 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transfer Learning for End-to-End Speech Synthesis from Deep Pre-Trained Language Models
Jun 17, 2019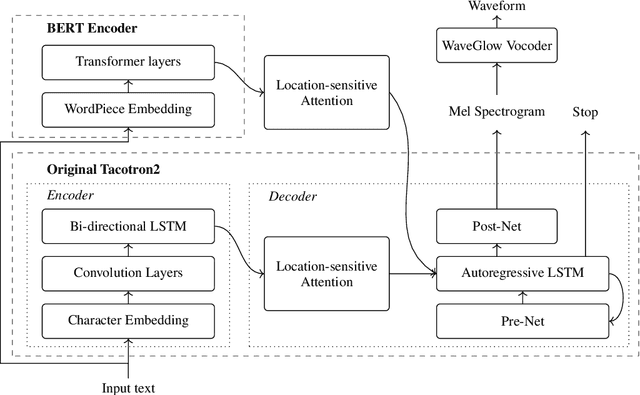

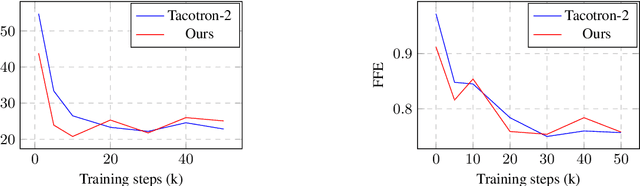
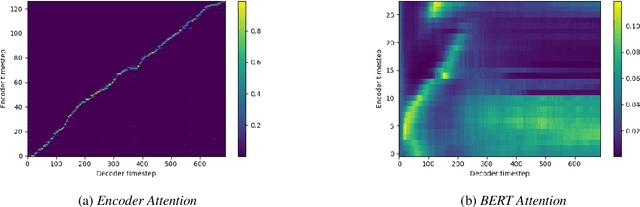
Modern text-to-speech (TTS) systems are able to generate audio that sounds almost as natural as human speech. However, the bar of developing high-quality TTS systems remains high since a sizable set of studio-quality <text, audio> pairs is usually required. Compared to commercial data used to develop state-of-the-art systems, publicly available data are usually worse in terms of both quality and size. Audio generated by TTS systems trained on publicly available data tends to not only sound less natural, but also exhibits more background noise. In this work, we aim to lower TTS systems' reliance on high-quality data by providing them the textual knowledge extracted by deep pre-trained language models during training. In particular, we investigate the use of BERT to assist the training of Tacotron-2, a state of the art TTS consisting of an encoder and an attention-based decoder. BERT representations learned from large amounts of unlabeled text data are shown to contain very rich semantic and syntactic information about the input text, and have potential to be leveraged by a TTS system to compensate the lack of high-quality data. We incorporate BERT as a parallel branch to the Tacotron-2 encoder with its own attention head. For an input text, it is simultaneously passed into BERT and the Tacotron-2 encoder. The representations extracted by the two branches are concatenated and then fed to the decoder. As a preliminary study, although we have not found incorporating BERT into Tacotron-2 generates more natural or cleaner speech at a human-perceivable level, we observe improvements in other aspects such as the model is being significantly better at knowing when to stop decoding such that there is much less babbling at the end of the synthesized audio and faster convergence during training.
