 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid In-memory Computing Architecture for the Training of Deep Neural Networks
Feb 10, 2021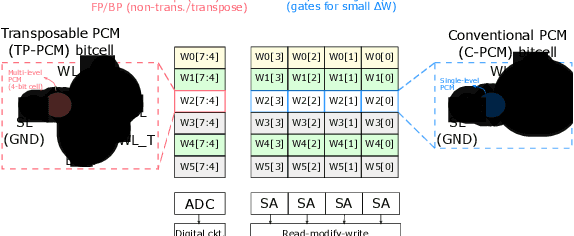
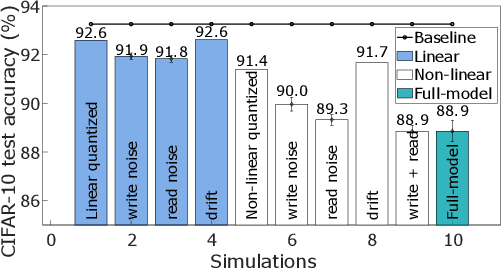
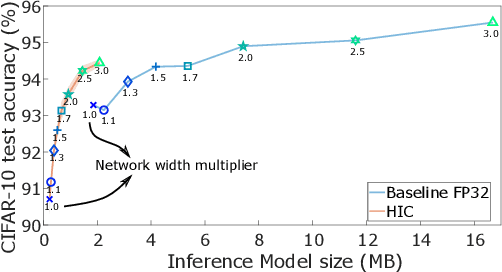
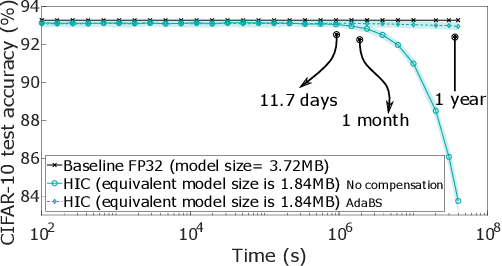
The cost involved in training deep neural networks (DNNs) on von-Neumann architectures has motivated the development of novel solutions for efficient DNN training accelerators. We propose a hybrid in-memory computing (HIC) architecture for the training of DNNs on hardware accelerators that results in memory-efficient inference and outperforms baseline software accuracy in benchmark tasks. We introduce a weight representation technique that exploits both binary and multi-level phase-change memory (PCM) devices, and this leads to a memory-efficient inference accelerator. Unlike previous in-memory computing-based implementations, we use a low precision weight update accumulator that results in more memory savings. We trained the ResNet-32 network to classify CIFAR-10 images using HIC. For a comparable model size, HIC-based training outperforms baseline network, trained in floating-point 32-bit (FP32) precision, by leveraging appropriate network width multiplier. Furthermore, we observe that HIC-based training results in about 50% less inference model size to achieve baseline comparable accuracy. We also show that the temporal drift in PCM devices has a negligible effect on post-training inference accuracy for extended periods (year). Finally, our simulations indicate HIC-based training naturally ensures that the number of write-erase cycles seen by the devices is a small fraction of the endurance limit of PCM, demonstrating the feasibility of this architecture for achieving hardware platforms that can learn in the field.
