 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeaker adaptation for Wav2vec2 based dysarthric ASR
Apr 02, 2022
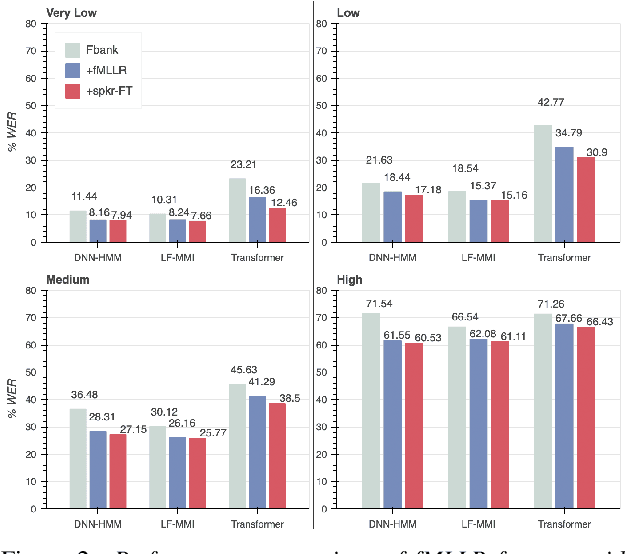
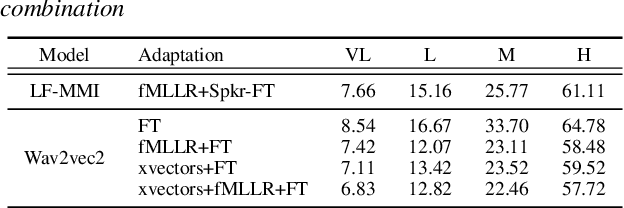
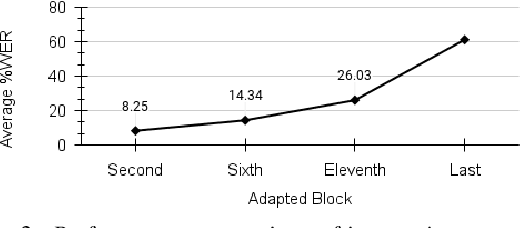
Dysarthric speech recognition has posed major challenges due to lack of training data and heavy mismatch in speaker characteristics. Recent ASR systems have benefited from readily available pretrained models such as wav2vec2 to improve the recognition performance. Speaker adaptation using fMLLR and xvectors have provided major gains for dysarthric speech with very little adaptation data. However, integration of wav2vec2 with fMLLR features or xvectors during wav2vec2 finetuning is yet to be explored. In this work, we propose a simple adaptation network for fine-tuning wav2vec2 using fMLLR features. The adaptation network is also flexible to handle other speaker adaptive features such as xvectors. Experimental analysis show steady improvements using our proposed approach across all impairment severity levels and attains 57.72\% WER for high severity in UASpeech dataset. We also performed experiments on German dataset to substantiate the consistency of our proposed approach across diverse domains.
Training Speaker Embedding Extractors Using Multi-Speaker Audio with Unknown Speaker Boundaries
Mar 29, 2022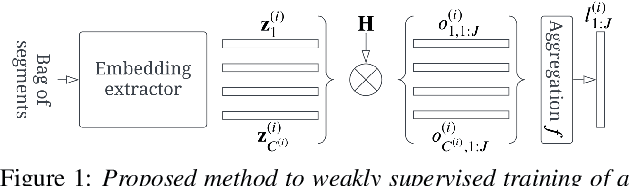
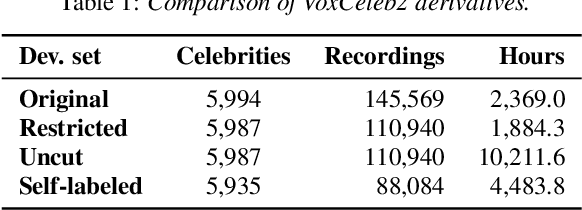
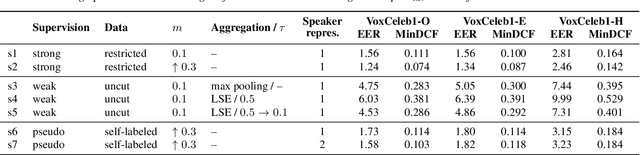
In this paper, we demonstrate a method for training speaker embedding extractors using weak annotation. More specifically, we are using the full VoxCeleb recordings and the name of the celebrities appearing on each video without knowledge of the time intervals the celebrities appear in the video. We show that by combining a baseline speaker diarization algorithm that requires no training or parameter tuning, a modified loss with aggregation over segments, and a two-stage training approach, we are able to train a competitive ResNet-based embedding extractor. Finally, we experiment with two different aggregation functions and analyze their behaviour in terms of their gradients.