FAKTA: An Automatic End-to-End Fact Checking System
Jun 07, 2019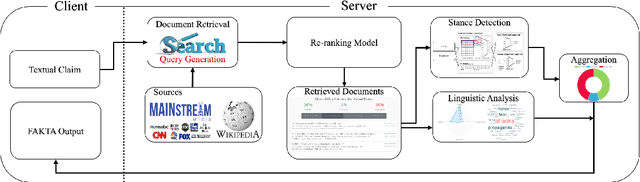
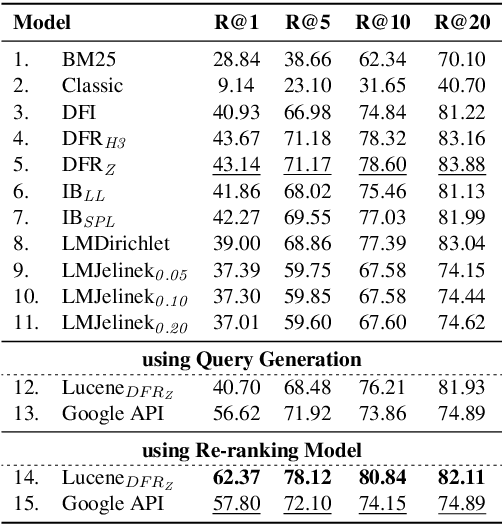
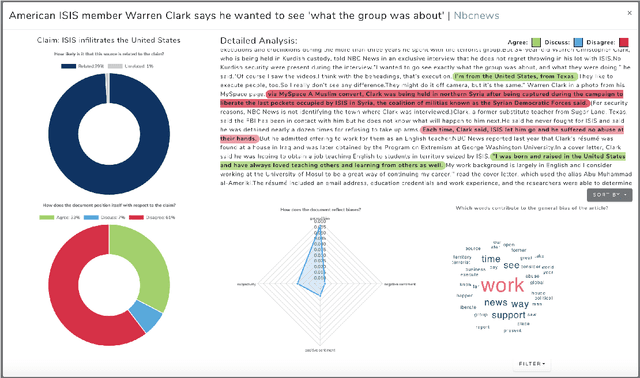
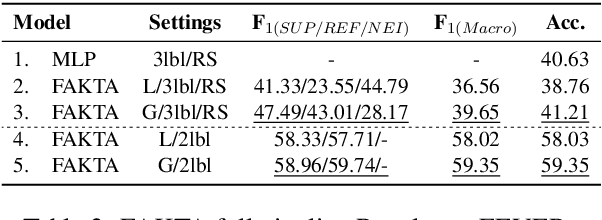
We present FAKTA which is a unified framework that integrates various components of a fact checking process: document retrieval from media sources with various types of reliability, stance detection of documents with respect to given claims, evidence extraction, and linguistic analysis. FAKTA predicts the factuality of given claims and provides evidence at the document and sentence level to explain its predictions
Improving Neural Language Models by Segmenting, Attending, and Predicting the Future
Jun 04, 2019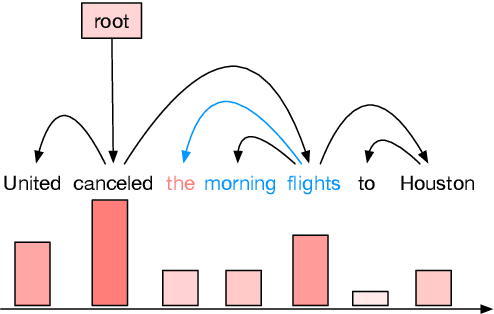
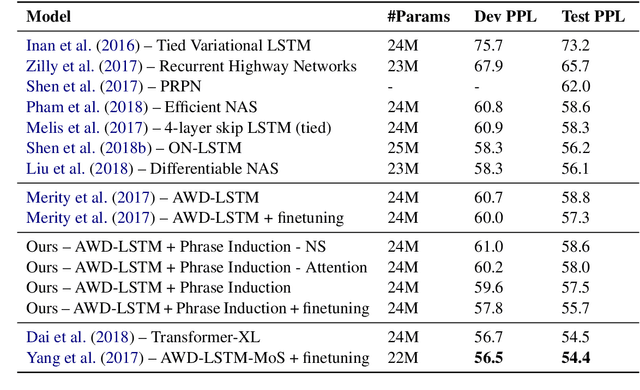
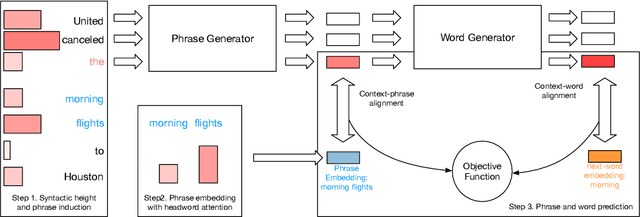
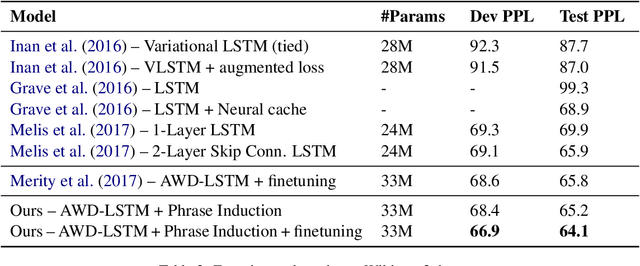
Common language models typically predict the next word given the context. In this work, we propose a method that improves language modeling by learning to align the given context and the following phrase. The model does not require any linguistic annotation of phrase segmentation. Instead, we define syntactic heights and phrase segmentation rules, enabling the model to automatically induce phrases, recognize their task-specific heads, and generate phrase embeddings in an unsupervised learning manner. Our method can easily be applied to language models with different network architectures since an independent module is used for phrase induction and context-phrase alignment, and no change is required in the underlying