 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the GAP: A Balanced Corpus of Gendered Ambiguous Pronouns
Oct 11, 2018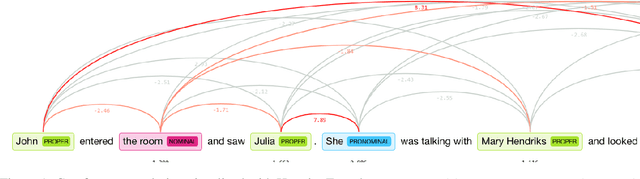
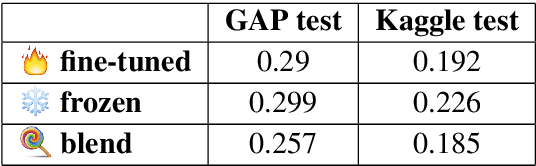


Coreference resolution is an important task for natural language understanding, and the resolution of ambiguous pronouns a longstanding challenge. Nonetheless, existing corpora do not capture ambiguous pronouns in sufficient volume or diversity to accurately indicate the practical utility of models. Furthermore, we find gender bias in existing corpora and systems favoring masculine entities. To address this, we present and release GAP, a gender-balanced labeled corpus of 8,908 ambiguous pronoun-name pairs sampled to provide diverse coverage of challenges posed by real-world text. We explore a range of baselines which demonstrate the complexity of the challenge, the best achieving just 66.9% F1. We show that syntactic structure and continuous neural models provide promising, complementary cues for approaching the challenge.
A Fast, Compact, Accurate Model for Language Identification of Codemixed Text
Oct 09, 2018
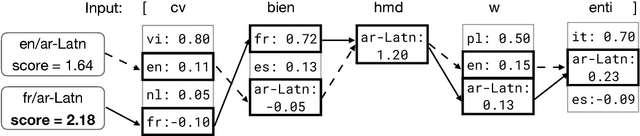
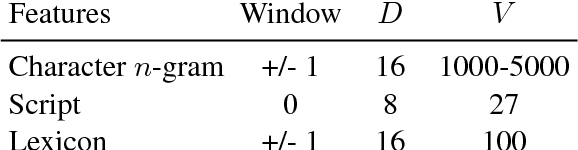
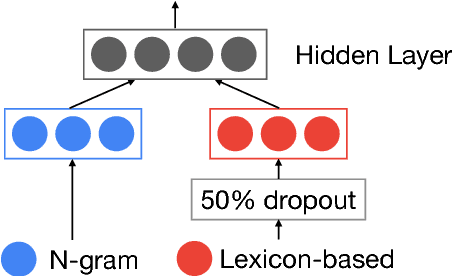
We address fine-grained multilingual language identification: providing a language code for every token in a sentence, including codemixed text containing multiple languages. Such text is prevalent online, in documents, social media, and message boards. We show that a feed-forward network with a simple globally constrained decoder can accurately and rapidly label both codemixed and monolingual text in 100 languages and 100 language pairs. This model outperforms previously published multilingual approaches in terms of both accuracy and speed, yielding an 800x speed-up and a 19.5% averaged absolute gain on three codemixed datasets. It furthermore outperforms several benchmark systems on monolingual language identification.
Learning To Split and Rephrase From Wikipedia Edit History
Aug 28, 2018

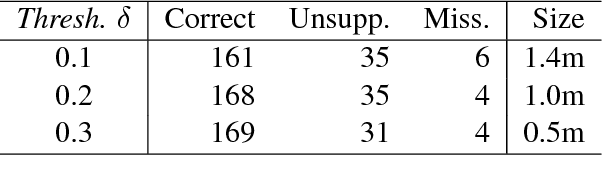
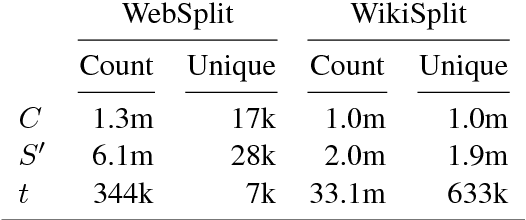
Split and rephrase is the task of breaking down a sentence into shorter ones that together convey the same meaning. We extract a rich new dataset for this task by mining Wikipedia's edit history: WikiSplit contains one million naturally occurring sentence rewrites, providing sixty times more distinct split examples and a ninety times larger vocabulary than the WebSplit corpus introduced by Narayan et al. (2017) as a benchmark for this task. Incorporating WikiSplit as training data produces a model with qualitatively better predictions that score 32 BLEU points above the prior best result on the WebSplit benchmark.
