per-instance explanations emphasizing diagnostically important entities in the graph. Although we focus our analyses to cells and cellular interactions in breast cancer subtyping, the proposed explainer is generic enough to be extended to other topological representations in DP. Qualitative and quantitative analyses demonstrate the efficacy of the explainer in generating comprehensive and compact explanations.
Pathological Retinal Region Segmentation From OCT Images Using Geometric Relation Based Augmentation
Apr 03, 2020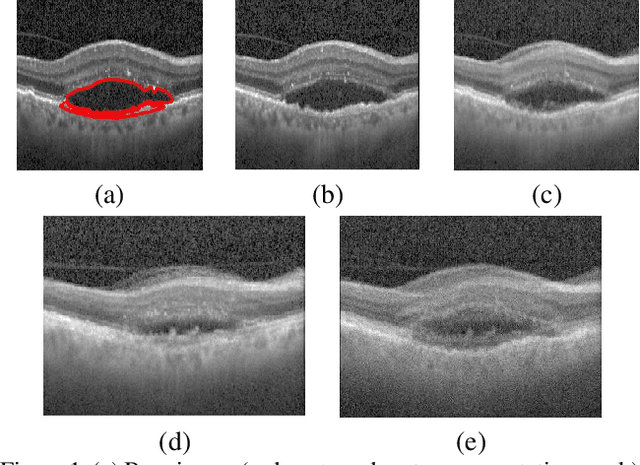
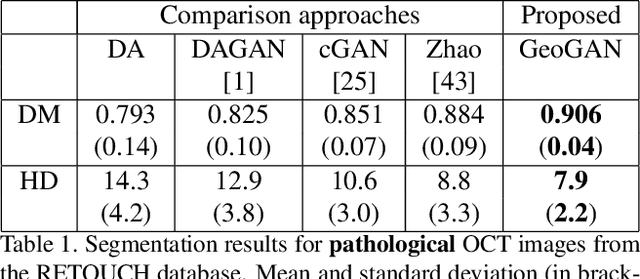
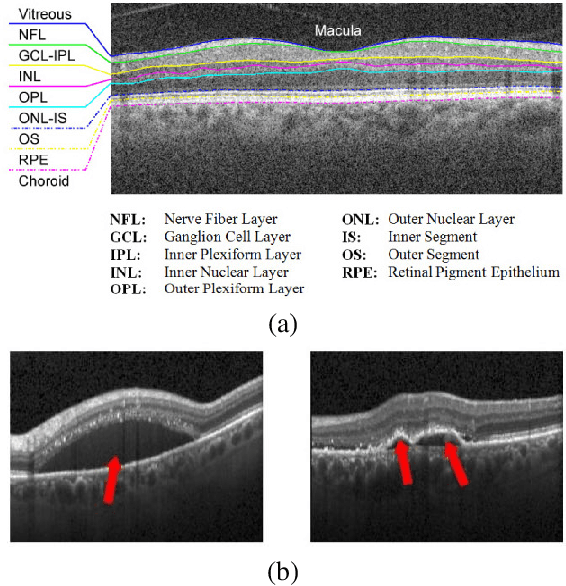
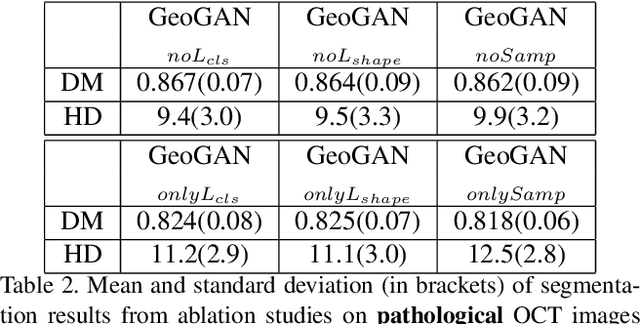
Medical image segmentation is an important task for computer aided diagnosis. Pixelwise manual annotations of large datasets require high expertise and is time consuming. Conventional data augmentations have limited benefit by not fully representing the underlying distribution of the training set, thus affecting model robustness when tested on images captured from different sources. Prior work leverages synthetic images for data augmentation ignoring the interleaved geometric relationship between different anatomical labels. We propose improvements over previous GAN-based medical image synthesis methods by jointly encoding the intrinsic relationship of geometry and shape. Latent space variable sampling results in diverse generated images from a base image and improves robustness. Given those augmented images generated by our method, we train the segmentation network to enhance the segmentation performance of retinal optical coherence tomography (OCT) images. The proposed method outperforms state-of-the-art segmentation methods on the public RETOUCH dataset having images captured from different acquisition procedures. Ablation studies and visual analysis also demonstrate benefits of integrating geometry and diversity.
