 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinetuned Language Models Are Zero-Shot Learners
Sep 03, 2021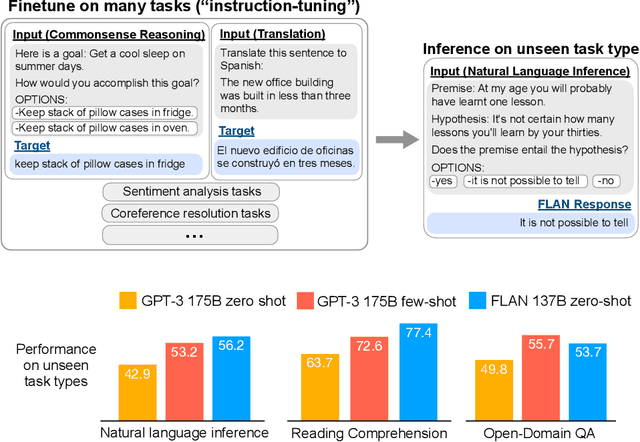
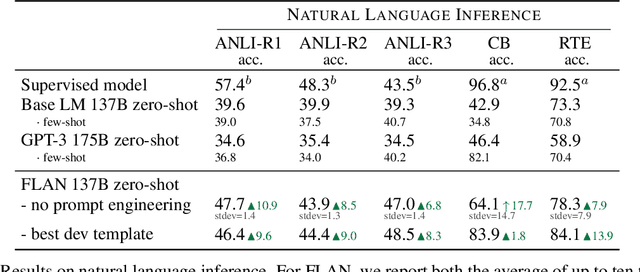
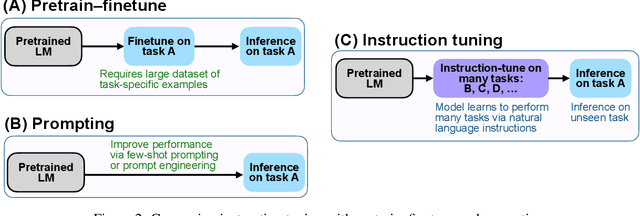
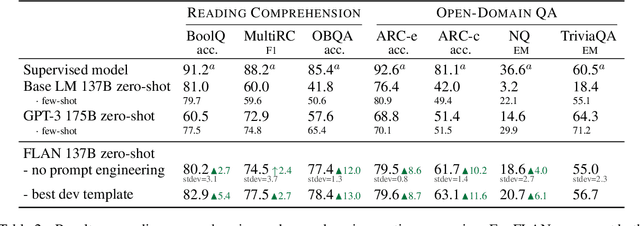
This paper explores a simple method for improving the zero-shot learning abilities of language models. We show that instruction tuning -- finetuning language models on a collection of tasks described via instructions -- substantially boosts zero-shot performance on unseen tasks. We take a 137B parameter pretrained language model and instruction-tune it on over 60 NLP tasks verbalized via natural language instruction templates. We evaluate this instruction-tuned model, which we call FLAN, on unseen task types. FLAN substantially improves the performance of its unmodified counterpart and surpasses zero-shot 175B GPT-3 on 19 of 25 tasks that we evaluate. FLAN even outperforms few-shot GPT-3 by a large margin on ANLI, RTE, BoolQ, AI2-ARC, OpenbookQA, and StoryCloze. Ablation studies reveal that number of tasks and model scale are key components to the success of instruction tuning.
Language Model Augmented Relevance Score
Aug 19, 2021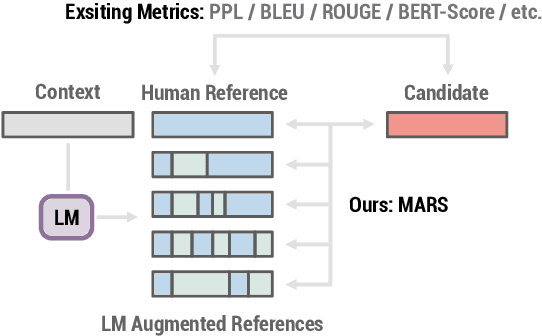


Although automated metrics are commonly used to evaluate NLG systems, they often correlate poorly with human judgements. Newer metrics such as BERTScore have addressed many weaknesses in prior metrics such as BLEU and ROUGE, which rely on n-gram matching. These newer methods, however, are still limited in that they do not consider the generation context, so they cannot properly reward generated text that is correct but deviates from the given reference. In this paper, we propose Language Model Augmented Relevance Score (MARS), a new context-aware metric for NLG evaluation. MARS leverages off-the-shelf language models, guided by reinforcement learning, to create augmented references that consider both the generation context and available human references, which are then used as additional references to score generated text. Compared with seven existing metrics in three common NLG tasks, MARS not only achieves higher correlation with human reference judgements, but also differentiates well-formed candidates from adversarial samples to a larger degree.