Benchmarking TinyML Systems: Challenges and Direction
Mar 10, 2020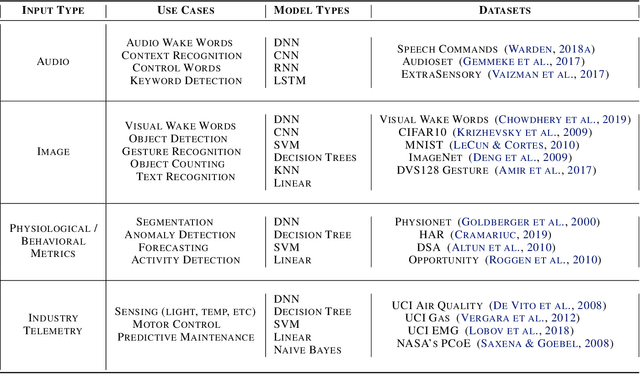
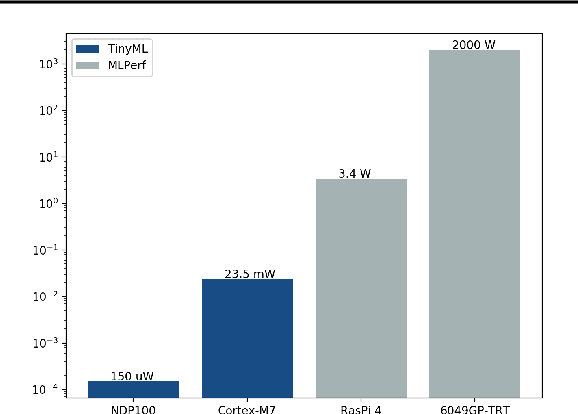
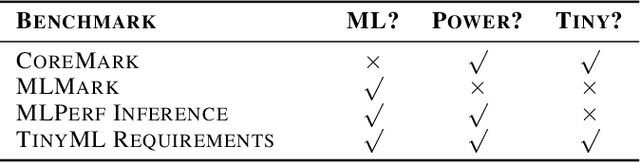
Recent advancements in ultra-low-power machine learning (TinyML) hardware promises to unlock an entirely new class of smart applications. However, continued progress is limited by the lack of a widely accepted benchmark for these systems. Benchmarking allows us to measure and thereby systematically compare, evaluate, and improve the performance of systems. In this position paper, we present the current landscape of TinyML and discuss the challenges and direction towards developing a fair and useful hardware benchmark for TinyML workloads. Our viewpoints reflect the collective thoughts of the TinyMLPerf working group that is comprised of 30 organizations.
High-Throughput In-Memory Computing for Binary Deep Neural Networks with Monolithically Integrated RRAM and 90nm CMOS
Sep 16, 2019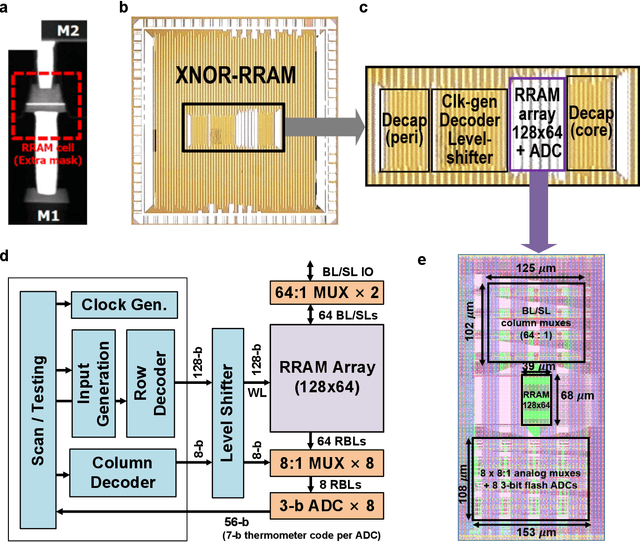
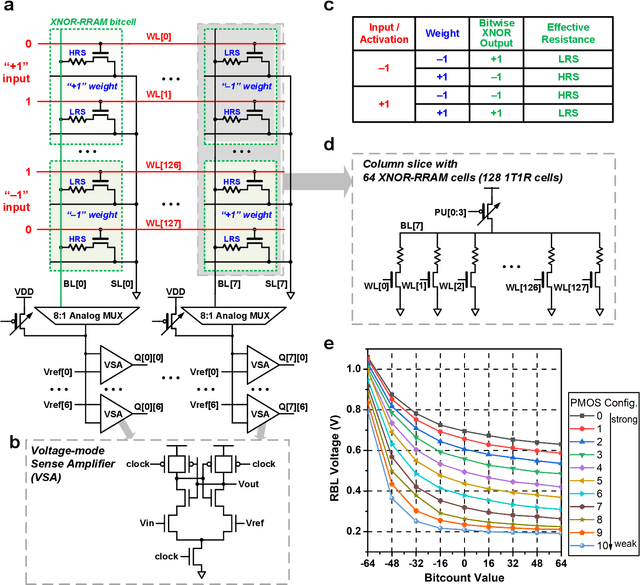
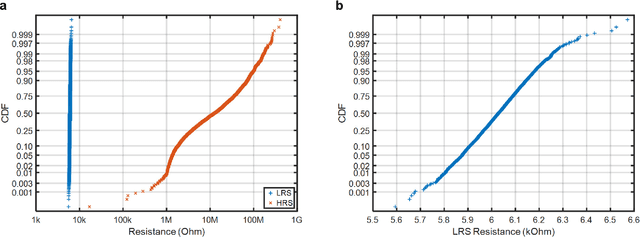
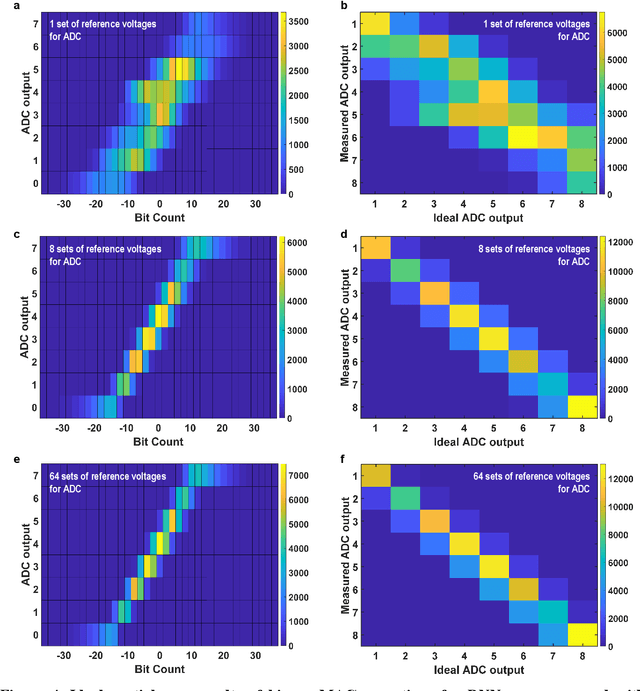
Deep learning hardware designs have been bottlenecked by conventional memories such as SRAM due to density, leakage and parallel computing challenges. Resistive devices can address the density and