 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgeplingo: A system for probabilistic reasoning in clingo based on lpmln
Jun 23, 2022

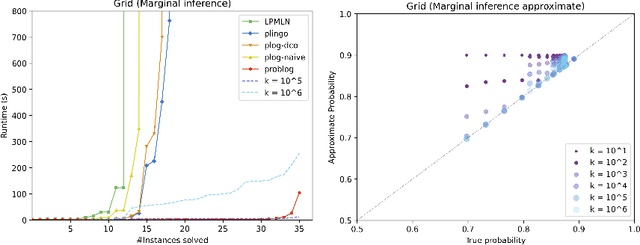
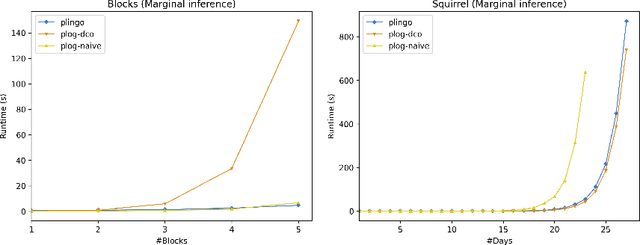
We present plingo, an extension of the ASP system clingo with various probabilistic reasoning modes. Plingo is centered upon LP^MLN, a probabilistic extension of ASP based on a weight scheme from Markov Logic. This choice is motivated by the fact that the core probabilistic reasoning modes can be mapped onto optimization problems and that LP^MLN may serve as a middle-ground formalism connecting to other probabilistic approaches. As a result, plingo offers three alternative frontends, for LP^MLN, P-log, and ProbLog. The corresponding input languages and reasoning modes are implemented by means of clingo's multi-shot and theory solving capabilities. The core of plingo amounts to a re-implementation of LP^MLN in terms of modern ASP technology, extended by an approximation technique based on a new method for answer set enumeration in the order of optimality. We evaluate plingo's performance empirically by comparing it to other probabilistic systems.
AutoAvatar: Autoregressive Neural Fields for Dynamic Avatar Modeling
Mar 25, 2022
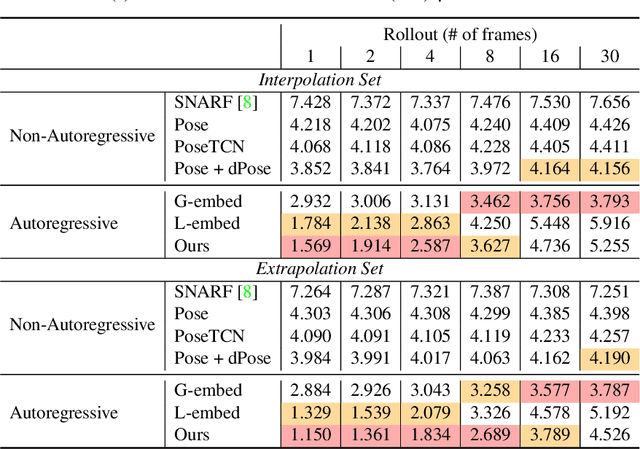
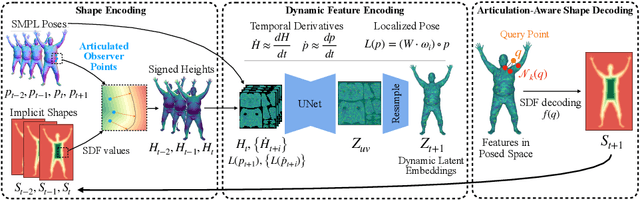
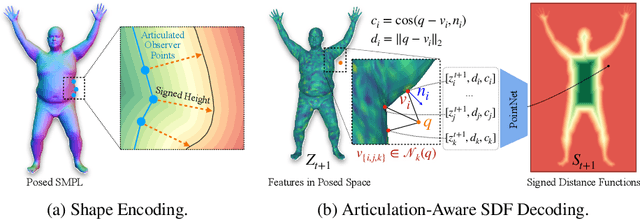
Neural fields such as implicit surfaces have recently enabled avatar modeling from raw scans without explicit temporal correspondences. In this work, we exploit autoregressive modeling to further extend this notion to capture dynamic effects, such as soft-tissue deformations. Although autoregressive models are naturally capable of handling dynamics, it is non-trivial to apply them to implicit representations, as explicit state decoding is infeasible due to prohibitive memory requirements. In this work, for the first time, we enable autoregressive modeling of implicit avatars. To reduce the memory bottleneck and efficiently model dynamic implicit surfaces, we introduce the notion of articulated observer points, which relate implicit states to the explicit surface of a parametric human body model. We