Modulating Language Models with Emotions
Aug 17, 2021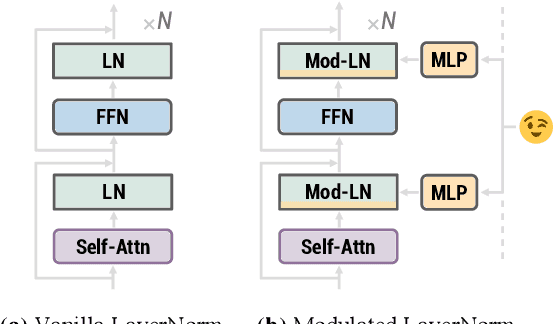
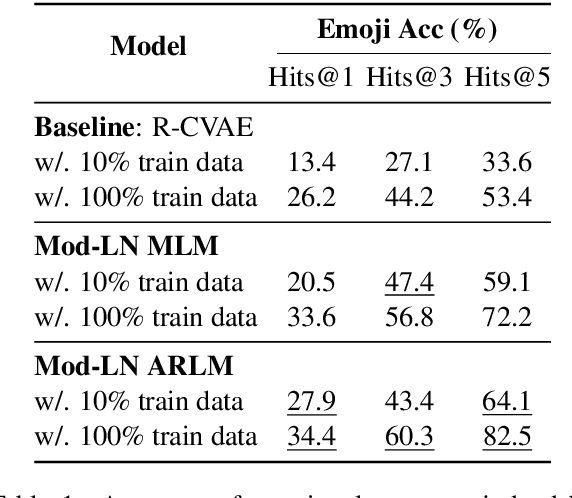
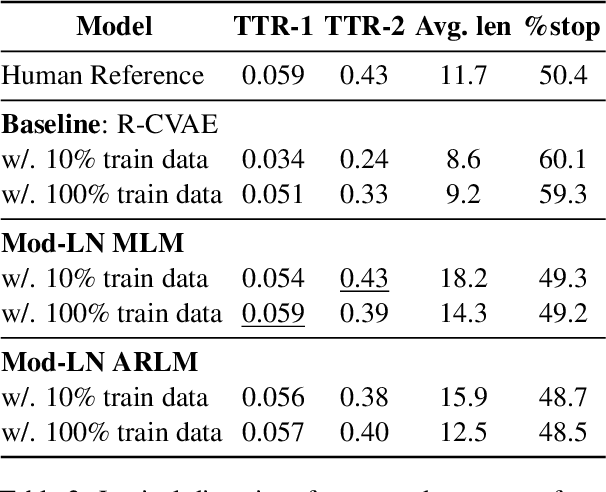
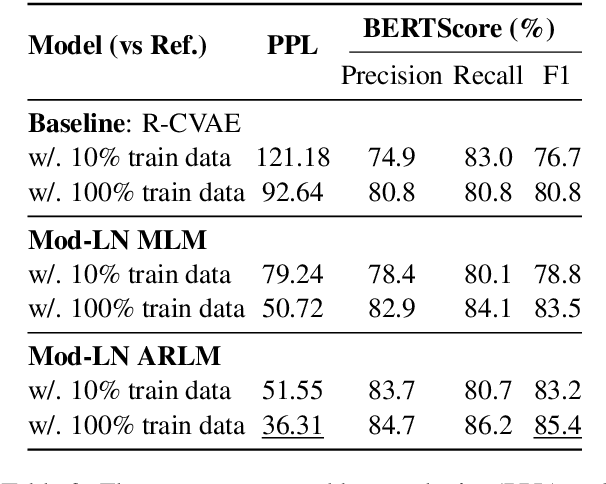
Generating context-aware language that embodies diverse emotions is an important step towards building empathetic NLP systems. In this paper, we propose a formulation of modulated layer normalization -- a technique inspired by computer vision -- that allows us to use large-scale language models for emotional response generation. In automatic and human evaluation on the MojiTalk dataset, our proposed modulated layer normalization method outperforms prior baseline methods while maintaining diversity, fluency, and coherence. Our method also obtains competitive performance even when using only 10% of the available training data.