volatility issues, but have been limited by peripheral circuit integration. In this work, we demonstrate a scalable RRAM based in-memory computing design, termed XNOR-RRAM, which is fabricated in a 90nm CMOS technology with monolithic integration of RRAM devices between metal 1 and 2. We integrated a 128x64 RRAM array with CMOS peripheral circuits including row/column decoders and flash analog-to-digital converters (ADCs), which collectively become a core component for scalable RRAM-based in-memory computing towards large deep neural networks (DNNs). To maximize the parallelism of in-memory computing, we assert all 128 wordlines of the RRAM array simultaneously, perform analog computing along the bitlines, and digitize the bitline voltages using ADCs. The resistance distribution of low resistance states is tightened by write-verify scheme, and the ADC offset is calibrated. Prototype chip measurements show that the proposed design achieves high binary DNN accuracy of 98.5% for MNIST and 83.5% for CIFAR-10 datasets, respectively, with energy efficiency of 24 TOPS/W and 158 GOPS throughput. This represents 5.6X, 3.2X, 14.1X improvements in throughput, energy-delay product (EDP), and energy-delay-squared product (ED2P), respectively, compared to the state-of-the-art literature. The proposed XNOR-RRAM can enable intelligent functionalities for area-/energy-constrained edge computing devices.
Automatic Compiler Based FPGA Accelerator for CNN Training
Aug 15, 2019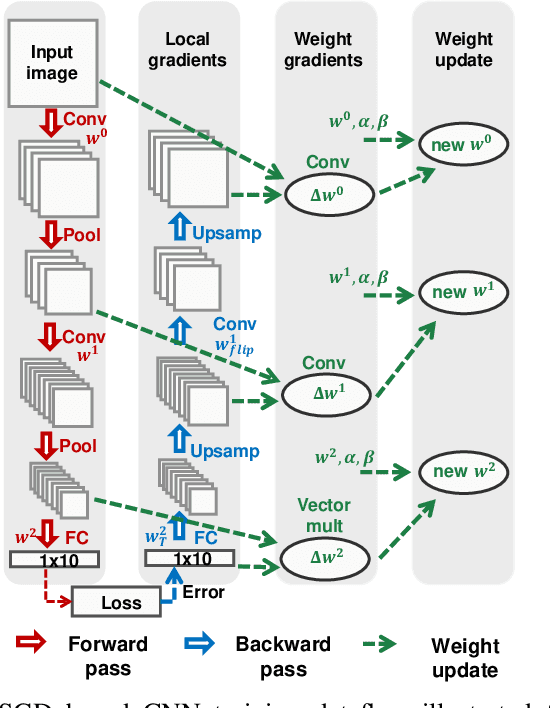
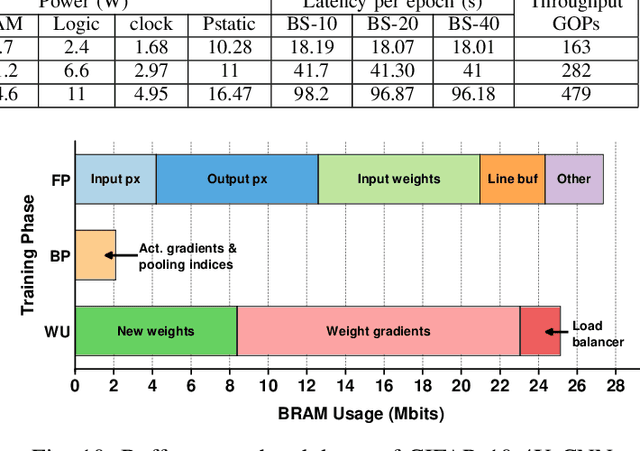
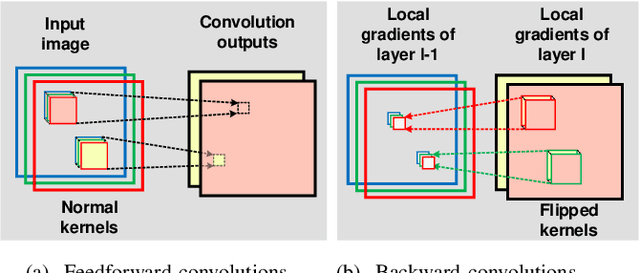
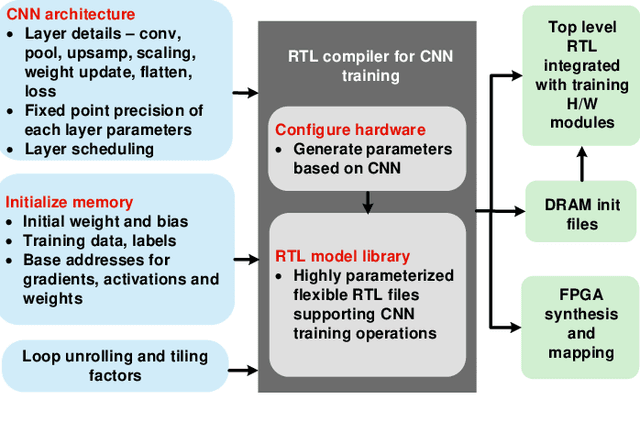
Training of convolutional neural networks (CNNs)on embedded platforms to support on-device learning is earning vital importance in recent days. Designing flexible training hard-ware is much more challenging than inference hardware, due to design complexity and large computation/memory requirement. In this work, we present an automatic compiler-based FPGA accelerator with 16-bit fixed-point precision for complete CNNtraining, including Forward Pass (FP), Backward Pass (BP) and Weight Update (WU). We implemented an optimized RTL library to perform training-specific tasks and developed an RTL compiler to automatically generate FPGA-synthesizable RTL based on user-defined constraints. We present a new cyclic weight storage/access scheme for on-chip BRAM and off-chip DRAMto efficiently implement non-transpose and transpose operations during FP and BP phases, respectively. Representative CNNs for CIFAR-10 dataset are implemented and trained on Intel Stratix 10-GX FPGA using proposed hardware architecture, demonstrating up to 479 GOPS performance.
