 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Flow Matching for Graph Generation
Jun 07, 2024We present a formulation of flow matching as variational inference, which we refer to as variational flow matching (VFM). Based on this formulation we develop CatFlow, a flow matching method for categorical data. CatFlow is easy to implement, computationally efficient, and achieves strong results on graph generation tasks. In VFM, the objective is to approximate the posterior probability path, which is a distribution over possible end points of a trajectory. We show that VFM admits both the CatFlow objective and the original flow matching objective as special cases. We also relate VFM to score-based models, in which the dynamics are stochastic rather than deterministic, and derive a bound on the model likelihood based on a reweighted VFM objective. We evaluate CatFlow on one abstract graph generation task and two molecular generation tasks. In all cases, CatFlow exceeds or matches performance of the current state-of-the-art models.
Inverse Concave-Utility Reinforcement Learning is Inverse Game Theory
May 29, 2024

We consider inverse reinforcement learning problems with concave utilities. Concave Utility Reinforcement Learning (CURL) is a generalisation of the standard RL objective, which employs a concave function of the state occupancy measure, rather than a linear function. CURL has garnered recent attention for its ability to represent instances of many important applications including the standard RL such as imitation learning, pure exploration, constrained MDPs, offline RL, human-regularized RL, and others. Inverse reinforcement learning is a powerful paradigm that focuses on recovering an unknown reward function that can rationalize the observed behaviour of an agent. There has been recent theoretical advances in inverse RL where the problem is formulated as identifying the set of feasible reward functions. However, inverse RL for CURL problems has not been considered previously. In this paper we show that most of the standard IRL results do not apply to CURL in general, since CURL invalidates the classical Bellman equations. This calls for a new theoretical framework for the inverse CURL problem. Using a recent equivalence result between CURL and Mean-field Games, we propose a new definition for the feasible rewards for I-CURL by proving that this problem is equivalent to an inverse game theory problem in a subclass of mean-field games. We present initial query and sample complexity results for the I-CURL problem under assumptions such as Lipschitz-continuity. Finally, we outline future directions and applications in human--AI collaboration enabled by our results.
VISA: Variational Inference with Sequential Sample-Average Approximations
Mar 15, 2024



We present variational inference with sequential sample-average approximation (VISA), a method for approximate inference in computationally intensive models, such as those based on numerical simulations. VISA extends importance-weighted forward-KL variational inference by employing a sequence of sample-average approximations, which are considered valid inside a trust region. This makes it possible to reuse model evaluations across multiple gradient steps, thereby reducing computational cost. We perform experiments on high-dimensional Gaussians, Lotka-Volterra dynamics, and a Pickover attractor, which demonstrate that VISA can achieve comparable approximation accuracy to standard importance-weighted forward-KL variational inference with computational savings of a factor two or more for conservatively chosen learning rates.
Towards Reducing Diagnostic Errors with Interpretable Risk Prediction
Feb 15, 2024



Many diagnostic errors occur because clinicians cannot easily access relevant information in patient Electronic Health Records (EHRs). In this work we propose a method to use LLMs to identify pieces of evidence in patient EHR data that indicate increased or decreased risk of specific diagnoses; our ultimate aim is to increase access to evidence and reduce diagnostic errors. In particular, we propose a Neural Additive Model to make predictions backed by evidence with individualized risk estimates at time-points where clinicians are still uncertain, aiming to specifically mitigate delays in diagnosis and errors stemming from an incomplete differential. To train such a model, it is necessary to infer temporally fine-grained retrospective labels of eventual "true" diagnoses. We do so with LLMs, to ensure that the input text is from before a confident diagnosis can be made. We use an LLM to retrieve an initial pool of evidence, but then refine this set of evidence according to correlations learned by the model. We conduct an in-depth evaluation of the usefulness of our approach by simulating how it might be used by a clinician to decide between a pre-defined list of differential diagnoses.
Topological Obstructions and How to Avoid Them
Dec 12, 2023



Incorporating geometric inductive biases into models can aid interpretability and generalization, but encoding to a specific geometric structure can be challenging due to the imposed topological constraints. In this paper, we theoretically and empirically characterize obstructions to training encoders with geometric latent spaces. We show that local optima can arise due to singularities (e.g. self-intersection) or due to an incorrect degree or winding number. We then discuss how normalizing flows can potentially circumvent these obstructions by defining multimodal variational distributions. Inspired by this observation, we propose a new flow-based model that maps data points to multimodal distributions over geometric spaces and empirically evaluate our model on 2 domains. We observe improved stability during training and a higher chance of converging to a homeomorphic encoder.
One-shot Imitation Learning via Interaction Warping
Jun 21, 2023