demonstrate that encoding implicit surfaces as a set of height fields defined on articulated observer points leads to significantly better generalization compared to a latent representation. The experiments show that our approach outperforms the state of the art, achieving plausible dynamic deformations even for unseen motions. https://zqbai-jeremy.github.io/autoavatar
Embodied Hands: Modeling and Capturing Hands and Bodies Together
Jan 07, 2022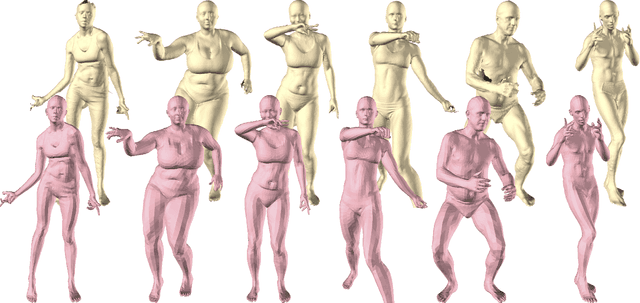
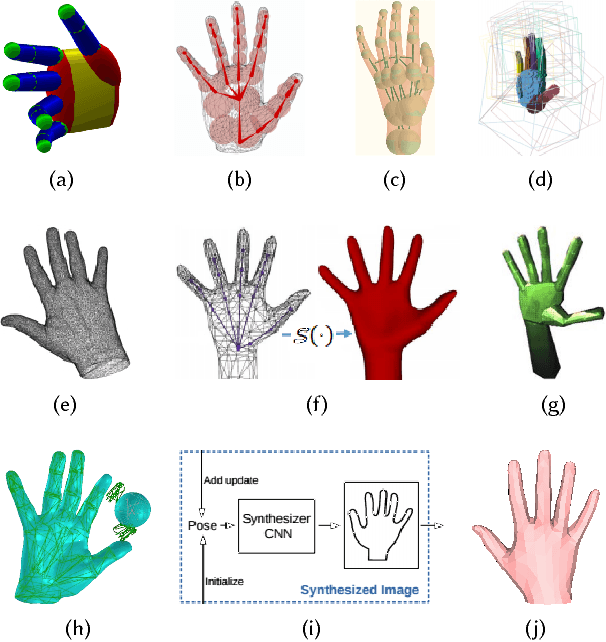
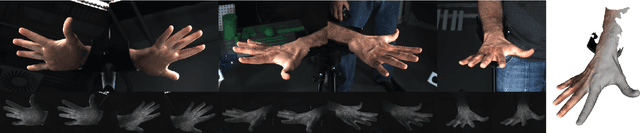
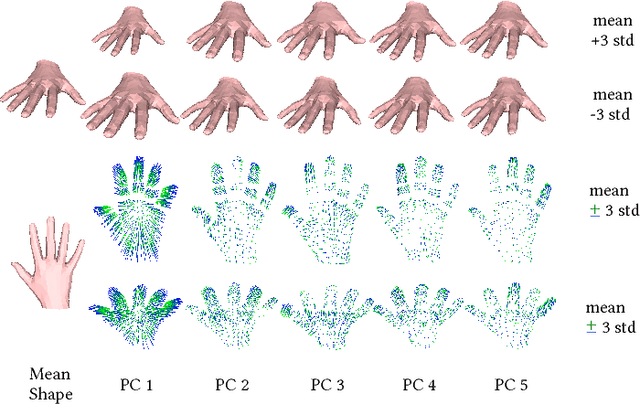
Humans move their hands and bodies together to communicate and solve tasks. Capturing and replicating such coordinated activity is critical for virtual characters that behave realistically. Surprisingly, most methods treat the 3D modeling and tracking of bodies and hands separately. Here we formulate a model of hands and bodies interacting together and fit it to full-body 4D sequences. When scanning or capturing the full body in 3D, hands are small and often partially occluded, making their shape and pose hard to recover. To cope with low-resolution, occlusion, and noise, we develop a new model called MANO (hand Model with Articulated and Non-rigid defOrmations). MANO is learned from around 1000 high-resolution 3D scans of hands of 31 subjects in a wide variety of hand poses. The model is realistic, low-dimensional, captures non-rigid shape changes with pose, is compatible with standard graphics packages, and can fit any human hand. MANO provides a compact mapping from hand poses to pose blend shape corrections and a linear manifold of pose synergies. We attach MANO to a standard parameterized 3D body shape model (SMPL), resulting in a fully articulated body and hand model (SMPL+H). We illustrate SMPL+H by fitting complex, natural, activities of subjects captured with a 4D scanner. The fitting is fully automatic and results in full body models that move naturally with detailed hand motions and a realism not seen before in full body performance capture. The models and data are freely available for research purposes in our website (http://mano.is.tue.mpg.de).