FixyNN: Efficient Hardware for Mobile Computer Vision via Transfer Learning
Feb 27, 2019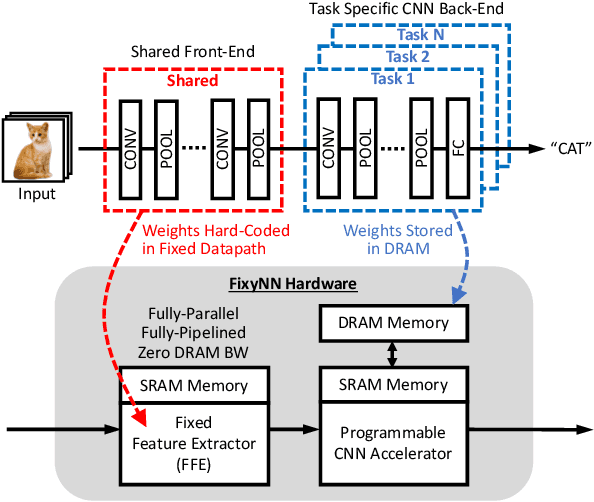
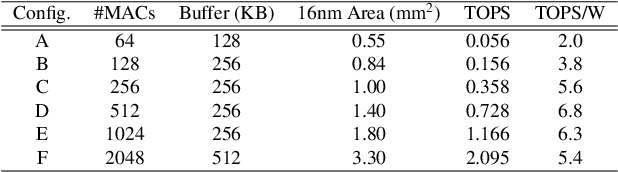
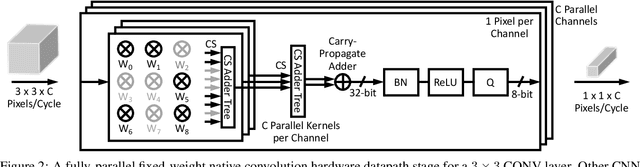
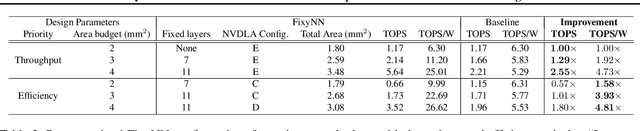
The computational demands of computer vision tasks based on state-of-the-art Convolutional Neural Network (CNN) image classification far exceed the energy budgets of mobile devices. This paper proposes FixyNN, which consists of a fixed-weight feature extractor that generates ubiquitous CNN features, and a conventional programmable CNN accelerator which processes a dataset-specific CNN. Image classification models for FixyNN are trained end-to-end via transfer learning, with the common feature extractor representing the transfered part, and the programmable part being learnt on the target dataset. Experimental results demonstrate FixyNN hardware can achieve very high energy efficiencies up to 26.6 TOPS/W ($4.81 \times$ better than iso-area programmable accelerator). Over a suite of six datasets we trained models via transfer learning with an accuracy loss of $<1\%$ resulting in up to 11.2 TOPS/W - nearly $2 \times$ more efficient than a conventional programmable CNN accelerator of the same area.
Large-Scale Neuromorphic Spiking Array Processors: A quest to mimic the brain
May 23, 2018
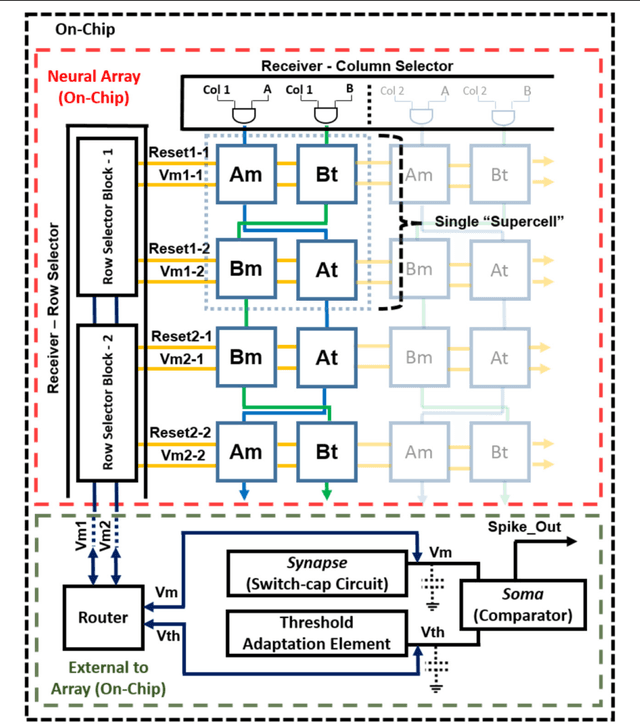
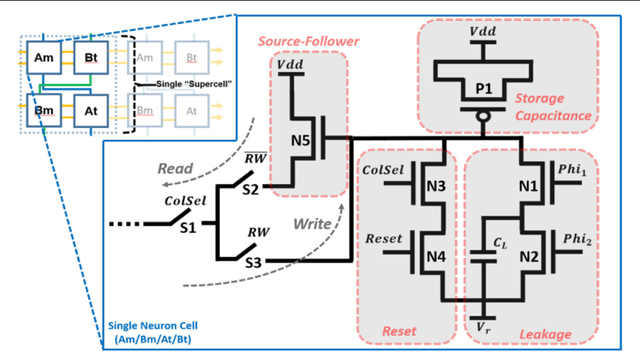
Neuromorphic engineering (NE) encompasses a diverse range of approaches to information processing that are inspired by neurobiological systems, and this feature distinguishes neuromorphic systems from conventional computing systems. The brain has evolved over billions of years to solve difficult engineering problems by using efficient, parallel, low-power computation. The goal of NE is to design systems capable of brain-like computation. Numerous large-scale neuromorphic projects have emerged recently. This interdisciplinary field was listed among the top 10 technology breakthroughs of 2014 by the MIT Technology Review and among the top 10 emerging technologies of 2015 by the World Economic Forum. NE has two-way goals: one, a scientific goal to understand the computational properties of biological neural systems by using models implemented in integrated circuits (ICs); second, an engineering goal to exploit the known properties of biological systems to design and implement efficient devices for engineering applications. Building hardware neural emulators can be extremely useful for simulating large-scale neural models to explain how intelligent behavior arises in the brain. The principle advantages of neuromorphic emulators are that they are highly energy efficient, parallel and distributed, and require a small silicon area. Thus, compared to conventional CPUs, these neuromorphic emulators are beneficial in many engineering applications such as for the porting of deep learning algorithms for various recognitions tasks. In this review article, we describe some of the most significant neuromorphic spiking emulators, compare the different architectures and approaches used by them, illustrate their advantages and drawbacks, and highlight the capabilities that each can deliver to neural modelers.
