 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Entropy and Reconstruction in Multi-View Self-Supervised Learning
Jul 20, 2023
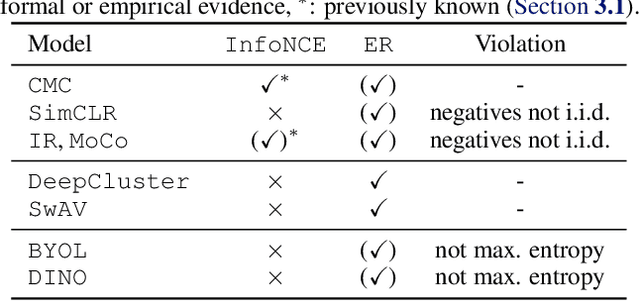
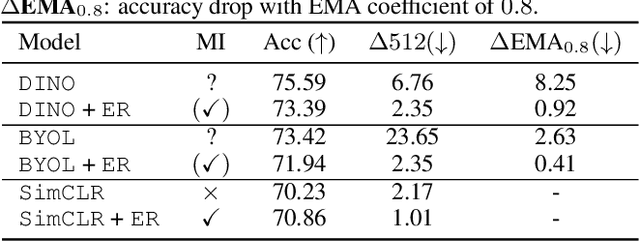

The mechanisms behind the success of multi-view self-supervised learning (MVSSL) are not yet fully understood. Contrastive MVSSL methods have been studied through the lens of InfoNCE, a lower bound of the Mutual Information (MI). However, the relation between other MVSSL methods and MI remains unclear. We consider a different lower bound on the MI consisting of an entropy and a reconstruction term (ER), and analyze the main MVSSL families through its lens. Through this ER bound, we show that clustering-based methods such as DeepCluster and SwAV maximize the MI. We also re-interpret the mechanisms of distillation-based approaches such as BYOL and DINO, showing that they explicitly maximize the reconstruction term and implicitly encourage a stable entropy, and we confirm this empirically. We show that replacing the objectives of common MVSSL methods with this ER bound achieves competitive performance, while making them stable when training with smaller batch sizes or smaller exponential moving average (EMA) coefficients. Github repo: https://github.com/apple/ml-entropy-reconstruction.
DUET: 2D Structured and Approximately Equivariant Representations
Jun 30, 2023Multiview Self-Supervised Learning (MSSL) is based on learning invariances with respect to a set of input transformations. However, invariance partially or totally removes transformation-related information from the representations, which might harm performance for specific downstream tasks that require such information. We propose 2D strUctured and EquivarianT representations (coined DUET), which are 2d representations organized in a matrix structure, and equivariant with respect to transformations acting on the input data. DUET representations maintain information about an input transformation, while remaining semantically expressive. Compared to SimCLR (Chen et al., 2020) (unstructured and invariant) and ESSL (Dangovski et al., 2022) (unstructured and equivariant), the structured and equivariant nature of DUET representations enables controlled generation with lower reconstruction error, while controllability is not possible with SimCLR or ESSL. DUET also achieves higher accuracy for several discriminative tasks, and improves transfer learning.
Stabilizing Transformer Training by Preventing Attention Entropy Collapse
Mar 11, 2023Training stability is of great importance to Transformers. In this work, we investigate the training dynamics of Transformers by examining the evolution of the attention layers. In particular, we track the attention entropy for each attention head during the course of training, which is a proxy for model sharpness. We identify a common pattern across different architectures and tasks, where low attention entropy is accompanied by high training instability, which can take the form of oscillating loss or divergence. We denote the pathologically low attention entropy, corresponding to highly concentrated attention scores, as $\textit{entropy collapse}$. As a remedy, we propose $\sigma$Reparam, a simple and efficient solution where we reparametrize all linear layers with spectral normalization and an additional learned scalar. We demonstrate that the proposed reparameterization successfully prevents entropy collapse in the attention layers, promoting more stable training. Additionally, we prove a tight lower bound of the attention entropy, which decreases exponentially fast with the spectral norm of the attention logits, providing additional motivation for our approach. We conduct experiments with $\sigma$Reparam on image classification, image self-supervised learning, machine translation, automatic speech recognition, and language modeling tasks, across Transformer architectures. We show that $\sigma$Reparam provides stability and robustness with respect to the choice of hyperparameters, going so far as enabling training (a) a Vision Transformer to competitive performance without warmup, weight decay, layer normalization or adaptive optimizers; (b) deep architectures in machine translation and (c) speech recognition to competitive performance without warmup and adaptive optimizers.