* SIGGRAPH ASIA 2017
Answer Set Programming Made Easy
Nov 24, 2021We take up an idea from the folklore of Answer Set Programming, namely that choices, integrity constraints along with a restricted rule format is sufficient for Answer Set Programming. We elaborate upon the foundations of this idea in the context of the logic of Here-and-There and show how it can be derived from the logical principle of extension by definition. We then provide an austere form of logic programs that may serve as a normalform for logic programs similar to conjunctive normalform in classical logic. Finally, we take the key ideas and propose a modeling methodology for ASP beginners and illustrate how it can be used.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021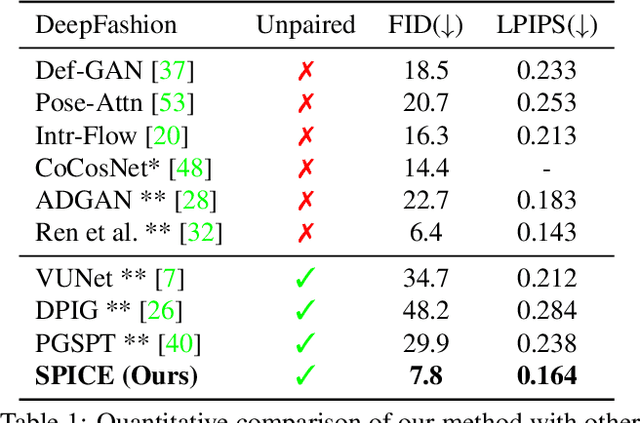
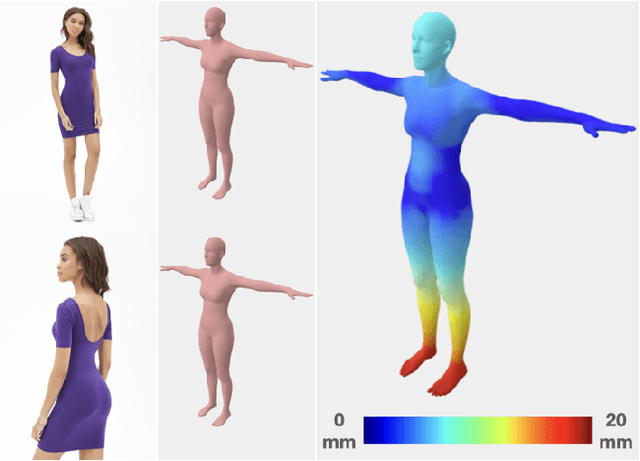

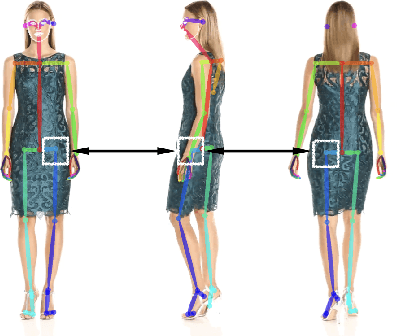
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
Planning with Incomplete Information in Quantified Answer Set Programming
Aug 13, 2021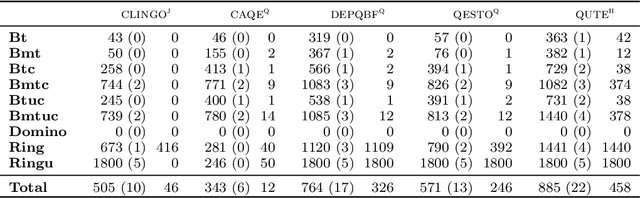
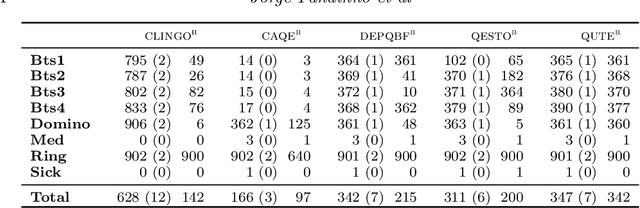
We present a general approach to planning with incomplete information in Answer Set Programming (ASP). More precisely, we consider the problems of conformant and conditional planning with sensing actions and assumptions. We represent planning problems using a simple formalism where logic programs describe the transition function between states, the initial states and the goal states. For solving planning problems, we use Quantified Answer Set Programming (QASP), an extension of ASP with existential and universal quantifiers over atoms that is analogous to Quantified Boolean Formulas (QBFs). We define the language of quantified logic programs and use it to represent the solutions to different variants of conformant and conditional planning. On the practical side, we present a translation-based QASP solver that converts quantified logic programs into QBFs and then executes a QBF solver, and we evaluate experimentally the approach on conformant and conditional planning benchmarks. Under consideration for acceptance in TPLP.
