 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCT-Conditioned Diffusion Prior with Physics-Constrained Sampling for PET Super-Resolution
Mar 14, 2026PET super-resolution is highly under-constrained because paired multi-resolution scans from the same subject are rarely available, and effective resolution is determined by scanner-specific physics (e.g., PSF, detector geometry, and acquisition settings). This limits supervised end-to-end training and makes purely image-domain generative restoration prone to hallucinated structures when anatomical and physical constraints are weak. We formulate PET super-resolution as posterior inference under heterogeneous system configurations and propose a CT-conditioned diffusion framework with physics-constrained sampling. During training, a conditional diffusion prior is learned from high-quality PET/CT pairs using cross-attention for anatomical guidance, without requiring paired LR--HR PET data. During inference, measurement consistency is enforced through a scanner-aware forward model with explicit PSF effects and gradient-based data-consistency refinement. Under both standard and OOD settings, the proposed method consistently improves experimental metrics and lesion-level clinical relevance indicators over strong baselines, while reducing hallucination artifacts and improving structural fidelity.
ProSMA-UNet: Decoder Conditioning for Proximal-Sparse Skip Feature Selection
Mar 04, 2026Medical image segmentation commonly relies on U-shaped encoder-decoder architectures such as U-Net, where skip connections preserve fine spatial detail by injecting high-resolution encoder features into the decoder. However, these skip pathways also propagate low-level textures, background clutter, and acquisition noise, allowing irrelevant information to bypass deeper semantic filtering -- an issue that is particularly detrimental in low-contrast clinical imaging. Although attention gates have been introduced to address this limitation, they typically produce dense sigmoid masks that softly reweight features rather than explicitly removing irrelevant activations. We propose ProSMA-UNet (Proximal-Sparse Multi-Scale Attention U-Net), which reformulates skip gating as a decoder-conditioned sparse feature selection problem. ProSMA constructs a multi-scale compatibility field using lightweight depthwise dilated convolutions to capture relevance across local and contextual scales, then enforces explicit sparsity via an $\ell_1$ proximal operator with learnable per-channel thresholds, yielding a closed-form soft-thresholding gate that can remove noisy responses. To further suppress semantically irrelevant channels, ProSMA incorporates decoder-conditioned channel gating driven by global decoder context. Extensive experiments on challenging 2D and 3D benchmarks demonstrate state-of-the-art performance, with particularly large gains ($\approx20$\%) on difficult 3D segmentation tasks. Project page: https://math-ml-x.github.io/ProSMA-UNet/
MAP-Diff: Multi-Anchor Guided Diffusion for Progressive 3D Whole-Body Low-Dose PET Denoising
Mar 02, 2026Low-dose Positron Emission Tomography (PET) reduces radiation exposure but suffers from severe noise and quantitative degradation. Diffusion-based denoising models achieve strong final reconstructions, yet their reverse trajectories are typically unconstrained and not aligned with the progressive nature of PET dose formation. We propose MAP-Diff, a multi-anchor guided diffusion framework for progressive 3D whole-body PET denoising. MAP-Diff introduces clinically observed intermediate-dose scans as trajectory anchors and enforces timestep-dependent supervision to regularize the reverse process toward dose-aligned intermediate states. Anchor timesteps are calibrated via degradation matching between simulated diffusion corruption and real multi-dose PET pairs, and a timestep-weighted anchor loss stabilizes stage-wise learning. At inference, the model requires only ultra-low-dose input while enabling progressive, dose-consistent intermediate restoration. Experiments on internal (Siemens Biograph Vision Quadra) and cross-scanner (United Imaging uEXPLORER) datasets show consistent improvements over strong CNN-, Transformer-, GAN-, and diffusion-based baselines. On the internal dataset, MAP-Diff improves PSNR from 42.48 dB to 43.71 dB (+1.23 dB), increases SSIM to 0.986, and reduces NMAE from 0.115 to 0.103 (-0.012) compared to 3D DDPM. Performance gains generalize across scanners, achieving 34.42 dB PSNR and 0.141 NMAE on the external cohort, outperforming all competing methods.