Elastic Weight Consolidation Improves the Robustness of Self-Supervised Learning Methods under Transfer
Oct 28, 2022Self-supervised representation learning (SSL) methods provide an effective label-free initial condition for fine-tuning downstream tasks. However, in numerous realistic scenarios, the downstream task might be biased with respect to the target label distribution. This in turn moves the learned fine-tuned model posterior away from the initial (label) bias-free self-supervised model posterior. In this work, we re-interpret SSL fine-tuning under the lens of Bayesian continual learning and consider regularization through the Elastic Weight Consolidation (EWC) framework. We demonstrate that self-regularization against an initial SSL backbone improves worst sub-group performance in Waterbirds by 5% and Celeb-A by 2% when using the ViT-B/16 architecture. Furthermore, to help simplify the use of EWC with SSL, we pre-compute and publicly release the Fisher Information Matrix (FIM), evaluated with 10,000 ImageNet-1K variates evaluated on large modern SSL architectures including ViT-B/16 and ResNet50 trained with DINO.
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022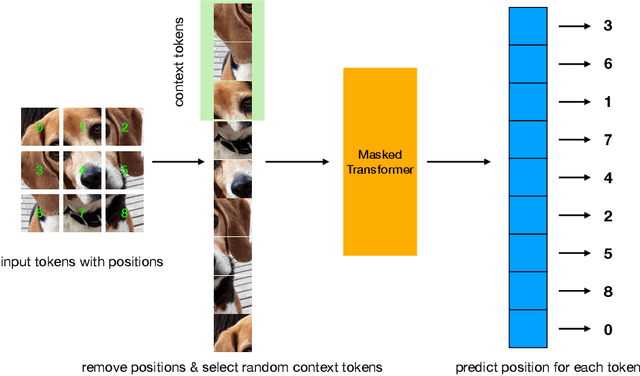


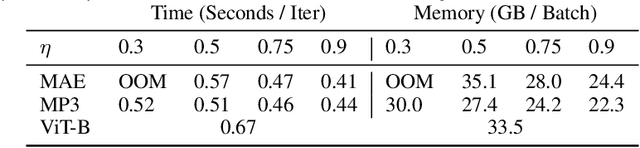
Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
Challenges of Adversarial Image Augmentations
Dec 03, 2021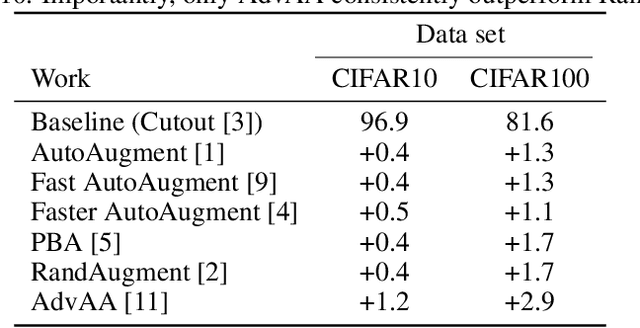
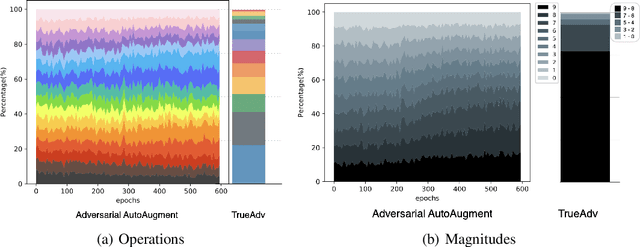


Image augmentations applied during training are crucial for the generalization performance of image classifiers. Therefore, a large body of research has focused on finding the optimal augmentation policy for a given task. Yet, RandAugment [2], a simple random augmentation policy, has recently been shown to outperform existing sophisticated policies. Only Adversarial AutoAugment (AdvAA) [11], an approach based on the idea of adversarial training, has shown to be better than RandAugment. In this paper, we show that random augmentations are still competitive compared to an optimal adversarial approach, as well as to simple curricula, and conjecture that the success of AdvAA is due to the stochasticity of the policy controller network, which introduces a mild form of curriculum.