EAT: Enhanced ASR-TTS for Self-supervised Speech Recognition
Apr 13, 2021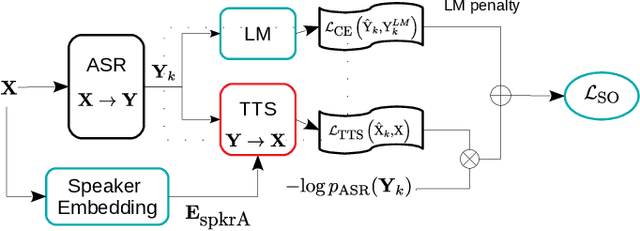
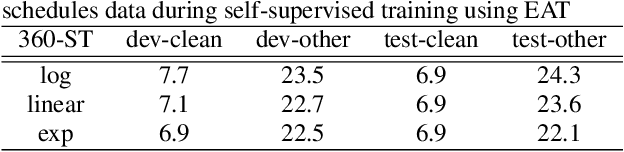
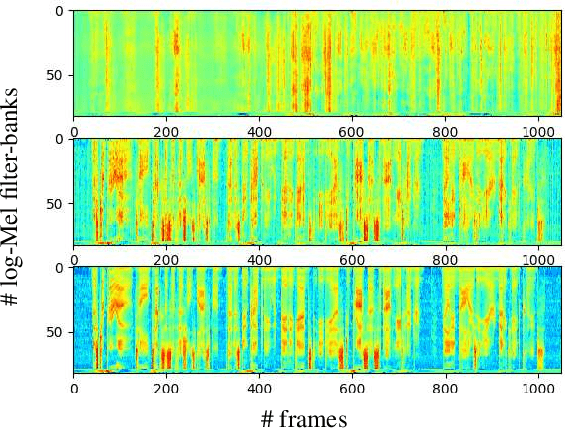
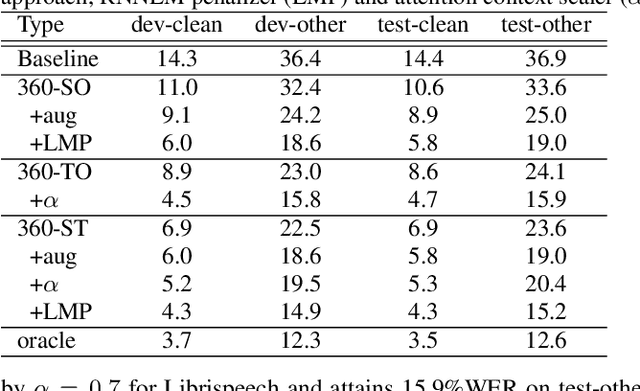
Self-supervised ASR-TTS models suffer in out-of-domain data conditions. Here we propose an enhanced ASR-TTS (EAT) model that incorporates two main features: 1) The ASR$\rightarrow$TTS direction is equipped with a language model reward to penalize the ASR hypotheses before forwarding it to TTS. 2) In the TTS$\rightarrow$ASR direction, a hyper-parameter is introduced to scale the attention context from synthesized speech before sending it to ASR to handle out-of-domain data. Training strategies and the effectiveness of the EAT model are explored under out-of-domain data conditions. The results show that EAT reduces the performance gap between supervised and self-supervised training significantly by absolute 2.6\% and 2.7\% on Librispeech and BABEL respectively.
BUT Opensat 2019 Speech Recognition System
Jan 30, 2020
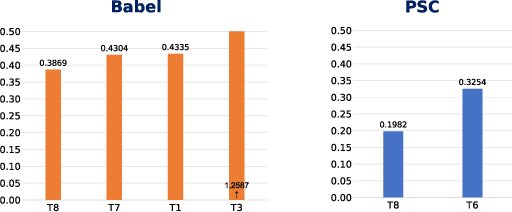


The paper describes the BUT Automatic Speech Recognition (ASR) systems submitted for OpenSAT evaluations under two domain categories such as low resourced languages and public safety communications. The first was challenging due to lack of training data, therefore various architectures and multilingual approaches were employed. The combination led to superior performance. The second domain was challenging due to recording in extreme conditions such as specific channel, speaker under stress and high levels of noise. Data augmentation process was inevitable to get reasonably good performance.
