 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Geometric Learning for Grasping and Manipulation
Feb 27, 2019
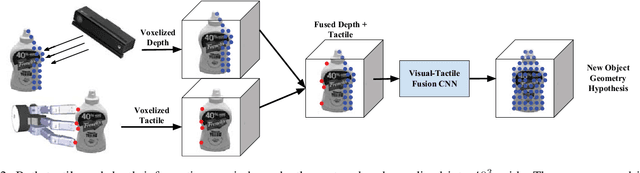
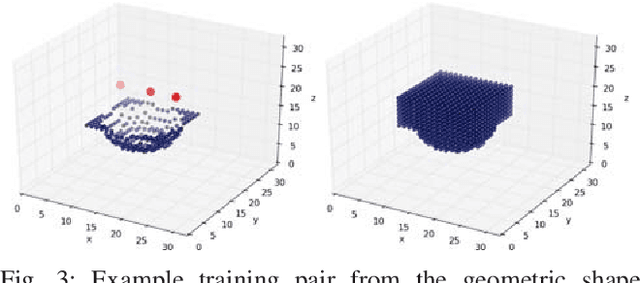

This work provides an architecture that incorporates depth and tactile information to create rich and accurate 3D models useful for robotic manipulation tasks. This is accomplished through the use of a 3D convolutional neural network (CNN). Offline, the network is provided with both depth and tactile information and trained to predict the object's geometry, thus filling in regions of occlusion. At runtime, the network is provided a partial view of an object. Tactile information is acquired to augment the captured depth information. The network can then reason about the object's geometry by utilizing both the collected tactile and depth information. We demonstrate that even small amounts of additional tactile information can be incredibly helpful in reasoning about object geometry. This is particularly true when information from depth alone fails to produce an accurate geometric prediction. Our method is benchmarked against and outperforms other visual-tactile approaches to general geometric reasoning. We also provide experimental results comparing grasping success with our method.
Workspace Aware Online Grasp Planning
Jun 29, 2018
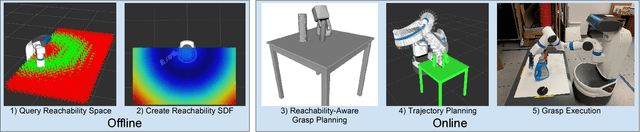
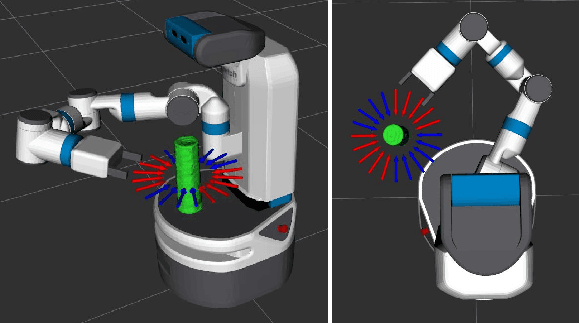
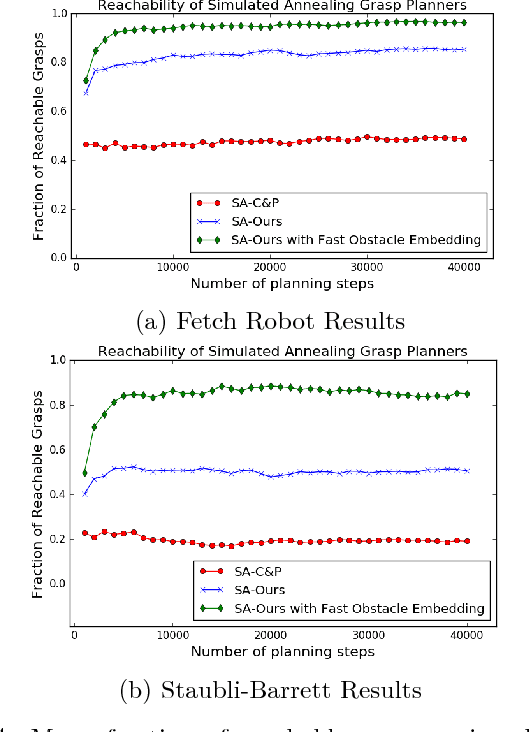
This work provides a framework for a workspace aware online grasp planner. This framework greatly improves the performance of standard online grasp planning algorithms by incorporating a notion of reachability into the online grasp planning process. Offline, a database of hundreds of thousands of unique end-effector poses were queried for feasability. At runtime, our grasp planner uses this database to bias the hand towards reachable end-effector configurations. The bias keeps the grasp planner in accessible regions of the planning scene so that the resulting grasps are tailored to the situation at hand. This results in a higher percentage of reachable grasps, a higher percentage of successful grasp executions, and a reduced planning time. We also present experimental results using simulated and real environments.
Human Robot Interface for Assistive Grasping
Apr 06, 2018
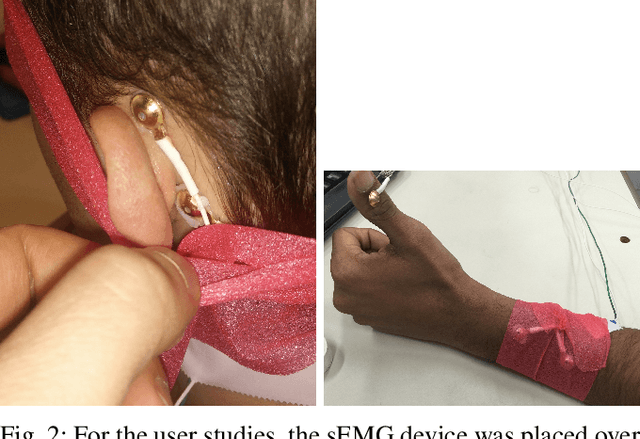