PrepNet: A Convolutional Auto-Encoder to Homogenize CT Scans for Cross-Dataset Medical Image Analysis
Aug 19, 2022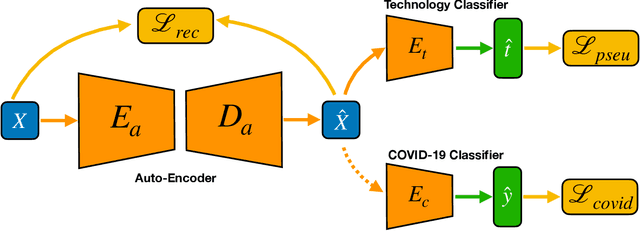
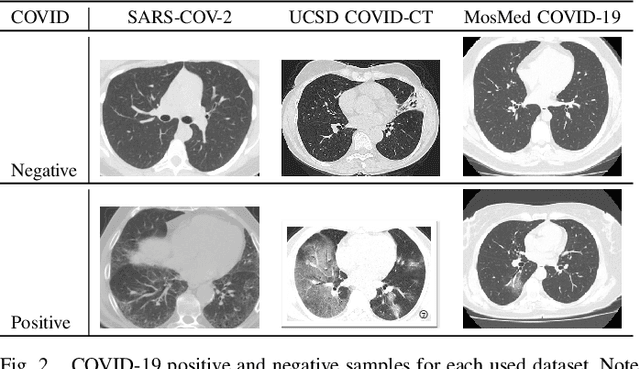
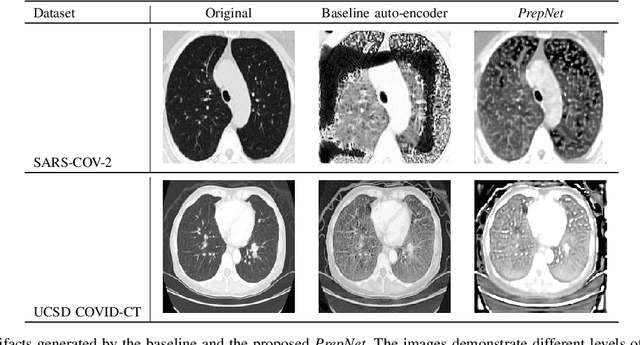
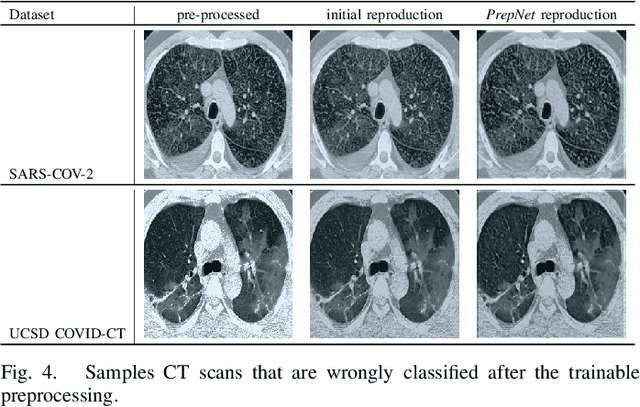
With the spread of COVID-19 over the world, the need arose for fast and precise automatic triage mechanisms to decelerate the spread of the disease by reducing human efforts e.g. for image-based diagnosis. Although the literature has shown promising efforts in this direction, reported results do not consider the variability of CT scans acquired under varying circumstances, thus rendering resulting models unfit for use on data acquired using e.g. different scanner technologies. While COVID-19 diagnosis can now be done efficiently using PCR tests, this use case exemplifies the need for a methodology to overcome data variability issues in order to make medical image analysis models more widely applicable. In this paper, we explicitly address the variability issue using the example of COVID-19 diagnosis and propose a novel generative approach that aims at erasing the differences induced by e.g. the imaging technology while simultaneously introducing minimal changes to the CT scans through leveraging the idea of deep auto-encoders. The proposed prepossessing architecture (PrepNet) (i) is jointly trained on multiple CT scan datasets and (ii) is capable of extracting improved discriminative features for improved diagnosis. Experimental results on three public datasets (SARS-COVID-2, UCSD COVID-CT, MosMed) show that our model improves cross-dataset generalization by up to $11.84$ percentage points despite a minor drop in within dataset performance.
* 7 pages 4 figures peer reviewed and published in IEEE EMBS Regional Conference on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI 2021)