 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Robustness through Local Linearization
Jul 04, 2019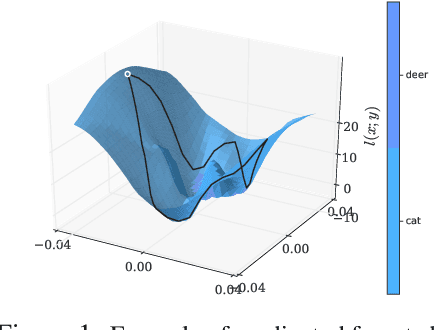
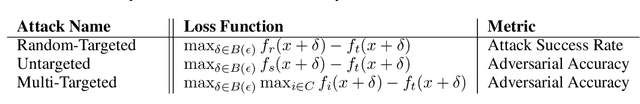
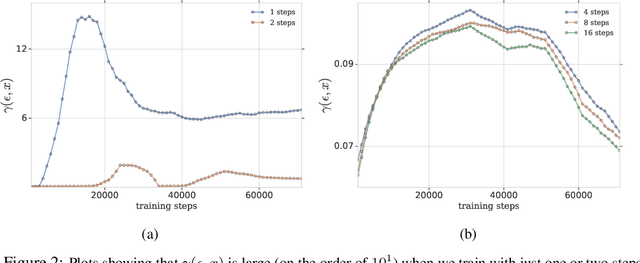
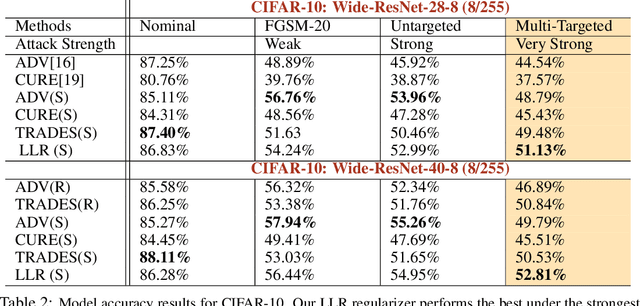
Adversarial training is an effective methodology for training deep neural networks that are robust against adversarial, norm-bounded perturbations. However, the computational cost of adversarial training grows prohibitively as the size of the model and number of input dimensions increase. Further, training against less expensive and therefore weaker adversaries produces models that are robust against weak attacks but break down under attacks that are stronger. This is often attributed to the phenomenon of gradient obfuscation; such models have a highly non-linear loss surface in the vicinity of training examples, making it hard for gradient-based attacks to succeed even though adversarial examples still exist. In this work, we introduce a novel regularizer that encourages the loss to behave linearly in the vicinity of the training data, thereby penalizing gradient obfuscation while encouraging robustness. We show via extensive experiments on CIFAR-10 and ImageNet, that models trained with our regularizer avoid gradient obfuscation and can be trained significantly faster than adversarial training. Using this regularizer, we exceed current state of the art and achieve 47% adversarial accuracy for ImageNet with l-infinity adversarial perturbations of radius 4/255 under an untargeted, strong, white-box attack. Additionally, we match state of the art results for CIFAR-10 at 8/255.
Fast Convergence of Natural Gradient Descent for Overparameterized Neural Networks
May 27, 2019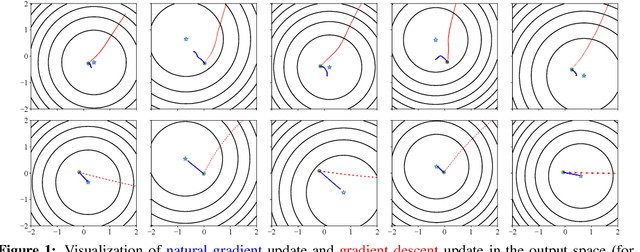
Natural gradient descent has proven effective at mitigating the effects of pathological curvature in neural network optimization, but little is known theoretically about its convergence properties, especially for \emph{nonlinear} networks. In this work, we analyze \emph{for the first time} the speed of convergence for natural gradient descent on nonlinear neural networks with the squared-error loss. We identify two conditions which guarantee the efficient convergence from random initializations: (1) the Jacobian matrix (of network's output for all training cases with respect to the parameters) is full row rank, and (2) the Jacobian matrix is stable for small perturbations around the initialization. For two-layer ReLU neural networks (i.e., with one hidden layer), we prove that these two conditions do in fact hold throughout the training, under the assumptions of nondegenerate inputs and overparameterization. We further extend our analysis to more general loss functions. Lastly, we show that K-FAC, an approximate natural gradient descent method, also converges to global minima under the same assumptions.