Revisiting Few-Shot Learning for Facial Expression Recognition
Dec 11, 2019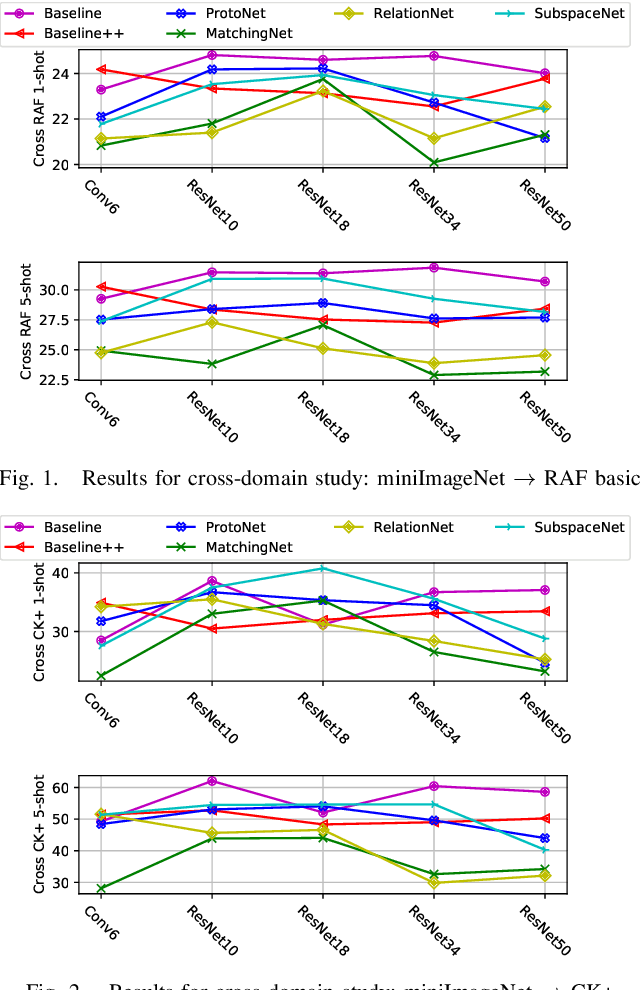
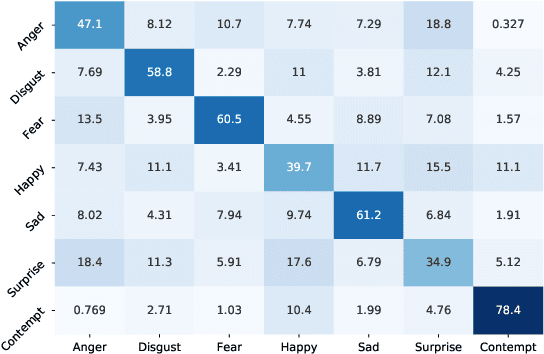
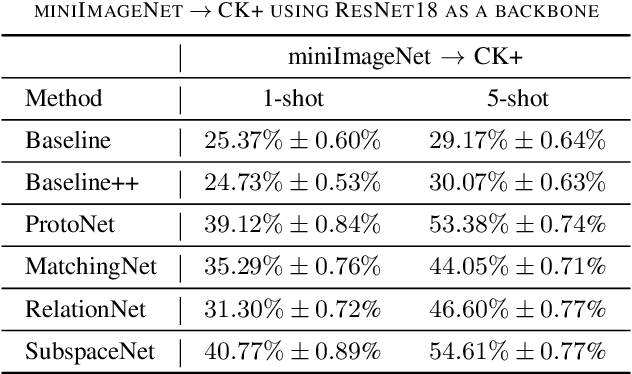
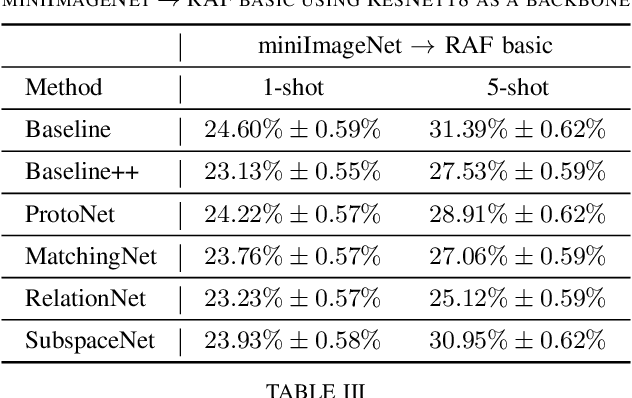
Most of the existing deep neural nets on automatic facial expression recognition focus on a set of predefined emotion classes, where the amount of training data has the biggest impact on performance. However, in the standard setting over-parameterised neural networks are not amenable for learning from few samples as they can quickly over-fit. In addition, these approaches do not have such a strong generalisation ability to identify a new category, where the data of each category is too limited and significant variations exist in the expression within the same semantic category. We embrace these challenges and formulate the problem as a low-shot learning, where once the base classifier is deployed, it must rapidly adapt to recognise novel classes using a few samples. In this paper, we revisit and compare existing few-shot learning methods for the low-shot facial expression recognition in terms of their generalisation ability via episode-training. In particular, we extend our analysis on the cross-domain generalisation, where training and test tasks are not drawn from the same distribution. We demonstrate the efficacy of low-shot learning methods through extensive experiments.