language modeling network. Experiments have shown that our model outperformed several strong baseline models on different data sets. We achieved a new state-of-the-art performance of 17.4 perplexity on the Wikitext-103 dataset. Additionally, visualizing the outputs of the phrase induction module showed that our model is able to learn approximate phrase-level structural knowledge without any annotation.
Quantifying Exposure Bias for Neural Language Generation
May 25, 2019
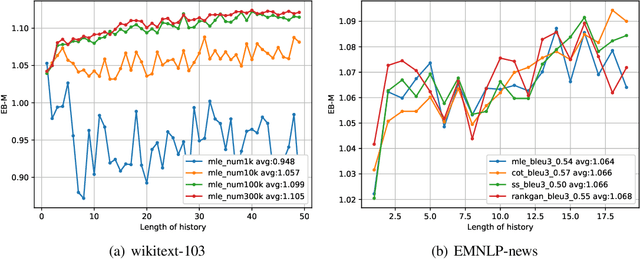
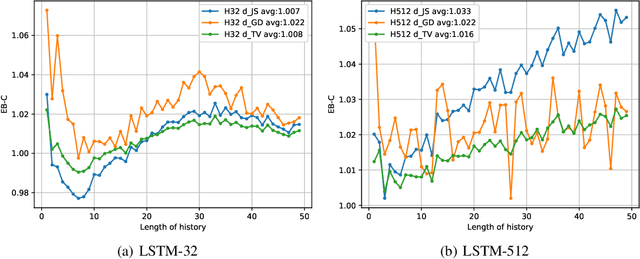

The exposure bias problem refers to the training-inference discrepancy caused by teacher forcing in maximum likelihood estimation (MLE) training for recurrent neural network language models (RNNLM). It has been regarded as a central problem for natural language generation (NLG) model training. Although a lot of algorithms have been proposed to avoid teacher forcing and therefore to remove exposure bias, there is little work showing how serious the exposure bias problem is. In this work, starting from the definition of exposure bias, we propose two simple and intuitive approaches to quantify exposure bias for MLE-trained language models. Experiments are conducted on both synthetic and real data-sets. Surprisingly, our results indicate that either exposure bias is trivial (i.e. indistinguishable from the mismatch between model and data distribution), or is not as significant as it is presumed to be (with a measured performance gap of 3%). With this work, we suggest re-evaluating the viewpoint that teacher forcing or exposure bias is a major drawback of MLE training.