Fill it up: Exploiting partial dependency annotations in a minimum spanning tree parser
Nov 26, 2016
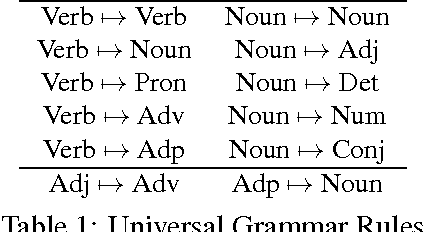
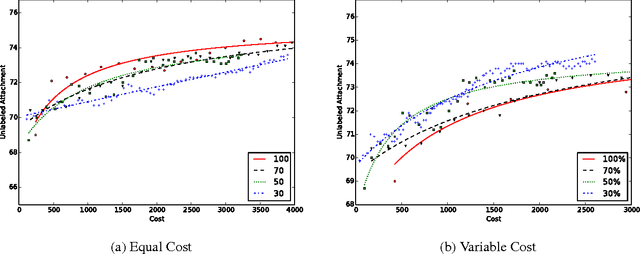
Unsupervised models of dependency parsing typically require large amounts of clean, unlabeled data plus gold-standard part-of-speech tags. Adding indirect supervision (e.g. language universals and rules) can help, but we show that obtaining small amounts of direct supervision - here, partial dependency annotations - provides a strong balance between zero and full supervision. We adapt the unsupervised ConvexMST dependency parser to learn from partial dependencies expressed in the Graph Fragment Language. With less than 24 hours of total annotation, we obtain 7% and 17% absolute improvement in unlabeled dependency scores for English and Spanish, respectively, compared to the same parser using only universal grammar constraints.
A framework for (under)specifying dependency syntax without overloading annotators
Jun 15, 2013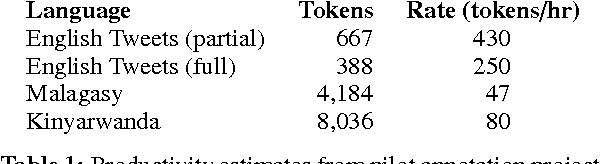

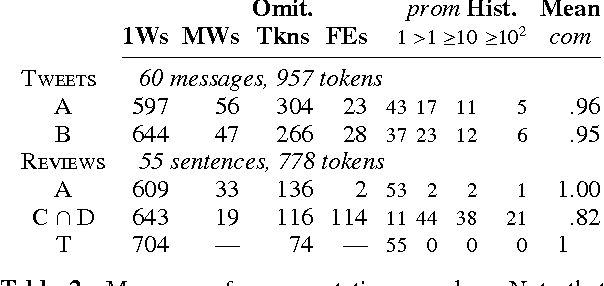
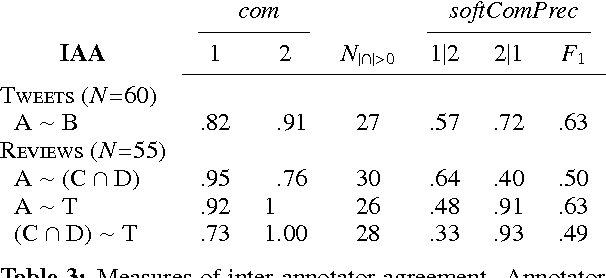
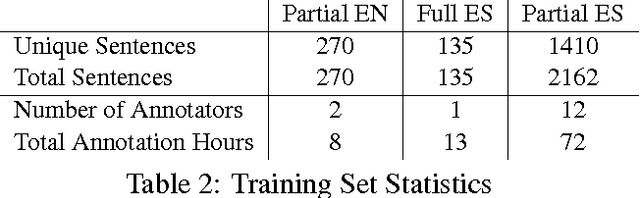
We introduce a framework for lightweight dependency syntax annotation. Our formalism builds upon the typical representation for unlabeled dependencies, permitting a simple notation and annotation workflow. Moreover, the formalism encourages annotators to underspecify parts of the syntax if doing so would streamline the annotation process. We demonstrate the efficacy of this annotation on three languages and develop algorithms to evaluate and compare underspecified annotations.
