 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning by the Baldwin Effect
Jun 22, 2018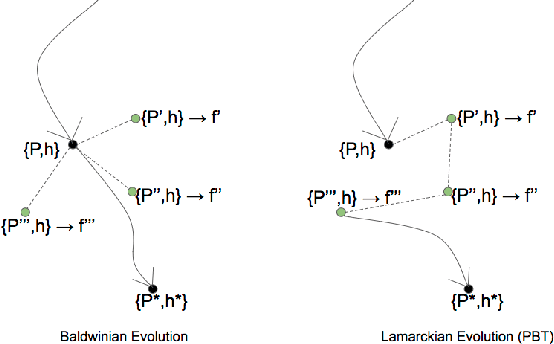
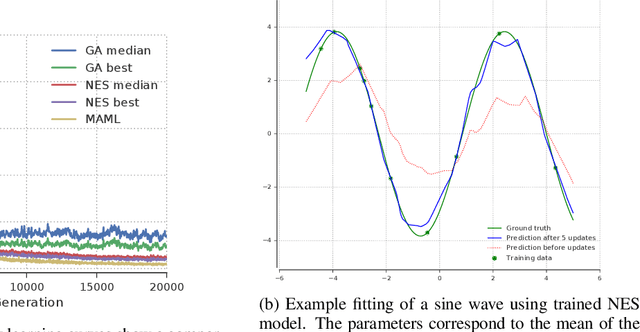
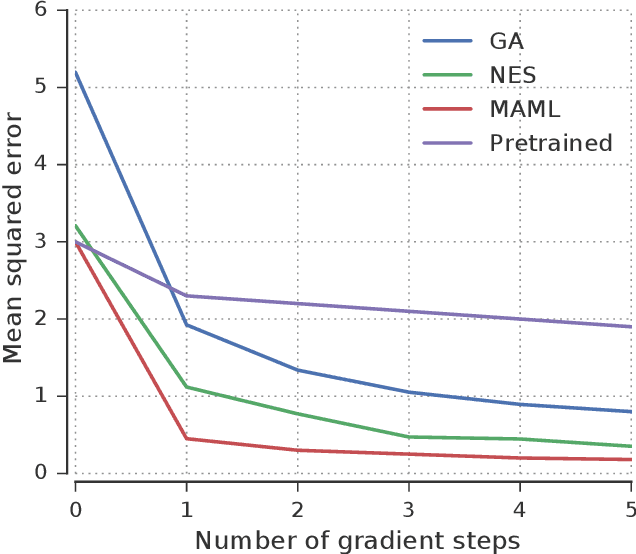
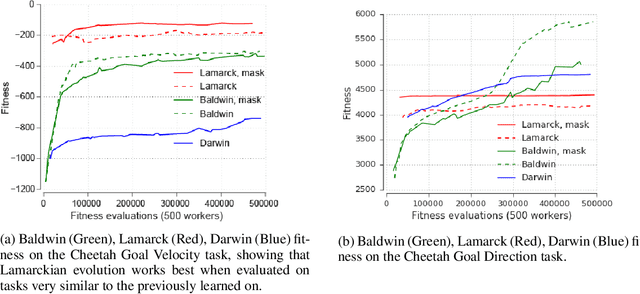
The scope of the Baldwin effect was recently called into question by two papers that closely examined the seminal work of Hinton and Nowlan. To this date there has been no demonstration of its necessity in empirically challenging tasks. Here we show that the Baldwin effect is capable of evolving few-shot supervised and reinforcement learning mechanisms, by shaping the hyperparameters and the initial parameters of deep learning algorithms. Furthermore it can genetically accommodate strong learning biases on the same set of problems as a recent machine learning algorithm called MAML "Model Agnostic Meta-Learning" which uses second-order gradients instead of evolution to learn a set of reference parameters (initial weights) that can allow rapid adaptation to tasks sampled from a distribution. Whilst in simple cases MAML is more data efficient than the Baldwin effect, the Baldwin effect is more general in that it does not require gradients to be backpropagated to the reference parameters or hyperparameters, and permits effectively any number of gradient updates in the inner loop. The Baldwin effect learns strong learning dependent biases, rather than purely genetically accommodating fixed behaviours in a learning independent manner.
Theano: A Python framework for fast computation of mathematical expressions
May 09, 2016



Theano is a Python library that allows to define, optimize, and evaluate mathematical expressions involving multi-dimensional arrays efficiently. Since its introduction, it has been one of the most used CPU and GPU mathematical compilers - especially in the machine learning community - and has shown steady performance improvements. Theano is being actively and continuously developed since 2008, multiple frameworks have been built on top of it and it has been used to produce many state-of-the-art machine learning models. The present article is structured as follows. Section I provides an overview of the Theano software and its community. Section II presents the principal features of Theano and how to use them, and compares them with other similar projects. Section III focuses on recently-introduced functionalities and improvements. Section IV compares the performance of Theano against Torch7 and TensorFlow on several machine learning models. Section V discusses current limitations of Theano and potential ways of improving it.
Learning from the memory of Atari 2600
May 04, 2016
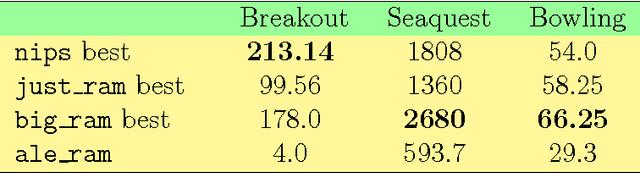
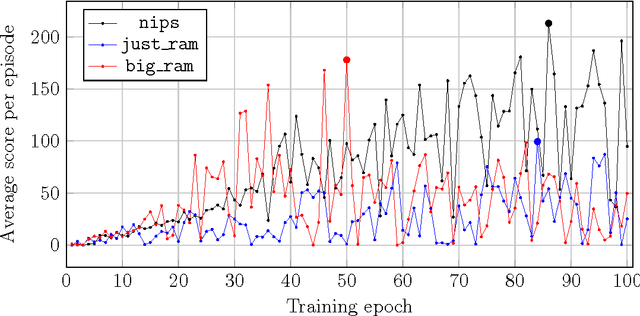

We train a number of neural networks to play games Bowling, Breakout and Seaquest using information stored in the memory of a video game console Atari 2600. We consider four models of neural networks which differ in size and architecture: two networks which use only information contained in the RAM and two mixed networks which use both information in the RAM and information from the screen. As the benchmark we used the convolutional model proposed in NIPS and received comparable results in all considered games. Quite surprisingly, in the case of Seaquest we were able to train RAM-only agents which behave better than the benchmark screen-only agent. Mixing screen and RAM did not lead to an improved performance comparing to screen-only and RAM-only agents.