SROBB: Targeted Perceptual Loss for Single Image Super-Resolution
Aug 20, 2019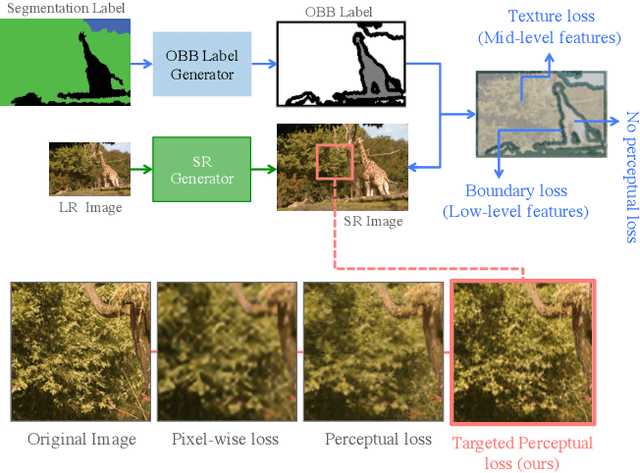
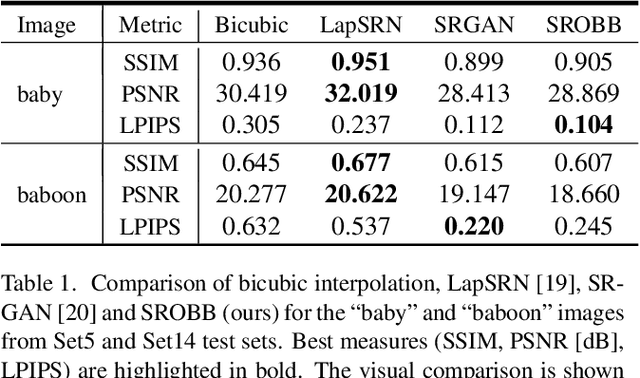

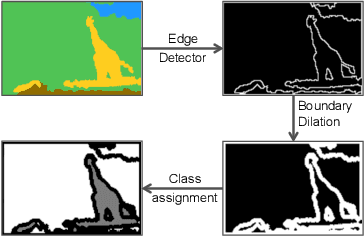
By benefiting from perceptual losses, recent studies have improved significantly the performance of the super-resolution task, where a high-resolution image is resolved from its low-resolution counterpart. Although such objective functions generate near-photorealistic results, their capability is limited, since they estimate the reconstruction error for an entire image in the same way, without considering any semantic information. In this paper, we propose a novel method to benefit from perceptual loss in a more objective way. We optimize a deep network-based decoder with a targeted objective function that penalizes images at different semantic levels using the corresponding terms. In particular, the proposed method leverages our proposed OBB (Object, Background and Boundary) labels, generated from segmentation labels, to estimate a suitable perceptual loss for boundaries, while considering texture similarity for backgrounds. We show that our proposed approach results in more realistic textures and sharper edges, and outperforms other state-of-the-art algorithms in terms of both qualitative results on standard benchmarks and results of extensive user studies.