This work describes a new human-in-the-loop (HitL) assistive grasping system for individuals with varying levels of physical capabilities. We investigated the feasibility of using four potential input devices with our assistive grasping system interface, using able-bodied individuals to define a set of quantitative metrics that could be used to assess an assistive grasping system. We then took these measurements and created a generalized benchmark for evaluating the effectiveness of any arbitrary input device into a HitL grasping system. The four input devices were a mouse, a speech recognition device, an assistive switch, and a novel sEMG device developed by our group that was connected either to the forearm or behind the ear of the subject. These preliminary results provide insight into how different interface devices perform for generalized assistive grasping tasks and also highlight the potential of sEMG based control for severely disabled individuals.
Shape Completion Enabled Robotic Grasping
Mar 02, 2017
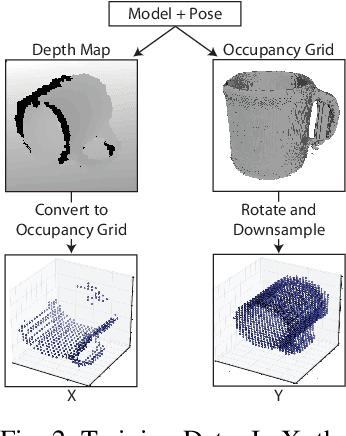
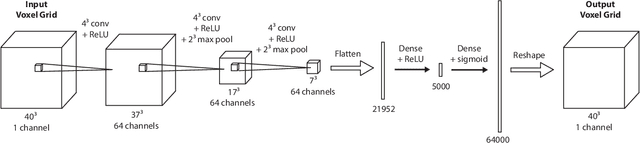

This work provides an architecture to enable robotic grasp planning via shape completion. Shape completion is accomplished through the use of a 3D convolutional neural network (CNN). The network is trained on our own new open source dataset of over 440,000 3D exemplars captured from varying viewpoints. At runtime, a 2.5D pointcloud captured from a single point of view is fed into the CNN, which fills in the occluded regions of the scene, allowing grasps to be planned and executed on the completed object. Runtime shape completion is very rapid because most of the computational costs of shape completion are borne during offline training. We explore how the quality of completions vary based on several factors. These include whether or not the object being completed existed in the training data and how many object models were used to train the network. We also look at the ability of the network to generalize to novel objects allowing the system to complete previously unseen objects at runtime. Finally, experimentation is done both in simulation and on actual robotic hardware to explore the relationship between completion quality and the utility of the completed mesh model for grasping.