Imitation learning of robot policies from few demonstrations is crucial in open-ended applications. We propose a new method, Interaction Warping, for learning SE(3) robotic manipulation policies from a single demonstration. We infer the 3D mesh of each object in the environment using shape warping, a technique for aligning point clouds across object instances. Then, we represent manipulation actions as keypoints on objects, which can be warped with the shape of the object. We show successful one-shot imitation learning on three simulated and real-world object re-arrangement tasks. We also demonstrate the ability of our method to predict object meshes and robot grasps in the wild.
String Diagrams with Factorized Densities
May 04, 2023
A growing body of research on probabilistic programs and causal models has highlighted the need to reason compositionally about model classes that extend directed graphical models. Both probabilistic programs and causal models define a joint probability density over a set of random variables, and exhibit sparse structure that can be used to reason about causation and conditional independence. This work builds on recent work on Markov categories of probabilistic mappings to define a category whose morphisms combine a joint density, factorized over each sample space, with a deterministic mapping from samples to return values. This is a step towards closing the gap between recent category-theoretic descriptions of probability measures, and the operational definitions of factorized densities that are commonly employed in probabilistic programming and causal inference.
CHiLL: Zero-shot Custom Interpretable Feature Extraction from Clinical Notes with Large Language Models
Feb 23, 2023



Large Language Models (LLMs) have yielded fast and dramatic progress in NLP, and now offer strong few- and zero-shot capabilities on new tasks, reducing the need for annotation. This is especially exciting for the medical domain, in which supervision is often scant and expensive. At the same time, model predictions are rarely so accurate that they can be trusted blindly. Clinicians therefore tend to favor "interpretable" classifiers over opaque LLMs. For example, risk prediction tools are often linear models defined over manually crafted predictors that must be laboriously extracted from EHRs. We propose CHiLL (Crafting High-Level Latents), which uses LLMs to permit natural language specification of high-level features for linear models via zero-shot feature extraction using expert-composed queries. This approach has the promise to empower physicians to use their domain expertise to craft features which are clinically meaningful for a downstream task of interest, without having to manually extract these from raw EHR (as often done now). We are motivated by a real-world risk prediction task, but as a reproducible proxy, we use MIMIC-III and MIMIC-CXR data and standard predictive tasks (e.g., 30-day readmission) to evaluate our approach. We find that linear models using automatically extracted features are comparably performant to models using reference features, and provide greater interpretability than linear models using "Bag-of-Words" features. We verify that learned feature weights align well with clinical expectations.
Verified Reversible Programming for Verified Lossless Compression
Nov 02, 2022
Lossless compression implementations typically contain two programs, an encoder and a decoder, which are required to be inverse to one another. Maintaining consistency between two such programs during development requires care, and incorrect data decoding can be costly and difficult to debug. We observe that a significant class of compression methods, based on asymmetric numeral systems (ANS), have shared structure between the encoder and decoder -- the decoder program is the 'reverse' of the encoder program -- allowing both to be simultaneously specified by a single, reversible, 'codec' function. To exploit this, we have implemented a small reversible language, embedded in Agda, which we call 'Flipper'. Agda supports formal verification of program properties, and the compiler for our reversible language (which is implemented as an Agda macro), produces not just an encoder/decoder pair of functions but also a proof that they are inverse to one another. Thus users of the language get formal verification 'for free'. We give a small example use-case of Flipper in this paper, and plan to publish a full compression implementation soon.
A Variational Perspective on Generative Flow Networks
Oct 14, 2022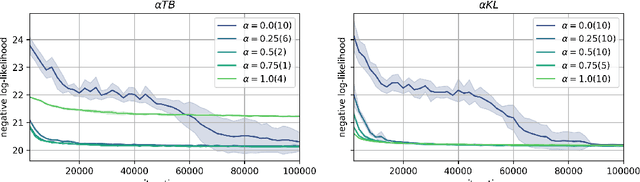
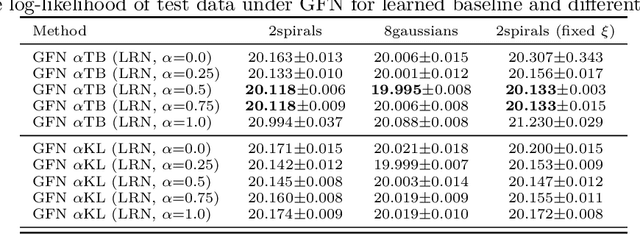
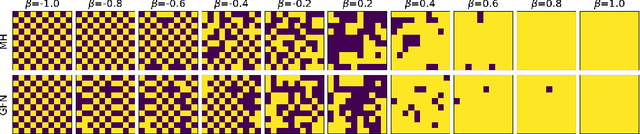

Generative flow networks (GFNs) are a class of models for sequential sampling of composite objects, which approximate a target distribution that is defined in terms of an energy function or a reward. GFNs are typically trained using a flow matching or trajectory balance objective, which matches forward and backward transition models over trajectories. In this work, we define variational objectives for GFNs in terms of the Kullback-Leibler (KL) divergences between the forward and backward distribution. We show that variational inference in GFNs is equivalent to minimizing the trajectory balance objective when sampling trajectories from the forward model. We generalize this approach by optimizing a convex combination of the reverse- and forward KL divergence. This insight suggests variational inference methods can serve as a means to define a more general family of objectives for training generative flow networks, for example by incorporating control variates, which are commonly used in variational inference, to reduce the variance of the gradients of the trajectory balance objective. We evaluate our findings and the performance of the proposed variational objective numerically by comparing it to the trajectory balance objective on two synthetic tasks.