The MultiBERTs: BERT Reproductions for Robustness Analysis
Jun 30, 2021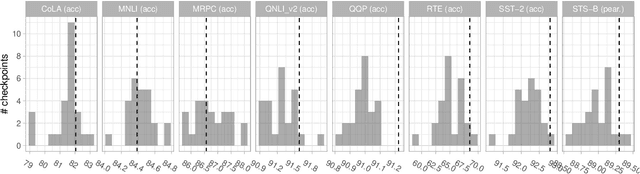
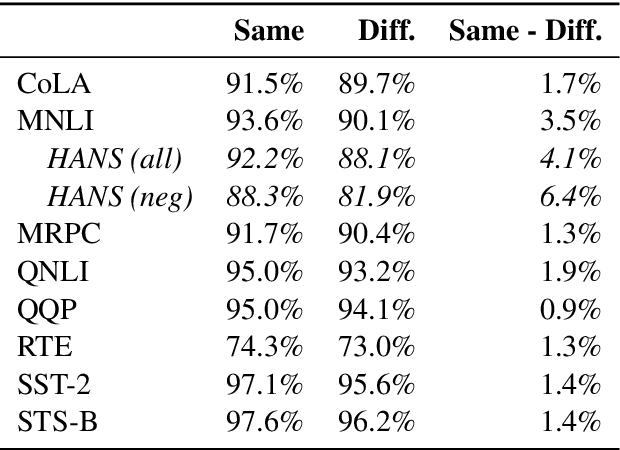
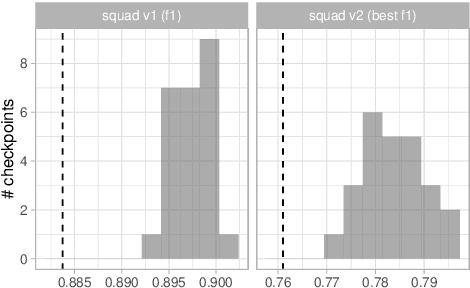
Experiments with pretrained models such as BERT are often based on a single checkpoint. While the conclusions drawn apply to the artifact (i.e., the particular instance of the model), it is not always clear whether they hold for the more general procedure (which includes the model architecture, training data, initialization scheme, and loss function). Recent work has shown that re-running pretraining can lead to substantially different conclusions about performance, suggesting that alternative evaluations are needed to make principled statements about procedures. To address this question, we introduce MultiBERTs: a set of 25 BERT-base checkpoints, trained with similar hyper-parameters as the original BERT model but differing in random initialization and data shuffling. The aim is to enable researchers to draw robust and statistically justified conclusions about pretraining procedures. The full release includes 25 fully trained checkpoints, as well as statistical guidelines and a code library implementing our recommended hypothesis testing methods. Finally, for five of these models we release a set of 28 intermediate checkpoints in order to support research on learning dynamics.
