Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConLID: Supervised Contrastive Learning for Low-Resource Language Identification
Paper and Code
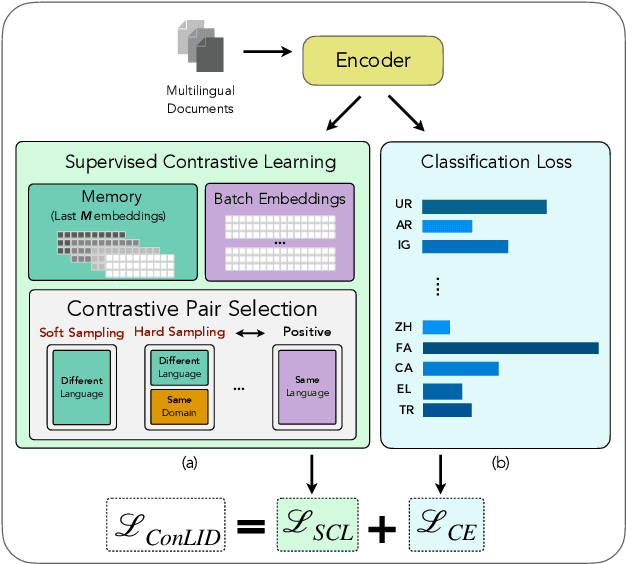
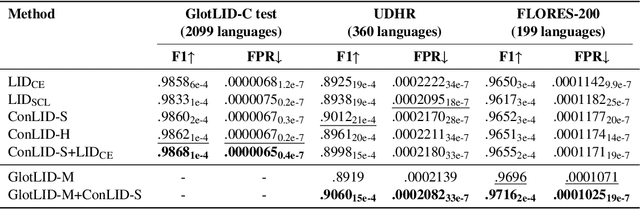

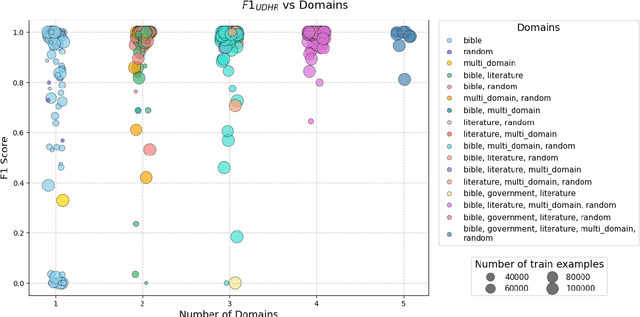
Language identification (LID) is a critical step in curating multilingual LLM pretraining corpora from web crawls. While many studies on LID model training focus on collecting diverse training data to improve performance, low-resource languages -- often limited to single-domain data, such as the Bible -- continue to perform poorly. To resolve these class imbalance and bias issues, we propose a novel supervised contrastive learning (SCL) approach to learn domain-invariant representations for low-resource languages. Through an extensive analysis, we show that our approach improves LID performance on out-of-domain data for low-resource languages by 3.2%, demonstrating its effectiveness in enhancing LID models.
* Submitted to EMNLP
View paper on