Benefiting from Multitask Learning to Improve Single Image Super-Resolution
Jul 29, 2019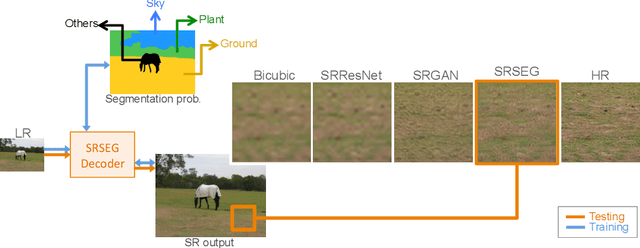
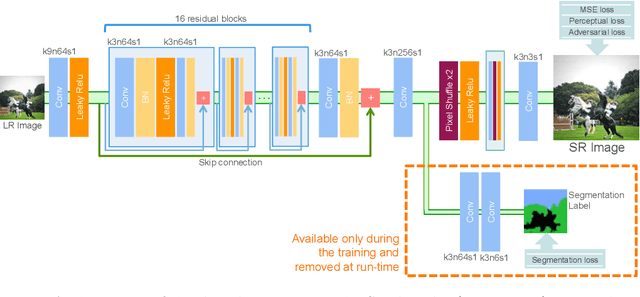
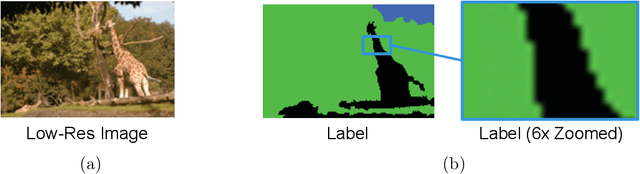
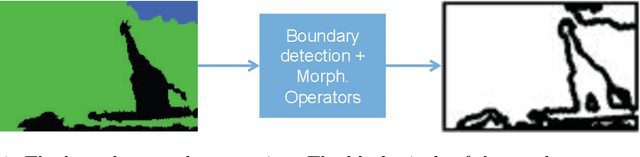
Despite significant progress toward super resolving more realistic images by deeper convolutional neural networks (CNNs), reconstructing fine and natural textures still remains a challenging problem. Recent works on single image super resolution (SISR) are mostly based on optimizing pixel and content wise similarity between recovered and high-resolution (HR) images and do not benefit from recognizability of semantic classes. In this paper, we introduce a novel approach using categorical information to tackle the SISR problem; we present a decoder architecture able to extract and use semantic information to super-resolve a given image by using multitask learning, simultaneously for image super-resolution and semantic segmentation. To explore categorical information during training, the proposed decoder only employs one shared deep network for two task-specific output layers. At run-time only layers resulting HR image are used and no segmentation label is required. Extensive perceptual experiments and a user study on images randomly selected from COCO-Stuff dataset demonstrate the effectiveness of our proposed method and it outperforms the state-of-the-art methods.