Minimizing Area and Energy of Deep Learning Hardware Design Using Collective Low Precision and Structured Compression
Apr 19, 2018

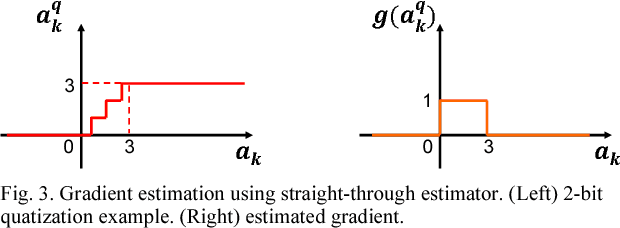
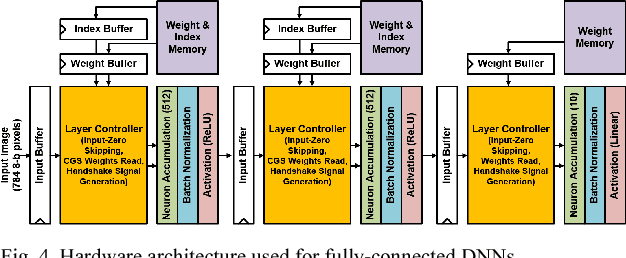
Deep learning algorithms have shown tremendous success in many recognition tasks; however, these algorithms typically include a deep neural network (DNN) structure and a large number of parameters, which makes it challenging to implement them on power/area-constrained embedded platforms. To reduce the network size, several studies investigated compression by introducing element-wise or row-/column-/block-wise sparsity via pruning and regularization. In addition, many recent works have focused on reducing precision of activations and weights with some reducing down to a single bit. However, combining various sparsity structures with binarized or very-low-precision (2-3 bit) neural networks have not been comprehensively explored. In this work, we present design techniques for minimum-area/-energy DNN hardware with minimal degradation in accuracy. During training, both binarization/low-precision and structured sparsity are applied as constraints to find the smallest memory footprint for a given deep learning algorithm. The DNN model for CIFAR-10 dataset with weight memory reduction of 50X exhibits accuracy comparable to that of the floating-point counterpart. Area, performance and energy results of DNN hardware in 40nm CMOS are reported for the MNIST dataset. The optimized DNN that combines 8X structured compression and 3-bit weight precision showed 98.4% accuracy at 20nJ per classification.