Learning First-Order Representations for Planning from Black-Box States: New Results
May 23, 2021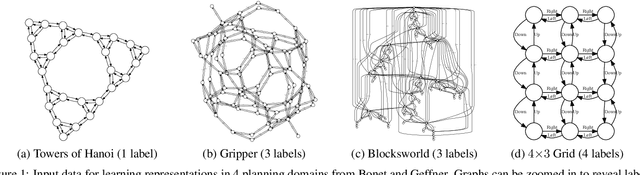
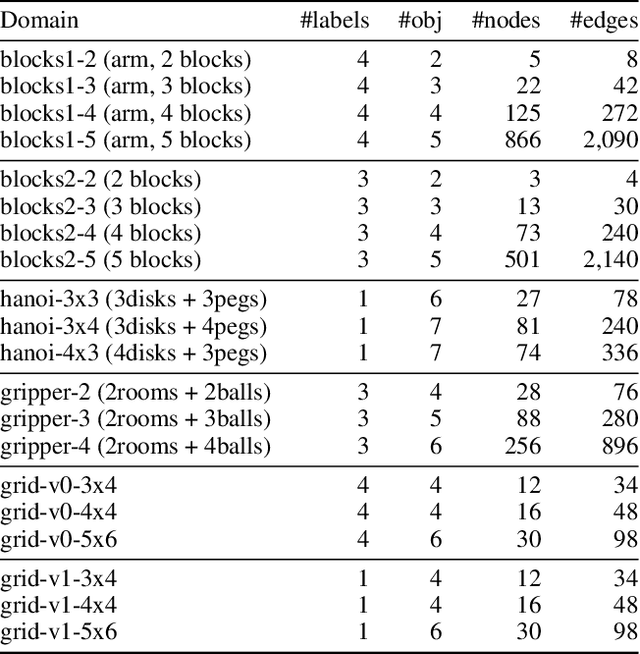

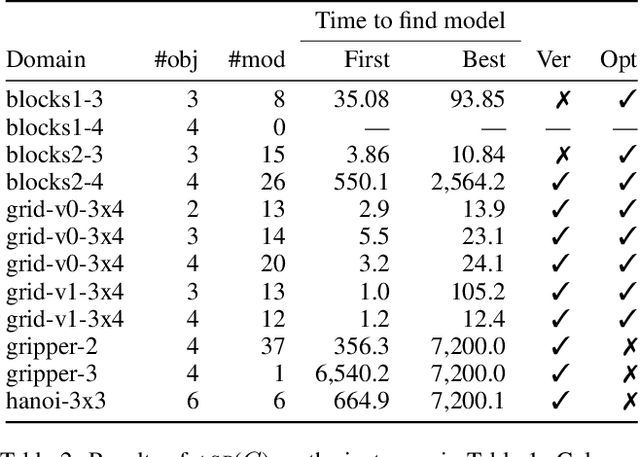
Recently Bonet and Geffner have shown that first-order representations for planning domains can be learned from the structure of the state space without any prior knowledge about the action schemas or domain predicates. For this, the learning problem is formulated as the search for a simplest first-order domain description D that along with information about instances I_i (number of objects and initial state) determine state space graphs G(P_i) that match the observed state graphs G_i where P_i = (D, I_i). The search is cast and solved approximately by means of a SAT solver that is called over a large family of propositional theories that differ just in the parameters encoding the possible number of action schemas and domain predicates, their arities, and the number of objects. In this work, we push the limits of these learners by moving to an answer set programming (ASP) encoding using the CLINGO system. The new encodings are more transparent and concise, extending the range of possible models while facilitating their exploration. We show that the domains introduced by Bonet and Geffner can be solved more efficiently in the new approach, often optimally, and furthermore, that the approach can be easily extended to handle partial information about the state graphs as well as noise that prevents some states from being distinguished.