A Cognitive Regularizer for Language Modeling
Jun 10, 2021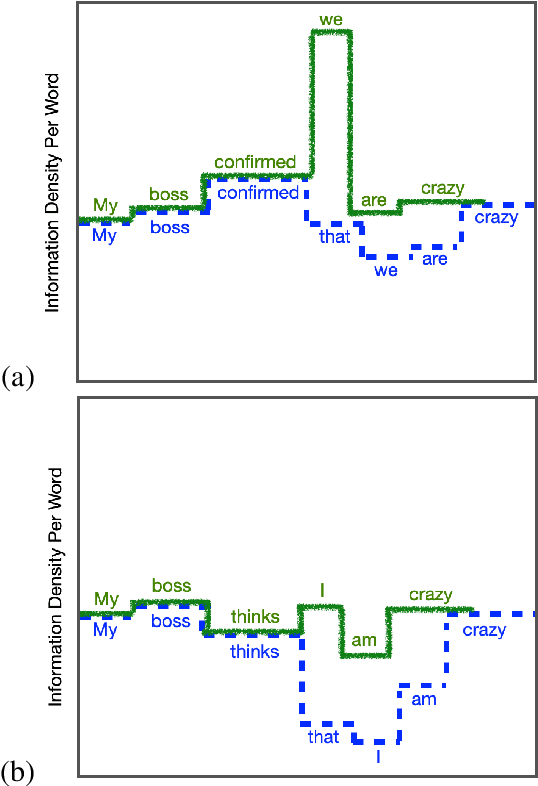
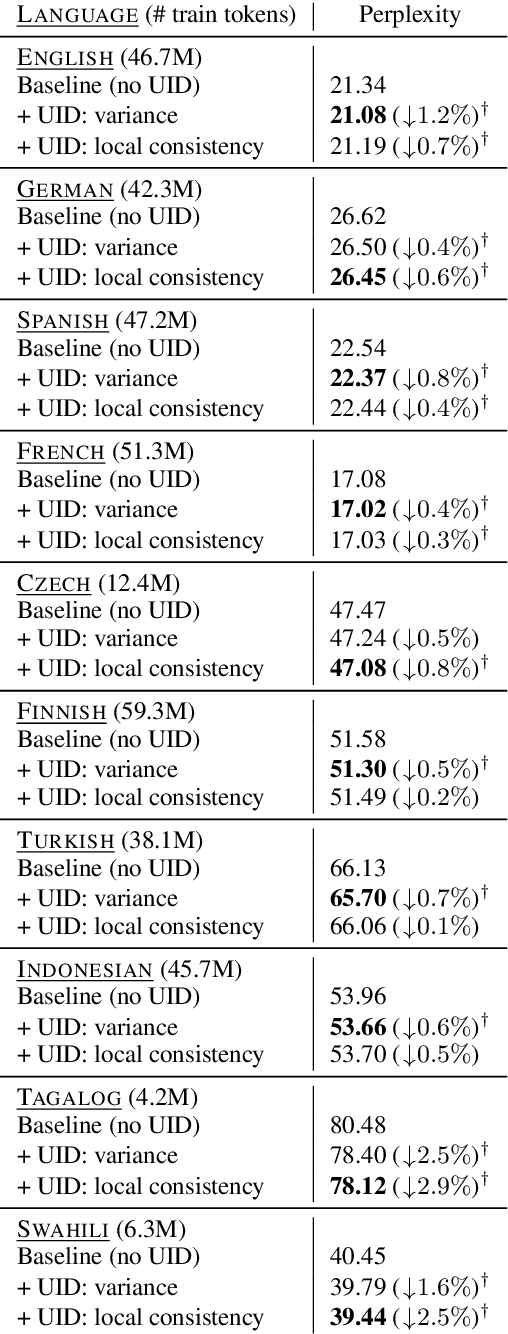
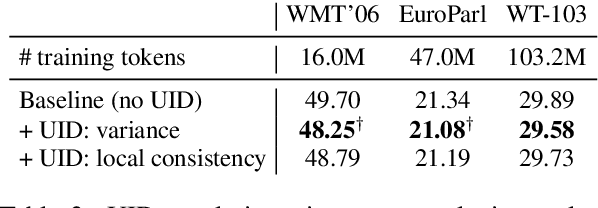
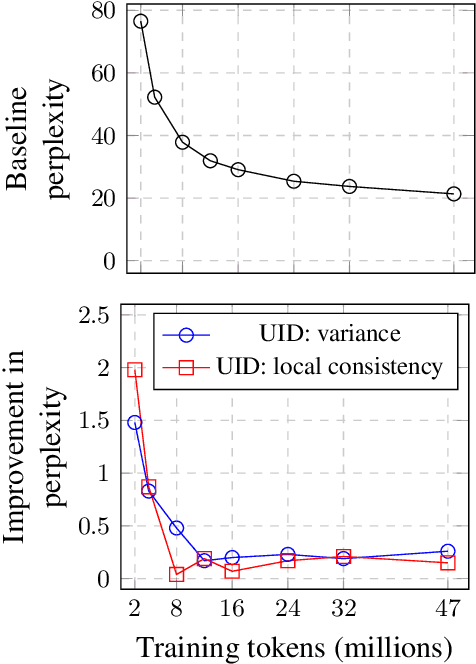
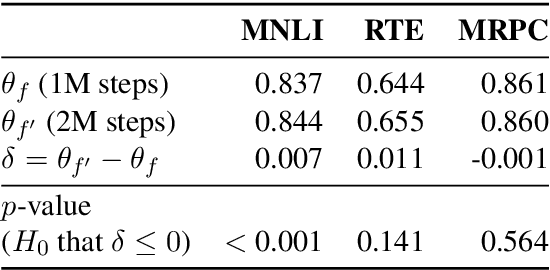
The uniform information density (UID) hypothesis, which posits that speakers behaving optimally tend to distribute information uniformly across a linguistic signal, has gained traction in psycholinguistics as an explanation for certain syntactic, morphological, and prosodic choices. In this work, we explore whether the UID hypothesis can be operationalized as an inductive bias for statistical language modeling. Specifically, we augment the canonical MLE objective for training language models with a regularizer that encodes UID. In experiments on ten languages spanning five language families, we find that using UID regularization consistently improves perplexity in language models, having a larger effect when training data is limited. Moreover, via an analysis of generated sequences, we find that UID-regularized language models have other desirable properties, e.g., they generate text that is more lexically diverse. Our results not only suggest that UID is a reasonable inductive bias for language modeling, but also provide an alternative validation of the UID hypothesis using modern-day NLP tools.
A Survey of Data Augmentation Approaches for NLP
May 29, 2021
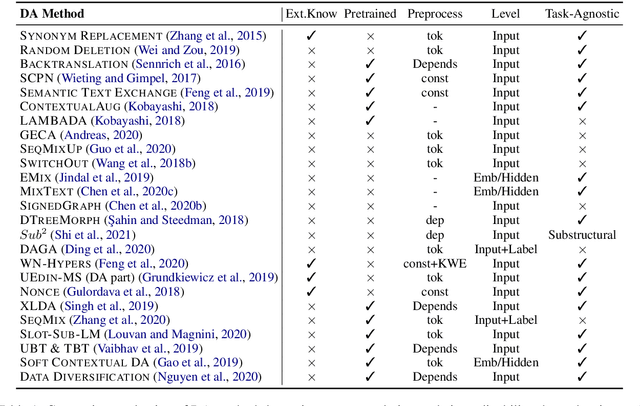
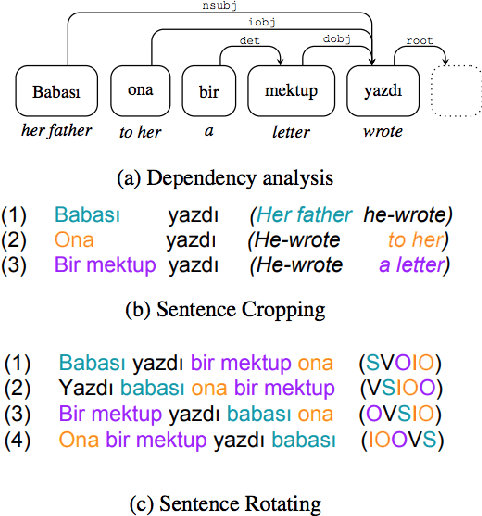
