 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAM: Generalization in Deep RL with a Robust Adaptation Module
Dec 05, 2024



The reliable deployment of deep reinforcement learning in real-world settings requires the ability to generalize across a variety of conditions, including both in-distribution scenarios seen during training as well as novel out-of-distribution scenarios. In this work, we present a framework for dynamics generalization in deep reinforcement learning that unifies these two distinct types of generalization within a single architecture. We introduce a robust adaptation module that provides a mechanism for identifying and reacting to both in-distribution and out-of-distribution environment dynamics, along with a joint training pipeline that combines the goals of in-distribution adaptation and out-of-distribution robustness. Our algorithm GRAM achieves strong generalization performance across in-distribution and out-of-distribution scenarios upon deployment, which we demonstrate on a variety of realistic simulated locomotion tasks with a quadruped robot.
PIETRA: Physics-Informed Evidential Learning for Traversing Out-of-Distribution Terrain
Sep 04, 2024



Self-supervised learning is a powerful approach for developing traversability models for off-road navigation, but these models often struggle with inputs unseen during training. Existing methods utilize techniques like evidential deep learning to quantify model uncertainty, helping to identify and avoid out-of-distribution terrain. However, always avoiding out-of-distribution terrain can be overly conservative, e.g., when novel terrain can be effectively analyzed using a physics-based model. To overcome this challenge, we introduce Physics-Informed Evidential Traversability (PIETRA), a self-supervised learning framework that integrates physics priors directly into the mathematical formulation of evidential neural networks and introduces physics knowledge implicitly through an uncertainty-aware, physics-informed training loss. Our evidential network seamlessly transitions between learned and physics-based predictions for out-of-distribution inputs. Additionally, the physics-informed loss regularizes the learned model, ensuring better alignment with the physics model. Extensive simulations and hardware experiments demonstrate that PIETRA improves both learning accuracy and navigation performance in environments with significant distribution shifts.
Provably Efficient Off-Policy Adversarial Imitation Learning with Convergence Guarantees
May 26, 2024

Adversarial Imitation Learning (AIL) faces challenges with sample inefficiency because of its reliance on sufficient on-policy data to evaluate the performance of the current policy during reward function updates. In this work, we study the convergence properties and sample complexity of off-policy AIL algorithms. We show that, even in the absence of importance sampling correction, reusing samples generated by the $o(\sqrt{K})$ most recent policies, where $K$ is the number of iterations of policy updates and reward updates, does not undermine the convergence guarantees of this class of algorithms. Furthermore, our results indicate that the distribution shift error induced by off-policy updates is dominated by the benefits of having more data available. This result provides theoretical support for the sample efficiency of off-policy AIL algorithms. To the best of our knowledge, this is the first work that provides theoretical guarantees for off-policy AIL algorithms.
A Model-Based Approach for Improving Reinforcement Learning Efficiency Leveraging Expert Observations
Feb 29, 2024



This paper investigates how to incorporate expert observations (without explicit information on expert actions) into a deep reinforcement learning setting to improve sample efficiency. First, we formulate an augmented policy loss combining a maximum entropy reinforcement learning objective with a behavioral cloning loss that leverages a forward dynamics model. Then, we propose an algorithm that automatically adjusts the weights of each component in the augmented loss function. Experiments on a variety of continuous control tasks demonstrate that the proposed algorithm outperforms various benchmarks by effectively utilizing available expert observations.
Adversarial Imitation Learning from Visual Observations using Latent Information
Sep 29, 2023
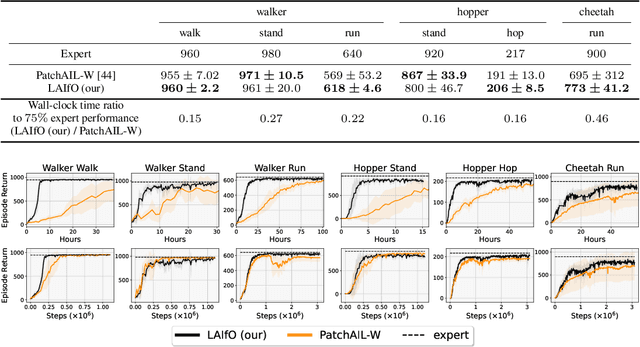


We focus on the problem of imitation learning from visual observations, where the learning agent has access to videos of experts as its sole learning source. The challenges of this framework include the absence of expert actions and the partial observability of the environment, as the ground-truth states can only be inferred from pixels. To tackle this problem, we first conduct a theoretical analysis of imitation learning in partially observable environments. We establish upper bounds on the suboptimality of the learning agent with respect to the divergence between the expert and the agent latent state-transition distributions. Motivated by this analysis, we introduce an algorithm called Latent Adversarial Imitation from Observations, which combines off-policy adversarial imitation techniques with a learned latent representation of the agent's state from sequences of observations. In experiments on high-dimensional continuous robotic tasks, we show that our algorithm matches state-of-the-art performance while providing significant computational advantages. Additionally, we show how our method can be used to improve the efficiency of reinforcement learning from pixels by leveraging expert videos. To ensure reproducibility, we provide free access to our code.
Optimal Transport Perturbations for Safe Reinforcement Learning with Robustness Guarantees
Jan 31, 2023