Time-Contrastive Learning Based Deep Bottleneck Features for Text-Dependent Speaker Verification
May 11, 2019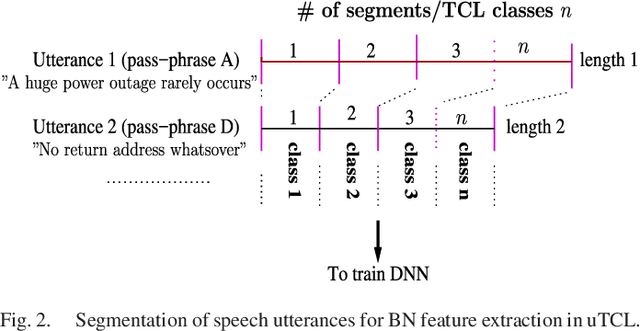
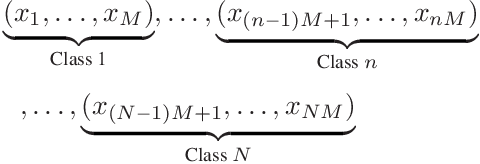
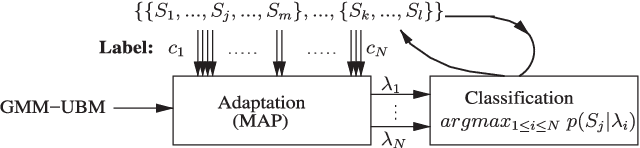
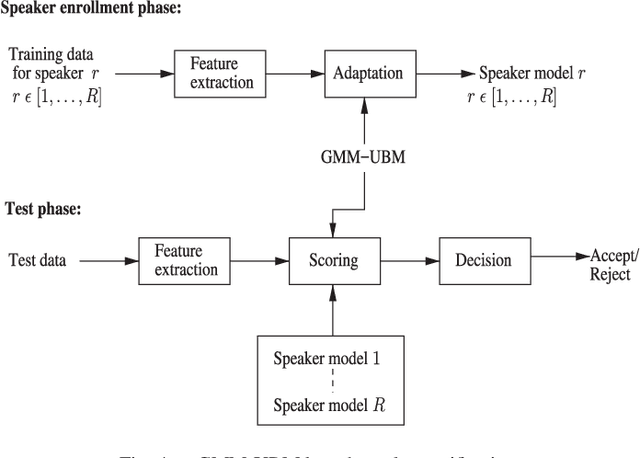
There are a number of studies about extraction of bottleneck (BN) features from deep neural networks (DNNs)trained to discriminate speakers, pass-phrases and triphone states for improving the performance of text-dependent speaker verification (TD-SV). However, a moderate success has been achieved. A recent study [1] presented a time contrastive learning (TCL) concept to explore the non-stationarity of brain signals for classification of brain states. Speech signals have similar non-stationarity property, and TCL further has the advantage of having no need for labeled data. We therefore present a TCL based BN feature extraction method. The method uniformly partitions each speech utterance in a training dataset into a predefined number of multi-frame segments. Each segment in an utterance corresponds to one class, and class labels are shared across utterances. DNNs are then trained to discriminate all speech frames among the classes to exploit the temporal structure of speech. In addition, we propose a segment-based unsupervised clustering algorithm to re-assign class labels to the segments. TD-SV experiments were conducted on the RedDots challenge database. The TCL-DNNs were trained using speech data of fixed pass-phrases that were excluded from the TD-SV evaluation set, so the learned features can be considered phrase-independent. We compare the performance of the proposed TCL bottleneck (BN) feature with those of short-time cepstral features and BN features extracted from DNNs discriminating speakers, pass-phrases, speaker+pass-phrase, as well as monophones whose labels and boundaries are generated by three different automatic speech recognition (ASR) systems. Experimental results show that the proposed TCL-BN outperforms cepstral features and speaker+pass-phrase discriminant BN features, and its performance is on par with those of ASR derived BN features. Moreover,....