Differentiable Game Mechanics
May 13, 2019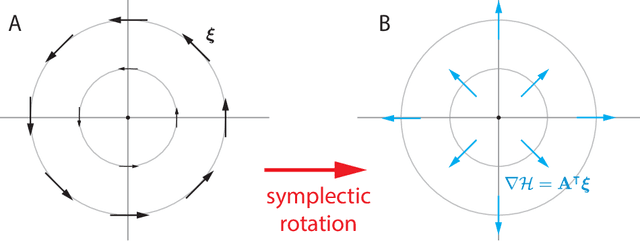
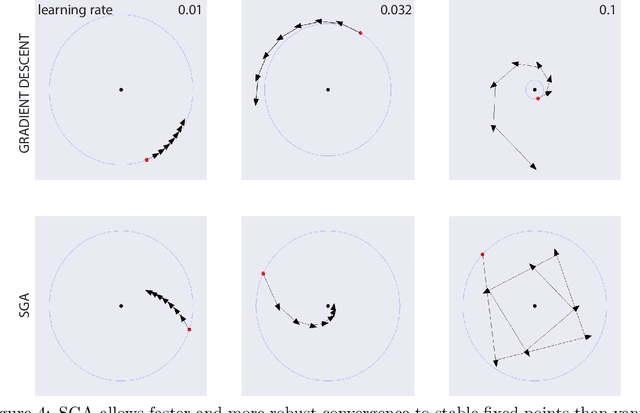
Deep learning is built on the foundational guarantee that gradient descent on an objective function converges to local minima. Unfortunately, this guarantee fails in settings, such as generative adversarial nets, that exhibit multiple interacting losses. The behavior of gradient-based methods in games is not well understood -- and is becoming increasingly important as adversarial and multi-objective architectures proliferate. In this paper, we develop new tools to understand and control the dynamics in n-player differentiable games. The key result is to decompose the game Jacobian into two components. The first, symmetric component, is related to potential games, which reduce to gradient descent on an implicit function. The second, antisymmetric component, relates to Hamiltonian games, a new class of games that obey a conservation law akin to conservation laws in classical mechanical systems. The decomposition motivates Symplectic Gradient Adjustment (SGA), a new algorithm for finding stable fixed points in differentiable games. Basic experiments show SGA is competitive with recently proposed algorithms for finding stable fixed points in GANs -- while at the same time being applicable to, and having guarantees in, much more general cases.
* JMLR 2019, journal version of arXiv:1802.05642
On the Variance of Unbiased Online Recurrent Optimization
Feb 06, 2019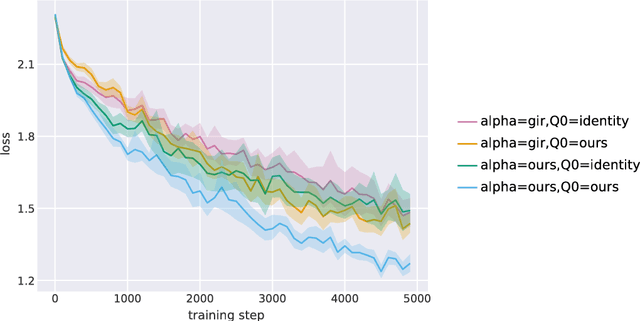
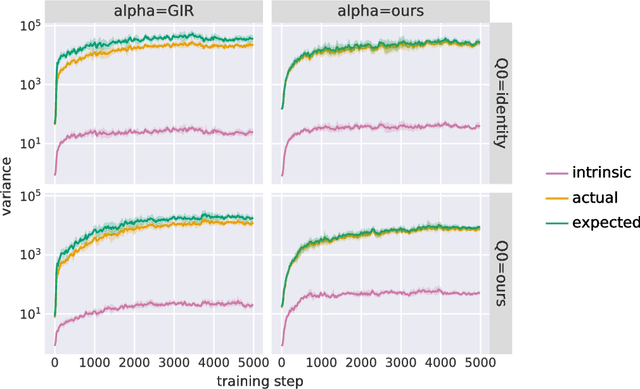
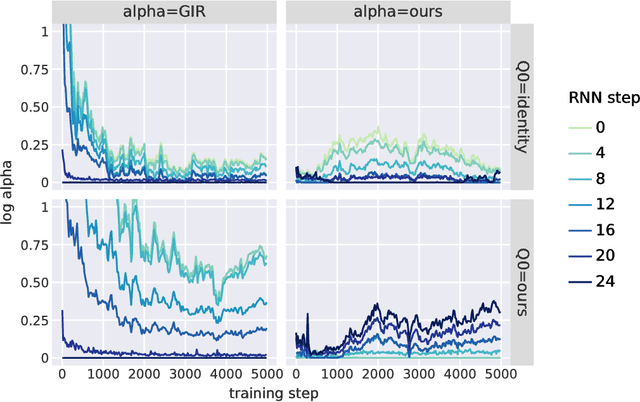
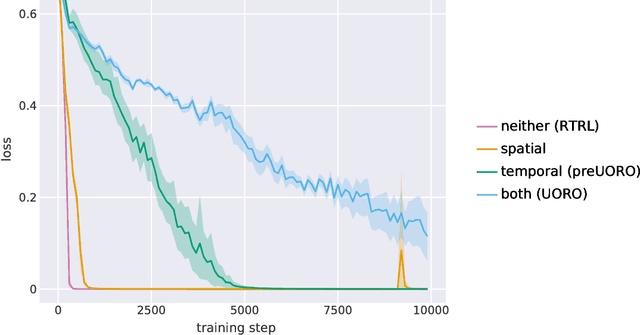