A Multi Purpose and Large Scale Speech Corpus in Persian and English for Speaker and Speech Recognition: the DeepMine Database
Dec 08, 2019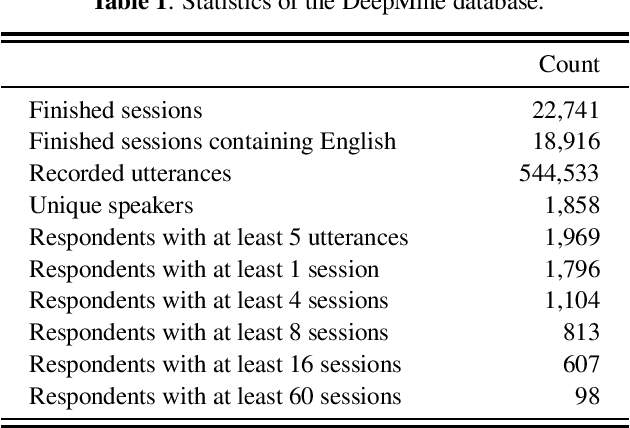

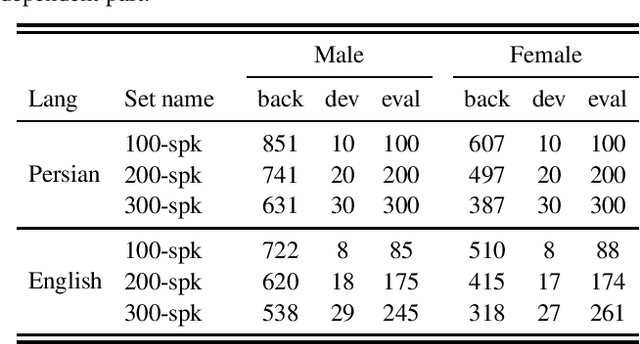
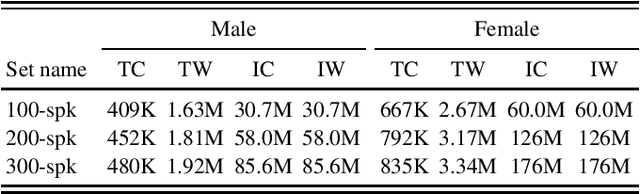
DeepMine is a speech database in Persian and English designed to build and evaluate text-dependent, text-prompted, and text-independent speaker verification, as well as Persian speech recognition systems. It contains more than 1850 speakers and 540 thousand recordings overall, more than 480 hours of speech are transcribed. It is the first public large-scale speaker verification database in Persian, the largest public text-dependent and text-prompted speaker verification database in English, and the largest public evaluation dataset for text-independent speaker verification. It has a good coverage of age, gender, and accents. We provide several evaluation protocols for each part of the database to allow for research on different aspects of speaker verification. We also provide the results of several experiments that can be considered as baselines: HMM-based i-vectors for text-dependent speaker verification, and HMM-based as well as state-of-the-art deep neural network based ASR. We demonstrate that the database can serve for training robust ASR models.