Robustness and safety are critical for the trustworthy deployment of deep reinforcement learning in real-world decision making applications. In particular, we require algorithms that can guarantee robust, safe performance in the presence of general environment disturbances, while making limited assumptions on the data collection process during training. In this work, we propose a safe reinforcement learning framework with robustness guarantees through the use of an optimal transport cost uncertainty set. We provide an efficient, theoretically supported implementation based on Optimal Transport Perturbations, which can be applied in a completely offline fashion using only data collected in a nominal training environment. We demonstrate the robust, safe performance of our approach on a variety of continuous control tasks with safety constraints in the Real-World Reinforcement Learning Suite.
Risk-Averse Model Uncertainty for Distributionally Robust Safe Reinforcement Learning
Jan 30, 2023Many real-world domains require safe decision making in the presence of uncertainty. In this work, we propose a deep reinforcement learning framework for approaching this important problem. We consider a risk-averse perspective towards model uncertainty through the use of coherent distortion risk measures, and we show that our formulation is equivalent to a distributionally robust safe reinforcement learning problem with robustness guarantees on performance and safety. We propose an efficient implementation that only requires access to a single training environment, and we demonstrate that our framework produces robust, safe performance on a variety of continuous control tasks with safety constraints in the Real-World Reinforcement Learning Suite.
Generalized Policy Improvement Algorithms with Theoretically Supported Sample Reuse
Jun 28, 2022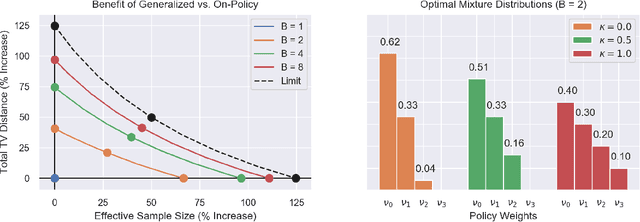