Data augmentation has recently seen increased interest in NLP due to more work in low-resource domains, new tasks, and the popularity of large-scale neural networks that require large amounts of training data. Despite this recent upsurge, this area is still relatively underexplored, perhaps due to the challenges posed by the discrete nature of language data. In this paper, we present a comprehensive and unifying survey of data augmentation for NLP by summarizing the literature in a structured manner. We first introduce and motivate data augmentation for NLP, and then discuss major methodologically representative approaches. Next, we highlight techniques that are used for popular NLP applications and tasks. We conclude by outlining current challenges and directions for future research. Overall, our paper aims to clarify the landscape of existing literature in data augmentation for NLP and motivate additional work in this area. We also present a GitHub repository with a paper list that will be continuously updated at https://github.com/styfeng/DataAug4NLP
Mitigating Political Bias in Language Models Through Reinforced Calibration
Apr 30, 2021
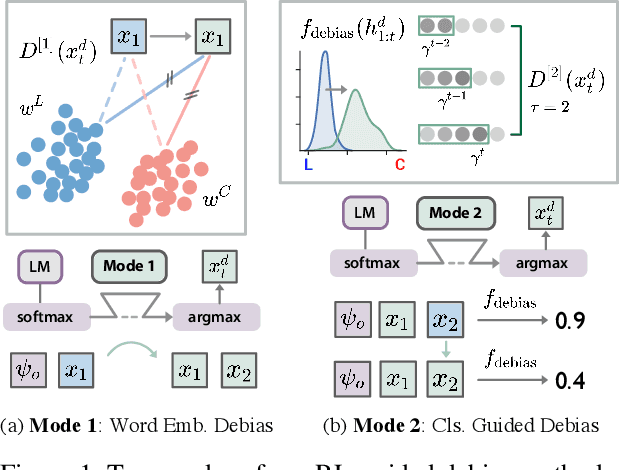
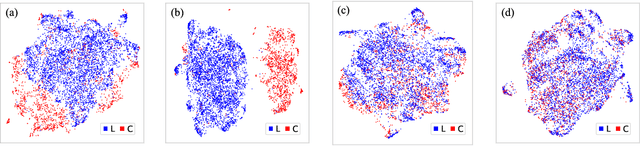
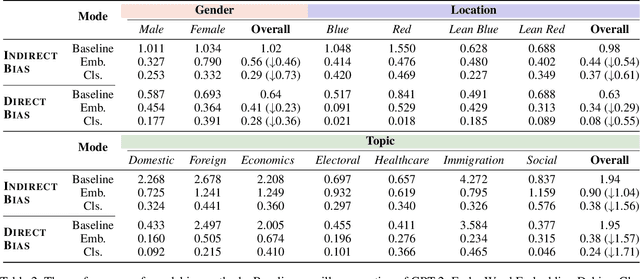
Current large-scale language models can be politically biased as a result of the data they are trained on, potentially causing serious problems when they are deployed in real-world settings. In this paper, we describe metrics for measuring political bias in GPT-2 generation and propose a reinforcement learning (RL) framework for mitigating political biases in generated text. By using rewards from word embeddings or