* Copyright (c) 2019 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Team QCRI-MIT at SemEval-2019 Task 4: Propaganda Analysis Meets Hyperpartisan News Detection
Apr 06, 2019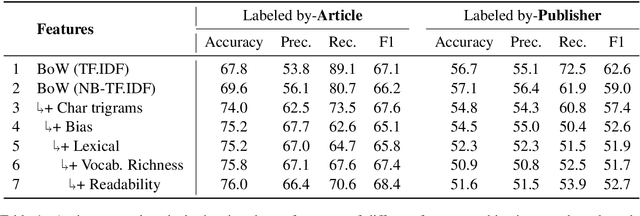
In this paper, we describe our submission to SemEval-2019 Task 4 on Hyperpartisan News Detection. Our system relies on a variety of engineered features originally used to detect propaganda. This is based on the assumption that biased messages are propagandistic in the sense that they promote a particular political cause or viewpoint. We trained a logistic regression model with features ranging from simple bag-of-words to vocabulary richness and text readability features. Our system achieved 72.9% accuracy on the test data that is annotated manually and 60.8% on the test data that is annotated with distant supervision. Additional experiments showed that significant performance improvements can be achieved with better feature pre-processing.
An Unsupervised Autoregressive Model for Speech Representation Learning
Apr 05, 2019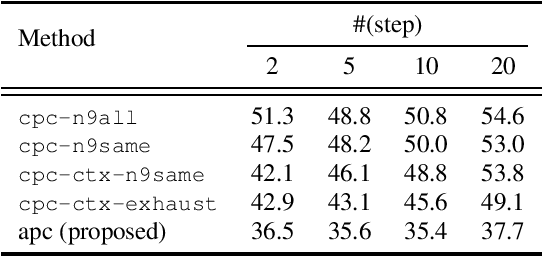
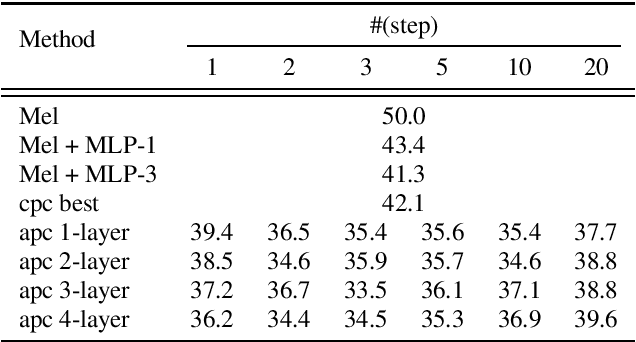
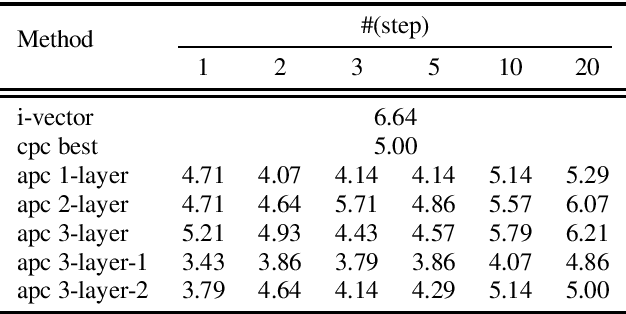
This paper proposes a novel unsupervised autoregressive neural model for learning generic speech representations. In contrast to other speech representation learning methods that aim to remove noise or speaker variabilities, ours is designed to preserve information for a wide range of downstream tasks. In addition, the proposed model does not require any phonetic or word boundary labels, allowing the model to benefit from large quantities of unlabeled data. Speech representations learned by our model significantly improve performance on both phone classification and speaker verification over the surface features and other supervised and unsupervised approaches. Further analysis shows that different levels of speech information are captured by our model at different layers. In particular, the lower layers tend to be more discriminative for speakers, while the upper layers provide more phonetic content.