Detecting Spoofing Attacks Using VGG and SincNet: BUT-Omilia Submission to ASVspoof 2019 Challenge
Jul 13, 2019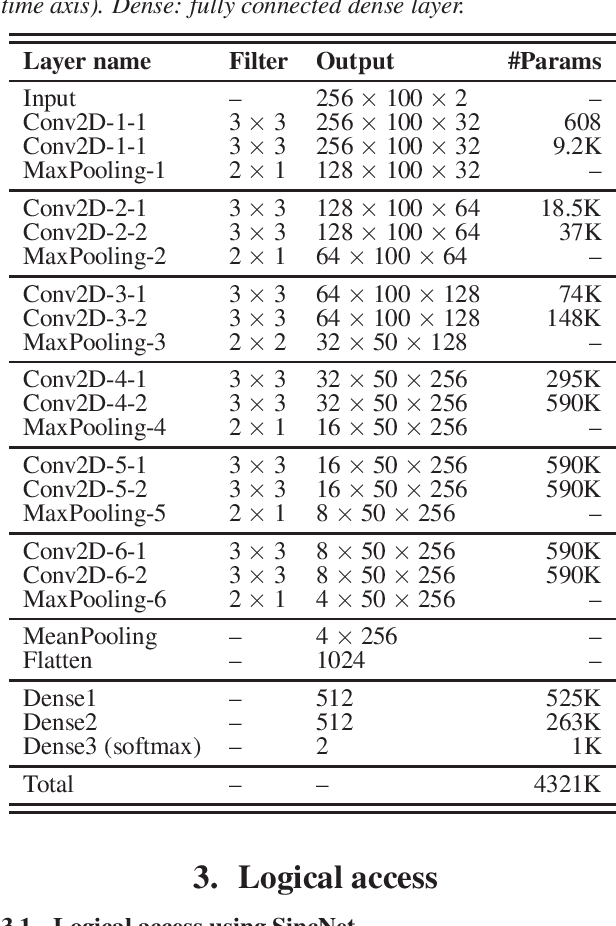
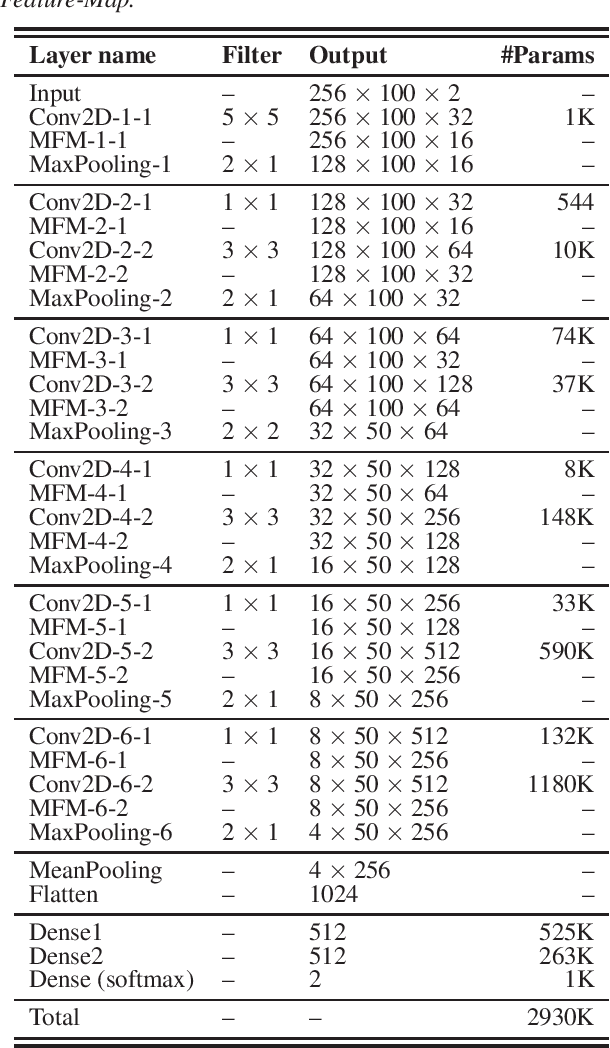
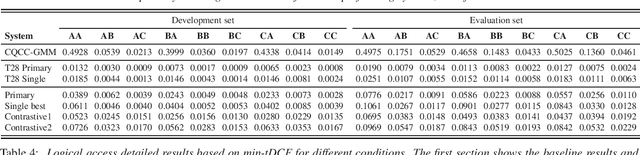
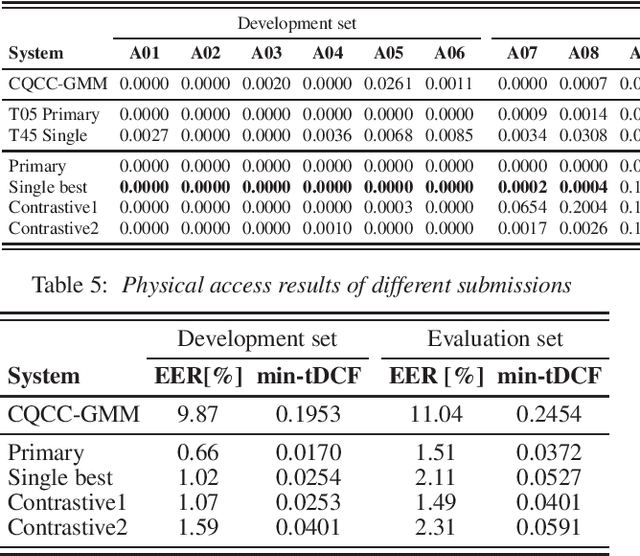
In this paper, we present the system description of the joint efforts of Brno University of Technology (BUT) and Omilia -- Conversational Intelligence for the ASVSpoof2019 Spoofing and Countermeasures Challenge. The primary submission for Physical access (PA) is a fusion of two VGG networks, trained on single and two-channels features. For Logical access (LA), our primary system is a fusion of VGG and the recently introduced SincNet architecture. The results on PA show that the proposed networks yield very competitive performance in all conditions and achieved 86\:\% relative improvement compared to the official baseline. On the other hand, the results on LA showed that although the proposed architecture and training strategy performs very well on certain spoofing attacks, it fails to generalize to certain attacks that are unseen during training.