a classifier, our RL framework guides debiased generation without having access to the training data or requiring the model to be retrained. In empirical experiments on three attributes sensitive to political bias (gender, location, and topic), our methods reduced bias according to both our metrics and human evaluation, while maintaining readability and semantic coherence.
Few-Shot Text Classification with Triplet Networks, Data Augmentation, and Curriculum Learning
Mar 12, 2021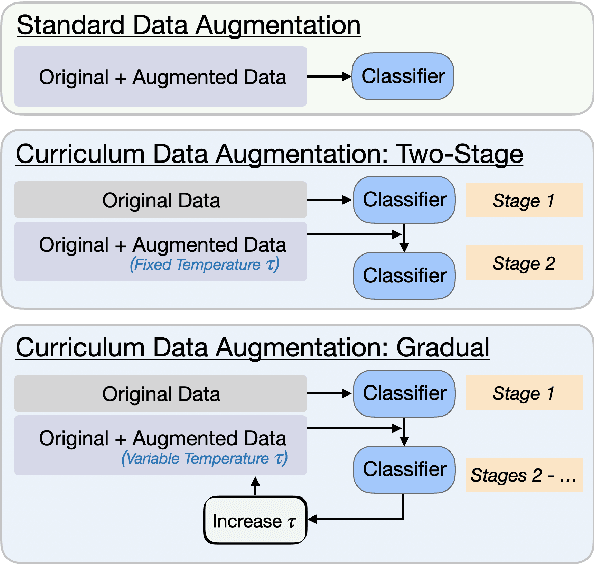
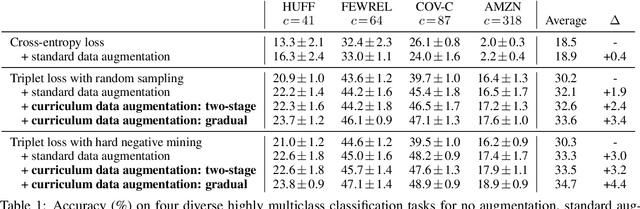
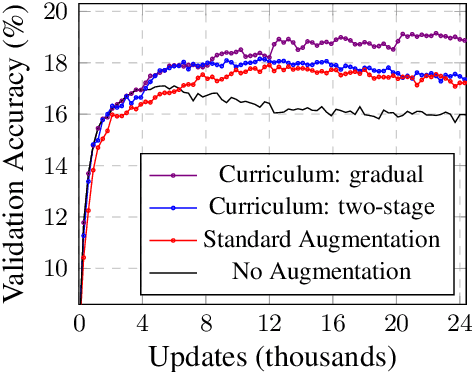

Few-shot text classification is a fundamental NLP task in which a model aims to classify text into a large number of categories, given only a few training examples per category. This paper explores data augmentation -- a technique particularly suitable for training with limited data -- for this few-shot, highly-multiclass text classification setting. On four diverse text classification tasks, we find that common data augmentation techniques can improve the performance of triplet networks by up to 3.0% on average. To further boost performance, we present a simple training strategy called curriculum data augmentation, which leverages curriculum learning by first training on only original examples and then introducing augmented data as training progresses. We explore a two-stage and a gradual schedule, and find that, compared with standard single-stage training, curriculum data augmentation trains faster, improves performance, and remains robust to high amounts of noising from augmentation.