Multi-Task Ordinal Regression for Jointly Predicting the Trustworthiness and the Leading Political Ideology of News Media
Apr 01, 2019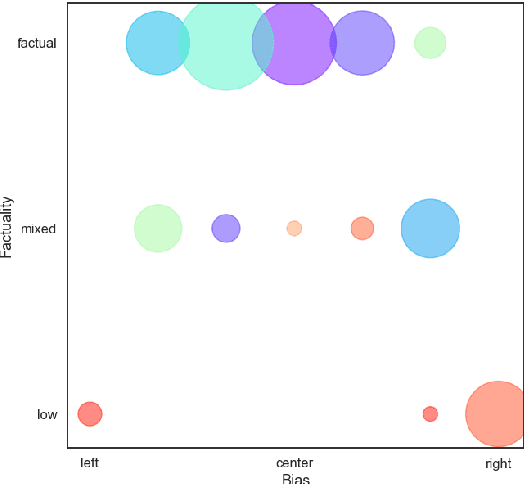
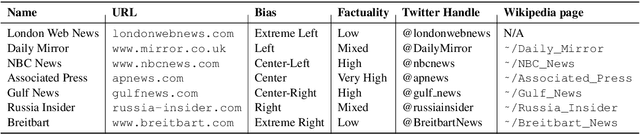
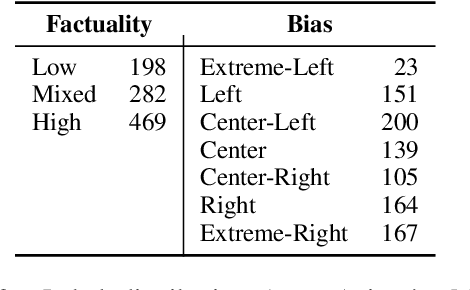
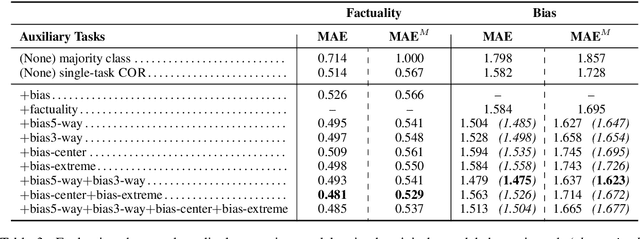
In the context of fake news, bias, and propaganda, we study two important but relatively under-explored problems: (i) trustworthiness estimation (on a 3-point scale) and (ii) political ideology detection (left/right bias on a 7-point scale) of entire news outlets, as opposed to evaluating individual articles. In particular, we propose a multi-task ordinal regression framework that models the two problems jointly. This is motivated by the observation that hyper-partisanship is often linked to low trustworthiness, e.g., appealing to emotions rather than sticking to the facts, while center media tend to be generally more impartial and trustworthy. We further use several auxiliary tasks, modeling centrality, hyperpartisanship, as well as left-vs.-right bias on a coarse-grained scale. The evaluation results show sizable performance gains by the joint models over models that target the problems in isolation.