Stochastic Contrastive Learning
Oct 01, 2021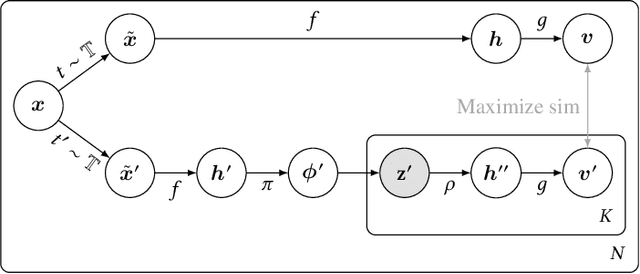

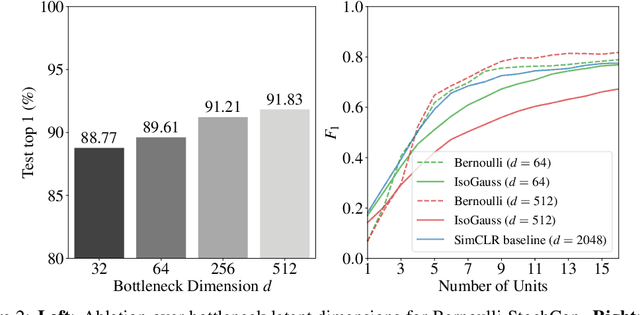
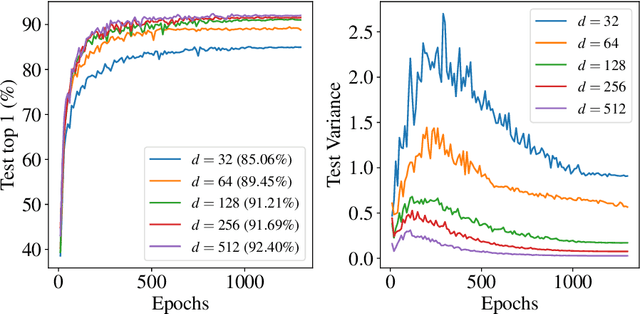
While state-of-the-art contrastive Self-Supervised Learning (SSL) models produce results competitive with their supervised counterparts, they lack the ability to infer latent variables. In contrast, prescribed latent variable (LV) models enable attributing uncertainty, inducing task specific compression, and in general allow for more interpretable representations. In this work, we introduce LV approximations to large scale contrastive SSL models. We demonstrate that this addition improves downstream performance (resulting in 96.42% and 77.49% test top-1 fine-tuned performance on CIFAR10 and ImageNet respectively with a ResNet50) as well as producing highly compressed representations (588x reduction) that are useful for interpretability, classification and regression downstream tasks.
Evaluating the fairness of fine-tuning strategies in self-supervised learning
Oct 01, 2021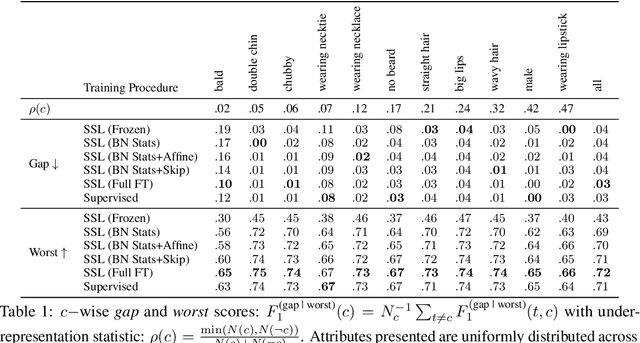
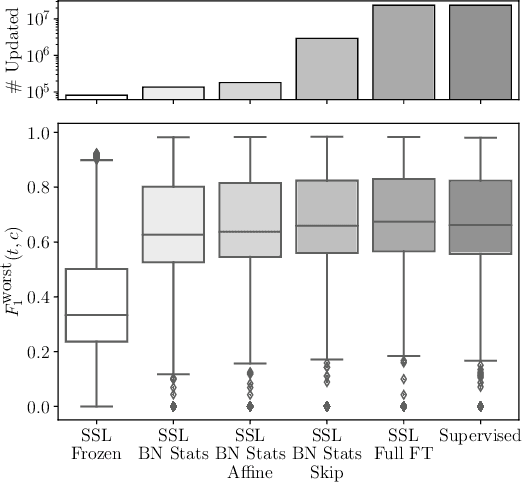
In this work we examine how fine-tuning impacts the fairness of contrastive Self-Supervised Learning (SSL) models. Our findings indicate that Batch Normalization (BN) statistics play a crucial role, and that updating only the BN statistics of a pre-trained SSL backbone improves its downstream fairness (36% worst subgroup, 25% mean subgroup gap). This procedure is competitive with supervised learning, while taking 4.4x less time to train and requiring only 0.35% as many parameters to be updated. Finally, inspired by recent work in supervised learning, we find that updating BN statistics and training residual skip connections (12.3% of the parameters) achieves parity with a fully fine-tuned model, while taking 1.33x less time to train.
Do Self-Supervised and Supervised Methods Learn Similar Visual Representations?