SMPLpix: Neural Avatars from 3D Human Models
Aug 16, 2020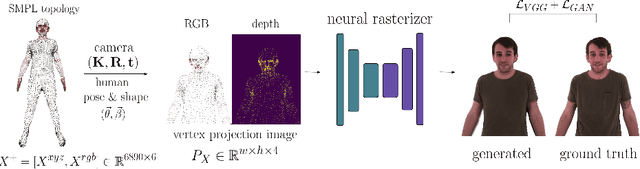
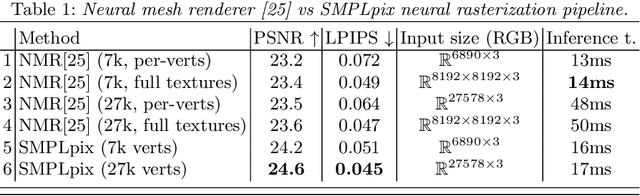


Recent advances in deep generative models have led to an unprecedented level of realism for synthetically generated images of humans. However, one of the remaining fundamental limitations of these models is the ability to flexibly control the generative process, e.g. change the camera and human pose while retaining the subject identity. At the same time, deformable human body models like SMPL and its successors provide full control over pose and shape, but rely on classic computer graphics pipelines for rendering. Such rendering pipelines require explicit mesh rasterization that (a) does not have the potential to fix artifacts or lack of realism in the original 3D geometry and (b) until recently, were not fully incorporated into deep learning frameworks. In this work, we propose to bridge the gap between classic geometry-based rendering and the latest generative networks operating in pixel space by introducing a neural rasterizer, a trainable neural network module that directly "renders" a sparse set of 3D mesh vertices as photorealistic images, avoiding any hardwired logic in pixel colouring and occlusion reasoning. We train our model on a large corpus of human 3D models and corresponding real photos, and show the advantage over conventional differentiable renderers both in terms of the level of photorealism and rendering efficiency.
How to build your own ASP-based system?!
Aug 15, 2020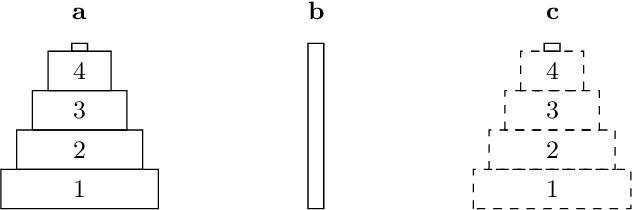

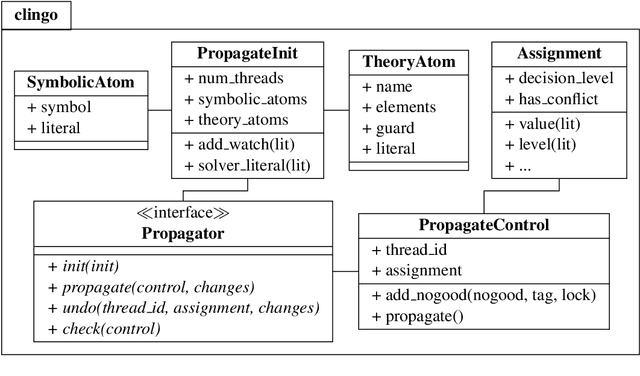

Answer Set Programming (ASP) has become a popular and quite sophisticated approach to declarative problem solving. This is arguably due to its attractive modeling-grounding-solving workflow that provides an easy approach to problem solving, even for laypersons outside computer science. Unlike this, the high degree of sophistication of the underlying technology makes it increasingly hard for ASP experts to put ideas into practice. For addressing this issue, this tutorial aims at enabling users to build their own ASP-based systems. More precisely, we show how the ASP system CLINGO can be used for extending ASP and for implementing customized special-purpose systems. To this end, we propose two alternatives. We begin with a traditional AI technique and show how meta programming can be used for extending ASP. This is a rather light approach that relies on CLINGO's reification feature to use ASP itself for expressing new functionalities. Unlike this, the major part of this tutorial uses traditional programming (in PYTHON) for manipulating CLINGO via its application programming interface. This approach allows for changing and controlling the entire model-ground-solve workflow of ASP. Central to this is CLINGO's new Application class that allows us to draw on CLINGO's infrastructure by customizing processes similar to the one in CLINGO. For instance, we may engage manipulations to programs' abstract syntax trees, control various forms of multi-shot solving, and set up theory propagators for foreign inferences. Another cross-sectional structure, spanning meta as well as application programming, is CLINGO's intermediate format, ASPIF, that specifies the interface among the underlying grounder and solver. We illustrate the aforementioned concepts and techniques throughout this tutorial by means of examples and several non-trivial case-studies.