Negative Training for Neural Dialogue Response Generation
Mar 06, 2019
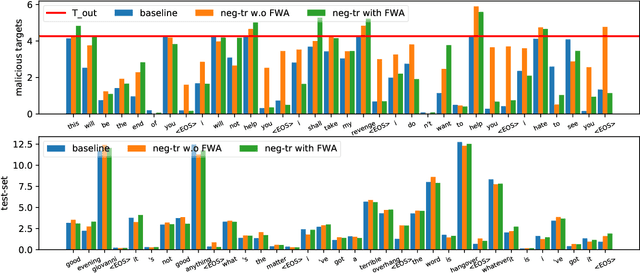

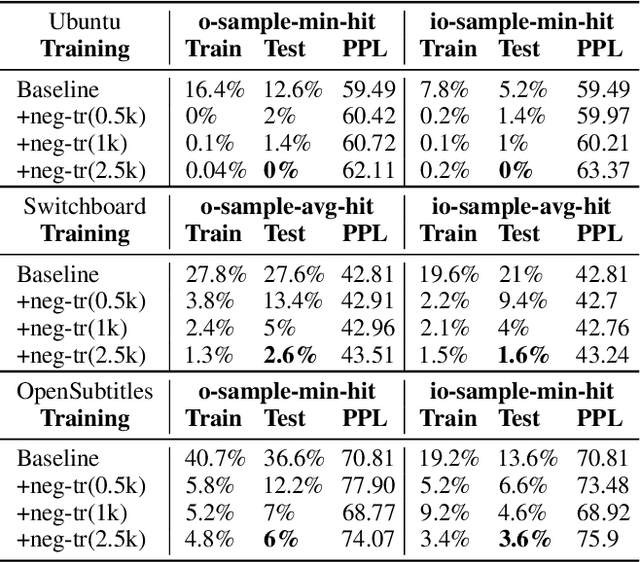
Although deep learning models have brought tremendous advancements to the field of open-domain dialogue response generation, recent research results have revealed that the trained models have undesirable generation behaviors, such as malicious responses and generic (boring) responses. In this work, we propose a framework named "Negative Training" to minimize such behaviors. Given a trained model, the framework will first find generated samples that exhibit the undesirable behavior, and then use them to feed negative training signals for fine-tuning the model. Our experiments show that negative training can significantly reduce the hit rate of malicious responses (e.g. from 12.6% to 0%), or discourage frequent responses and improve response diversity (e.g. improve response entropy by over 63%).
Towards Visually Grounded Sub-Word Speech Unit Discovery
Feb 21, 2019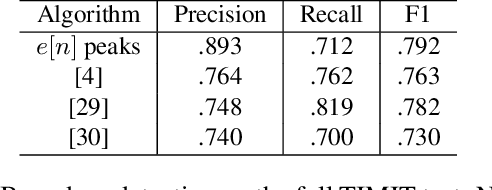
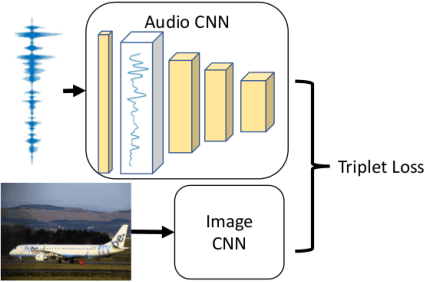
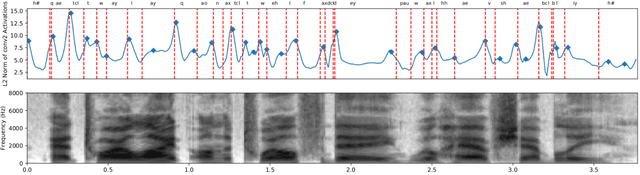
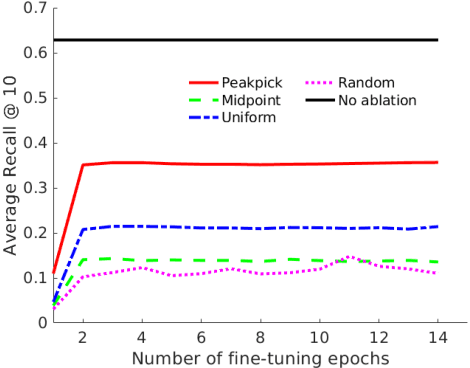
In this paper, we investigate the manner in which interpretable sub-word speech units emerge within a convolutional neural network model trained to associate raw speech waveforms with semantically related natural image scenes. We show how diphone boundaries can be superficially extracted from the activation patterns of intermediate layers of the model, suggesting that the model may be leveraging these events for the purpose of word recognition. We present a series of experiments investigating the information encoded by these events.