Analysis of Multilingual Sequence-to-Sequence speech recognition systems
Nov 07, 2018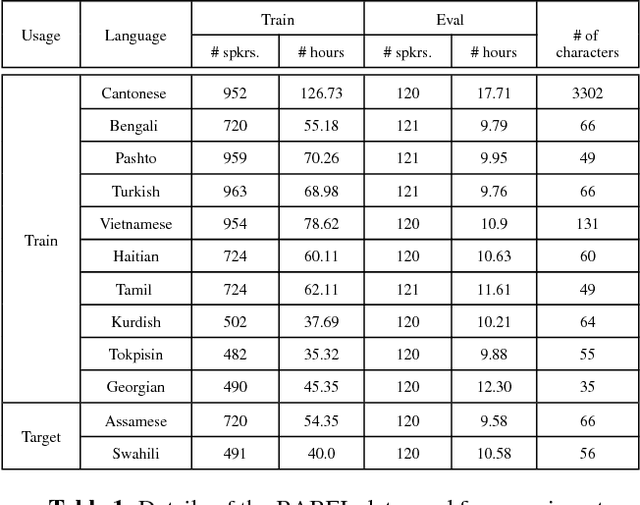
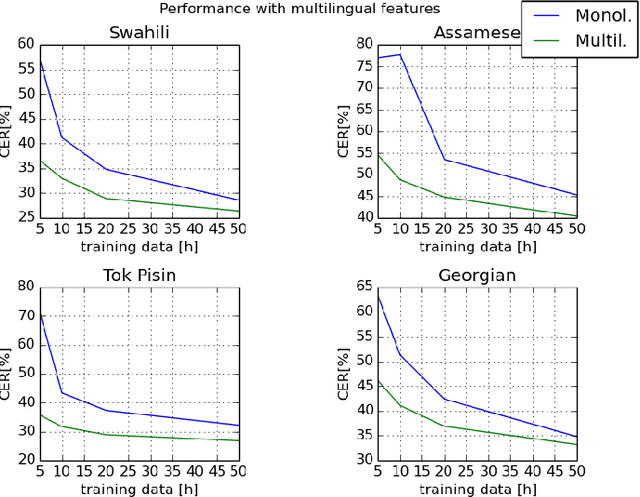
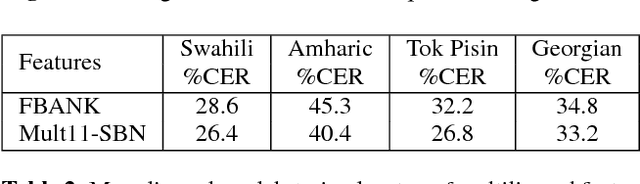
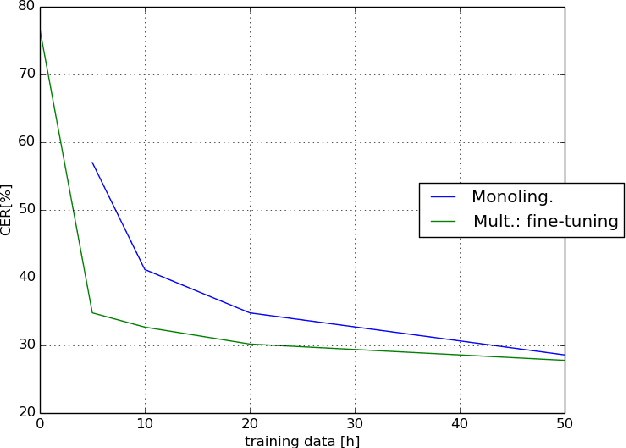
This paper investigates the applications of various multilingual approaches developed in conventional hidden Markov model (HMM) systems to sequence-to-sequence (seq2seq) automatic speech recognition (ASR). On a set composed of Babel data, we first show the effectiveness of multi-lingual training with stacked bottle-neck (SBN) features. Then we explore various architectures and training strategies of multi-lingual seq2seq models based on CTC-attention networks including combinations of output layer, CTC and/or attention component re-training. We also investigate the effectiveness of language-transfer learning in a very low resource scenario when the target language is not included in the original multi-lingual training data. Interestingly, we found multilingual features superior to multilingual models, and this finding suggests that we can efficiently combine the benefits of the HMM system with the seq2seq system through these multilingual feature techniques.