A Petri Dish for Histopathology Image Analysis
Jan 29, 2021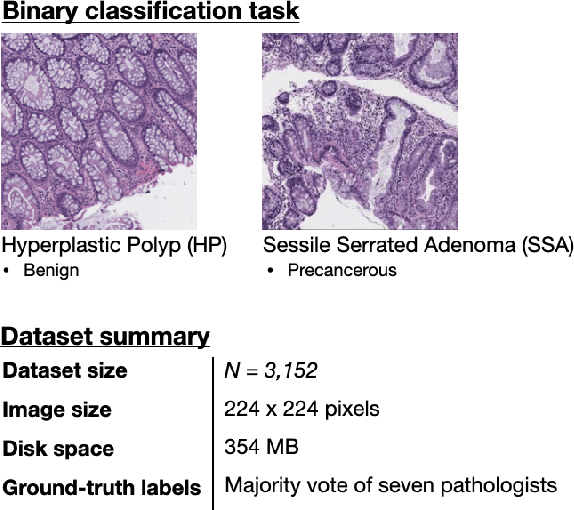
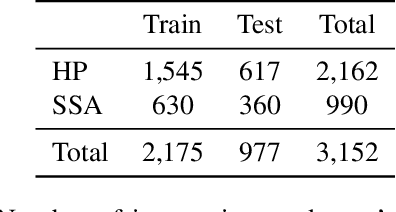
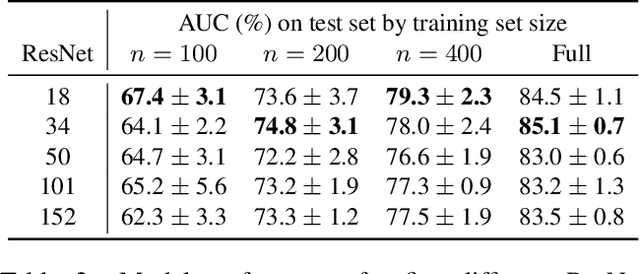
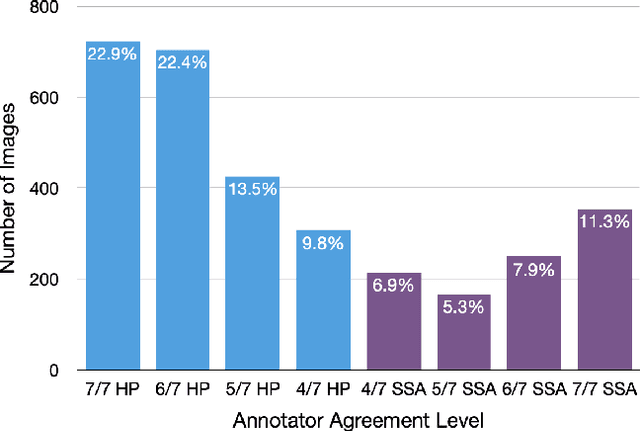
With the rise of deep learning, there has been increased interest in using neural networks for histopathology image analysis, a field that investigates the properties of biopsy or resected specimens that are traditionally manually examined under a microscope by pathologists. In histopathology image analysis, however, challenges such as limited data, costly annotation, and processing high-resolution and variable-size images create a high barrier of entry and make it difficult to quickly iterate over model designs. Throughout scientific history, many significant research directions have leveraged small-scale experimental setups as petri dishes to efficiently evaluate exploratory ideas, which are then validated in large-scale applications. For instance, the Drosophila fruit fly in genetics and MNIST in computer vision are well-known petri dishes. In this paper, we introduce a minimalist histopathology image analysis dataset (MHIST), an analogous petri dish for histopathology image analysis. MHIST is a binary classification dataset of 3,152 fixed-size images of colorectal polyps, each with a gold-standard label determined by the majority vote of seven board-certified gastrointestinal pathologists and annotator agreement level. MHIST occupies less than 400 MB of disk space, and a ResNet-18 baseline can be trained to convergence on MHIST in just 6 minutes using 3.5 GB of memory on a NVIDIA RTX 3090. As example use cases, we use MHIST to study natural questions such as how dataset size, network depth, transfer learning, and high-disagreement examples affect model performance. By introducing MHIST, we hope to not only help facilitate the work of current histopathology imaging researchers, but also make histopathology image analysis more accessible to the general computer vision community. Our dataset is available at https://bmirds.github.io/MHIST.