The recently proposed Unbiased Online Recurrent Optimization algorithm (UORO, arXiv:1702.05043) uses an unbiased approximation of RTRL to achieve fully online gradient-based learning in RNNs. In this work we analyze the variance of the gradient estimate computed by UORO, and propose several possible changes to the method which reduce this variance both in theory and practice. We also contribute significantly to the theoretical and intuitive understanding of UORO (and its existing variance reduction technique), and demonstrate a fundamental connection between its gradient estimate and the one that would be computed by REINFORCE if small amounts of noise were added to the RNN's hidden units.
The Mechanics of n-Player Differentiable Games
Jun 06, 2018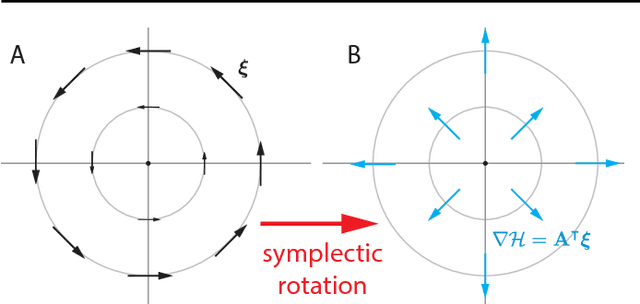
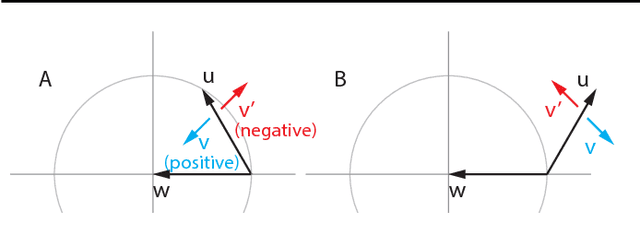
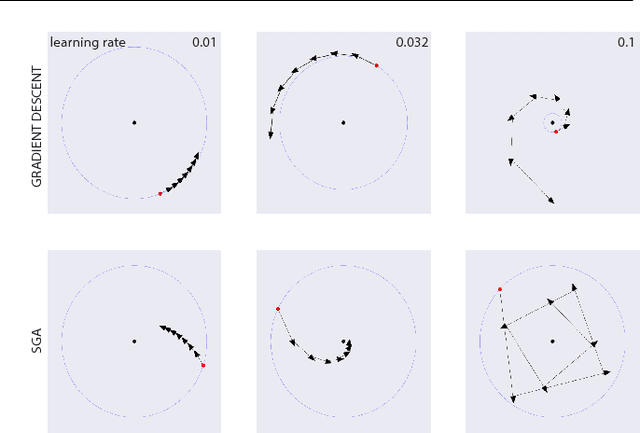
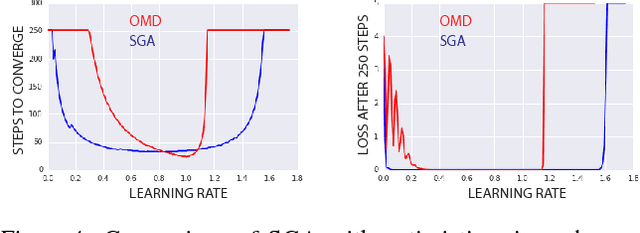
The cornerstone underpinning deep learning is the guarantee that gradient descent on an objective converges to local minima. Unfortunately, this guarantee fails in settings, such as generative adversarial nets, where there are multiple interacting losses. The behavior of gradient-based methods in games is not well understood -- and is becoming increasingly important as adversarial and multi-objective architectures proliferate. In this paper, we develop new techniques to understand and control the dynamics in general games. The key result is to decompose the second-order dynamics into two components. The first is related to potential games, which reduce to gradient descent on an implicit function; the second relates to Hamiltonian games, a new class of games that obey a conservation law, akin to conservation laws in classical mechanical systems. The decomposition motivates Symplectic Gradient Adjustment (SGA), a new algorithm for finding stable fixed points in general games. Basic experiments show SGA is competitive with recently proposed algorithms for finding stable fixed points in GANs -- whilst at the same time being applicable to -- and having guarantees in -- much more general games.