Algorithm and Hardware Design of Discrete-Time Spiking Neural Networks Based on Back Propagation with Binary Activations
Sep 19, 2017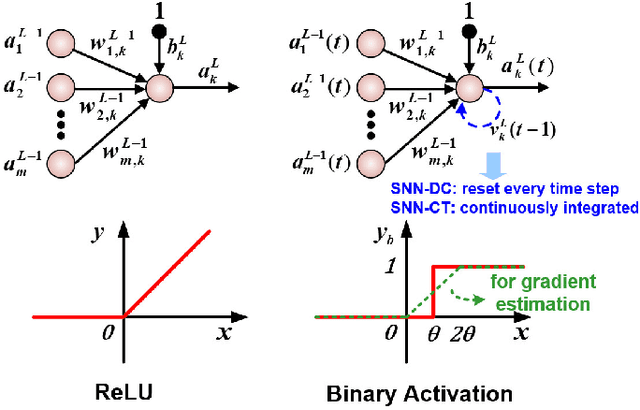
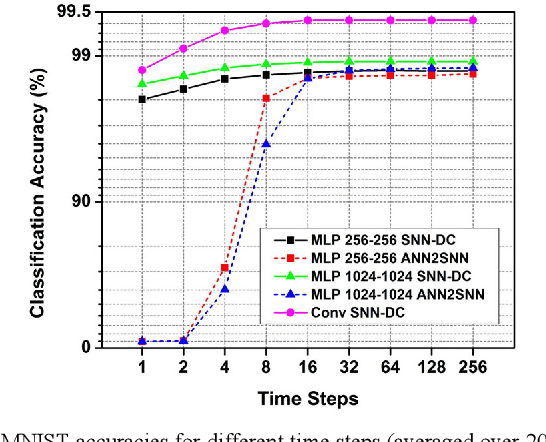
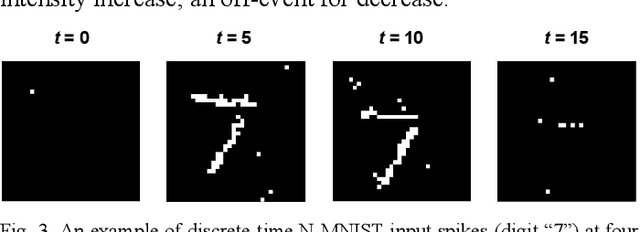
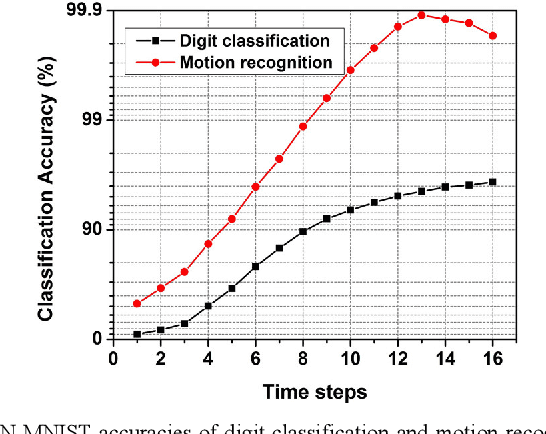
We present a new back propagation based training algorithm for discrete-time spiking neural networks (SNN). Inspired by recent deep learning algorithms on binarized neural networks, binary activation with a straight-through gradient estimator is used to model the leaky integrate-fire spiking neuron, overcoming the difficulty in training SNNs using back propagation. Two SNN training algorithms are proposed: (1) SNN with discontinuous integration, which is suitable for rate-coded input spikes, and (2) SNN with continuous integration, which is more general and can handle input spikes with temporal information. Neuromorphic hardware designed in 40nm CMOS exploits the spike sparsity and demonstrates high classification accuracy (>98% on MNIST) and low energy (48.4-773 nJ/image).
Comprehensive Evaluation of OpenCL-based Convolutional Neural Network Accelerators in Xilinx and Altera FPGAs
Sep 29, 2016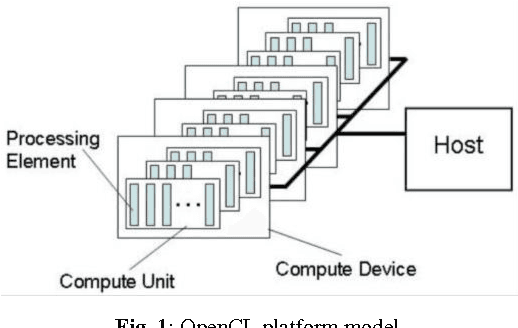



Deep learning has significantly advanced the state of the art in artificial intelligence, gaining wide popularity from both industry and academia. Special interest is around Convolutional Neural Networks (CNN), which take inspiration from the hierarchical structure of the visual cortex, to form deep layers of convolutional operations, along with fully connected classifiers. Hardware implementations of these deep CNN architectures are challenged with memory bottlenecks that require many convolution and fully-connected layers demanding large amount of communication for parallel computation. Multi-core CPU based solutions have demonstrated their inadequacy for this problem due to the memory wall and low parallelism. Many-core GPU architectures show superior performance but they consume high power and also have memory constraints due to inconsistencies between cache and main memory. FPGA design solutions are also actively being explored, which allow implementing the memory hierarchy using embedded BlockRAM. This boosts the parallel use of shared memory elements between multiple processing units, avoiding data replicability and inconsistencies. This makes FPGAs potentially powerful solutions for real-time classification of CNNs. Both Altera and Xilinx have adopted OpenCL co-design framework from GPU for FPGA designs as a pseudo-automatic development solution. In this paper, a comprehensive evaluation and comparison of Altera and Xilinx OpenCL frameworks for a 5-layer deep CNN is presented. Hardware resources, temporal performance and the OpenCL architecture for CNNs are discussed. Xilinx demonstrates faster synthesis, better FPGA resource utilization and more compact boards. Altera provides multi-platforms tools, mature design community and better execution times.