Text Augmentation in a Multi-Task View
Jan 14, 2021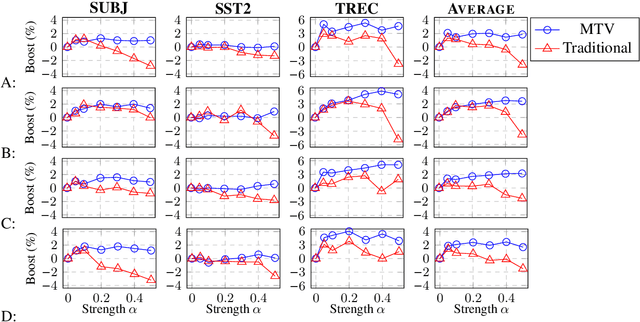
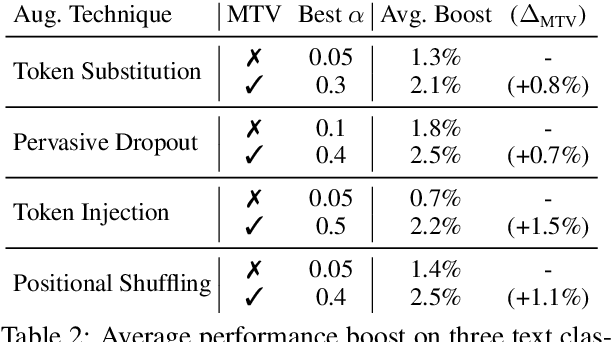
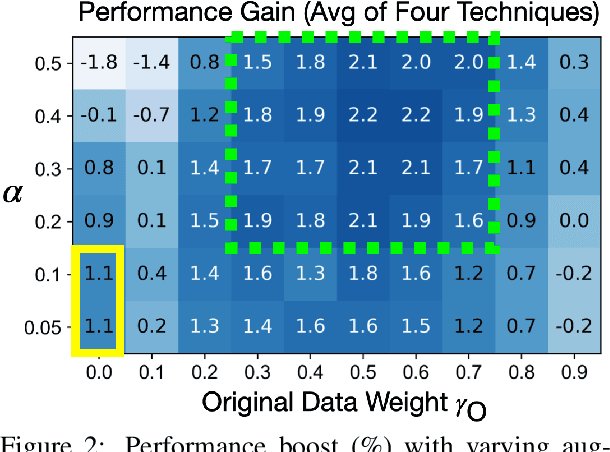
Traditional data augmentation aims to increase the coverage of the input distribution by generating augmented examples that strongly resemble original samples in an online fashion where augmented examples dominate training. In this paper, we propose an alternative perspective -- a multi-task view (MTV) of data augmentation -- in which the primary task trains on original examples and the auxiliary task trains on augmented examples. In MTV data augmentation, both original and augmented samples are weighted substantively during training, relaxing the constraint that augmented examples must resemble original data and thereby allowing us to apply stronger levels of augmentation. In empirical experiments using four common data augmentation techniques on three benchmark text classification datasets, we find that the MTV leads to higher and more robust performance improvements than traditional augmentation.