* ICML 2018, final version
New insights and perspectives on the natural gradient method
Nov 21, 2017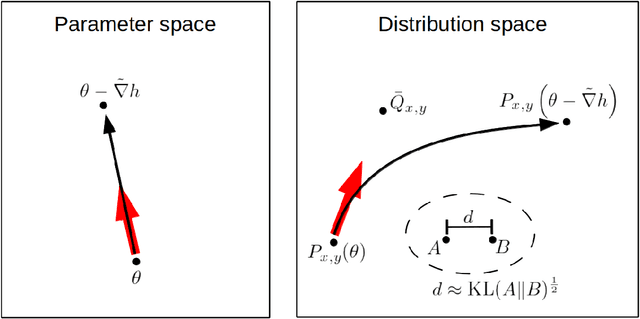
Natural gradient descent is an optimization method traditionally motivated from the perspective of information geometry, and works well for many applications as an alternative to stochastic gradient descent. In this paper we critically analyze this method and its properties, and show how it can be viewed as a type of approximate 2nd-order optimization method, where the Fisher information matrix can be viewed as an approximation of the Hessian. This perspective turns out to have significant implications for how to design a practical and robust version of the method. Additionally, we make the following contributions to the understanding of natural gradient and 2nd-order methods: a thorough analysis of the convergence speed of stochastic natural gradient descent (and more general stochastic 2nd-order methods) as applied to convex quadratics, a critical examination of the oft-used "empirical" approximation of the Fisher matrix, and an analysis of the (approximate) parameterization invariance property possessed by natural gradient methods, which we show still holds for certain choices of the curvature matrix other than the Fisher, but notably not the Hessian.
A Kronecker-factored approximate Fisher matrix for convolution layers
May 23, 2016
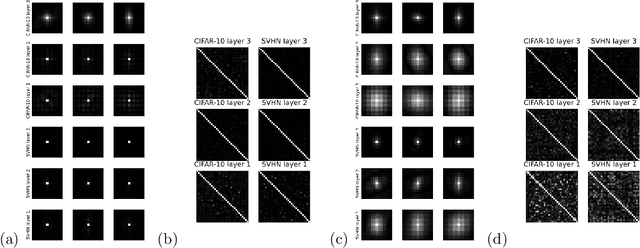

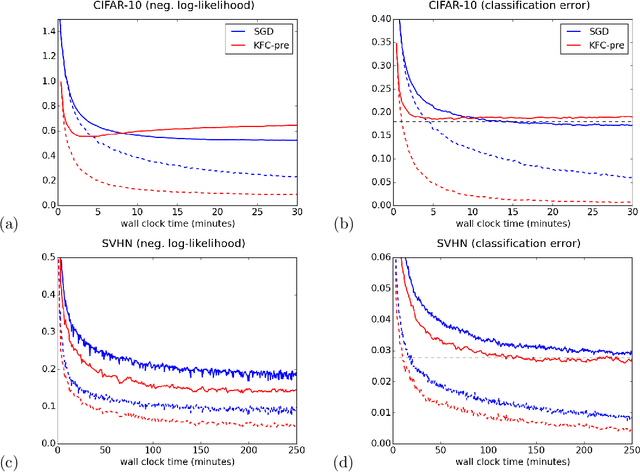
Second-order optimization methods such as natural gradient descent have the potential to speed up training of neural networks by correcting for the curvature of the loss function. Unfortunately, the exact natural gradient is impractical to compute for large models, and most approximations either require an expensive iterative procedure or make crude approximations to the curvature. We present Kronecker Factors for Convolution (KFC), a tractable approximation to the Fisher matrix for convolutional networks based on a structured probabilistic model for the distribution over backpropagated derivatives. Similarly to the recently proposed Kronecker-Factored Approximate Curvature (K-FAC), each block of the approximate Fisher matrix decomposes as the Kronecker product of small matrices, allowing for efficient inversion. KFC captures important curvature information while still yielding comparably efficient updates to stochastic gradient descent (SGD). We show that the updates are invariant to commonly used reparameterizations, such as centering of the activations. In our experiments, approximate natural gradient descent with KFC was able to train convolutional networks several times faster than carefully tuned SGD. Furthermore, it was able to train the networks in 10-20 times fewer iterations than SGD, suggesting its potential applicability in a distributed setting.