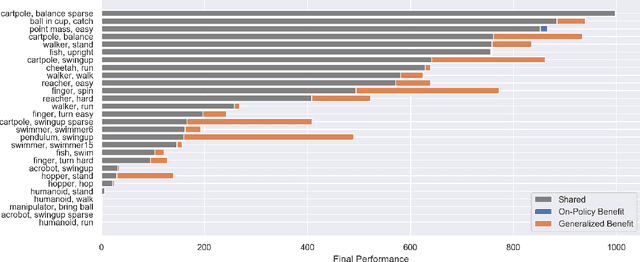
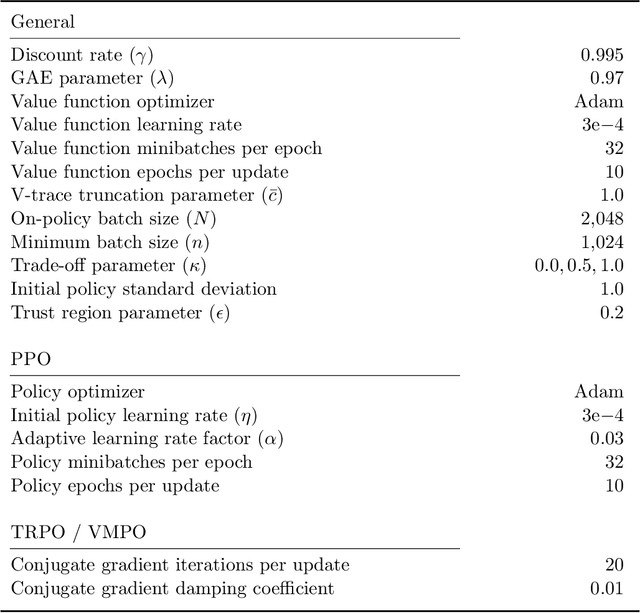
Real-world sequential decision making requires data-driven algorithms that provide practical guarantees on performance throughout training while also making efficient use of data. Model-free deep reinforcement learning represents a framework for such data-driven decision making, but existing algorithms typically only focus on one of these goals while sacrificing performance with respect to the other. On-policy algorithms guarantee policy improvement throughout training but suffer from high sample complexity, while off-policy algorithms make efficient use of data through sample reuse but lack theoretical guarantees. In order to balance these competing goals, we develop a class of Generalized Policy Improvement algorithms that combines the policy improvement guarantees of on-policy methods with the efficiency of theoretically supported sample reuse. We demonstrate the benefits of this new class of algorithms through extensive experimental analysis on a variety of continuous control tasks from the DeepMind Control Suite.
Generalized Proximal Policy Optimization with Sample Reuse
Oct 29, 2021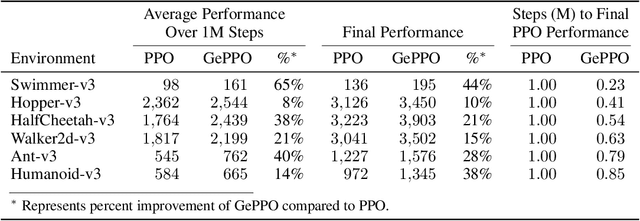
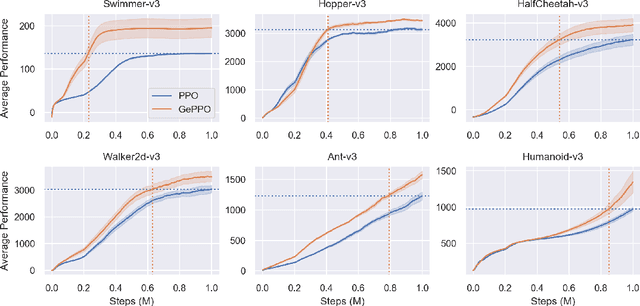
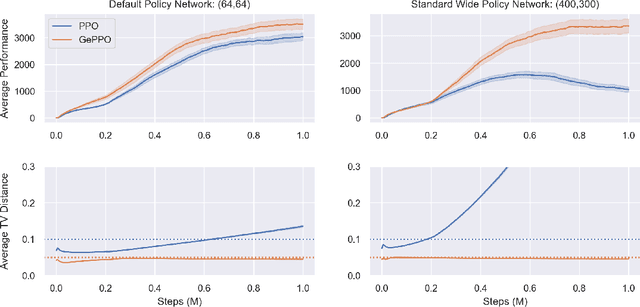
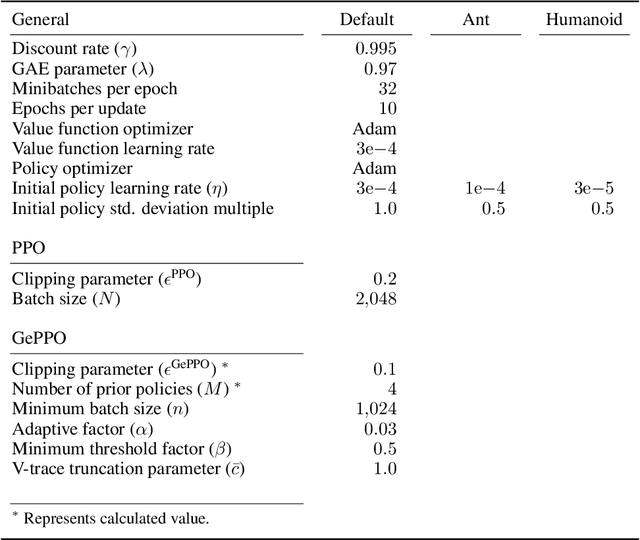
In real-world decision making tasks, it is critical for data-driven reinforcement learning methods to be both stable and sample efficient. On-policy methods typically generate reliable policy improvement throughout training, while off-policy methods make more efficient use of data through sample reuse. In this work, we combine the theoretically supported stability benefits of on-policy algorithms with the sample efficiency of off-policy algorithms. We develop policy improvement guarantees that are suitable for the off-policy setting, and connect these bounds to the clipping mechanism used in Proximal Policy Optimization. This motivates an off-policy version of the popular algorithm that we call Generalized Proximal Policy Optimization with Sample Reuse. We demonstrate both theoretically and empirically that our algorithm delivers improved performance by effectively balancing the competing goals of stability and sample efficiency.
Uncertainty-Aware Policy Optimization: A Robust, Adaptive Trust Region Approach
Dec 19, 2020



In order for reinforcement learning techniques to be useful in real-world decision making processes, they must be able to produce robust performance from limited data. Deep policy optimization methods have achieved impressive results on complex tasks, but their real-world adoption remains limited because they often require significant amounts of data to succeed. When combined with small sample sizes, these methods can result in unstable learning due to their reliance on high-dimensional sample-based estimates. In this work, we develop techniques to control the uncertainty introduced by these estimates. We leverage these techniques to propose a deep policy optimization approach designed to produce stable performance even when data is scarce. The resulting algorithm, Uncertainty-Aware Trust Region Policy Optimization, generates robust policy updates that adapt to the level of uncertainty present throughout the learning process.