Oct 01, 2021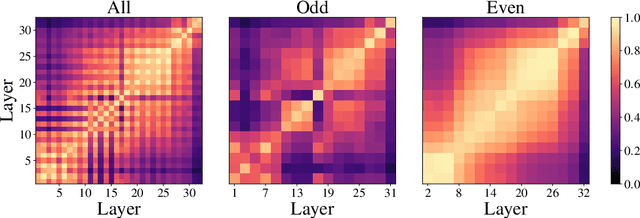

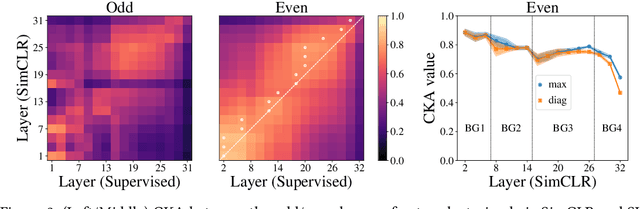
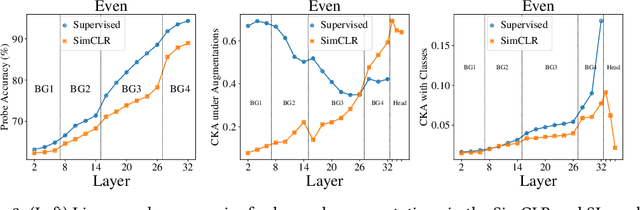
Despite the success of a number of recent techniques for visual self-supervised deep learning, there remains limited investigation into the representations that are ultimately learned. By using recent advances in comparing neural representations, we explore in this direction by comparing a constrastive self-supervised algorithm (SimCLR) to supervision for simple image data in a common architecture. We find that the methods learn similar intermediate representations through dissimilar means, and that the representations diverge rapidly in the final few layers. We investigate this divergence, finding that it is caused by these layers strongly fitting to the distinct learning objectives. We also find that SimCLR's objective implicitly fits the supervised objective in intermediate layers, but that the reverse is not true. Our work particularly highlights the importance of the learned intermediate representations, and raises important questions for auxiliary task design.
Kanerva++: extending The Kanerva Machine with differentiable, locally block allocated latent memory
Mar 16, 2021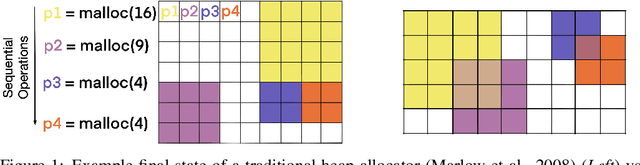
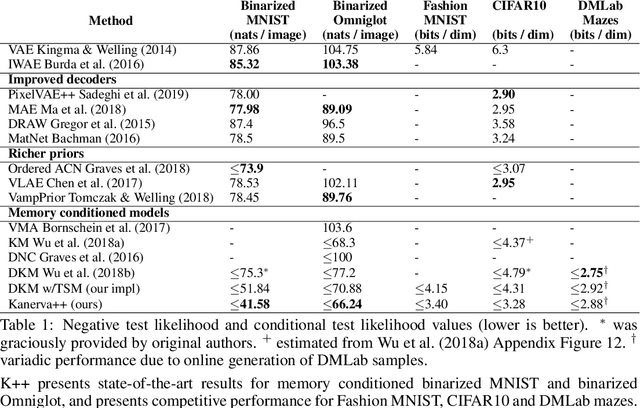
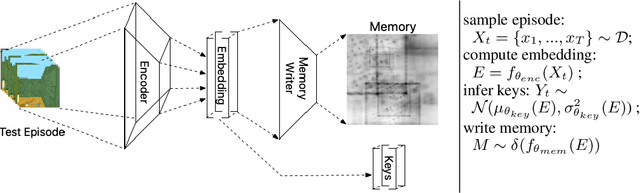
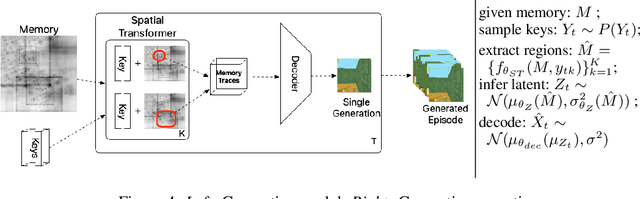
Episodic and semantic memory are critical components of the human memory model. The theory of complementary learning systems (McClelland et al., 1995) suggests that the compressed representation produced by a serial event (episodic memory) is later restructured to build a more generalized form of reusable knowledge (semantic memory). In this work we develop a new principled Bayesian memory allocation scheme that bridges the gap between episodic and semantic memory via a hierarchical latent variable model. We take inspiration from traditional heap allocation and extend the idea of locally contiguous memory to the Kanerva Machine, enabling a novel differentiable block allocated latent memory. In contrast to the Kanerva Machine, we simplify the process of memory writing by treating it as a fully feed forward deterministic process, relying on the stochasticity of the read key distribution to disperse information within the memory. We demonstrate that this allocation scheme improves performance in memory conditional image generation, resulting in new state-of-the-art conditional likelihood values on binarized MNIST (<=41.58 nats/image) , binarized Omniglot (<=66.24 nats/image), as well as presenting competitive performance on CIFAR10, DMLab Mazes, Celeb-A and ImageNet32x32.