Optimizing Neural Networks with Kronecker-factored Approximate Curvature
May 04, 2016

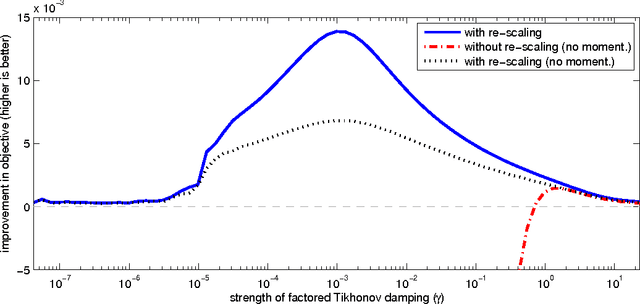
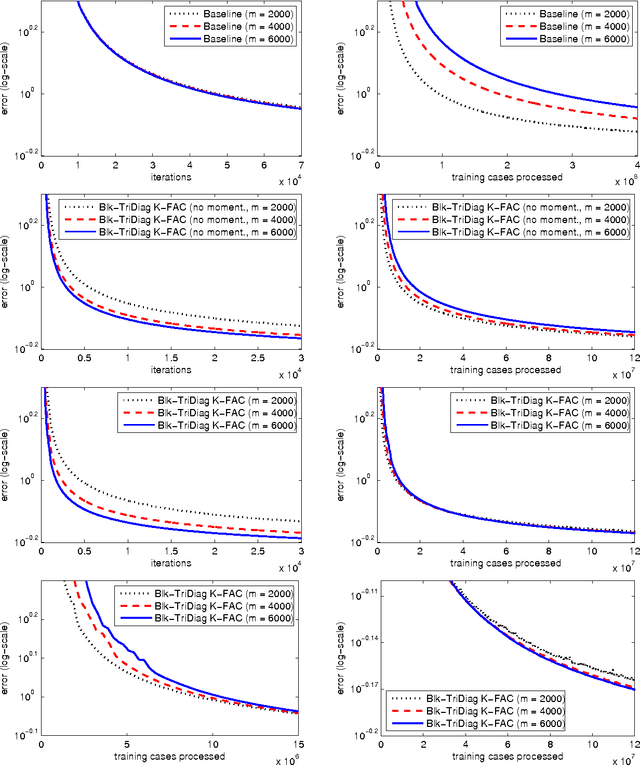
We propose an efficient method for approximating natural gradient descent in neural networks which we call Kronecker-Factored Approximate Curvature (K-FAC). K-FAC is based on an efficiently invertible approximation of a neural network's Fisher information matrix which is neither diagonal nor low-rank, and in some cases is completely non-sparse. It is derived by approximating various large blocks of the Fisher (corresponding to entire layers) as being the Kronecker product of two much smaller matrices. While only several times more expensive to compute than the plain stochastic gradient, the updates produced by K-FAC make much more progress optimizing the objective, which results in an algorithm that can be much faster than stochastic gradient descent with momentum in practice. And unlike some previously proposed approximate natural-gradient/Newton methods which use high-quality non-diagonal curvature matrices (such as Hessian-free optimization), K-FAC works very well in highly stochastic optimization regimes. This is because the cost of storing and inverting K-FAC's approximation to the curvature matrix does not depend on the amount of data used to estimate it, which is a feature typically associated only with diagonal or low-rank approximations to the curvature matrix.