eclingo: A solver for Epistemic Logic Programs
Aug 05, 2020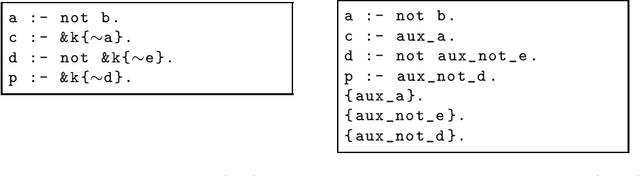
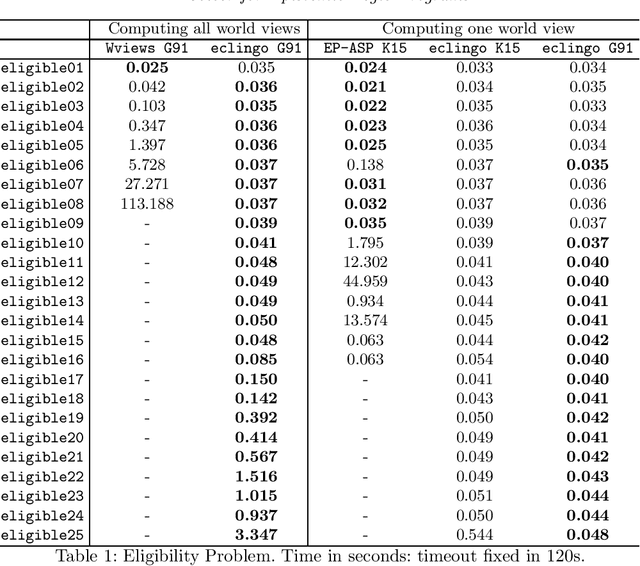
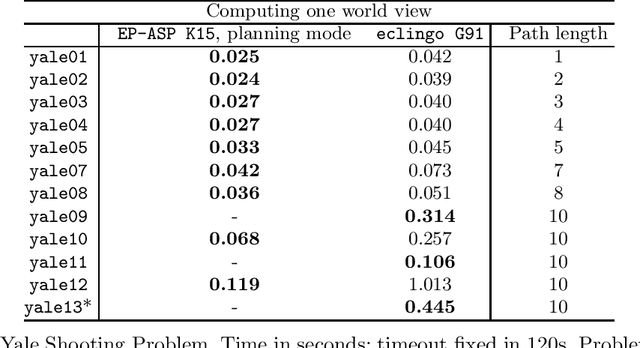
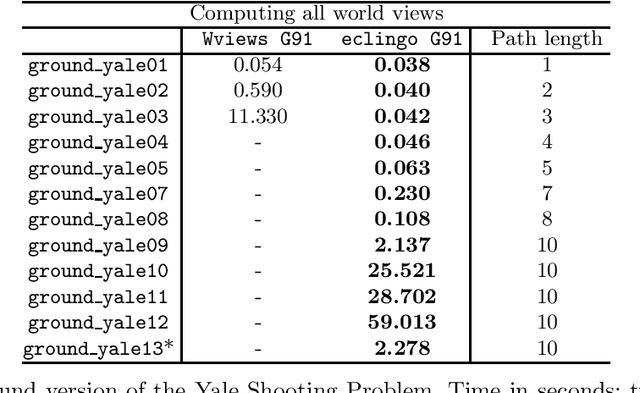
We describe eclingo, a solver for epistemic logic programs under Gelfond 1991 semantics built upon the Answer Set Programming system clingo. The input language of eclingo uses the syntax extension capabilities of clingo to define subjective literals that, as usual in epistemic logic programs, allow for checking the truth of a regular literal in all or in some of the answer sets of a program. The eclingo solving process follows a guess and check strategy. It first generates potential truth values for subjective literals and, in a second step, it checks the obtained result with respect to the cautious and brave consequences of the program. This process is implemented using the multi-shot functionalities of clingo. We have also implemented some optimisations, aiming at reducing the search space and, therefore, increasing eclingo's efficiency in some scenarios. Finally, we compare the efficiency of eclingo with two state-of-the-art solvers for epistemic logic programs on a pair of benchmark scenarios and show that eclingo generally outperforms their obtained results. Under consideration for acceptance in TPLP.