Reducing the Model Order of Deep Neural Networks Using Information Theory
May 16, 2016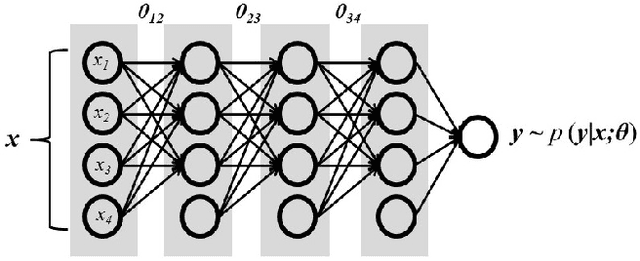
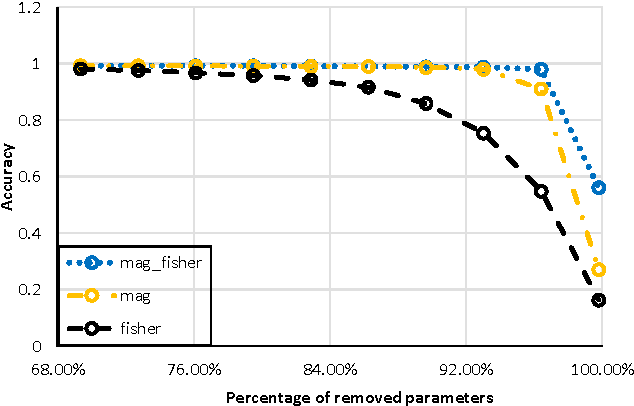
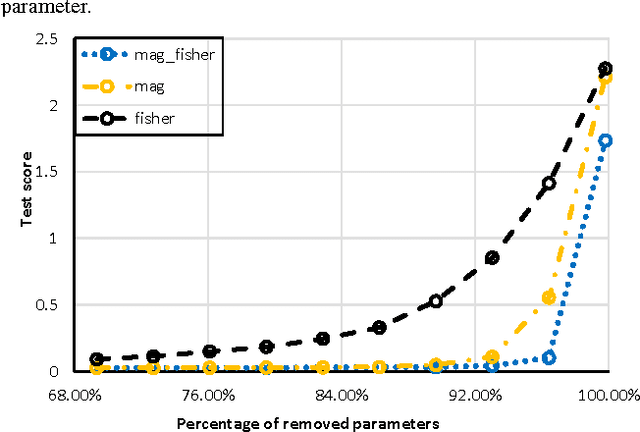
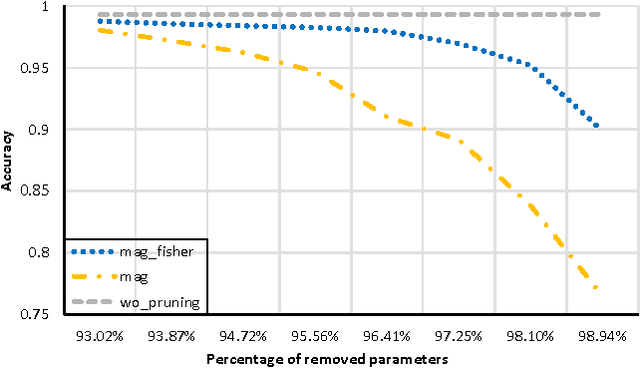
Deep neural networks are typically represented by a much larger number of parameters than shallow models, making them prohibitive for small footprint devices. Recent research shows that there is considerable redundancy in the parameter space of deep neural networks. In this paper, we propose a method to compress deep neural networks by using the Fisher Information metric, which we estimate through a stochastic optimization method that keeps track of second-order information in the network. We first remove unimportant parameters and then use non-uniform fixed point quantization to assign more bits to parameters with higher Fisher Information estimates. We evaluate our method on a classification task with a convolutional neural network trained on the MNIST data set. Experimental results show that our method outperforms existing methods for both network pruning and quantization.