Exploring Factors for Improving Low Resolution Face Recognition
Jul 25, 2019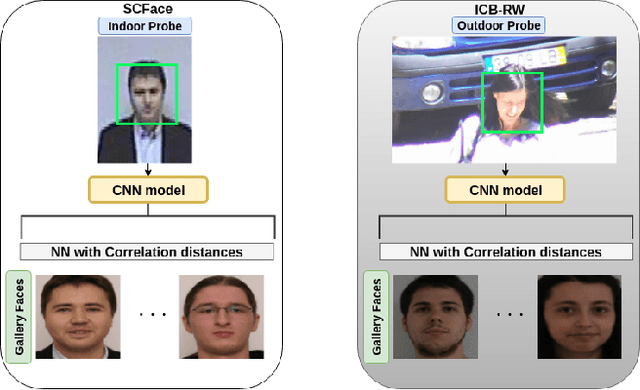
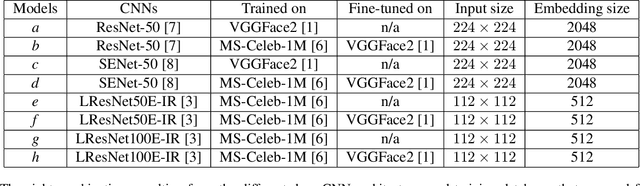

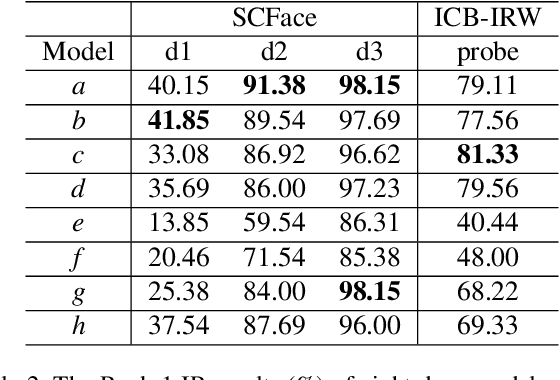
State-of-the-art deep face recognition approaches report near perfect performance on popular benchmarks, e.g., Labeled Faces in the Wild. However, their performance deteriorates significantly when they are applied on low quality images, such as those acquired by surveillance cameras. A further challenge for low resolution face recognition for surveillance applications is the matching of recorded low resolution probe face images with high resolution reference images, which could be the case in watchlist scenarios. In this paper, we have addressed these problems and investigated the factors that would contribute to the identification performance of the state-of-the-art deep face recognition models when they are applied to low resolution face recognition under mismatched conditions. We have observed that the following factors affect performance in a positive way: appearance variety and resolution distribution of the training dataset, resolution matching between the gallery and probe images, and the amount of information included in the probe images. By leveraging this information, we have utilized deep face models trained on MS-Celeb-1M and fine-tuned on VGGFace2 dataset and achieved state-of-the-art accuracies on the SCFace and ICB-RW benchmarks, even without using any training data from the datasets of these benchmarks.
FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents
May 27, 2019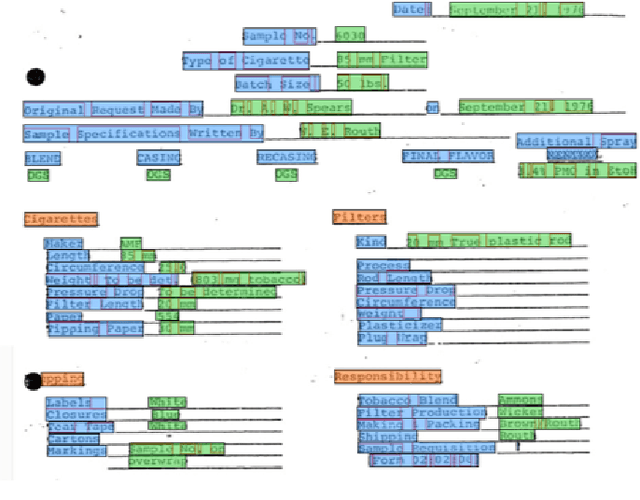
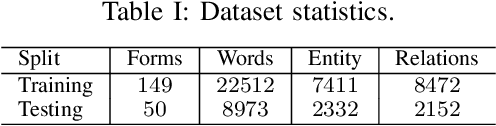

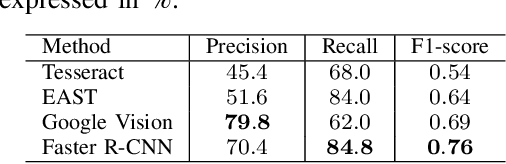
In this paper, we present a new dataset for Form Understanding in Noisy Scanned Documents (FUNSD). Form Understanding (FoUn) aims at extracting and structuring the textual content of forms. The dataset comprises 200 fully annotated real scanned forms. The documents are noisy and exhibit large variabilities in their representation making FoUn a challenging task. The proposed dataset can be used for various tasks including text detection, optical character recognition (OCR), spatial layout analysis and entity labeling/linking. To the best of our knowledge this is the first publicly available dataset with comprehensive annotations addressing the FoUn task. We also present a set of baselines and introduce metrics to evaluate performance on the FUNSD dataset. The FUNSD dataset can be downloaded at https://guillaumejaume.github. io/FUNSD/.