Adding Gradient Noise Improves Learning for Very Deep Networks
Nov 21, 2015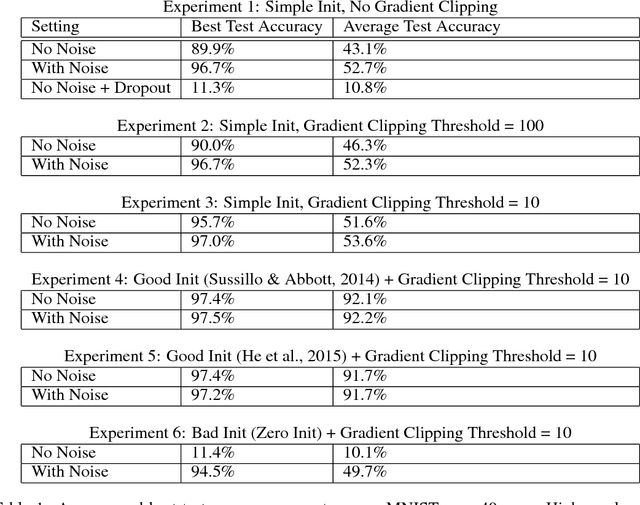

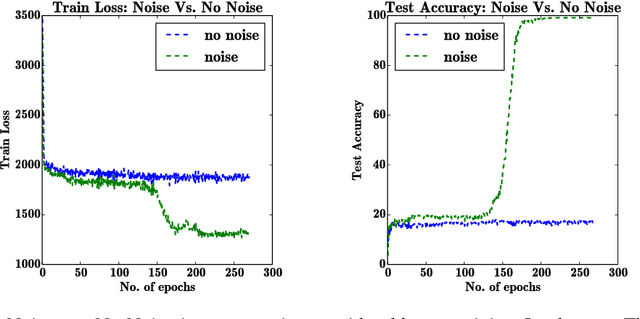
Deep feedforward and recurrent networks have achieved impressive results in many perception and language processing applications. This success is partially attributed to architectural innovations such as convolutional and long short-term memory networks. The main motivation for these architectural innovations is that they capture better domain knowledge, and importantly are easier to optimize than more basic architectures. Recently, more complex architectures such as Neural Turing Machines and Memory Networks have been proposed for tasks including question answering and general computation, creating a new set of optimization challenges. In this paper, we discuss a low-overhead and easy-to-implement technique of adding gradient noise which we find to be surprisingly effective when training these very deep architectures. The technique not only helps to avoid overfitting, but also can result in lower training loss. This method alone allows a fully-connected 20-layer deep network to be trained with standard gradient descent, even starting from a poor initialization. We see consistent improvements for many complex models, including a 72% relative reduction in error rate over a carefully-tuned baseline on a challenging question-answering task, and a doubling of the number of accurate binary multiplication models learned across 7,000 random restarts. We encourage further application of this technique to additional complex modern architectures.
On the Expressive Efficiency of Sum Product Networks
Jan 23, 2015Sum Product Networks (SPNs) are a recently developed class of deep generative models which compute their associated unnormalized density functions using a special type of arithmetic circuit. When certain sufficient conditions, called the decomposability and completeness conditions (or "D&C" conditions), are imposed on the structure of these circuits, marginal densities and other useful quantities, which are typically intractable for other deep generative models, can be computed by what amounts to a single evaluation of the network (which is a property known as "validity"). However, the effect that the D&C conditions have on the capabilities of D&C SPNs is not well understood. In this work we analyze the D&C conditions, expose the various connections that D&C SPNs have with multilinear arithmetic circuits, and consider the question of how well they can capture various distributions as a function of their size and depth. Among our various contributions is a result which establishes the existence of a relatively simple distribution with fully tractable marginal densities which cannot be efficiently captured by D&C SPNs of any depth, but which can be efficiently captured by various other deep generative models. We also show that with each additional layer of depth permitted, the set of distributions which can be efficiently captured by D&C SPNs grows in size. This kind of "depth hierarchy" property has been widely conjectured to hold for various deep models, but has never been proven for any of them. Some of our other contributions include a new characterization of the D&C conditions as sufficient and necessary ones for a slightly strengthened notion of validity, and various state-machine characterizations of the types of computations that can be performed efficiently by D&C SPNs.