 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTERMINATOR: Learning Optimal Exit Points for Early Stopping in Chain-of-Thought Reasoning
Mar 13, 2026Large Reasoning Models (LRMs) achieve impressive performance on complex reasoning tasks via Chain-of-Thought (CoT) reasoning, which enables them to generate intermediate thinking tokens before arriving at the final answer. However, LRMs often suffer from significant overthinking, spending excessive compute time even after the answer is generated early on. Prior work has identified the existence of an optimal reasoning length such that truncating reasoning at this point significantly shortens CoT outputs with virtually no change in performance. However, determining optimal CoT lengths for practical datasets is highly non-trivial as they are fully task and model-dependent. In this paper, we precisely address this and design TERMINATOR, an early-exit strategy for LRMs at inference to mitigate overthinking. The central idea underpinning TERMINATOR is that the first arrival of an LRM's final answer is often predictable, and we leverage these first answer positions to create a novel dataset of optimal reasoning lengths to train TERMINATOR. Powered by this approach, TERMINATOR achieves significant reductions in CoT lengths of 14%-55% on average across four challenging practical datasets: MATH-500, AIME 2025, HumanEval, and GPQA, whilst outperforming current state-of-the-art methods.
CommonLID: Re-evaluating State-of-the-Art Language Identification Performance on Web Data
Jan 25, 2026Language identification (LID) is a fundamental step in curating multilingual corpora. However, LID models still perform poorly for many languages, especially on the noisy and heterogeneous web data often used to train multilingual language models. In this paper, we introduce CommonLID, a community-driven, human-annotated LID benchmark for the web domain, covering 109 languages. Many of the included languages have been previously under-served, making CommonLID a key resource for developing more representative high-quality text corpora. We show CommonLID's value by using it, alongside five other common evaluation sets, to test eight popular LID models. We analyse our results to situate our contribution and to provide an overview of the state of the art. In particular, we highlight that existing evaluations overestimate LID accuracy for many languages in the web domain. We make CommonLID and the code used to create it available under an open, permissive license.
Apertus: Democratizing Open and Compliant LLMs for Global Language Environments
Sep 17, 2025



We present Apertus, a fully open suite of large language models (LLMs) designed to address two systemic shortcomings in today's open model ecosystem: data compliance and multilingual representation. Unlike many prior models that release weights without reproducible data pipelines or regard for content-owner rights, Apertus models are pretrained exclusively on openly available data, retroactively respecting robots.txt exclusions and filtering for non-permissive, toxic, and personally identifiable content. To mitigate risks of memorization, we adopt the Goldfish objective during pretraining, strongly suppressing verbatim recall of data while retaining downstream task performance. The Apertus models also expand multilingual coverage, training on 15T tokens from over 1800 languages, with ~40% of pretraining data allocated to non-English content. Released at 8B and 70B scales, Apertus approaches state-of-the-art results among fully open models on multilingual benchmarks, rivalling or surpassing open-weight counterparts. Beyond model weights, we release all scientific artifacts from our development cycle with a permissive license, including data preparation scripts, checkpoints, evaluation suites, and training code, enabling transparent audit and extension.
ConLID: Supervised Contrastive Learning for Low-Resource Language Identification
Jun 18, 2025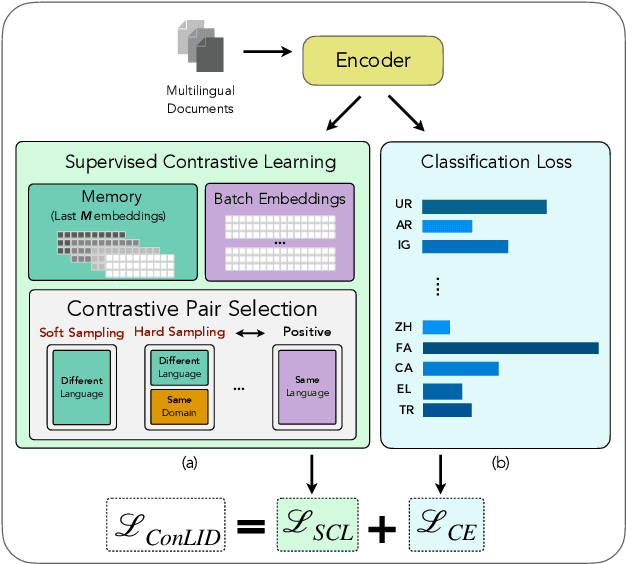
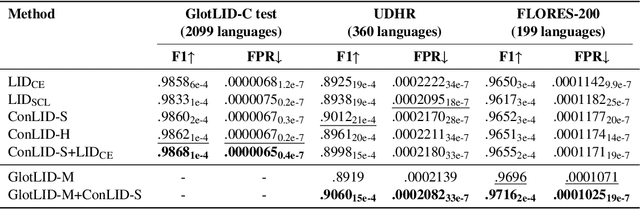

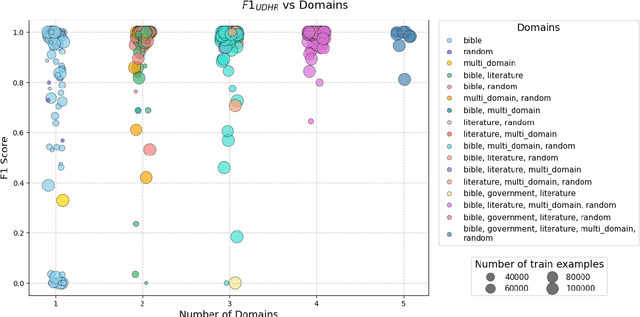
Language identification (LID) is a critical step in curating multilingual LLM pretraining corpora from web crawls. While many studies on LID model training focus on collecting diverse training data to improve performance, low-resource languages -- often limited to single-domain data, such as the Bible -- continue to perform poorly. To resolve these class imbalance and bias issues, we propose a novel supervised contrastive learning (SCL) approach to learn domain-invariant representations for low-resource languages. Through an extensive analysis, we show that our approach improves LID performance on out-of-domain data for low-resource languages by 3.2%, demonstrating its effectiveness in enhancing LID models.
LLM-Powered Agents for Navigating Venice's Historical Cadastre
May 22, 2025Cadastral data reveal key information about the historical organization of cities but are often non-standardized due to diverse formats and human annotations, complicating large-scale analysis. We explore as a case study Venice's urban history during the critical period from 1740 to 1808, capturing the transition following the fall of the ancient Republic and the Ancien R\'egime. This era's complex cadastral data, marked by its volume and lack of uniform structure, presents unique challenges that our approach adeptly navigates, enabling us to generate spatial queries that bridge past and present urban landscapes. We present a text-to-programs framework that leverages Large Language Models (LLMs) to translate natural language queries into executable code for processing historical cadastral records. Our methodology implements two complementary techniques: a text-to-SQL approach for handling structured queries about specific cadastral information, and a text-to-Python approach for complex analytical operations requiring custom data manipulation. We propose a taxonomy that classifies historical research questions based on their complexity and analytical requirements, mapping them to the most appropriate technical approach. This framework is supported by an investigation into the execution consistency of the system, alongside a qualitative analysis of the answers it produces. By ensuring interpretability and minimizing hallucination through verifiable program outputs, we demonstrate the system's effectiveness in reconstructing past population information, property features, and spatiotemporal comparisons in Venice.