Dating Texts without Explicit Temporal Cues
Nov 10, 2012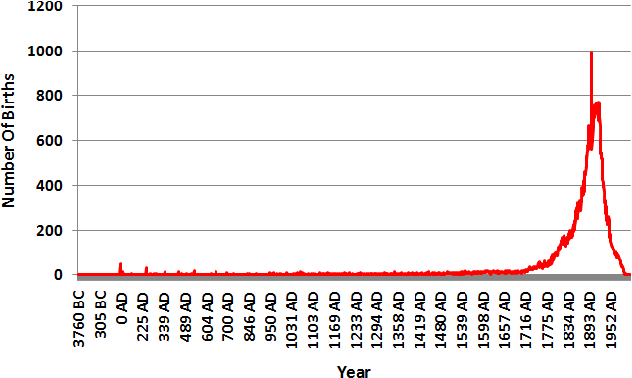

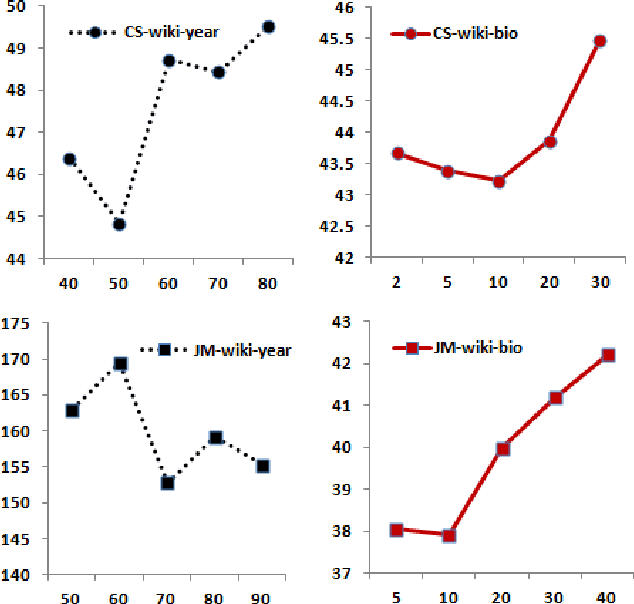
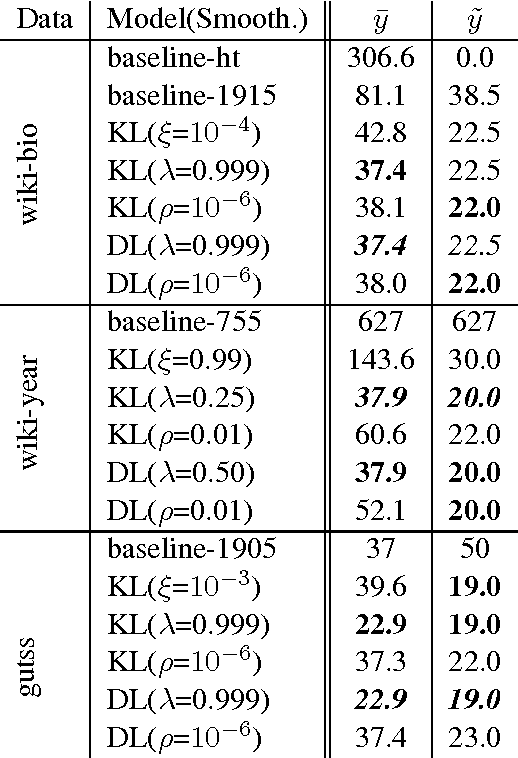
This paper tackles temporal resolution of documents, such as determining when a document is about or when it was written, based only on its text. We apply techniques from information retrieval that predict dates via language models over a discretized timeline. Unlike most previous works, we rely {\it solely} on temporal cues implicit in the text. We consider both document-likelihood and divergence based techniques and several smoothing methods for both of them. Our best model predicts the mid-point of individuals' lives with a median of 22 and mean error of 36 years for Wikipedia biographies from 3800 B.C. to the present day. We also show that this approach works well when training on such biographies and predicting dates both for non-biographical Wikipedia pages about specific years (500 B.C. to 2010 A.D.) and for publication dates of short stories (1798 to 2008). Together, our work shows that, even in absence of temporal extraction resources, it is possible to achieve remarkable temporal locality across a diverse set of texts.